JVM
JVM中有哪些引用
在Java中,引用(Reference)是指向对象的一个变量。Java中的引用不仅仅有常规的直接引用,还有不同类型的引用,用于控制垃圾回收(GC)的行为和优化性能。JVM中有四种引用类型,它们分别是:
-
强引用(Strong Reference)
-
软引用(Soft Reference)
-
弱引用(Weak Reference)
-
虚引用(Phantom Reference)
这些引用的不同之处在于它们在垃圾回收(GC)中的生命周期和回收机制。
1. 强引用(Strong Reference)
强引用是最常见的引用类型,就是我们平时定义的普通对象引用。例如:
Object obj = new Object();
在这个例子中,obj 是 Object 类型的一个强引用。如果一个对象有强引用指向它,那么垃圾回收器永远不会回收这个对象,除非该引用被显式地置为 null。
特点:
-
强引用是最普通、最常用的引用类型。
-
如果一个对象具有强引用,垃圾回收器在 GC 时不会回收该对象。
-
即使对象没有任何其他引用,只要强引用存在,垃圾回收器不会回收它。
2. 软引用(Soft Reference)
软引用是用来描述那些在内存不足时可以被回收的对象。它通常用于缓存策略。软引用的对象只有在 JVM 内存不足时,才会被垃圾回收器回收。
软引用的创建方式通常通过 SoftReference 类:
SoftReference<Object> softRef = new SoftReference<>(new Object());
特点:
-
软引用所指向的对象,只有在内存不足的情况下,才会被垃圾回收器回收。
-
在内存充足的情况下,软引用的对象不会被回收,这使得它非常适合用作缓存。
-
如果系统内存充足,软引用的对象会一直存在,直到没有引用指向它或者程序结束。
3. 弱引用(Weak Reference)
弱引用与软引用类似,但弱引用所指向的对象在垃圾回收时会更早被回收,即使内存充足,也会在下一次 GC 时被回收。
弱引用的创建通常通过 WeakReference 类:
WeakReference<Object> weakRef = new WeakReference<>(new Object());
特点:
-
弱引用指向的对象在下一次垃圾回收时会被回收,无论内存是否充足。
-
适用于一些需要临时存在的对象,比如
ThreadLocal中使用的对象。 -
如果一个对象只被弱引用指向,那么该对象几乎可以在任何时刻被回收。
4. 虚引用(Phantom Reference)
虚引用是最弱的引用类型。虚引用所指向的对象在垃圾回收时无法被访问。虚引用的主要作用是为垃圾回收提供一种机制,在对象被回收时收到通知。
虚引用的创建通常通过 PhantomReference 类:
PhantomReference<Object> phantomRef = new PhantomReference<>(new Object(), new ReferenceQueue<>());
特点:
-
虚引用不提供对象的引用,无法通过虚引用访问对象的内容。
-
虚引用的主要用途是在对象被垃圾回收时进行清理工作(例如释放资源、记录日志等)。它常常与
ReferenceQueue配合使用。 -
对象一旦没有任何强引用、软引用或弱引用指向,垃圾回收器就会把它放入与虚引用关联的
ReferenceQueue中,从而让开发者能够进行一些清理操作。
引用与垃圾回收的关系
不同的引用类型在垃圾回收过程中的影响如下:
-
强引用:GC不会回收强引用指向的对象。
-
软引用:当系统内存足够时,垃圾回收器不会回收软引用指向的对象,但当内存紧张时,垃圾回收器会优先回收这些对象。
-
弱引用:无论内存是否紧张,垃圾回收器都会在下次GC时回收弱引用指向的对象。
-
虚引用:虚引用不会影响对象的生命周期。垃圾回收器回收对象时,会将其放入
ReferenceQueue,供程序进行清理。
引用的应用场景
-
强引用:普通的对象引用,大部分情况下使用的是强引用。
-
软引用:用于缓存。可以在内存不足时清理缓存,避免OOM(Out Of Memory)错误。例如,
java.util.WeakHashMap就是使用了软引用。 -
弱引用:用于一些临时的对象引用,例如
ThreadLocal的实现,它依赖于弱引用来确保线程局部变量的对象不会被无限持有。 -
虚引用:用于在对象被回收前进行某些清理工作,例如清理非堆内存、释放资源等。它是通过
