Saas/内部解决方案
2.10、Netflix Metacat
Metacat 是一种元数据服务,使数据易于发现、处理和管理。在 Netflix,数据仓库由存储在 Amazon S3(通过 Hive)、Druid、Elasticsearch、Redshift、Snowflake 和 MySql 中的大量数据集组成。平台支持使用 Spark、Presto、Pig 和 Hive 来消费、处理和生成数据集。鉴于数据源的多样性,并确保数据平台可以作为一个“单一”数据仓库跨这些数据集进行互操作,由此构建了 Metacat。
地址:https://netflixtechblog.com/metacat-making-big-data-discoverable-and-meaningful-at-netflix-56fb36a53520?gi=30b7bd4248ae
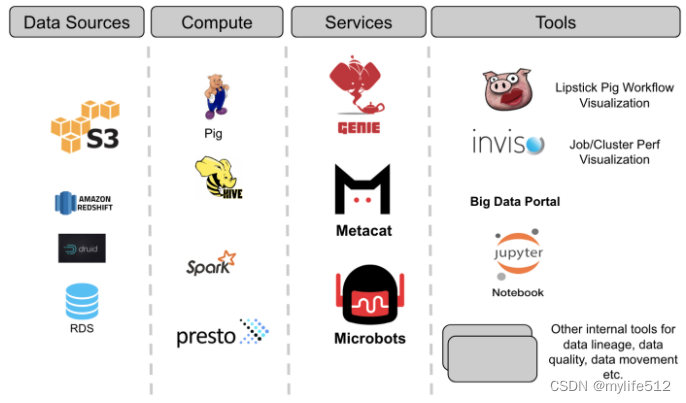
Netflix 大数据平台的核心架构涉及三个关键服务。它们是执行服务 (Genie)、元数据服务和事件服务。这些想法并不是 Netflix 独有的,他们认为这是构建一个系统所必需的架构。
许多年前,当Netflix开始构建平台时,采用 Pig 作为ETL 语言,采用 Hive 作为临时查询语言。由于 Pig 本身没有元数据系统,因此构建一个可以在两者之间进行互操作的系统似乎是当时的理想选择。
因此 Metacat 诞生了,一个系统充当支持的所有数据存储的联合元数据访问层。各种计算引擎可用于访问不同数据集的集中式服务。一般来说,Metacat 服务于三个主要目标:
1、元数据系统的联合视图
2、数据集元数据的统一 API
3、数据集的任意业务和用户元数据存储
值得注意的是,其他拥有大型分布式数据集的公司也面临着类似的挑战。 Apache Atlas、Twitter 的数据抽象层和 Linkedin 的 WhereHows(Linkedin 的数据发现)。
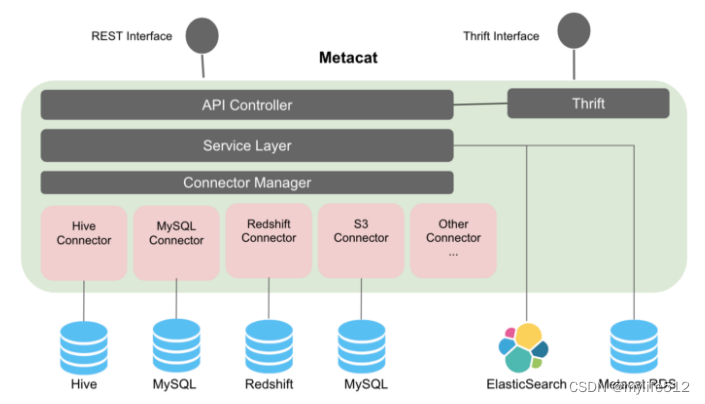
