1.datasets下载数据集
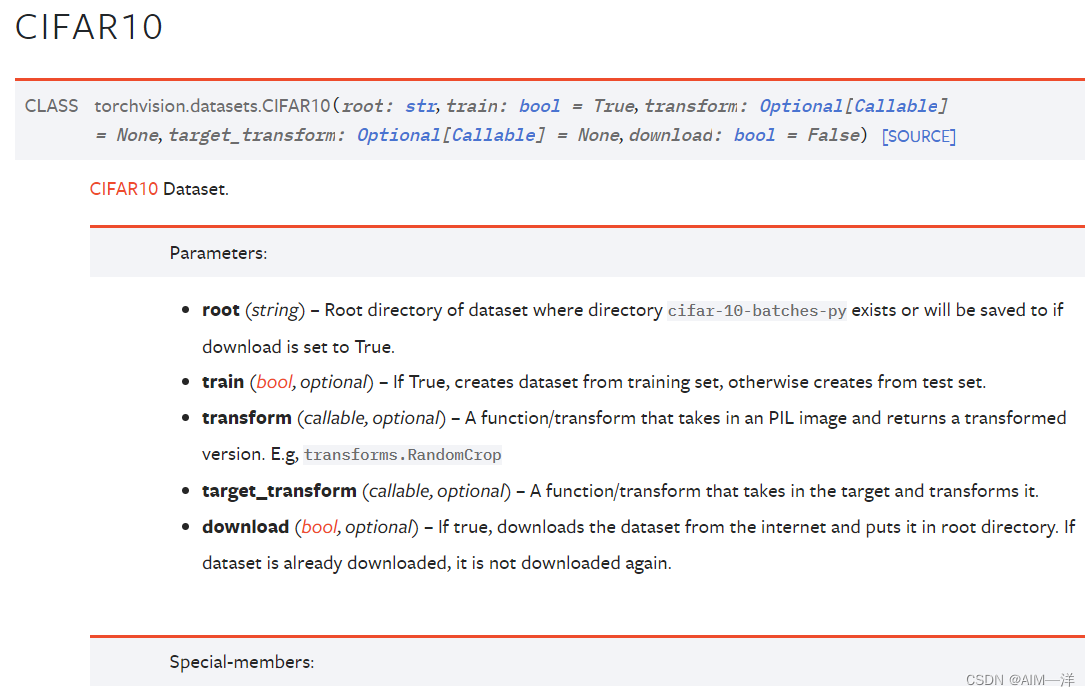
root :代表着路径,表示现存或者准备存储的地方。
train :代表是否下载训练数据集,如果否的话就下载测试数据集
transform: 如果想对数据集进行什么变化,在这里进行操作
target_transform:跟上面的一样
download:如果是True就会从网上下载数据集
这里使用datasets进行下载操作
import torchvision
train_set=torchvision.datasets.CIFAR10(root='../dataset',train=True,download=True)
test_set=torchvision.datasets.CIFAR10(root='../dataset',train=False,download=True)
