愿景
今年大部分业余时间都在nutsdb的开源贡献上,nutsdb是基于bitcask模型实现的持久化存储引擎,提供了诸如list,set等多种丰富的数据结构。近来很多小伙伴,其中也有一些我的好朋友陆陆续续加入到这个项目上来。为了帮助小伙伴们快速熟悉整个项目,我会把之前写的一些文章分享给他们,但是我觉得这样可能还是不太够,因为之前做的是关于性能优化的事情,文章是偏向于性能优化方面的思考。对于bitcask整体架构的解释,实现,感觉写着墨不多,意识到这一点之后,我就想写一篇文章来解释一下bitcask的核心概念,并且花了几个小时的时间写下了一个简单版本的demo(写unit test测试之后,几百行代码只有一个小bug,小窃喜)。在帮助大家了解了核心概念之后,就算是有了一个基本的入门了,后面可以更快的参与到项目中来。这是我写这篇文章的初衷,也同时欢迎更多的小伙伴参与到这个项目中来。
这篇文章会结合bitcask论文以及我的代码实现进行分析,主要是讲的是“怎么做”,对于“为什么”可能侧重并不多。另外该bitcask实现我已经开源到我的github上,可以在github上看到更多实现细节,链接:https://github.com/elliotchenzichang/tiny-bitcask ,欢迎star。
整体架构
该怎么开始这个故事呢,我思虑良久,决定从db的整体架构开始阐述,然后在自底向上的讲述每一个部分的实现细节。为什么是自底向上呢?因为从下往上讲可以从点到线,从线到面,慢慢的拨开云雾,看见一整个db的实现,会有一种世界在面前缓缓打开的感觉。另外,如果是从上到下来看结合代码讲的时候,可能有一些代码会变得不好解释。
言归正传,如上面所说我们要实现一个基于Bitcask模型的kv存储引擎,那么对于持久化存储引擎而言,数据的最终归宿是磁盘。而我们知道,程序是运行在内存中的,所以存储引擎提供需要做的就是以某种方式把用户给的数据存进磁盘,也以某种方式将用户的数据从磁盘里面拿出来使用。至于这些方式的设计的是否高效,就是存储引擎设计的艺术所在。其实粗略来看,存储引擎的整体架构整体如下图,内存中放置索引,可以直接(比如bitcask)或者间接(比如leveldb的SST的索引形式)的找到数据,磁盘中存储用户的数据,可以是同构的数据文件(比如bitcask全是data_file),也可以是异构的数据文件(比如leveldb的WAL log和SST)。
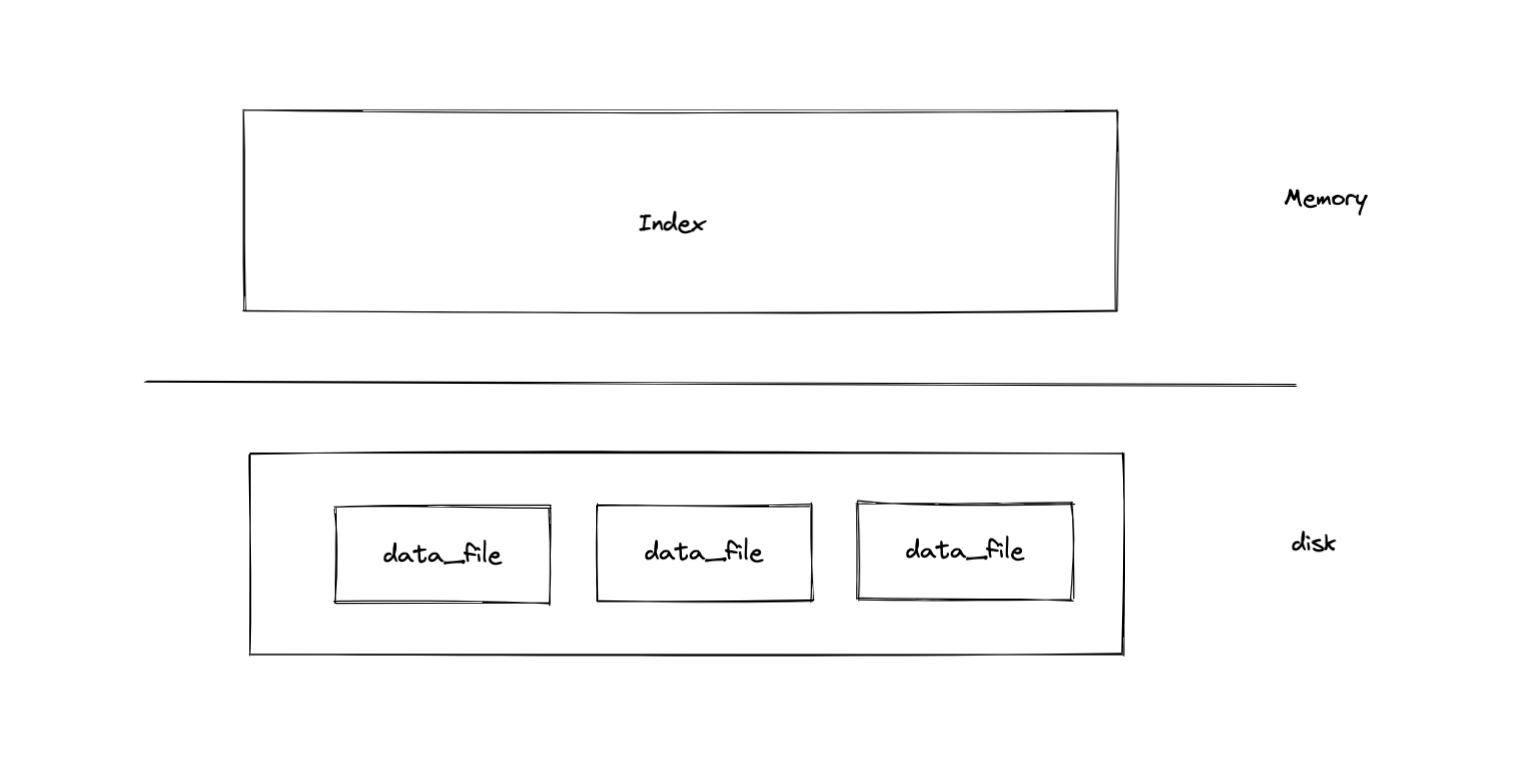
bitcask采用的是一种比较简单的形式,如下图所示,内存中会记录每条数据在磁盘中的位置,以及key和value的长度,这样就可以直接通过一次系统调用在数据存放的位置把它拿出来了。

大概讲述了整体的架构之后我们来看看代码实现中主要的对象有哪些,自底向上的看。
