摘要
背景:
基于GAN的融合方法存在训练不稳定,提取图像的局部和全局上下文语义信息能力不足,交互融合程度不够等问题
贡献:
提出双耦合交互式融合GAN(Dual-Coupled Interactive Fusion GAN,DCIF-GAN):
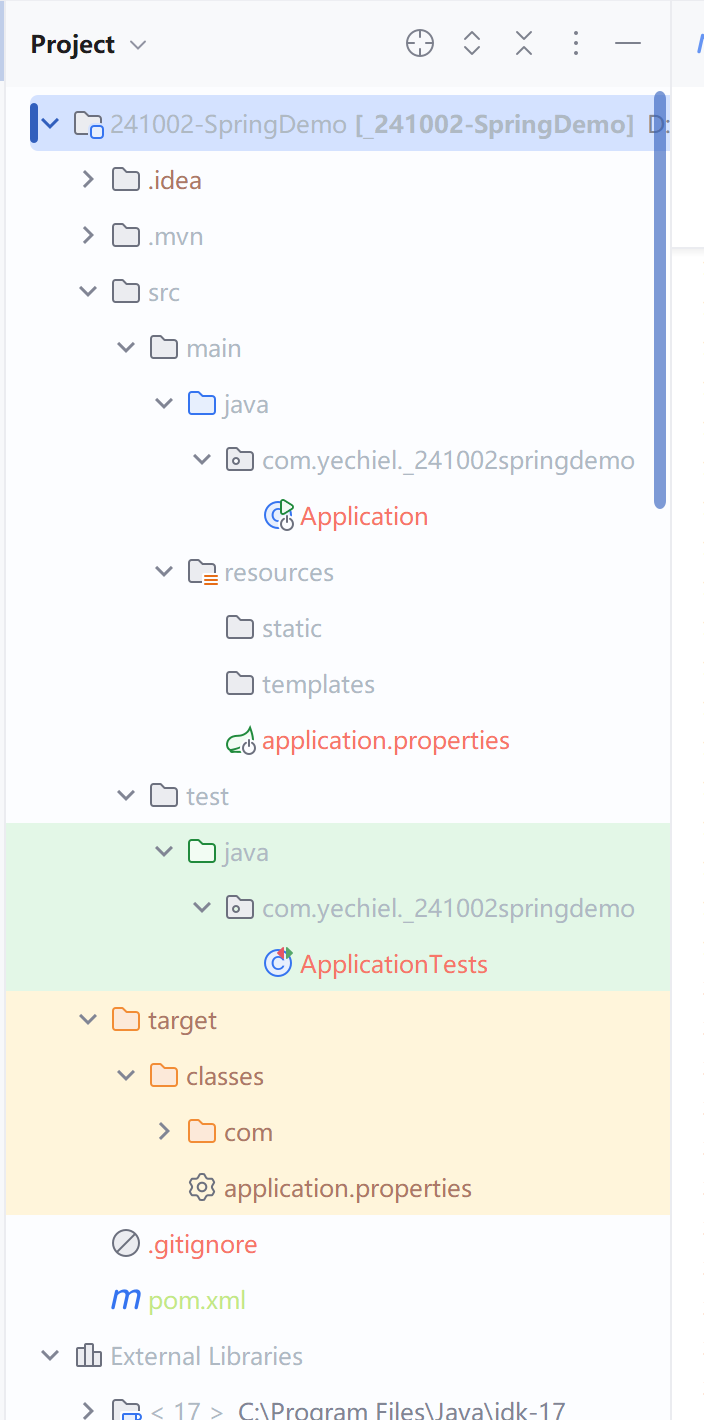
- 设计了双生成器双鉴别器GAN,通过权值共享机制实现生成器之间和鉴别器之间的耦合,通过全局自注意力机制实现交互式融合;
- 设计耦合CNN-Transformer的特征提取模块(Coupled CNN-T ransformer Feature Extraction Module, CC-TFEM)和特征重构模块(CNN-T ransformer F eature Reconstruction Module, C-TFRM),提升了对同一模态图像内部的局部和全局特征信息提取能力;
- 设计跨模态交互式融合模块(Cross Model Intermodal Fusion Module, CMIFM),通过跨模态自注意力机制,进一步整合不同模态间的全局交互信息。
结果:
在肺部肿瘤PET/CT医学图像数据集上进行实验,模型能够突出病变区域信息,融合图像结构清晰且纹理细节丰富。
1. 引言
-
CT——结构信息,分辨率高
-
PET——功能信息
-
传统:Fusion GAN、FLGC-Fusion GAN
-
双判别器:D2WGAN、DDcGAN、DFPGAN
-
多生成器多判别器:MGMDcGAN、RCGAN
贡献:
- 提出跨模态耦合生成器,处理PET图像中的病灶目标和CT图像中丰富的纹理特征,学习跨模态图像之间的联合分布;提出跨模态耦合鉴别器分别用于计算预融合图像与CT和PET图像间的结构差异,并使训练过程更加稳定。
- 设计耦合CNN-Transformer特征提取模块和CNN-Transformer特征重构模块,结合了Transformer和CNN的优势,在挖掘源图像中局部信息的同时也能学习特征之间的全局交互信息,实现更好的跨模态互补语义信息集成。
- 提出基于SwinTransformer的跨模态交互式融合模块,通过跨模态自注意力机制,可以进一步整合不同模态图像之间的全局交互信息。
2. 双耦合交互式融合DCIF-GAN
2.1 整体网络结构
网络结构:
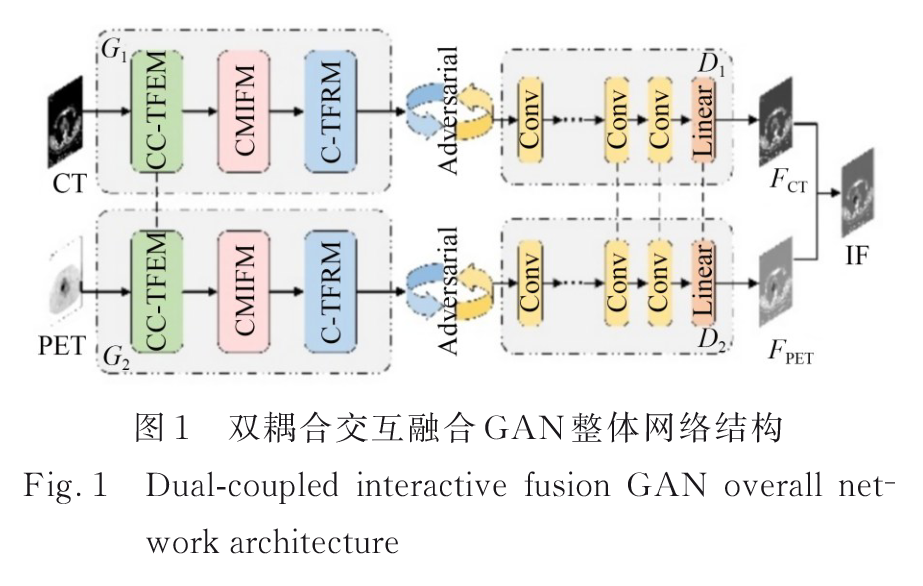
生成器由基于耦合CNN-Transformer的特征提取模块、跨模态与融合模块和基于联合CNN-Transformer的特征重构模块构成。
鉴别器由四个卷积块和一个Linear层构成,鉴别器的“耦合”通过网络最后几层共享权值,此操作可以有效降低网络的参数量。
关键:权值共享
第一生成器G1的目的是生成具有CT图像纹理信息的预融合图像FCT,
第一鉴别器D1的目的是计算FCT与源PET图像的相对偏移量并反馈,以增强FCT中的功能信息;
第二生成器G2用于生成具有PET图像功能信息的预融合图像FPET,
第二鉴别器D2计算FPET与源CT图像的相对偏移量并反馈,以增强FPET中的纹理信息。
随着迭代次数的增加,两个生成器都可以生成足以欺骗鉴别器的预融合图像,生成的图像分别会相对偏向于其中一幅源图像,故将生成的两幅预融合图像进行加权融合,得到最终的融合图像IF。
网络的极大极小博弈可以表示为:
min
G
1
,
G
2
max
D
1
,
D
2
L
(
G
1
,
G
2
,
D
1
,
D
2
)
=
E
I
P
E
T
[
log
D
1
(
I
P
E
T
)
]
+
E
I
C
T
[
log
(
1
−
D
1
(
G
1
(
I
C
T
)
)
)
]
+
E
I
C
T
[
log
D
2
(
I
C
T
)
]
+
E
I
P
E
T
[
log
(
1
−
D
2
(
G
2
(
I
P
E
T
)
)
)
]
\begin{aligned} \min_{G_1, G_2} \max_{D_1, D_2} L(G_1, G_2, D_1, D_2) = \mathbb{E}_{I_{PET}} \left[ \log D_1(I_{PET}) \right] + \mathbb{E}_{I_{CT}} \left[ \log (1 - D_1(G_1(I_{CT}))) \right] + \mathbb{E}_{I_{CT}} \left[ \log D_2(I_{CT}) \right] + \mathbb{E}_{I_{PET}} \left[ \log (1 - D_2(G_2(I_{PET}))) \right] \end{aligned}
G1,G2minD1,D2maxL(G1,G2,D1,D2)=EIPET[logD1(IPET)]+EICT[log(1−D1(G1(ICT)))]+EICT[logD2(ICT)]+EIPET[log(1−D2(G2(IPET)))]
2.2 耦合生成器结构
生成器网络结构:
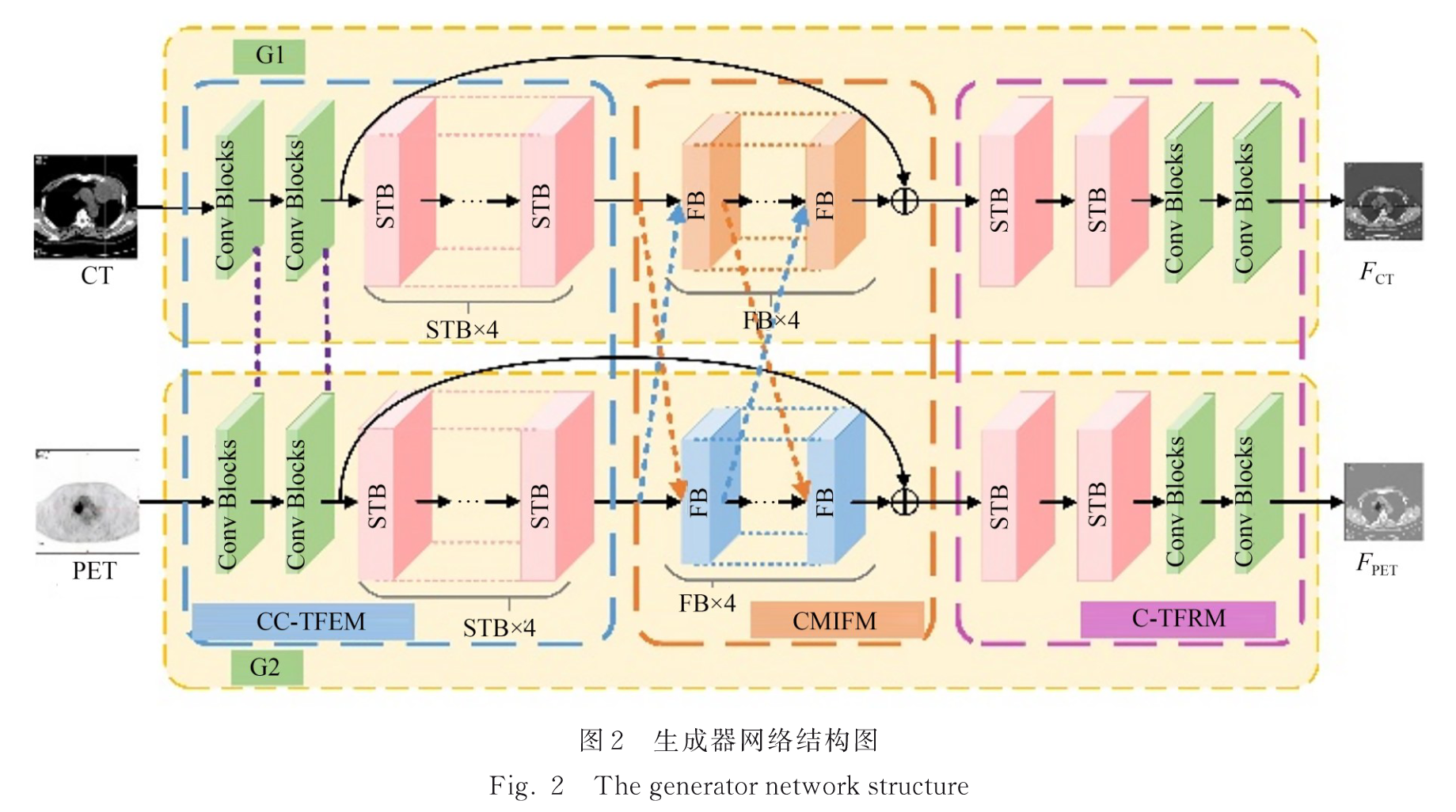
CNN能简单有效提取信息,但感受野有限,捕捉全局背景信息能力弱;
Transformer将整个图像转换为一维向量组输入(解决感受野有限),使用自注意力捕获全局信息(解决只提取局部信息),但全局信息的秩低,降低了前景和背景的可辨别性,融合不明显。
2.2.1 耦合CNN-Transformer特征提取模块(CC-TFEM)
基于CNN的浅层特征提取,局部特征;
基于Swin-Transformer的深层特征提取,全局特征。
2个卷积块+4个STB块
卷积块:一个卷积层(size=3, stride=1)+一个Leaky ReLU层
两个生成器权值共享:
- 有助于学习多模态图像的联合分布;
- 减少参数量。
通过浅层特征提取模块HSE(.)提取源图像
I
C
T
I_{CT}
ICT和
I
P
E
T
I_{PET}
IPET的浅层特征
F
S
F
C
T
F^{CT}_{SF}
FSFCT和
F
S
F
P
E
T
F^{PET}_{SF}
FSFPET;
通过深度特征提取模块HDE(.)从
F
S
F
C
T
F^{CT}_{SF}
FSFCT和
F
S
F
P
E
T
F^{PET}_{SF}
FSFPET中提取深度特征;
将
F
D
F
C
T
F^{CT}_{DF}
FDFCT和
F
D
F
P
E
T
F^{PET}_{DF}
FDFPET输人到跨模态预融合模块(CMIFM)中进行融合。
表述为:
[
F
S
F
C
T
,
F
S
F
P
E
T
]
=
[
H
S
E
(
I
C
T
)
,
H
S
E
(
I
P
E
T
)
]
\begin{bmatrix} F^{CT}_{SF} , F^{PET}_{SF} \end{bmatrix} = \begin{bmatrix} H_{SE}(I_{CT}) , H_{SE}(I_{PET}) \end{bmatrix}
[FSFCT,FSFPET]=[HSE(ICT),HSE(IPET)]
[
F
D
F
C
T
,
F
D
F
P
E
T
]
=
[
H
D
E
(
F
S
F
C
T
)
,
H
D
E
(
F
S
F
P
E
T
)
]
\begin{bmatrix} F^{CT}_{DF} , F^{PET}_{DF} \end{bmatrix} = \begin{bmatrix} H_{DE}(F^{CT}_{SF}) , H_{DE}(F^{PET}_{SF}) \end{bmatrix}
[FDFCT,FDFPET]=[HDE(FSFCT),HDE(FSFPET)]
特征提取模块:
Swin Transformer的局部注意力和窗口机制有效地降低了计算量。
W-MSA(Weighted Multi-Head Self-Attention)将输入特征
F
H
×
W
×
C
F^{H×W×C}
FH×W×C划分为不重叠的
M
×
M
M×M
M×M的局部窗口,重构为
H
W
M
2
×
M
2
×
C
\frac{HW}{M^2} \times M^2 \times C
M2HW×M2×C;每个窗口执行自注意力操作,局部窗口特征
X
∈
R
M
2
×
C
X \in \mathbb{R}^{M^2 \times C}
X∈RM2×C,经过三个线性变换矩阵
W
Q
∈
R
M
2
×
C
W^Q \in \mathbb{R}^{M^2 \times C}
WQ∈RM2×C,
W
K
∈
R
M
2
×
C
W^K \in \mathbb{R}^{M^2 \times C}
WK∈RM2×C,
W
V
∈
R
M
2
×
C
W^V \in \mathbb{R}^{M^2 \times C}
WV∈RM2×C投影到Q,K,V:
[
Q
,
K
,
V
]
=
[
X
W
Q
,
X
W
K
,
X
W
V
]
[Q, K, V] = [XW^Q, XW^K, XW^V]
[Q,K,V]=[XWQ,XWK,XWV]
注意力权重为:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
+
B
)
V
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + B\right)V
Attention(Q,K,V)=softmax(dkQKT+B)V
d
k
d_k
dk是建的维数,B是相对位置编码。
多头自注意力并行执行h次注意函数,并将每个注意力头的结果连接起来。
通过由两个多层感知器(MLP)层组成的前馈网络(Feed Forward Network, FFN)来细化W-MSA产生的特征向量,表述为:
Z
~
l
=
MSA
(
LN
(
Z
l
−
1
)
)
+
Z
l
−
1
\tilde{Z}^l = \text{MSA}(\text{LN}(Z^{l-1})) + Z^{l-1}
Z~l=MSA(LN(Zl−1))+Zl−1
Z
l
=
FFN
(
LN
(
Z
~
l
)
)
+
Z
~
l
\quad Z^l = \text{FFN}(\text{LN}(\tilde{Z}^l)) + \tilde{Z}^l
Zl=FFN(LN(Z~l))+Z~l
前馈网络FNN(∙),表述为:
F
F
N
(
X
)
=
G
E
L
U
(
W
1
+
b
1
)
W
2
+
b
2
FFN ( X ) = GELU (W_1 + b_1 ) W_2 + b_2
FFN(X)=GELU(W1+b1)W2+b2
GELU为高斯误差线性单元。

Swin Transformer 层计算注意力的滑动窗口机制,W-MSA的弊端在于窗口之间的相互作用较弱,引人SW-MSA模块,向左上方向循环移动,产生新的批窗口。
2.2.2 跨模态交互式融合模块(CMIFM)
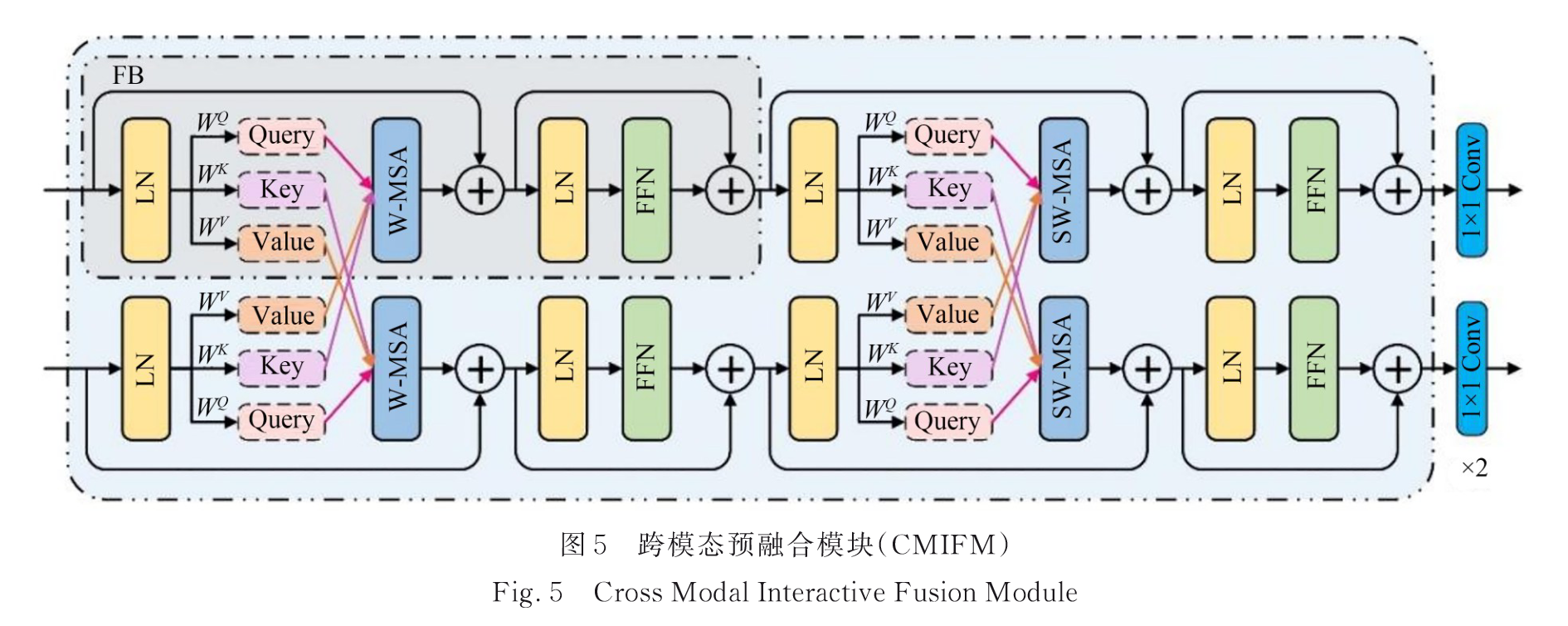
4个融合块(FB)
通过自注意力将特征图映射到Q、K、V,通过跨模态自注意力交换K、V,实现全局特征融合。
其余小块类似2.2.1。
跨模态融合单元的过程定义为:
[
Q
1
,
K
1
,
V
1
]
=
[
X
1
W
1
Q
,
X
1
W
1
K
,
X
1
W
1
V