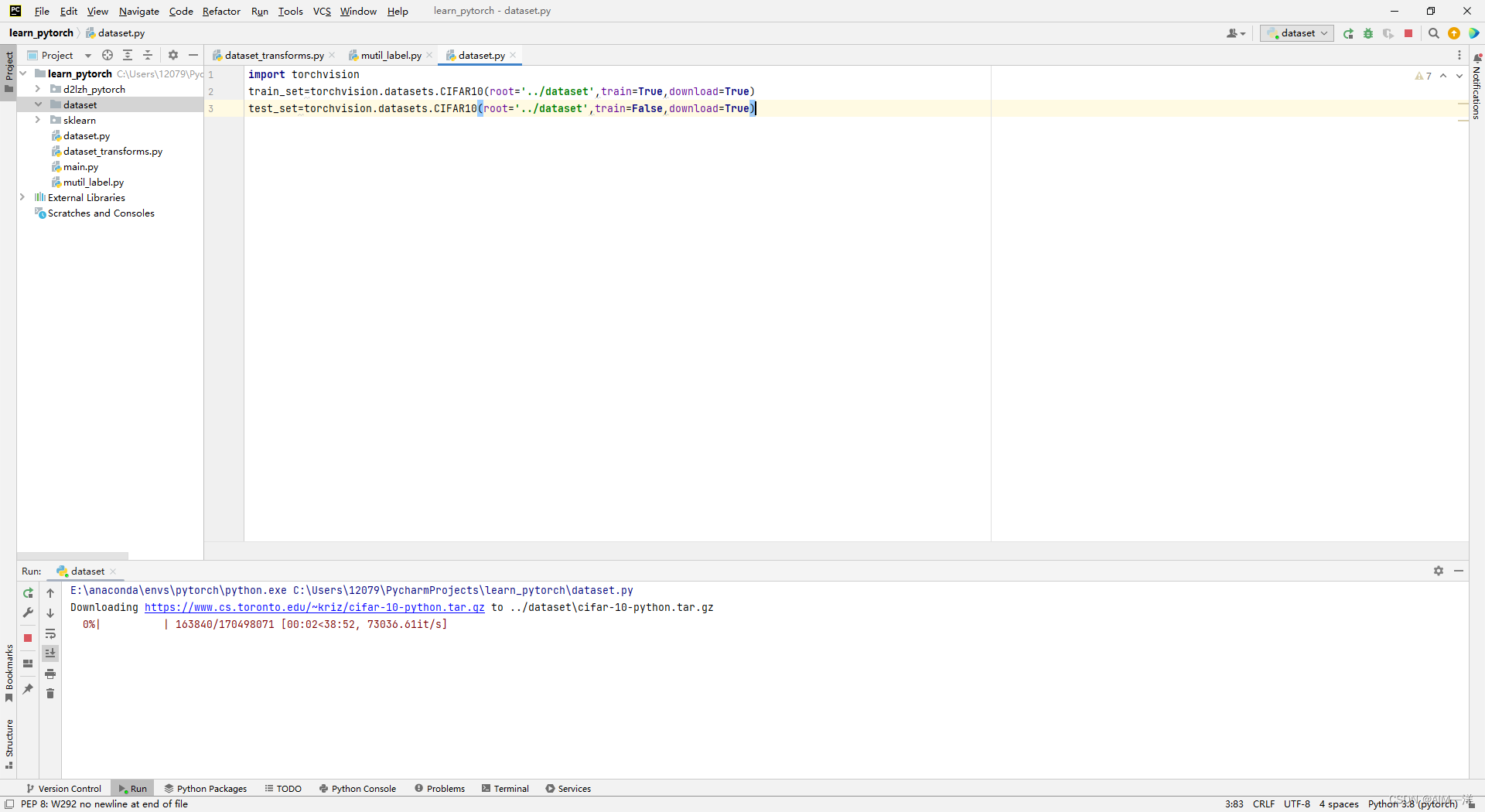
也可以将网址复制下来后在迅雷等软件上下载,但是在导入的时候需要注意一点:导入的是解压前的文件,解压后再导入不仅读取不了,而且还会报错然后重新下载。
除了这个数据集之外,datasets还提供很多其他数据集。
2.dataloader
首先了解官方文档的描述。
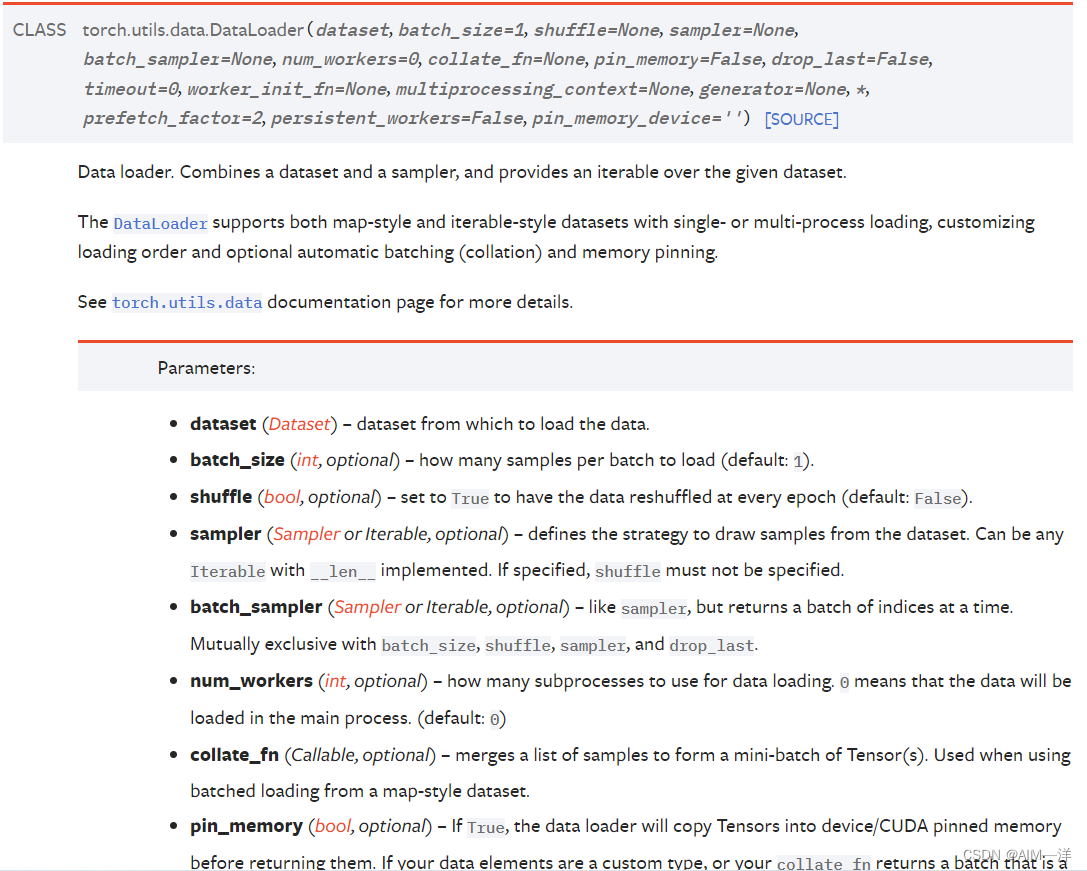
dataset: 这里就是指将要进行操作的数据集,也可以直接使用上面dataset下载好的数据集进行使用。
batch_size :这里指每次操作的数据个数,每次下载两个或者多个等都可以进行设置,默认情况为1
shuffle;指打乱的意思将数据进行打乱
num_workers:指使用多进程还是单进程,多进程自然会比较快
import torchvision
from torch.utils.data import DataLoader