Metacat 提供统一的 REST/Thrift 接口来访问各种数据存储的元数据,相应的元数据存储仍然是模式元数据的真实来源,因此 Metacat 不会在其存储中实现它。它只直接存储有关数据集的业务和用户定义的元数据。它还将有关数据集的所有信息存储到 Elasticsearch 以进行全文搜索和发现。
在更高的层次上,Metacat 的功能可以分为以下几类:
1、数据抽象和互操作性
2、业务和用户定义的元数据存储
3、数据发现
4、数据变更审计和通知
5、Hive 元存储优化
2.11、Uber Databook
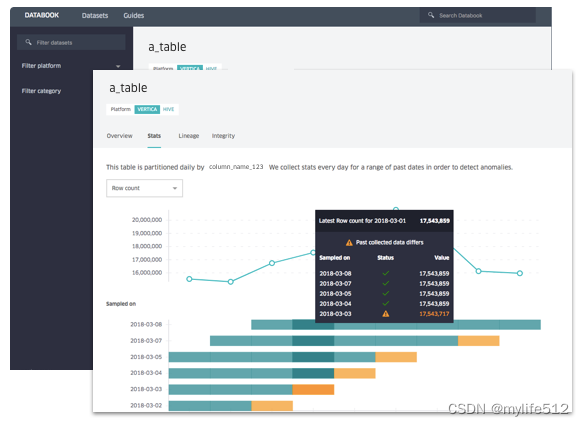
Databook是Uber的内部平台,该平台可以显示和管理数据集的内部位置和所有者的元数据,能够将数据转化为知识
地址:Databook: Turning Big Data into Knowledge with Metadata at Uber | Uber Blog
功能:
1、可扩展性:新的元数据、存储和实体很容易添加。
2、可访问性:服务可以以接口方式访问所有元数据
3、可伸缩性:支持高吞吐量读取
4、支持跨数据中心读写
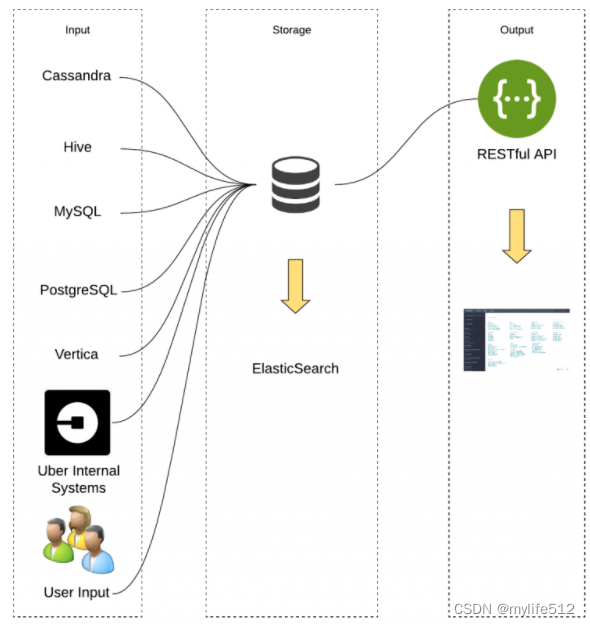
Databook 提供了来自 Hive、Vertica、MySQL、Postgres、Cassandra 和其他几个内部存储系统的各种元数据,包括:表模式、表/列描述、样本数据、统计数据、血缘、、表新鲜度、SLA 和责任人等等。
所有元数据都可以通过UI可视化和 RESTful API 访问。
1、RESTful API 由 Dropwizard 提供支持,Dropwizard 是一种用于高性能 RESTful Web 服务的 Java 框架,部署在多台机器上,并由 Uber 的内部请求转发服务进行负载平衡。
2、可视化 UI 是用 React.js 和 Redux 以及 D3.js 编写的,主要提供整个公司的工程师、数据科学家、数据分析师和运营团队使用,以及对数据质量问题进行分类并识别和探索相关数据集。
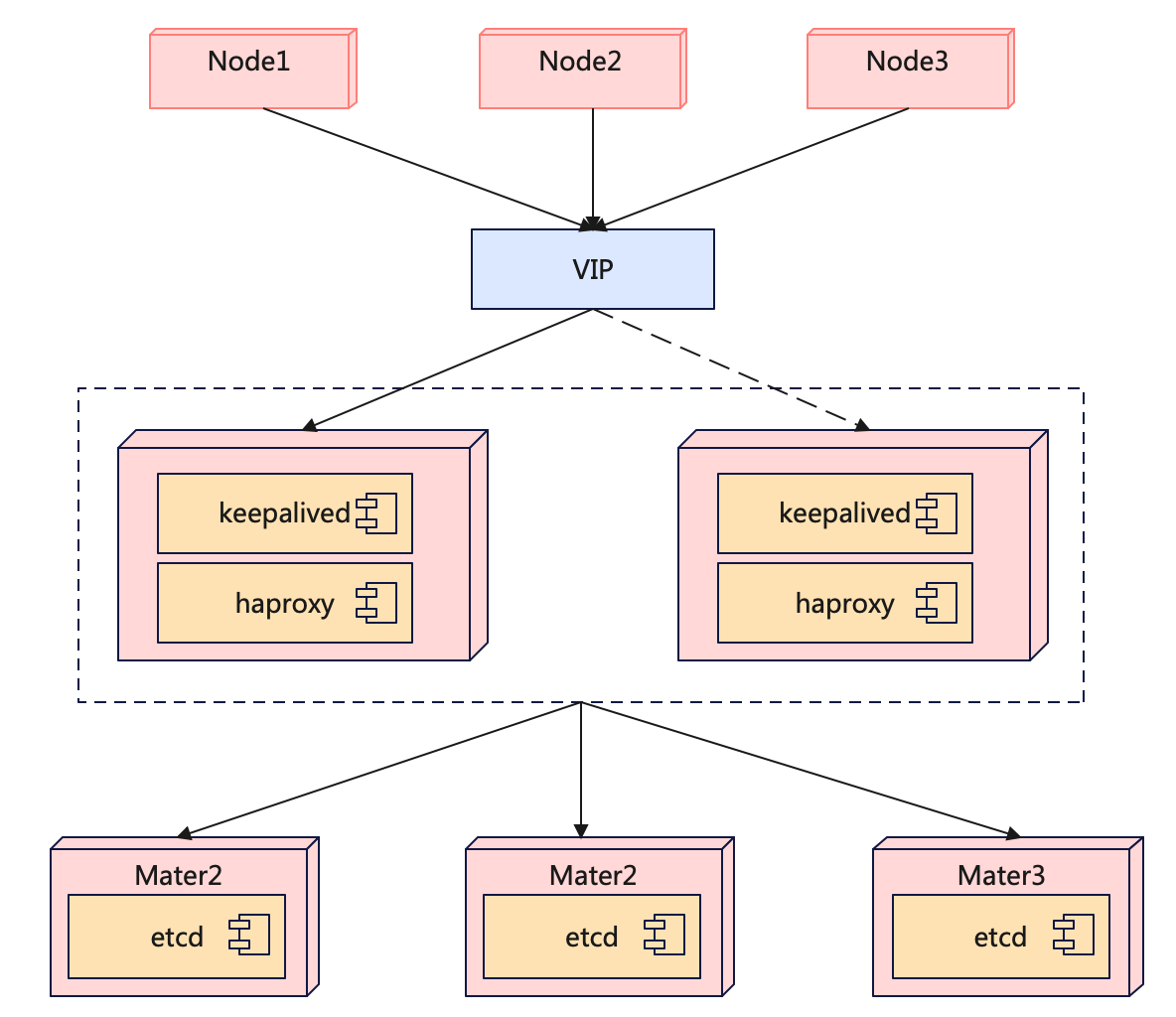
架构: