https://arxiv.org/pdf/2106.09018.pdf
半监督学习重在流程,而不在网络细节
Abstract
本文提出了一种端到端半监督目标检测方法,不同于以往更复杂的多阶段方法。端到端训练逐渐提高了训练过程的伪标签质量,越来越准确的伪标签进而有利于目标检测训练。在这个框架内,我们还提出了两种简单而有效的技术:一种soft teacher机制,其中每个未标记边界框的分类损失由teacher网络产生的分类分数来加权;一种box抖动方法来选择可靠的伪框来学习box回归。在COCO基准上,在不同的1%、5%和10%下,所提出的方法大大优于以前的方法。此外,当标记数据量相对较大时,我们的方法也表现得很好。
soft teacher机制主要是针对分类的,就是说,我们需要根据teacher网络预测效果的好坏给与不同的惩罚,即使预测相关均不好,我们也要给预测效果更差的给予更多的惩罚。如何进行惩罚呢?——损失函数
box抖动主要是针对回归而言,指的是单次预测并不足以反映预测出的伪标签的好坏,还需要评估预测伪标签的稳定程度,才能够评估预测出伪标签的可信程度。
1. Introduction
数据对于计算机领域很重要。然而,由于注释过程耗时且昂贵,获取标签可能是一个瓶颈。
对于半监督目标检测,我们关注的是基于伪标签的方法,这是目前最先进的方法。这些方法[27,36]进行了多阶段的训练模式,第一阶段使用标记数据训练初始检测器,然后对未标记数据进行伪标记处理,并基于伪标记未标注数据进行再训练步骤。这些多阶段的方法实现了相当好的准确性,然而,最终的性能受到由一个初始的,可能不准确的检测器训练生成的伪标签的质量的限制。
为了解决这一问题,我们提出了一个基于端到端伪标记的半监督目标检测框架,该框架同时对未标记图像进行伪标记,并在每次迭代中使用这些伪标记和一些标记标记训练检测器。具体来说,有标记和未标记的图像以预先设定的比例随机采样,形成一个数据批。对这些图像应用了两种模型,一种进行检测训练,另一种负责对未标记图像的伪标签进行标注。前者也被称为一个学生,而后者是一个教师,这是一个学生模型的指数移动平均线(EMA)。这种端到端方法避免了复杂的多阶段训练方案。此外,它还实现了一种“飞轮效应”,即伪标记和检测训练过程可以相互加强,从而随着训练的进行而变得越来越好。
与多阶段的方法的不同之处在于,它是对标注数据和未标注数据同时做的。