ReferenceQueue来实现的,通常用在 JVM 内部的一些特殊场景中。
小结
-
强引用:最常见,不会被GC回收。
-
软引用:用于缓存,可以在内存不足时回收。
-
弱引用:用于临时对象,下一次GC时会回收。
-
虚引用:用于对象回收前的清理操作。
这些引用类型为 Java 提供了更加细致的内存管理控制,允许开发者根据不同的需求选择合适的引用方式,以优化内存使用和垃圾回收过程。
类加载器和双亲委派机制
类加载器(ClassLoader)
Java的类加载器(ClassLoader)是负责将类的字节码加载到JVM内存中的组件。类加载器的主要任务是从文件系统或网络中读取 .class 文件,并将其转化为内存中的 Class 对象,供JVM执行。
类加载器的类型
-
Bootstrap ClassLoader
这是最顶层的类加载器,负责加载 Java 核心库(rt.jar)中的类,比如java.lang.*、java.util.*等。它由C++实现,通常无法通过Java代码访问。 -
Extension ClassLoader
这个类加载器负责加载Java的扩展库(ext目录下的类)。比如,javax.*包的类就是由它加载的。它是Bootstrap ClassLoader的子类。 -
System ClassLoader
也称为应用程序类加载器,负责加载应用程序的类。它加载路径通常由CLASSPATH环境变量或启动时指定的-classpath参数决定。 -
Custom ClassLoader
Java也允许开发者创建自定义类加载器,继承自ClassLoader类,来实现特定的加载行为。例如,可以从网络、数据库或其他来源加载类。
类加载的过程
类加载的过程大致分为以下几个阶段:
-
加载(Loading)
将类的二进制数据从文件、网络等源加载到内存中。 -
连接(Linking)
包括三个步骤:-
验证(Verification):检查字节码的正确性,确保没有违反JVM规范。
-
准备(Preparation):为类变量分配内存并设置默认值。
-
解析(Resolution):将常量池中的符号引用解析为直接引用。
-
-
初始化(Initialization)
执行类的静态初始化块(static {})以及静态变量的初始化。
双亲委派机制(Parent Delegation Model)
Java类加载器的双亲委派机制是一种确保Java类加载的安全性和一致性的机制。它的核心思想是:每个类加载器在加载类之前,会先委托给其父类加载器来加载。这种委托链一直向上,直到最顶层的 Bootstrap ClassLoader。
双亲委派机制的工作原理
-
委派规则:每个类加载器都有一个父类加载器,所有的类加载请求都会先委托给父加载器去处理,直到父加载器尝试加载类。
-
加载过程:
-
假设有一个
ClassLoaderA加载类X,它首先会请求其父类加载器去加载该类。 -
如果父类加载器加载失败或类已经存在,它才会自己去加载类。
-
只有当父加载器无法加载类时,子加载器才会尝试加载该类。
这种机制避免了类加载的冲突问题,比如保证了核心类库(如
java.lang.String)的唯一性,不会因为加载器的不同而出现多个版本的同一个类。 -
-
委派过程示例:
-
假设请求加载类
com.example.MyClass。 -
系统会首先询问
System ClassLoader(应用程序类加载器),它会将该请求委派给其父加载器Extension ClassLoader。 -
如果
Extension ClassLoader无法找到该类,它会继续将请求委派给Bootstrap ClassLoader。 -
如果最终
Bootstrap ClassLoader也找不到该类,加载器会返回给System ClassLoader,由它在应用程序的classpath中寻找该类。
-
优点
-
避免类加载冲突:通过父类委托机制,避免了一个类被多个加载器加载,从而减少了类冲突的风险。
-
提高效率:父加载器负责加载标准类库,只有当标准类库没有找到时,子加载器才会尝试加载其他类。这种结构能够提高类加载的效率。
-
增强安全性:由
Bootstrap ClassLoader和Extension ClassLoader负责加载系统核心类和标准库,防止用户定义的类覆盖核心类,从而避免一些潜在的安全问题。
常见的类加载器
-
AppClassLoader(应用程序类加载器):它负责加载应用程序的类路径上的类。
-
ExtClassLoader(扩展类加载器):它负责加载Java的扩展类库。