]
[
Q
2
,
K
2
,
V
2
]
=
[
X
2
W
2
Q
,
X
2
W
2
K
,
X
2
W
2
V
]
Attention
1
(
Q
1
,
K
2
,
V
2
)
=
softmax
(
Q
1
K
2
T
d
k
+
B
)
V
2
Attention
2
(
Q
2
,
K
1
,
V
1
)
=
softmax
(
Q
2
K
1
T
d
k
+
B
)
V
1
Z
~
1
l
=
W
−
MSA
(
LN
(
Z
1
l
−
1
)
)
+
Z
1
l
−
1
Z
~
2
l
=
W
−
MSA
(
LN
(
Z
2
l
−
1
)
)
+
Z
2
l
−
1
Z
1
l
=
FFN
(
LN
(
Z
~
1
l
)
)
+
Z
~
1
l
Z
2
l
=
FFN
(
LN
(
Z
~
2
l
)
)
+
Z
~
2
l
\begin{align*} [Q_1, K_1, V_1] &= [X_1 W_{1}^{Q}, X_1 W_{1}^{K}, X_1 W_{1}^{V}] \\ [Q_2, K_2, V_2] &= [X_2 W_{2}^{Q}, X_2 W_{2}^{K}, X_2 W_{2}^{V}] \\ \text{Attention}_1(Q_1, K_2, V_2) &= \text{softmax}\left(\frac{Q_1 K_2^T}{\sqrt{d_k}} + B\right)V_2 \\ \text{Attention}_2(Q_2, K_1, V_1) &= \text{softmax}\left(\frac{Q_2 K_1^T}{\sqrt{d_k}} + B\right)V_1 \\ \tilde{Z}^l_1 &= W - \text{MSA}(\text{LN}(Z^{l-1}_1)) + Z^{l-1}_1 \\ \tilde{Z}^l_2 &= W - \text{MSA}(\text{LN}(Z^{l-1}_2)) + Z^{l-1}_2 \\ Z^l_1 &= \text{FFN}(\text{LN}(\tilde{Z}^l_1)) + \tilde{Z}^l_1 \\ Z^l_2 &= \text{FFN}(\text{LN}(\tilde{Z}^l_2)) + \tilde{Z}^l_2 \end{align*}
[Q1,K1,V1][Q2,K2,V2]Attention1(Q1,K2,V2)Attention2(Q2,K1,V1)Z~1lZ~2lZ1lZ2l=[X1W1Q,X1W1K,X1W1V]=[X2W2Q,X2W2K,X2W2V]=softmax(dkQ1K2T+B)V2=softmax(dkQ2K1T+B)V1=W−MSA(LN(Z1l−1))+Z1l−1=W−MSA(LN(Z2l−1))+Z2l−1=FFN(LN(Z~1l))+Z~1l=FFN(LN(Z~2l))+Z~2l
