前沿科技速递🚀
微软推出的OmniParser是一种创新的框架,旨在将手机和电脑屏幕视为文档,通过OCR技术与多模态大模型实现对用户界面的深度理解和操作。OmniParser能够高效识别和提取界面中的文本信息、位置和语义,助力自动化操作。
来源:传神社区
01 模型简介
微软的OmniParser是一种创新的统一框架,旨在从视觉文档中提取结构化信息。该模型将文本定位、关键信息提取和表识别等任务整合在一个框架内,利用OCR技术和多模态大模型,提升了对用户界面的理解和操作能力。OmniParser的设计初衷是为了解决传统方法中存在的模态隔离和复杂工作流程问题,提供一种更高效、直观的文档理解方式。

02 核心创新
OmniParser的核心技术架构如下:
OmniParser使用一个统一的编码器-解码器架构,能够同时处理多种视觉文本解析任务。通过共享特征提取,减少了模型复杂性,提高了效率。
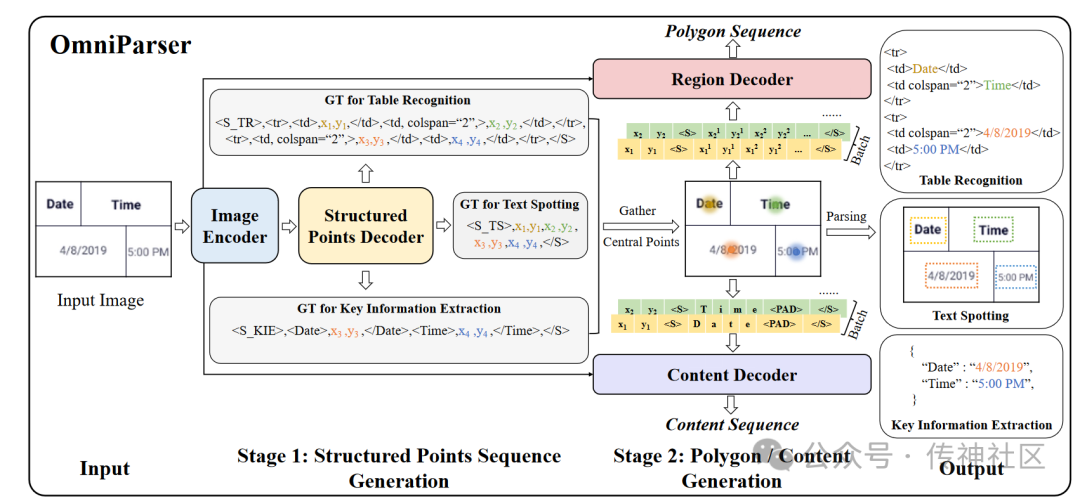
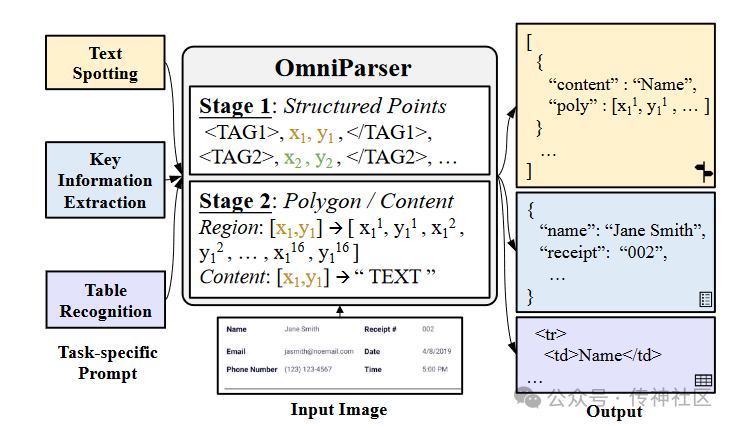
该模型采用两阶段生成策略。在第一阶段,基于输入图像和任务提示生成结构化序列;在第二阶段,对每个结构点进行多边形轮廓和识别结果的预测。这一策略显著降低了学习结构化序列的难度,提高了模型的泛化能力。
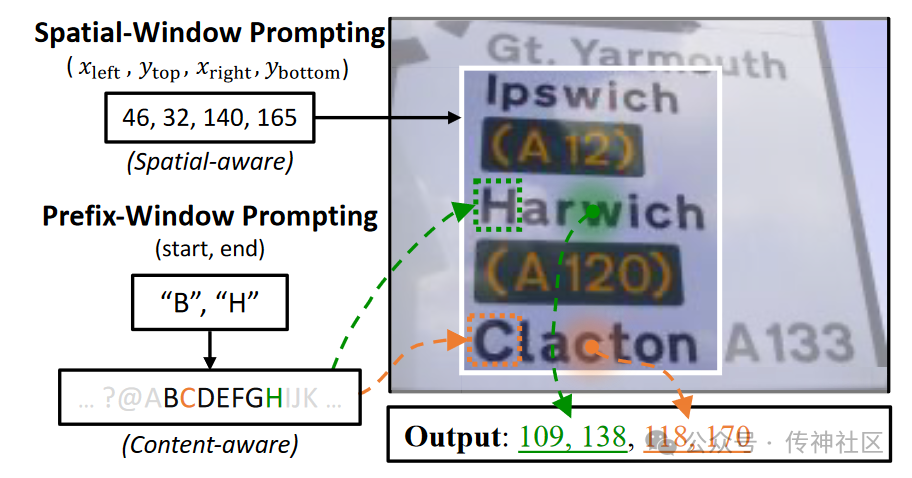
采用空间窗口提示和前缀窗口提示,增强了模型对文本结构和语义的理解能力。这使得模型在处理文本定位和信息抽取任务时更加高效。
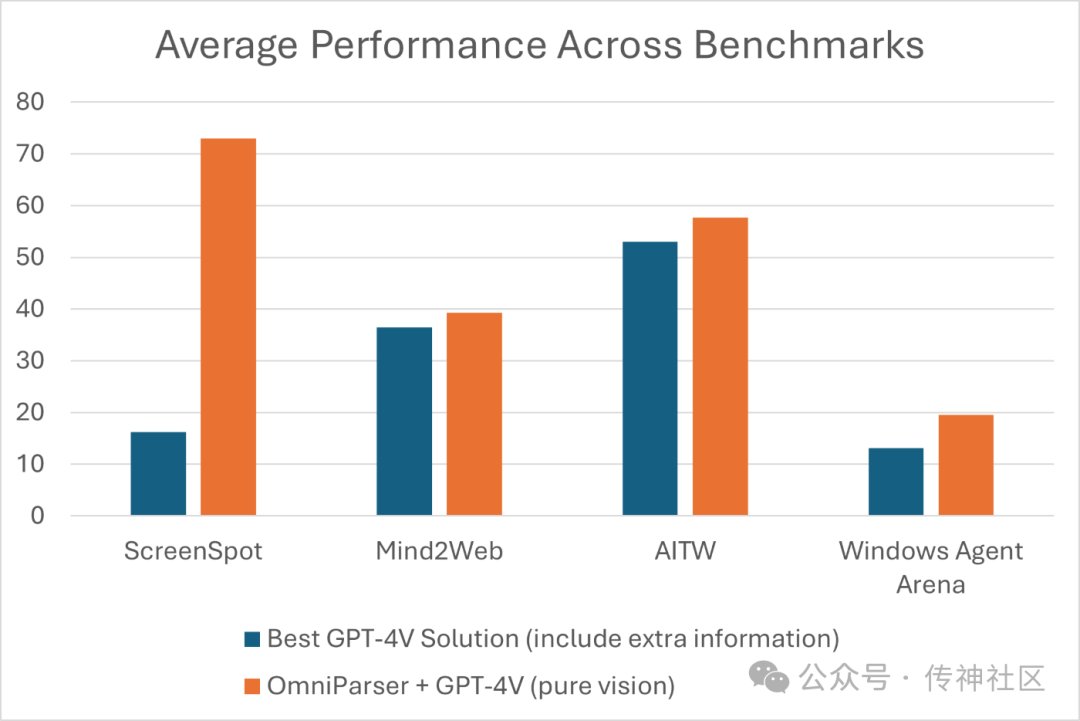
03 卓越性能
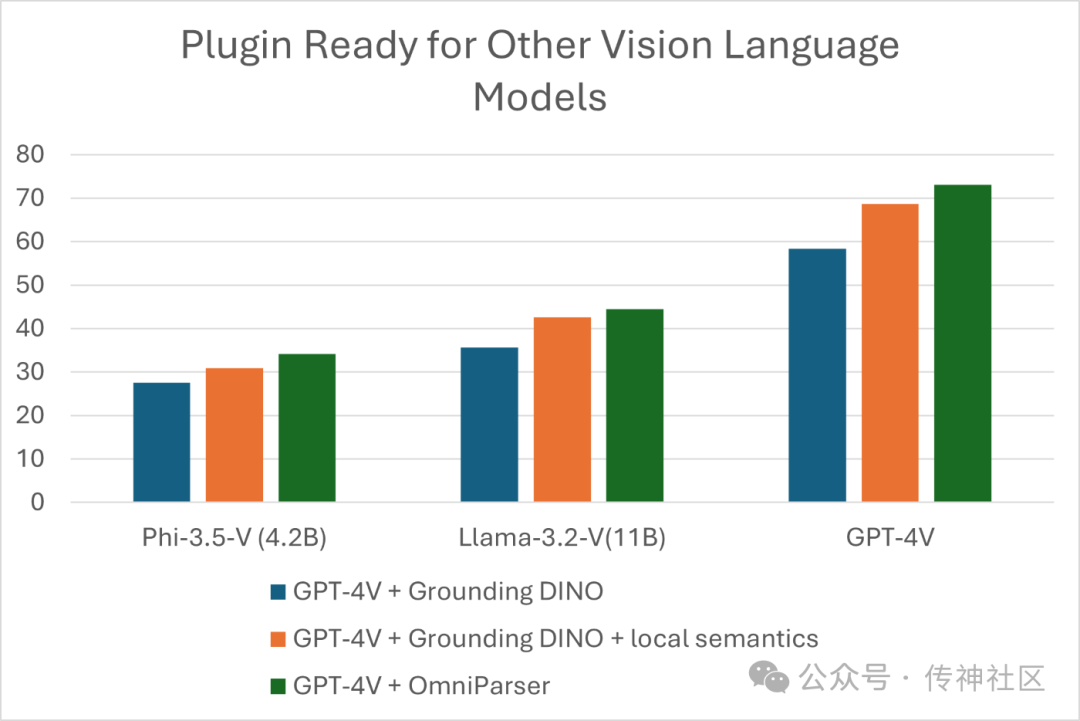
在ScreenSpot基准测试中,使用解析结果的GPT-4V性能得到了显著提升。在Mind2Web上,OmniParser与GPT-4V的结合表现优于使用HTML提取的额外信息的GPT-4V代理。
在AITW基准测试中,OmniParser超越了依赖于视图层次结构训练的专用Android图标检测模型的GPT-4V,表现出色。此外,OmniParser在新的WindowsAgentArena基准测试中也取得了最佳性能。
OmniParser可以作为现成视觉语言模型的插件,能够与最近发布的Phi-3.5-V和Llama-3.2-V模型结合使用,进一步展示了其广泛的兼容性和灵活性。我们希望OmniParser能成为一个通用、易于使用的工具,能够在PC和移动平台上解析用户屏幕,而无需依赖HTML和Android的视图层次结构等额外信息。
04 模型下载
传神社区:
https://opencsg.com/models/microsoft/OmniParser
huggingface:
https://huggingface.co/microsoft/OmniParser
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区















![[SaaS] 数禾科技 AIGC生成营销素材](https://i-blog.csdnimg.cn/direct/0094ed404346466586342764ad58b872.png)