-
BootstrapClassLoader(引导类加载器):它负责加载JVM的核心类库(如
rt.jar)。
自定义类加载器
在Java中,如果你需要从特殊来源加载类(比如数据库、网络),可以自定义类加载器。继承自 ClassLoader,并重写 findClass() 方法。例如:
public class MyClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classData = loadClassData(name); // 自定义加载字节码
return defineClass(name, classData, 0, classData.length); // 定义类
}
private byte[] loadClassData(String name) {
// 通过网络或其他方式加载类的字节码
return new byte[0]; // 假设加载类字节码
}
}
双亲委派机制总结
双亲委派机制是一种为了避免类加载冲突和保证Java平台类的安全性而设计的机制。每个加载器都会把加载请求先交给父加载器,只有父加载器没有找到类时,才会自己去加载。这种机制确保了Java类的加载顺序和安全性。
JVM类初始化顺序
在JVM中,类的初始化是类加载过程中的一个重要步骤。初始化阶段主要是执行类的静态代码块(static {})和静态变量的赋值操作。类的初始化是由JVM在第一次使用该类时触发的,不是类加载的每一步都进行初始化。
类的初始化顺序可以分为几个阶段,下面详细讲解:
1. 类加载的基本过程
类加载的过程包括:
-
加载(Loading):将类的字节码加载到内存中。
-
验证(Verification):确保字节码的正确性。
-
准备(Preparation):为类的静态变量分配内存,并设置默认值。
-
解析(Resolution):将类中的符号引用解析成直接引用。
-
初始化(Initialization):执行静态变量初始化和静态代码块。
2. 类初始化的触发时机
类的初始化并不是在类加载时就发生的,只有在第一次使用类时才会进行初始化。具体来说,类的初始化会在以下几种情况下触发:
-
创建类的实例:当你通过
new关键字创建一个类的对象时,会触发类的初始化。MyClass obj = new MyClass(); // 触发 MyClass 类的初始化 -
访问类的静态变量或静态方法:当你访问类的静态字段或调用类的静态方法时,会触发类的初始化。
MyClass.staticMethod(); // 触发 MyClass 类的初始化 -
使用
Class.forName()加载类:如果通过Class.forName("className")加载类,并且该方法的第二个参数为true,那么类会进行初始化。Class.forName("MyClass", true, classLoader); // 触发类的初始化 -
子类的初始化:如果父类的初始化被触发,那么子类的初始化可能会被延迟到使用时才进行(取决于是否是静态成员)。例如,子类的静态成员或构造方法可以触发父类的初始化。
3. 类初始化的顺序
类的初始化阶段具体执行的内容是:
-
静态变量初始化:为静态变量分配内存并赋予默认值。如果静态变量已经在声明时赋值,则会执行赋值操作。静态变量的初始化顺序是按声明顺序进行的。
-
静态代码块执行:执行类中的静态初始化块(
static {})。静态代码块中的代码按定义顺序执行,仅在类第一次被初始化时执行一次。
4. 类初始化的具体顺序
-
JVM确定类的初始化时机:类加载时,JVM会根据以下规则决定何时初始化类:
-
类第一次被使用时,JVM会触发类的初始化。
-
如果一个类已经初始化过了,那么后续的使用不会再次初始化该类。
-
-
静态变量赋值:静态变量赋值按照声明的顺序进行,首先会分配内存,并将它们初始化为默认值(如
0、null等),然后执行代码中显式的初始化操作。 -
静态代码块执行:静态代码块中的代码会在静态变量赋值之后执行。
-
父类的初始化:
-
如果子类需要初始化时,首先会初始化父类。如果父类还没有初始化,JVM会先初始化父类。父类的初始化过程遵循相同的顺序。
-
在继承体系中,子类的静态初始化发生在父类之后。