对于 CT 域中的 Q1,它通过对 PET 域中的 K2和 V2进行注意力加权来整合跨模态信息,同时通过残差连接保留 CT 域中的信息,PET 域中同理。
F
DF
CT
=
H
conv1
(
F
A
F
C
T
)
F^{\text{CT}}_{\text{DF}} = H_{\text{conv1}}(F^{CT}_{AF})
FDFCT=Hconv1(FAFCT)
F
DF
PET
=
H
conv2
(
F
A
F
PET
)
F^{\text{PET}}_{\text{DF}} = H_{\text{conv2}}(F^{\text{PET}}_{AF})
FDFPET=Hconv2(FAFPET)
F
A
F
C
T
F^{CT}_{AF}
FAFCT和
F
A
F
PET
F^{\text{PET}}_{AF}
FAFPET表示CMIFM以
F
D
F
C
T
F^{CT}_{DF}
FDFCT和
F
D
F
PET
F^{\text{PET}}_{DF}
FDFPET为输入而融合输出的特征;
H
conv
H_{\text{conv}}
Hconv表示具有空间不变滤波器的卷积层;
F
A
F
C
T
F^{CT}_{AF}
FAFCT和
F
A
F
PET
F^{\text{PET}}_{AF}
FAFPET表示融合的 CT 图像和 PET 图像的深度特征。
2.2.3 CNN-Transformer 特征重构模块(CTFRM)
2个STB块+2个卷积块(size=3, stride=1)+Leaky ReLU
生成预融合的图像
表述为:
F
F
S
F
C
T
=
H
D
R
(
F
F
D
F
C
T
+
F
S
F
C
T
)
F^{CT}_{FSF} = H_{DR}(F^{CT}_{FDF} + F^{CT}_{SF})
FFSFCT=HDR(FFDFCT+FSFCT)
F
F
S
F
P
E
T
=
H
D
R
(
F
F
D
F
P
E
T
+
F
S
F
P
E
T
)
F^{PET}_{FSF} = H_{DR}(F^{PET}_{FDF} + F^{PET}_{SF})
FFSFPET=HDR(FFDFPET+FSFPET)
F
C
T
=
H
S
R
(
F
F
S
F
C
T
)
F^{CT} = H_{SR}(F^{CT}_{FSF})
FCT=HSR(FFSFCT)
F
P
E
T
=
H
S
R
(
F
F
S
F
P
E
T
)
F^{PET} = H_{SR}(F^{PET}_{FSF})
FPET=HSR(FFSFPET)
H
D
R
H_{DR}
HDR是STB块的深度特征重构单元;
H
S
R
H_{SR}