这个端到端框架的另一个重要好处是,它允许更大地利用教师模型来指导学生模型的培训,而不是像以前的方法[27,36]那样,仅仅提供“一些生成的带有硬类别标签的伪box标签”。提出了一种soft teacher的方法来实现。在这种方法中,教师模型被用于直接评估由学生模型生成的所有候选框,而不是提供“伪box标签”来为这些学生生成的盒子候选人分配类别标签和回归向量。对这些候选框的直接评估使在学生模型培训中使用更广泛的监督信息。具体来说,我们首先根据具有高前景阈值的检测分数将候选框分类为前景/背景,以确保正伪标签的高精度,如[27]。然而,这种高前景阈值导致许多积极的候选框被错误地分配为背景。为了解决这个问题,我们建议使用一个可靠性度量来衡量每个“背景”候选盒子的损失。我们通过经验发现,由教师模型产生的一个简单的检测分数可以很好地作为可靠性度量,并被用于我们的方法。我们发现,这种方法的表现明显优于以前的硬前景/背景分配方法(见表3和表4),我们将其命名为“soft teacher”。
与之前方法不同的是,soft teacher是去评估teacher模型生成的伪box标签的准确度,而不是直接使用伪box标签。
另一种方法实例化这种见解是通过box抖动方法选择可靠的边界框来训练学生的定位分支。这种方法首先将伪前景框候选对象抖动几次。然后根据教师模型的位置分支对这些抖动box进行回归,并将这些回归box的方差作为可靠性度量。具有足够高可靠性的候选框将用于学生模型的训练。
2. Related works
图像分类中的半监督学习 图像分类中的半监督学习大致可以分为基于一致性和基于伪标记两类。基于一致性的方法[1,23,19,11]利用未标记的图像来构造一个正则化损失,从而鼓励对同一图像的不同扰动来产生类似的预测。有几种方法来实现扰动,包括扰动模型[1],增强图像[23]或对抗性训练[19]。在[11]中,训练目标是通过预测不同的训练步骤来组装的。在[29]中,他们通过集成模型本身而不是模型预测来开发[11],即学生模型的所谓指数平均平均值(EMA)。伪标签方法[33,7,12](也称为自训练)通过初始训练的分类模型对未标记图像进行标注,并通过这些伪标记图像对检测器进行细化。在[29]中,他们通过集成模型本身而不是模型预测来开发[11],即学生模型的所谓指数平均平均值(EMA)。伪标签方法[33,7,12](也称为自训练)通过初始训练的分类模型对未标记图像进行标注,并通过这些伪标记图像对检测器进行细化。与我们专注于目标检测的方法不同,伪标签在分类图像时不需要解决分配前景/背景标签和盒子回归的问题。最近,一些工作[32,3,2,26]探讨了数据增强在半监督学习中的重要性,这启发了我们使用弱增强来生成伪标签和强增强来学习检测模型。