- Entry:代表db中一条数据的信息。
- Storage:与文件系统打交道的对象,包括了写入,读取数据。
- Index,索引,记录一条数据的具体信息,主要是数据在磁盘中的位置。
- db,db的实体。包含了db的各种操作,包括读取,写入数据。
接下来我们看看具体的实现,下面解析会结合代码分析,在代码的关键部分我已经写好了注释。系好安全带,发车了!
1. 数据的编码与解码
首先我们要讲的是,一条数据是以怎么样的形式存进磁盘的。磁盘才不理你是放进来的是什么东西,他只知道在他身上存放的是一堆二进制,至于那些二进制是什么,由放进来的应用程序来定义。大概逻辑如下图所示,应用程序需要自己实现对磁盘数据写入和读出时候的编码和解码。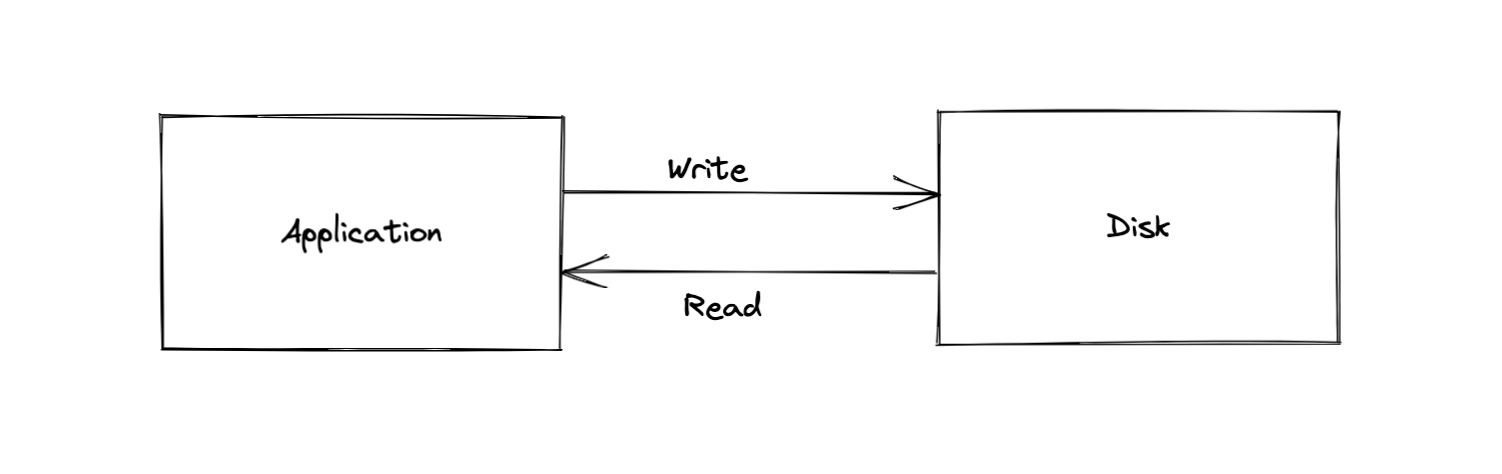
在kv存储引擎中一条数据在磁盘中的是如下图所示。整体上来看我们会有一个meta,key,value,key和value就不必多说了,就是真实的数据部分。那么meta是什么呢?meta是这条数据的元数据,也就是起到描述作用的数据,比如key有多长,value有多长,在什么位置,以及写入数据的时间,其实这个时间戳可以理解为数据的版本,可以是物理时间,也可以是逻辑时间(逻辑时间需要自己实现)。meta的crc部分是做数据校验用的,因为磁盘有时候会出现一些意外,比如一个比特位上的数据发生了变化,从存储1变成0或者从0到1,在或者磁盘数据丢失,也是可能的,所以要加上crc在读出数据的时候再读计算出crc的值和存在磁盘里的crc做比较,如果不一致说明数据出现了问题。
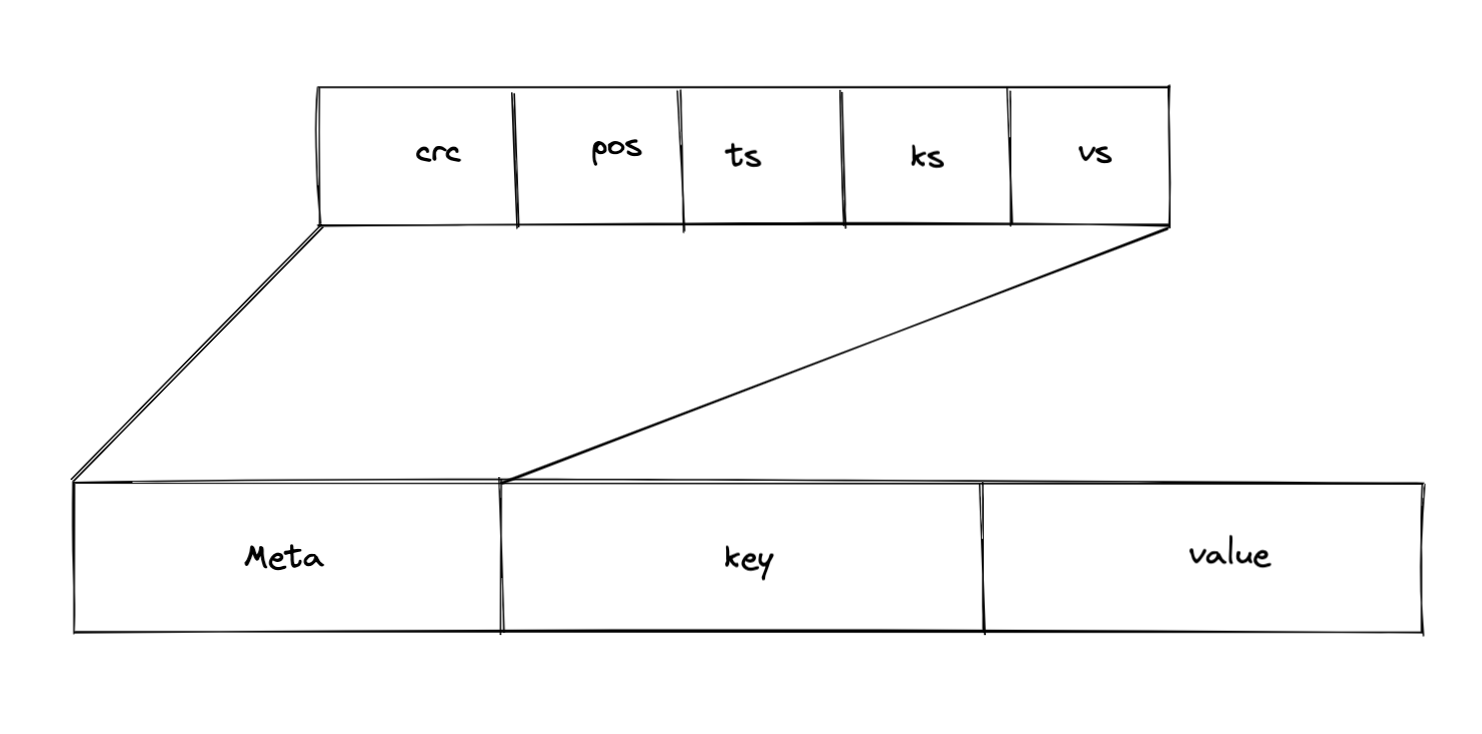
下面是代码实现的节选,其中包含了Entry和Meta这两个主要数据结构的定义,以及数据编码的实现。在写入数据的时候,我们会将一个内存中的Entry对象Encode编码成字节数组然后将字节数据存进磁盘中,在读取数据的时候再将拿到的字节数组解码,这样就组成了我们的数据编解码过程。
// Entry代表数据。
type Entry struct {
key []byte
value []byte
meta *Meta
}
// Meta是元数据
type Meta struct {
crc uint32
position uint64
timeStamp uint64
keySize uint32
valueSize uint32
}
//这个方法的功能是将一个Entry对象编码成byte数组
func (e *Entry) Encode() []byte {
// size是meta+key+value的长度。
size := e.Size()
buf := make([]byte, size)
//以小端字节序将数字写入到字节数组中