test_set=torchvision.datasets.CIFAR10(root='./datasets',train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
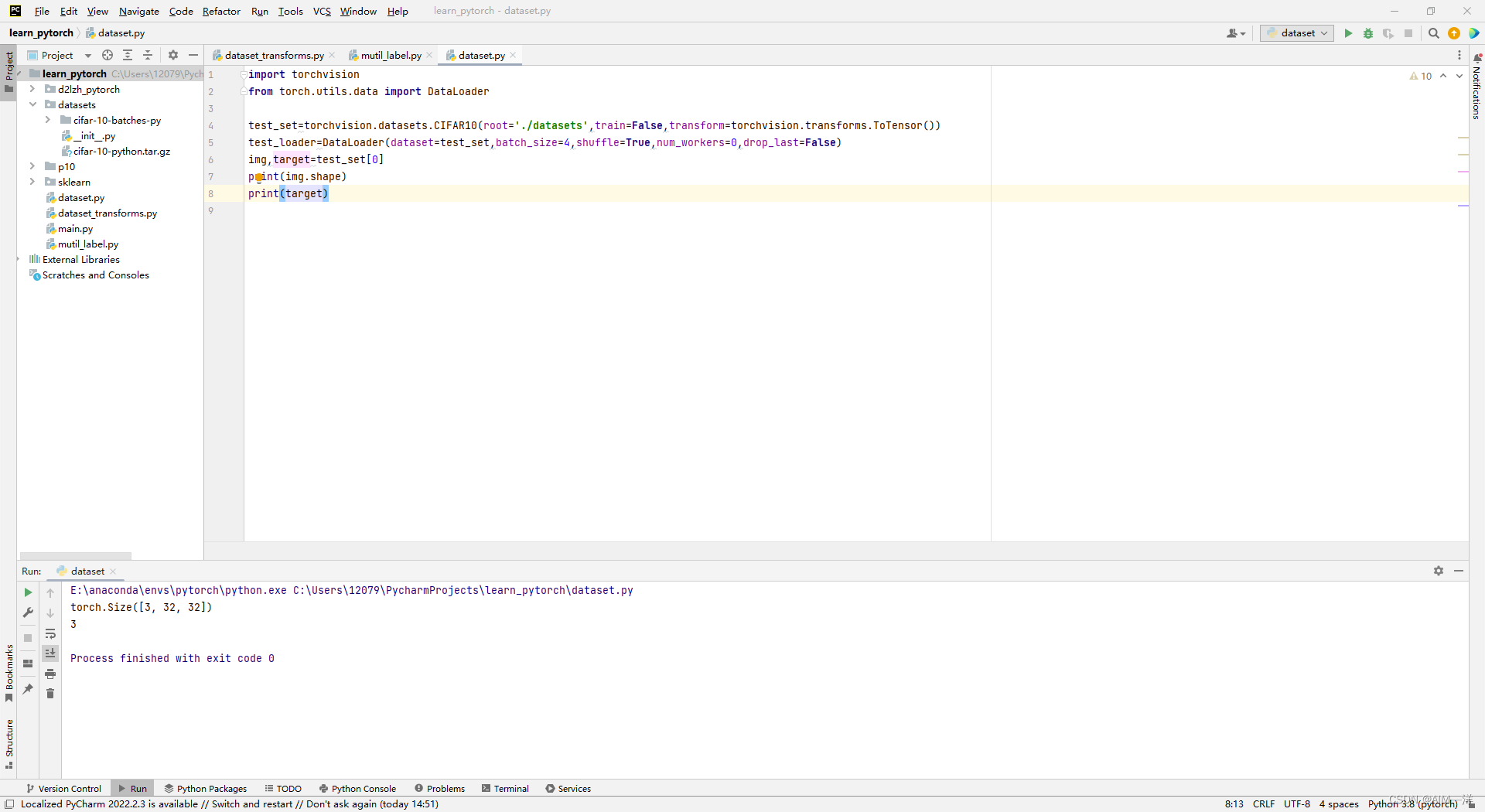
img,target=test_set[0]
print(img.shape)
print(target)
我们使用for循环来对data_loader中的数据进行抓取。
import torchvision
from torch.utils.data import DataLoader
test_set=torchvision.datasets.CIFAR10(root='./datasets',train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