HSR是基于CNN的浅层重构单元。
2.2.4 损失函数
以第一生成器为例:
G1总损失:
L
G
1
=
Φ
(
G
1
)
+
α
L
content
1
L_{G1} = \Phi(G_1) + \alpha L_{\text{content}1}
LG1=Φ(G1)+αLcontent1
Φ
(
G
1
)
\Phi(G_1)
Φ(G1)表示对抗损失,
L
c
o
n
t
e
n
t
1
L_{content1}
Lcontent1表示G1从源图像到预融合图像的损失,
α
\alpha
α表示控制源PET图像信息含量比例。
Φ
(
G
1
)
\Phi(G_1)
Φ(G1)对抗损失:
Φ
(
G
1
)
=
1
N
∑
n
=
1
N
(
D
1
(
F
C
T
n
,
I
P
E
T
n
)
−
I
P
E
T
n
)
2
\Phi(G_1) = \frac{1}{N} \sum_{n=1}^{N} \left( D_1(F^n_{CT}, I^n_{PET}) - I^n_{PET} \right)^2
Φ(G1)=N1n=1∑N(D1(FCTn,IPETn)−IPETn)2
L
c
o
n
t
e
n
t
1
L_{content1}
Lcontent1内容损失:
L
content
1
=
L
int
(
C
T
)
+
μ
L
ssim
(
C
T
)
L_{\text{content}1} = L_{\text{int}(CT)} + \mu L_{\text{ssim}(CT)}
Lcontent1=Lint(CT)+μLssim(CT)
L
i
n
t
L_{int}
Lint 和
L
s
s
i
m
L_{ssim}
Lssim 表示强度损失函数和结构相似度损失函数,μ 表示正则化参数。
第二生成器同理。
2.3 耦合鉴别器结构
不仅要考虑生成器和鉴别器之间的对抗关系,还要考虑两个鉴别器之间的平衡。
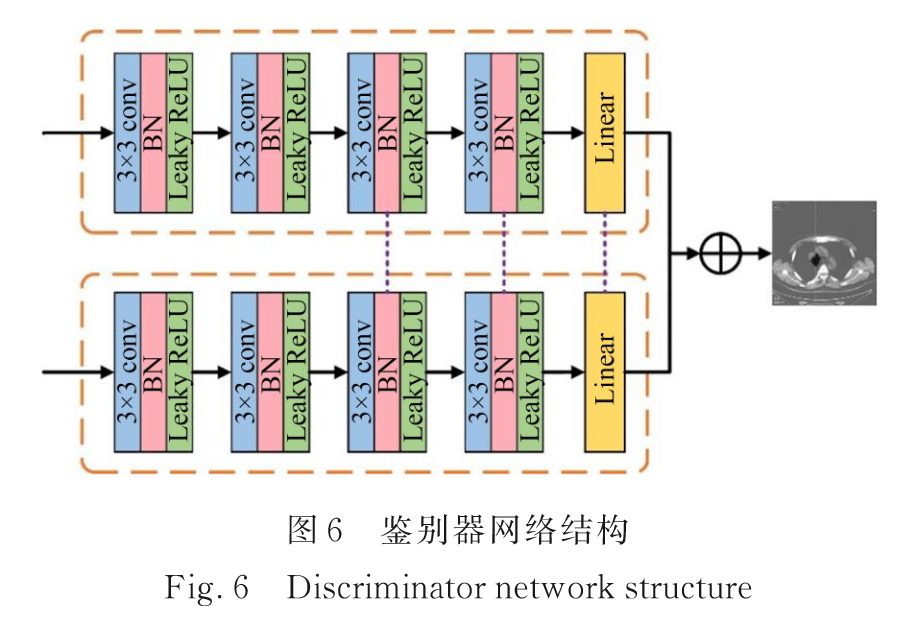
4个卷积块+1个线性层
卷积块:1个卷积层(size=3, stride=2, channel=32, 64, 128, 256)+1个BN层+1个Leaky ReLU层。
线性层:将特征图转化为输出,表示融合图像与相应源图像之间的相对距离。
鉴别器中第三、第四卷积块和线性层的共享权值。
以第一鉴别器为例:
D1的目的是通过损失函数使第一个预融合图像
F
C
T
F_{CT}
FCT逼近源PET图像:
D1的损失函数表示为:
L
1
=
D
1
(
I
P
E
T
,
F
C
T
)
L_1 = D_1(I_{PET}, F_{CT})
L1=D1(IPET,FCT)
D1的函数表示为:
D
1
(
I
P
E
T
,
F
C
T
)
=
C
1
(
I
P
E
T