binary.LittleEndian.PutUint64(buf[4:12], e.meta.position)
binary.LittleEndian.PutUint64(buf[12:20], e.meta.timeStamp)
binary.LittleEndian.PutUint32(buf[20:24], e.meta.keySize)
binary.LittleEndian.PutUint32(buf[24:28], e.meta.valueSize)
// 操作完meta,下面是操作key和value
copy(buf[MetaSize:MetaSize+len(e.key)], e.key)
copy(buf[MetaSize+len(e.key):MetaSize+len(e.key)+len(e.value)], e.value)
// 计算crc32校验值
c32 := crc32.ChecksumIEEE(buf[4:])
binary.LittleEndian.PutUint32(buf[0:4], c32)
return buf
}
2. 数据的存储与索引
首先我们知道在bitcask模型中有两种文件,一种叫active data file,这个文件可读可写,写入操作(包括删除)只会写入到active data file中,Older data file是active data file数据达到阈值之后转化来的,只可以读取数据,不可以写入数据。
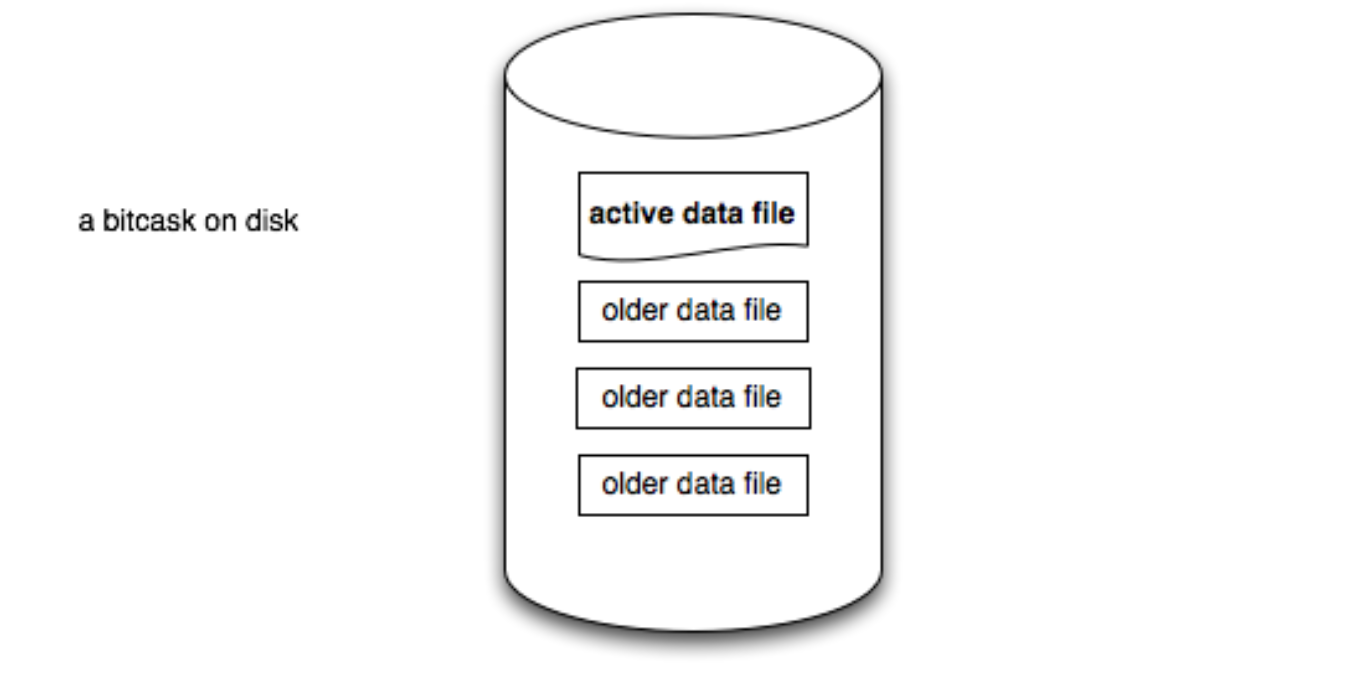
在实现的时候,我们把文件名定义成数字,并且在文件存储的数据到达阈值的时候让当前active data file的文件名 + 1 变成下一个active data file的文件名,这么做有什么好处呢?
这意味着数据文件中文件名所代表的数字最大的文件,就是active data file,另外,依照这个写入的逻辑,我们可以得到这样一个结论。假设fid是文件的名字,off是数据在文件中的位置,那么两条数据可以表示为fid1.off1,fid2.off2,并且如果这两条数据写入的是同一个key,那么那条数据是最新的呢?毫无疑问,如果fid大的数据是最新的,如果fid相等,off大的数据是最新的。这个也很好理解嘛,越往后写入的数据就越新。有了这条结论我们后续的很多操作都会变简单一些。
数据写入到磁盘之后要把当前最新的数据更新到索引中。索引结构如下,hashmap的key是存入数据的key,Index记录了找到这条数据的关键信息,主要是fid和off,这两个字段连起来含义就是:数据存在那个文件(fid)的什么位置(off),
type keyDir struct {
index map[string]*Index
}
type Index struct {
fid int
off int64