img,target=test_set[0]
print(img.shape)
print(target)
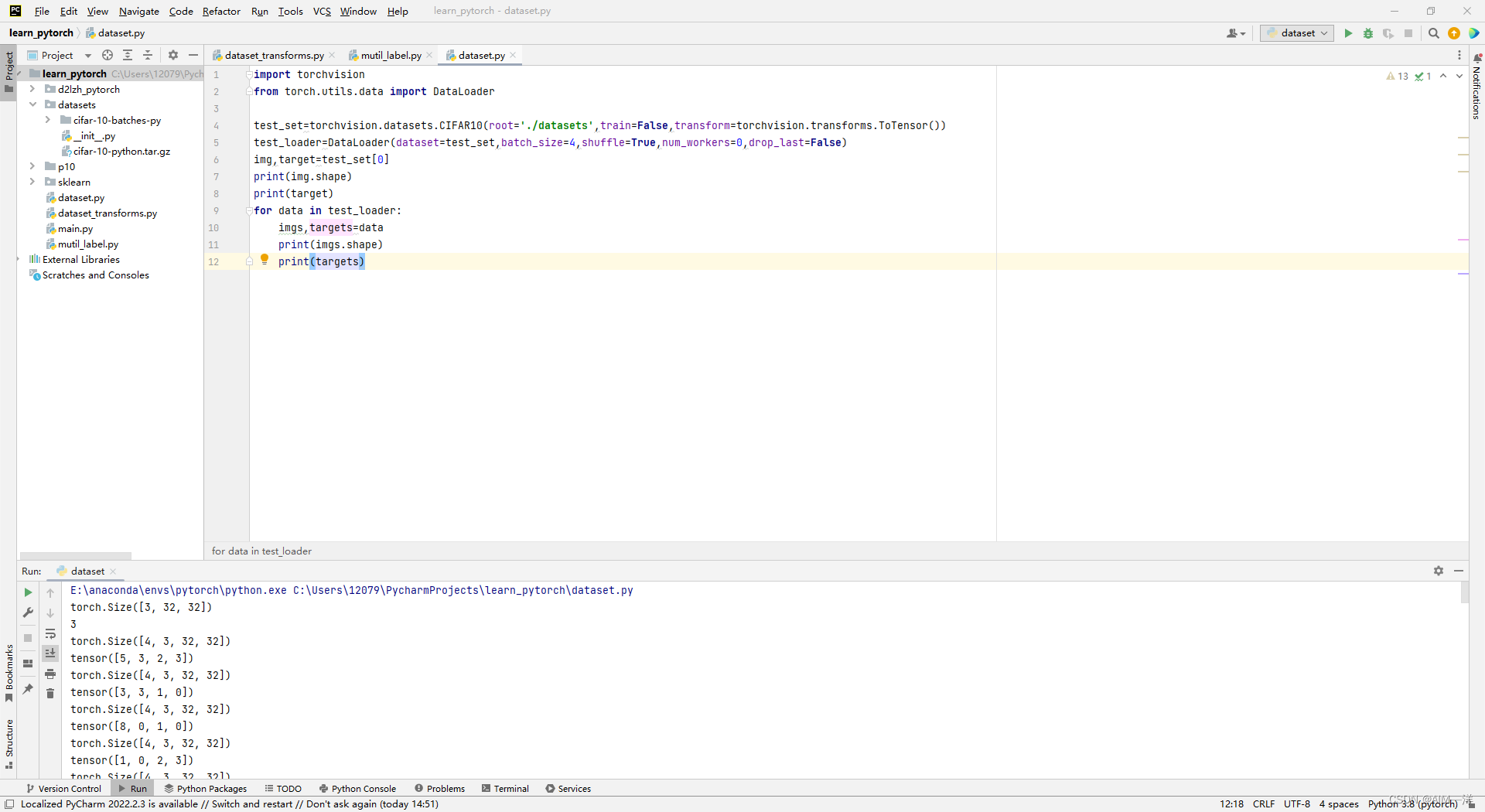
for data in test_loader:
imgs,targets=data
print(imgs.shape)
print(targets)
这里需注意,没轮抓取的size是一样的,但是由于shuffle设定为True,所以每次抓取的图片是随机不一样的。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_set=torchvision.datasets.CIFAR10(root='./datasets',train=False,transform=torchvision.transforms.ToTensor())
test_loader=DataLoader(dataset=test_set,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
img,target=test_set[0]
print(img.shape)
print(target)
writer = SummaryWriter("666")
step=0
for data in test_loader:
imgs,targets=data
#print(imgs.shape)
#print(targets)
writer.add_images("test_set",imgs,step)
step+=1
writer.close()

![[附源码]SSM计算机毕业设计大学生心理咨询网站JAVA](https://img-blog.csdnimg.cn/b4deb26816494d94a23a55cdf97cb6ac.png)