)
−
E
F
C
T
(
C
1
(
F
C
T
)
)
D_1(I_{PET}, F_{CT}) = C_1(I_{PET}) - E_{F_{CT}}(C_1(F_{CT}))
D1(IPET,FCT)=C1(IPET)−EFCT(C1(FCT))
E是期望输出值,C1表示第一鉴别器的非线性变换。
跨模态耦合鉴别器允许单个生成的图像具有相反图像的信息。但所得到的图像仍有一定程度的偏置,因此将生成的两幅图像进行平均,得到最终的融合结果F为:
F
=
0.5
×
(
F
C
T
+
F
P
E
T
)
F = 0.5 \times (F_{CT} + F_{PET})
F=0.5×(FCT+FPET)
3. 实验结果与分析
3.1 实验设置
数据集:1000 组已配准的肺部肿瘤PET和CT影像。
图像大小:356 pixel×356 pixel
将原始 RGB 三通道图像转换为灰度图像。
按照 6∶2∶2 比例划分为训练集、验证集和测试集。
lr=0.0001, epoch=1000, batch=4
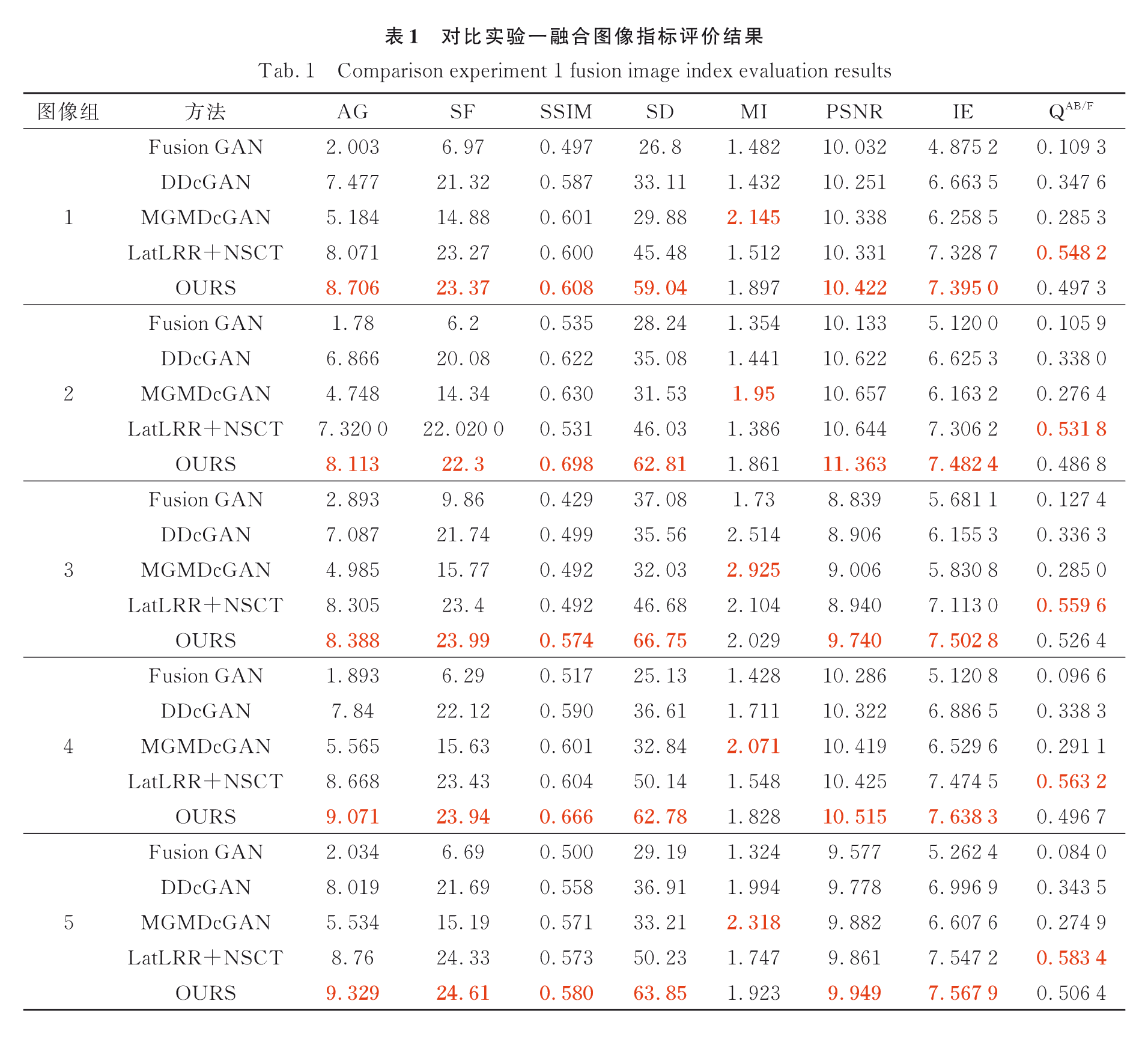
评价指标:AG、SF、SSIM、SD、MI、PSNR、IE、 Q A B / F Q^{AB/F} QAB/F
3.2 对比试验
3.2.1 实验一:PET/CT肺窗
实验一图像融合结果:
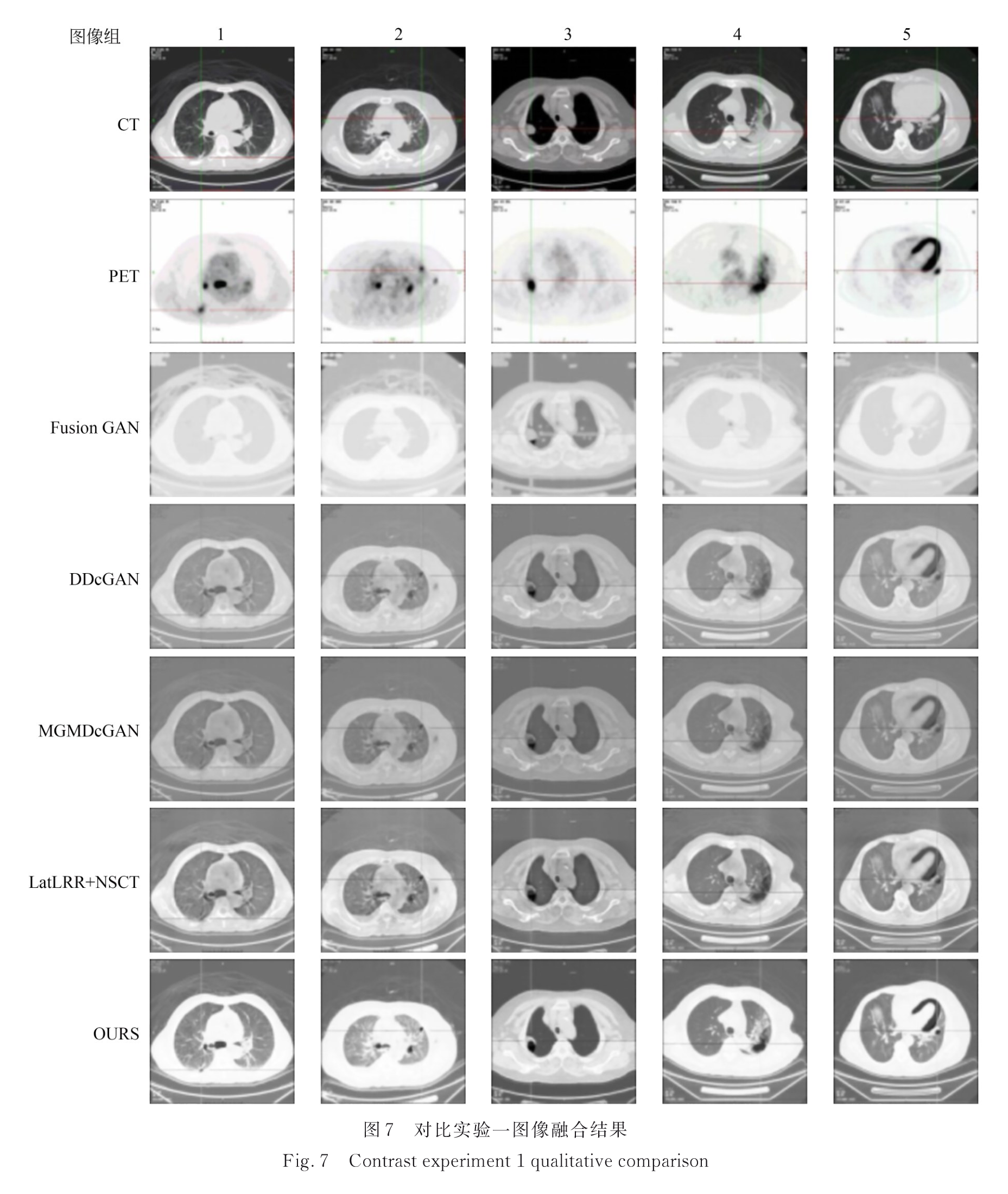
实验一图像融合结果评价:
3.2.2 实验二:PET/CT纵膈窗
实验一图像融合结果:
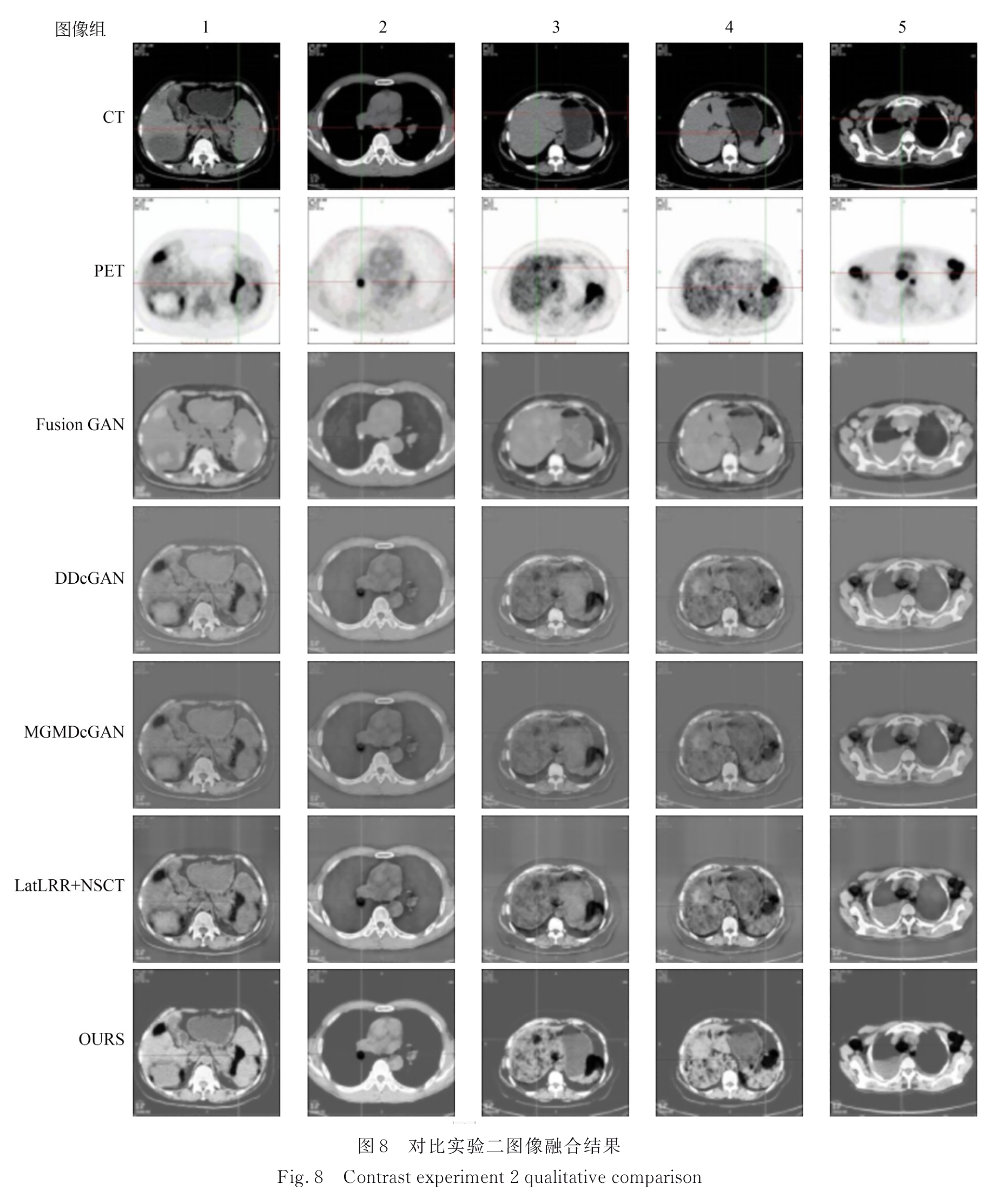
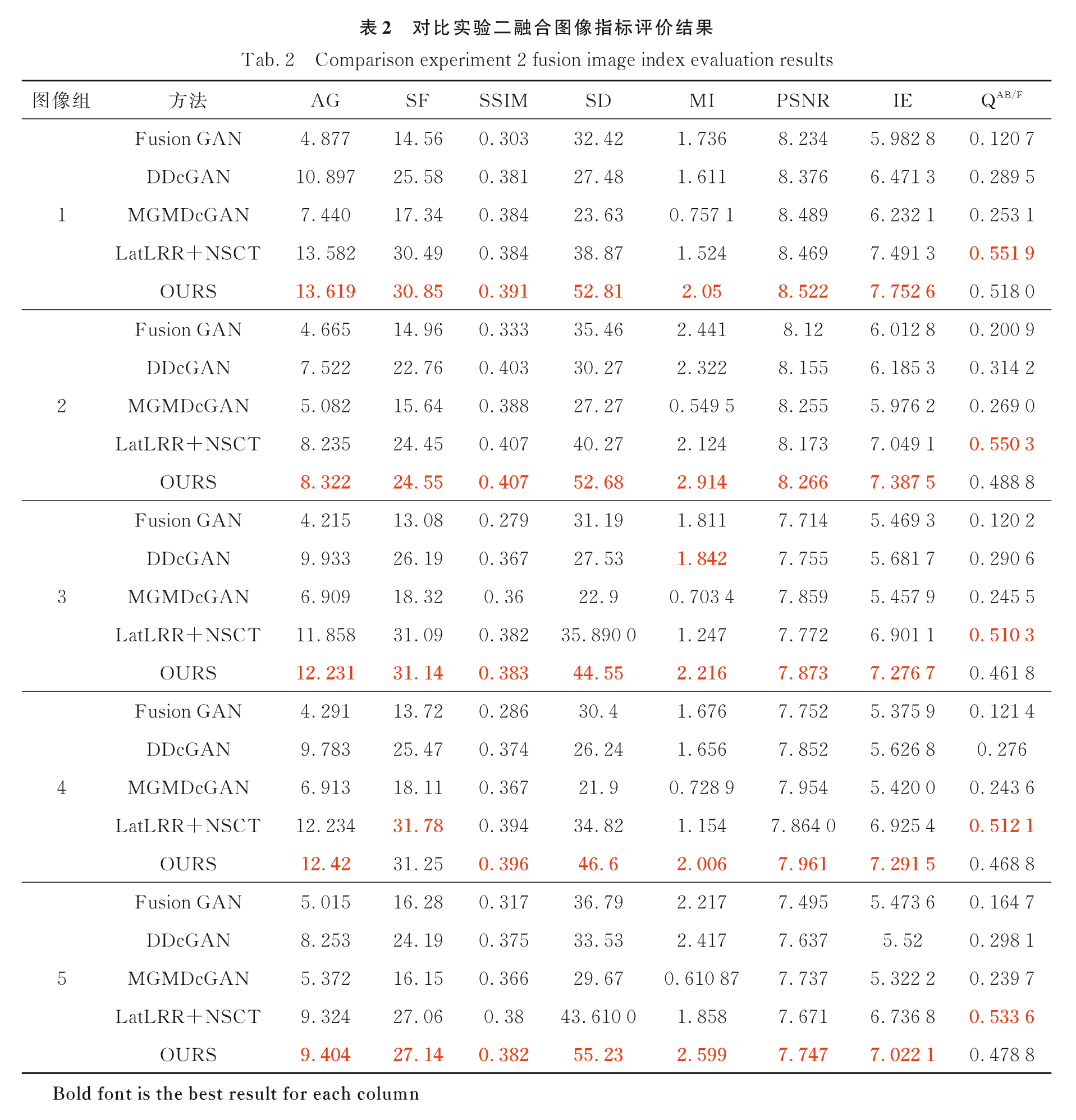
实验一图像融合结果评价:
3.3 消融实验
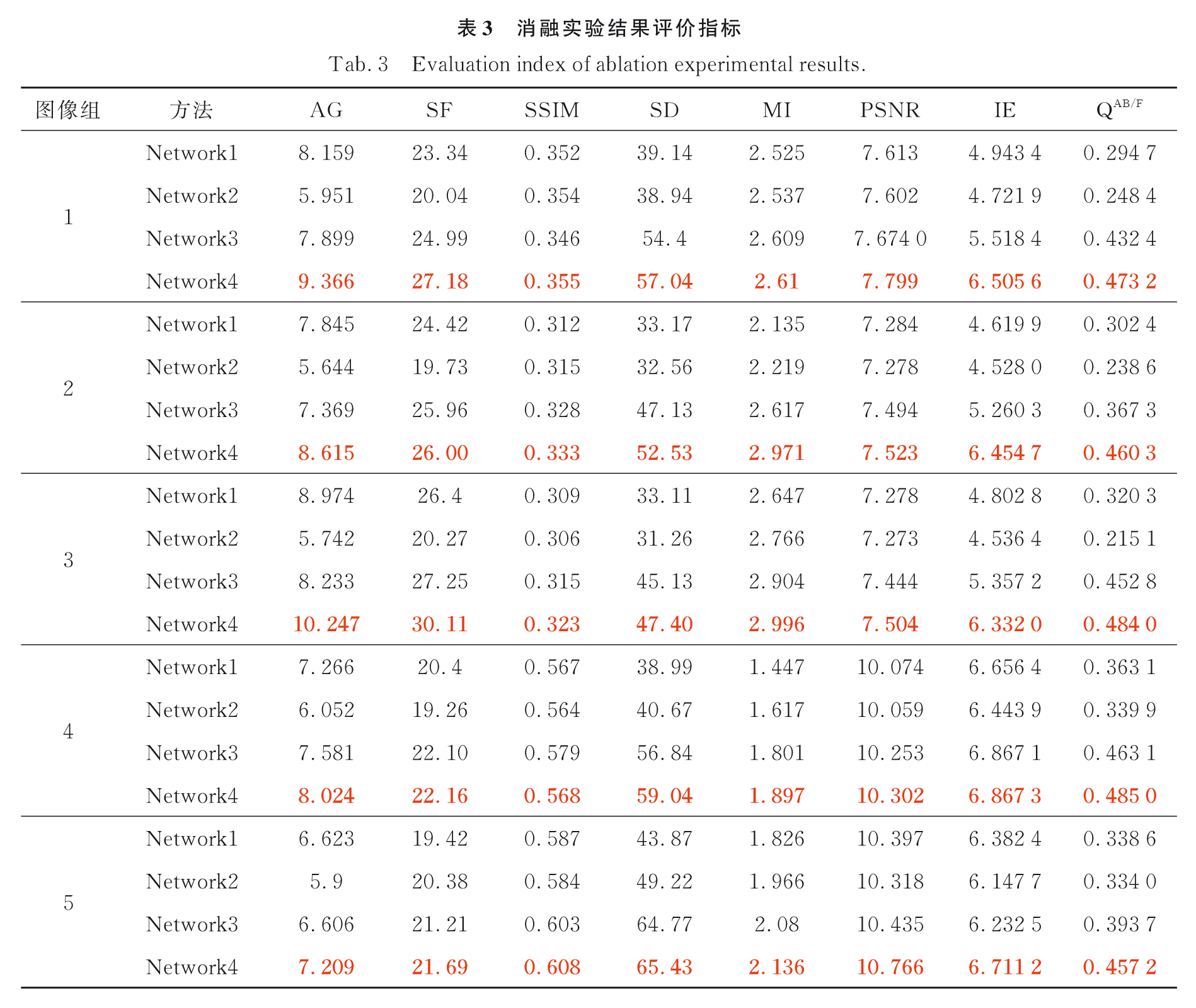
Network1:单生成器单鉴别器GAN
Network2:跨模态耦合生成器和跨模态耦合鉴别器
Network3:耦合 CNN-Transformer 特征提取模块
Network4:跨模态特征融合模块
消融实验结果:
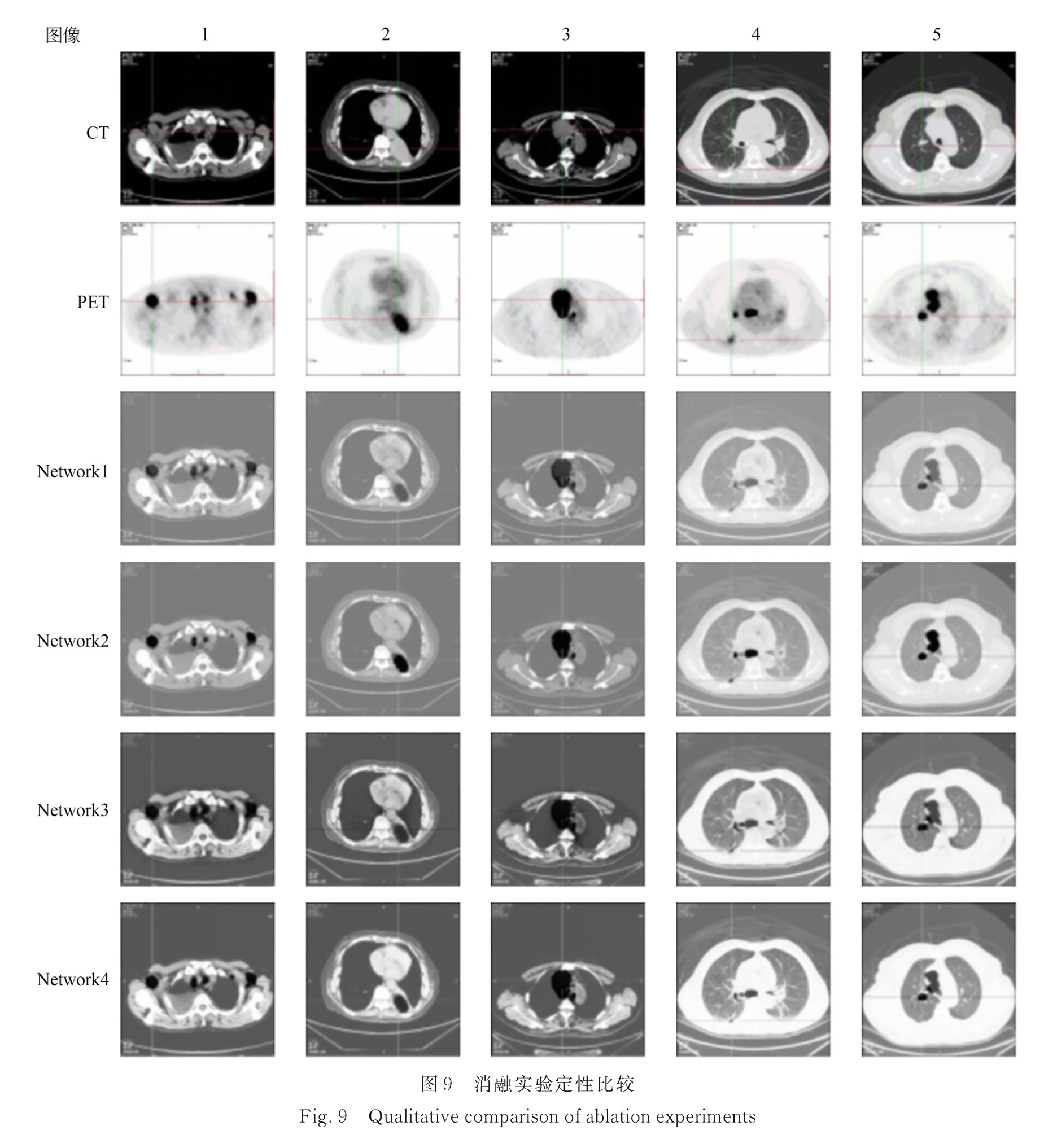
消融实验结果评价:
4. 结论
本文模型得到的融合图像符合人类视觉感知,能够较好地融合 PET 图像中的病灶信息和 CT 图像中的纹理信息,有助于医生更快速、更精准地定位肺部肿瘤在解剖结构中的位置。












![[VULFOCUS刷题]tomcat-pass-getshell 弱口令](https://img-blog.csdnimg.cn/img_convert/b27ad7212a08660546f55c935253f942.png)