timestamp uint64
}
存储数据的主要流程如下:
// Storage这个结构封装了和磁盘操作的相关逻辑
type Storage struct {
// 代表db所在的目录
dir string
// 代表可写入文件的阈值
fileSize int64
// 当前active data file的相关信息
af *ActiveFile
// db中所有数据文件的文件描述符(fd)缓存,免得重复打开文件描述符导致性能消耗。
fds map[int]*os.File
}
// activeFile封装了当前可写入文件的信息
type ActiveFile struct {
// 代表ative data file的名字
fid int
// 文件描述符
f *os.File
// 当前写入数据的最新位置,可以理解为文件的尾部
off int64
}
func (s *Storage) writeAt(bytes []byte) (i *Index, err error) {
err = s.af.writeAt(bytes)
if err != nil {
return nil, err
}
i = &Index{
fid: s.af.fid,
off: s.af.off,
}
s.af.off += int64(len(bytes))
// 如果当前的off大于设置的阈值,进行actice file的切换
// 具体操作是新建一个名为fid + 1 的文件,然后将af切换成代表最新可写入文件的对象。
if s.af.off >= s.fileSize {
err := s.rotate()
if err != nil {
return nil, err
}
}
return i, nil
}
// 代表在可写入文件写入数据
func (af *ActiveFile) writeAt(bytes []byte) error {
n, err := af.f.WriteAt(bytes, af.off)
if n < len(bytes) {
return writeMissDataErr
}
return err
}
讲完了写入流程,我还是想多费一些笔墨讲讲怎么读取数据出来,这里Index的实现其实和bitcask论文中的不太一样,论文中还会记录keySize和valueSize,在读取的时候其实一次性读取就可以了,用metaSize+keySize+valueSize就是整条数据的长度。那么我这里为什么不在Index中存储KeySize和ValueSize了呢?主要是为了和奔溃恢复做一个复用,在奔溃回复的场景中,内存里是没有索引信息的,所以需要两次读取,一次是读出meta,根据meta上面记录的keySize和valueSize,再读取key和value。
3. 并发处理