目标检测中的半监督学习 与图像分类中的半监督学习类似,半监督目标检测方法也有两类:一致性方法[10,28]和伪标签方法[20,36,13,27,31]。我们的方法属于伪标签类别。在[20,36]中,不同数据增强的预测被集成,形成未标记图像的伪标签。在[13]中,我们训练了一个选择网来选择伪标签。在[31]中,将未标记图像上检测到的盒子粘贴到标记图像上,并对粘贴后的标签图像进行定位一致性估计。由于图像本身被修改,在[31]中需要一个非常彻底的检测过程。在我们的方法中,只处理了轻量级的检测头。STAC [27]提出使用弱数据增强来进行模型训练,并使用强数据增强来进行伪标签。然而,与其他伪标签方法[20,36,13,27,31]一样,它也遵循了多阶段的训练方案。相比之下,我们的方法是一个端到端伪标记框架,它避免了复杂的训练过程,也取得了更好的性能。
3. Methodology
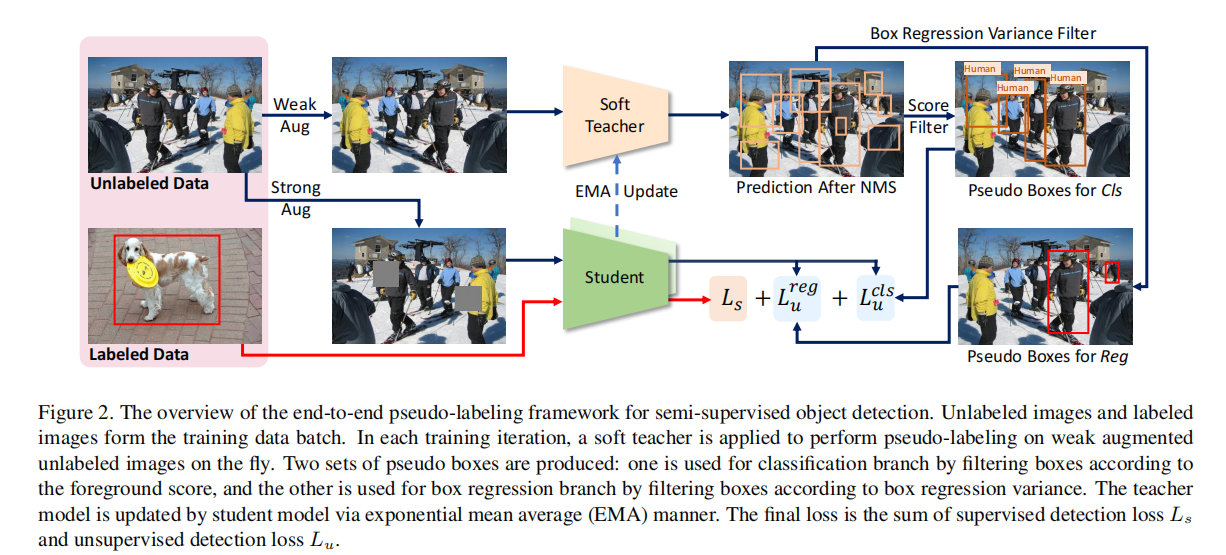
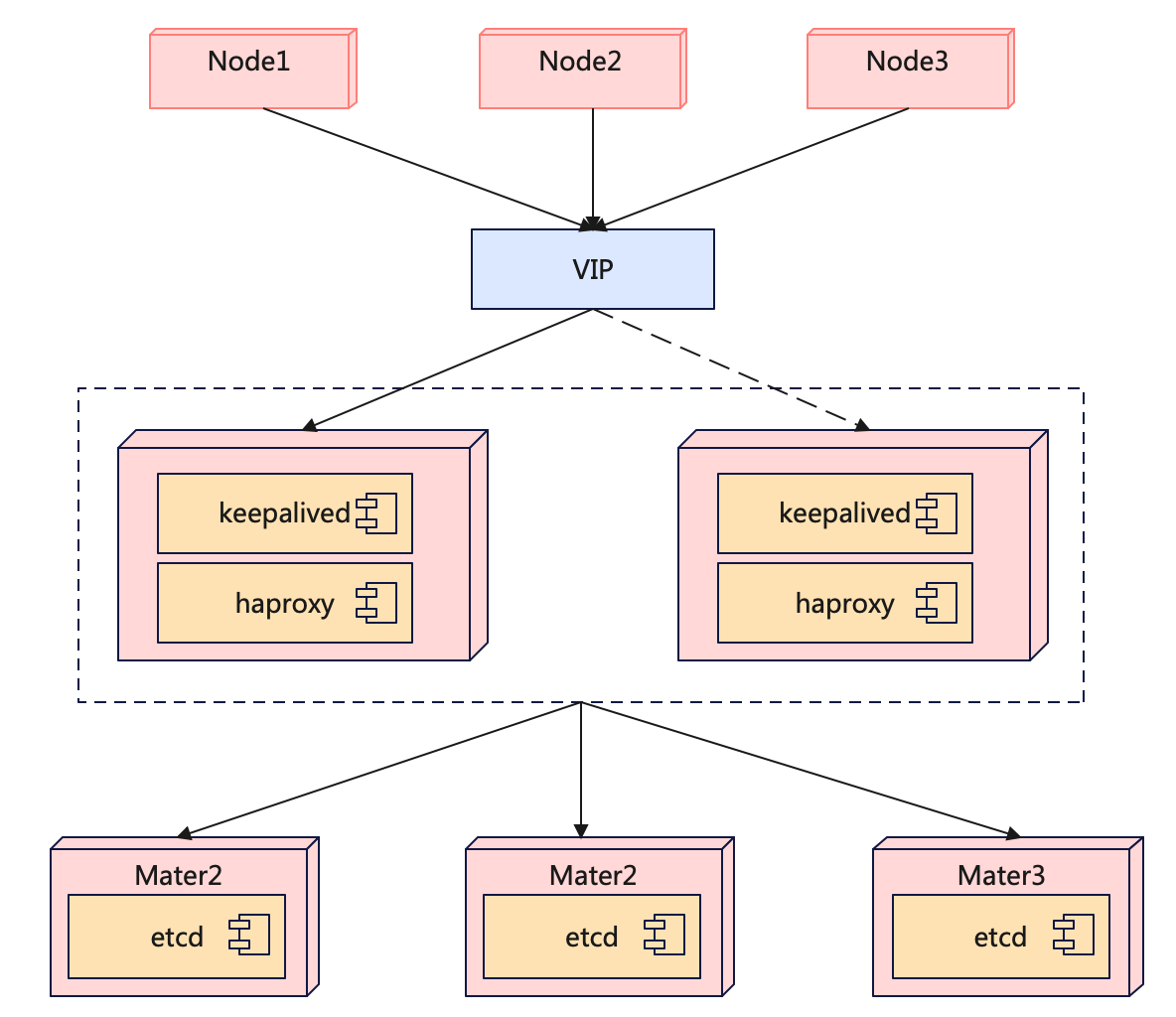
整体框架:
- 对于标注的数据,直接输入Student模型中
- Teacher模型是由Student模型加权得到
- 对于未标注的数据,一方面经过较弱的数据增强策略,输入soft teacher模型中,经过NMS后进行分类和回归预测,提供软标签。另一方面未标注的数据经过强的数据增强后,输入到Student模型中,与Soft teacher模型提供的软标签计算损失。
为了保证标签的置信程度,我们需要对soft teacher的预测进行过滤,且通常采用较高的阈值进行筛选。这会带来一个问题,这样做保证了高精度但是召回率会很低,这会严重影响结果。此外,box标签可能带有一定的随机性,即预测不稳定。
3.1. End-to-End Pseudo-Labeling Framework
损失包含有监督损失和无监督损失的损失和
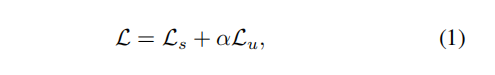
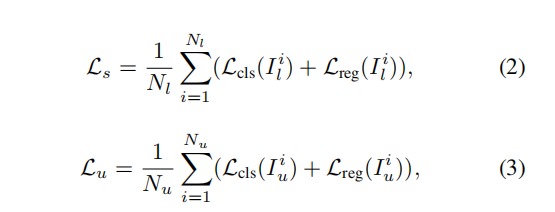