由于论文中没有提到bitcask是怎么实现并发控制的,这也是优化nutsdb并发性能的重大议题,目前我也有在看一些论文和做相关的实践。在这里,我们采用的是比较原始的方式。在整个db下面加上一把读写锁,有数据写入的时候就加上写锁,读取数据的时候就加上读锁。其实类似于mysql innodb的读提交。
4. 数据Merge
之前我们提到了,db在运行过程中写入操作一直是追加写入,考虑下面的操作:
set key_1 value_1
set key_1 value_2
在写入值为value_2的数据之后,原本的数据就会变成无效数据,为了节省磁盘空间,就需要一个操作来清理掉无效的数据。这个操作就是Merge操作。那么怎么做呢?之前提到的通过fid和off比较数据的新旧的结论在这个时候就派上用场了。因为fid越大,off越大,数据也就越新,merge操作要求我们的也是保留最新的数据。所以merge操作分为以下几步:
- 将文件按照名字(除了active data file)从小往大读取,文件从头读到尾。
- 遇到最新的数据就写入到ative data file,并更新该数据的索引到最新的写入位置。当一个文件中的所有最新数据都写入到别的地方,那么意味着这个文件中所有的数据都是旧数据,就可以把这个文件删除掉啦。
代码如下:
func (db *DB) Merge() error {
// 给整个db加入写锁防止在写入数据的时候有别的程序并发写入。当然这里实则锁住了整个db,效率很低。
db.rw.Lock()
defer db.rw.Unlock()
fids, err := getFids(db.s.dir)
if err != nil {
return err
}
if len(fids) < 2 {
return NoNeedToMerge
}
// fid排序
sort.Ints(fids)
// 这里将active data file排除在外
// 因为最新的数据重新写入逻辑是写在active data file中
// 如果还读取active data file的最新数据再写入到自己身上,就相当于蛇咬自己的尾巴,爱的魔力转圈圈圈了。
for _, fid := range fids[:len(fids)-1] {
var off int64 = 0
for {
entry, err := db.s.readEntry(fid, off)
if err == nil {
off += int64(entry.Size())
oldIndex := db.kd.index[string(entry.key)]
// 判断读出来的数据是不是最新的,用索引中存储的位置比较,如果fid和off都对上了,就是最新数据。
if oldIndex.fid == fid && oldIndex.off == off {