3.2. Soft Teacher
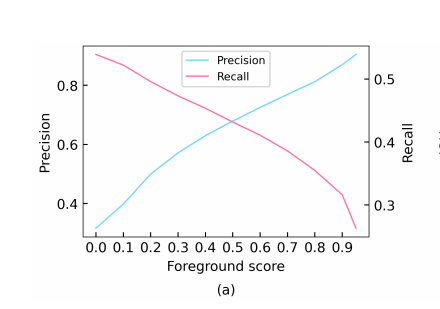
为了提升伪标签的质量,作者将阈值设为0.9, 然而,更高的阈值会导致更高的前景精度,但保留的候选框的召回率也会迅速下降。如图所示。3 (a),当前景阈值设置为0.9时,查全率较低,为33%,而精度达到89%。在这种情况下,如果我们使用学生生成候选框和教师生成伪框分配前景和背景标签,一般对象检测框架提供真正的框注释时,一些前景框候选框将被错误地分配为负样本,这可能会阻碍培训和损害性能。
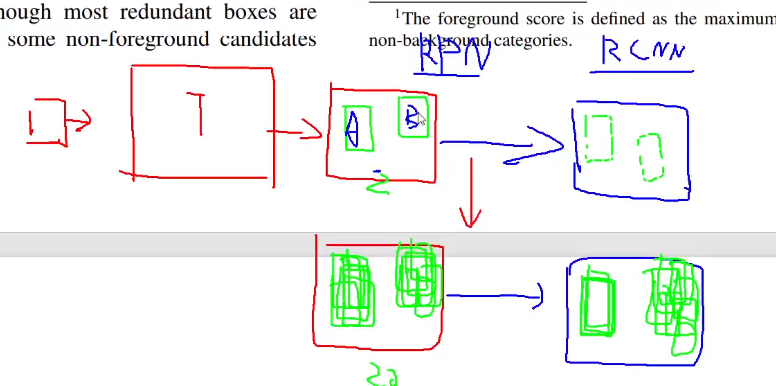
首先,作者并没有使用单阶段算法直接使用teacher伪标签,而是采用二阶段算法,在RPN层进行处理,利用teacher模型生成候选框,这是整个论文的精髓。
对于损失函数,前景部分非常常规,就是RPN层的候选框存在物体的可能性的损失函数。 而对于背景,正如前面所说,对于这种低召回率的处理,为了处理这种低召回率,作者在损失函数进行惩罚。我们不仅仅需要看前景和背景的预测结果。而且还要关注背景中候选框预测的概率。概率越高,预测错误的预测为背景的概率越大,需要给与更多的惩罚。
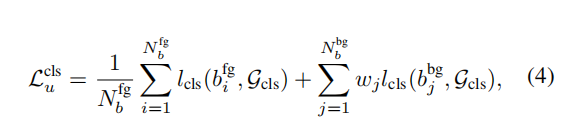
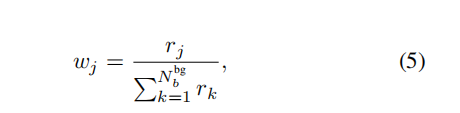
3.3. Box Jittering
box抖动的含义就是,RPN层预测的候选框,首先对box抖动一下,即随机改变一下候选框的位置和大小,后面再进行回归,对候选框进行微调,并用方差衡量候选框的微调结果。如果方差比较大,说明预测的候选框是不可信的, 为了保证计算速度,只对前景预测得分大于0.5的进行抖动评估。
抖动公式:
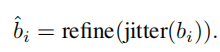
方差计算公式:
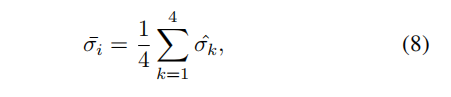
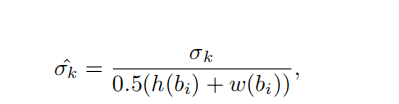
最终的回归损失,使用teacher的回归预测作为标签。
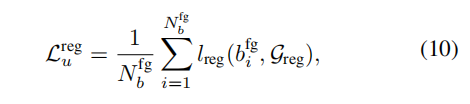
总损失:
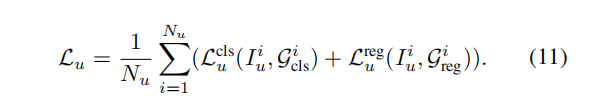