// 重新写入该数据,拿到最新写入位置的索引,并更新。
newIndex, err := db.s.writeAt(entry.Encode())
if err != nil {
return err
}
db.kd.index[string(entry.key)] = newIndex
}
} else {
if err == io.EOF {
break
}
return err
}
}
// 文件中的最新数据都重新写入完毕之后,这个文件的数据都是老数据了,就可以删除了。
err = os.Remove(fmt.Sprintf("%s/%d%s", db.s.dir, fid, fileSuffix))
if err != nil {
return err
}
}
return nil
}
5. 崩溃恢复
当db crash之后需要重新打开的时候,如何恢复现场呢?其实这个问题在理解merge的操作之后就会变的很简单。逻辑是一样的,按照文件名大小依次读取数据,将数据的位置信息构建成索引插入到内存索引中,不需要理会这个key在索引中是否存在,因为当前读到的数据,必定比索引中的存的索引所代表的数据要新。因为当前读到的数据fid或off必定是大于索引中存储的index信息的。这里就不贴代码了hh,感觉理解merge之后这里应该很快就理解啦。
总结
本篇文章我理解为是一篇基于bitcask kv存储引擎的保姆级教程了。不过这篇文章的目的还是让大家对bitcask和nutsdb有整体的了解,并且很多地方实现的个人感觉并不是很好,比如merge可以做到和主流程并发的,异步的进行,然后并发性能也是可以提升的,另外删除的api也没有提供hhh。不过读者朋友们如果能通过看我这篇文章就理解了bitcask,或者可以自己动手也搞一个简单的,我认为我的目的就达到了。相关的代码已经开源,对一些细节之处需要整体了解的可以直接去我的github仓库看哦,链接:https://github.com/elliotchenzichang/tiny-bitcask(欢迎star),另外我也不知道现在的代码中会不会有什么bug,如果github中的代码和文章中的有出入,请以github为准。
参考资料
- nutsdb:https://github.com/nutsdb/nutsdb
- tiny-bitcask:https://github.com/elliotchenzichang/tiny-bitcask
- bitcask paper:https://riak.com/assets/bitcask-intro.pdf

![[附源码]SSM计算机毕业设计大学生心理咨询网站JAVA](https://img-blog.csdnimg.cn/b4deb26816494d94a23a55cdf97cb6ac.png)