4. Experiments
4.1. Dataset and Evaluation Protocol
部分标记数据: 采样COCO数据集train2017的1%、5%和10%的图像作为标记训练数据,剩余的未采样图像作为未标记数据。
完全标记数据:在此设置中,整个train2017被用作标记数据,而未标记的2017被用作额外的未标记数据。这种设置更具挑战性。它的目标是使用额外的未标记数据来改进在大规模标记数据上训练有素的检测器。
4.2. Implementation Details
在本节中,我们将我们的方法与以前的MS-COCO技术进行了比较。我们首先评估部分标记的数据设置,并将我们的方法与STAC进行比较。对于基准测试,我们将我们的方法的监督基线与STAC中报告的结果进行了比较,发现它们的执行方式类似,结果如表所示。 3.在这种情况下,我们进一步在系统级上将我们的方法与STAC进行了比较,我们的方法在不同的协议中显示出了显著的性能提高。具体来说,当标记数据为1%、5%和10%时,我们的方法分别比STAC高出6.5%、6.4%和5.4%。我们的方法与监督基线相比的定性结果如图所示。

然后,我们比较了我们的方法与其他最先进的方法在完全标记的数据设置。由于报告的监督基线的表现不同,我们同时报告比较方法及其基线的结果。结果如表所示。
我们首先与提案学习[28]和STAC [27]进行比较,它们也使用未标记的2017作为额外的未标记数据。由于更好的超参数和更充分的训练,我们的监督基线比其他方法取得了更好的性能。在较强的基线下,我们的方法仍然比提案学习(+1.0%)和STAC(-0.3%)显示出更大的性能提高(+3.6%)。自训练[36]使用ImageNet(120万张图像)和开放图像(170万张图像)作为额外的未标记数据,比我们使用的未标记的2017张(123k张图像)大20×。具有类似的基线性能,我们的方法在较少的未标记数据下也显示出更好的结果。

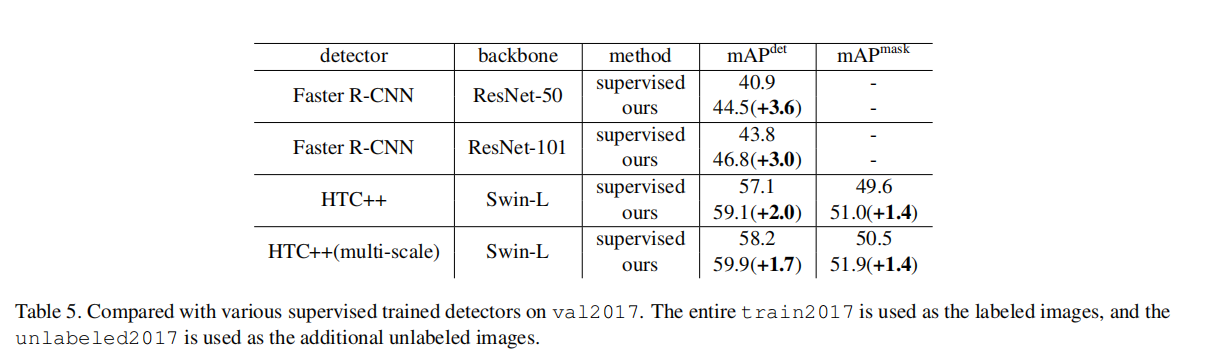
此外,我们在其他较强的检测器上进一步评估了我们的方法,在val2017集上评估的结果如表所示。 5.我们的方法持续地显著地提高了不同检测器的性能。即使在最先进的具有Swin-L主干的HTC++探测器中,我们仍然显示了检测AP的1.8改进和掩模AP的1.4改进。此外,我们还报告了测试-dev2017集的结果。如Tabel中所示。1、我们的方法对具有Swin-L骨干的HTC++进行了1.5 mAP的检测改进,这是第一次在COCO目标检测基准上进行了超过60 mAP的检测工作。
4.4. Ablation Studies
在本节中,我们将验证我们的关键设计。如果没有说明,所有消融实验都在[27]提供的单个数据折叠上进行,其中包含train2017的10%标记图像。
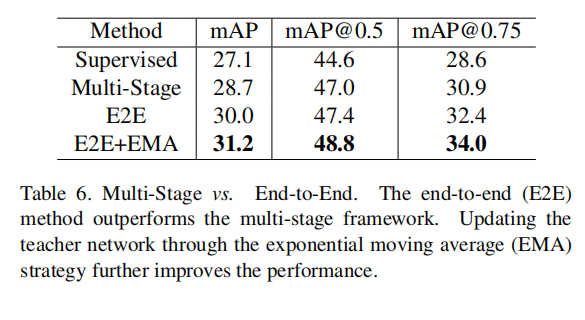
Multi-Stage vs. End-to-End. 我们将我们的端到端方法与如表6所示的多阶段框架进行了比较。通过简单地从多阶段框架切换到我们的端到端框架,性能提高了1.3%百分点。通过指数移动平均(EMA)策略对教师模型和学生模型进行更新,进一步实现了31.2 mAP。
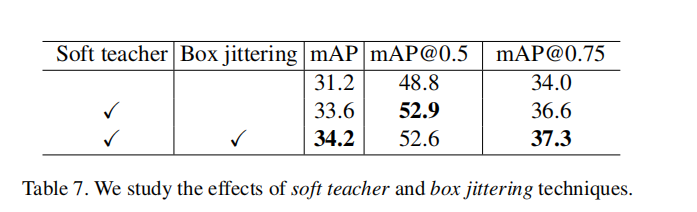
Effects of Soft Teacher and Box Jittering. 我们消除了soft teacher和box抖动的影响。结果如表所示。 7.基于我们配备了EMA(E2E+EMA)的端到端模型,集成了soft teacher的性能提高了2.4%。进一步应用盒抖动,性能达到34.2 mAP,比E2E+EMA好3分。
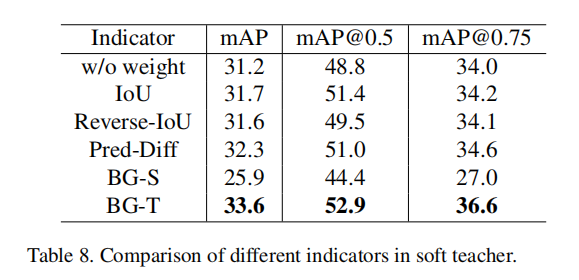
Different Indicators in Soft Teacher. 在部分中。3.2,探讨了几种不同的可靠性估计指标。在这里,我们评估了不同的指标,结果如表所示。 8.教师模型预测的背景得分表现最好。简单地把模式从老师换到学生会使表现更糟。此外,与BG-T相比,IoU和Revearse-IoU的改进可以忽略不计。这些结果证明了利用教师模式的必要性。
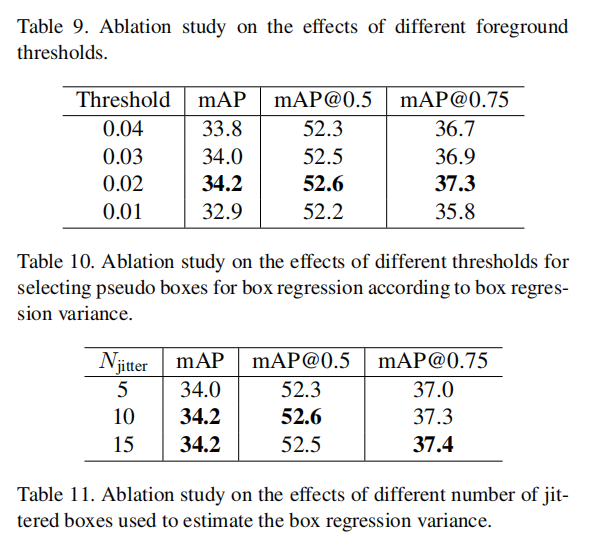
Effects of other hyper-parameters. 我们研究了在我们的方法中使用的超参数的影响。表9.研究了不同的前景评分阈值的影响。当阈值设置为0.9时,可以获得最佳性能,而较低或较高的阈值将导致显著的性能下降。在表中。10,我们研究了盒子回归方差阈值。当阈值设置为0.02时,可以获得最佳性能。在表中。11,我们研究了不同数量的抖动盒的影响,当Njetehr设置为10时,性能达到饱和。