class Parent { static { System.out.println("Parent static block"); } } class Child extends Parent { static { System.out.println("Child static block"); } } public class Test { public static void main(String[] args) { Child obj = new Child(); // 先初始化 Parent,再初始化 Child } }输出:
Parent static block Child static block -
-
main方法中的类初始化:-
类的初始化通常是在
main方法中第一次引用某个类时进行。如果类中有静态代码块,这些静态代码块会在类第一次使用时执行。
-
5. 特殊情况
-
常量池中的常量:类的常量池中的常量在类加载时已经被确定并直接初始化,不需要等到类初始化时执行。
class Test { public static final int CONSTANT = 100; // 在类加载时就已经初始化 } -
延迟加载和静态内部类:静态内部类的初始化是在它被第一次引用时才会发生。
class Outer { static class Inner { static { System.out.println("Inner class static block"); } } } public class Test { public static void main(String[] args) { Outer.Inner obj = new Outer.Inner(); // 静态内部类的初始化 } }输出:
Inner class static block -
Class.forName()加载类:使用Class.forName("className")可以控制类的初始化。它会触发类的初始化,并且可以通过第二个参数决定是否初始化类(默认为true)。Class.forName("com.example.MyClass"); // 触发类的初始化
6. 类初始化的注意事项
-
类初始化的顺序依赖于类的使用顺序,而不是它们的加载顺序。只有当类第一次被使用时,它的初始化才会被触发。
-
静态初始化块执行的时机:类的静态初始化块(
static {})在类第一次使用时执行,并且只执行一次。 -
类初始化的过程是线程安全的:如果多个线程同时访问同一个类的初始化,JVM会确保只有一个线程可以执行类的初始化。
7. 总结
-
类加载:包括加载、验证、准备、解析、初始化五个步骤。
-
初始化顺序:
-
静态变量按声明顺序赋值。
-
执行静态代码块。
-
父类的初始化(如果有继承关系)。
-
-
类初始化的触发时机:通过创建对象、访问静态成员、
Class.forName()等方式触发。
对象的创建过程
Java对象创建过程(完整版)
在Java中,对象的创建过程并不仅仅是分配内存和调用构造方法这么简单,还涉及到一些其他细节,如对象头的初始化、类的加载、锁的管理等。整个过程包括以下几个主要步骤:
-
类的加载
-
内存分配
-
对象头的设置
-
构造方法调用
-
实例变量初始化
-
返回对象引用
1. 类的加载
在对象创建之前,JVM首先必须确保该对象的类已经被加载到内存中。类加载的过程包括:
-
加载(Loading):类的字节码从文件系统、网络或其他地方加载到内存中。
-
验证(Verification):JVM会验证类文件的字节码是否符合Java语言规范。
-
准备(Preparation):为类的静态变量分配内存并初始化为默认值(如
null、0等)。 -
解析(Resolution):将类常量池中的符号引用解析为直接引用。
类加载是由类加载器(ClassLoader)负责的,它确保类被正确地加载到JVM中。
2. 内存分配
当类被加载后,JVM会为对象在堆内存中分配空间。对象的内存分配过程如下:
-
内存分配:JVM在堆内存中为对象分配空间。对象的内存分配不仅包括实例变量的空间,还包括对象头的空间。
-
对象头的设置:对象头(Object Header)用于存储与对象相关的元数据,如哈希码、锁状态信息以及类指针等。
3. 对象头的设置
对象头是每个Java对象内存布局中的重要部分。它存储了对象的元数据和一些状态信息,分为两部分:
-
Mark Word(标记字段):用于存储对象的哈希码、锁状态、GC标记、偏向锁信息、轻量级锁或重量级锁的标识符等。
-
Class Pointer(类指针):指向对象所属类的元数据,通常是该类在方法区或元空间中的位置。
在对象创建时,JVM会将这些信息填充到对象头中:
-
Mark Word:初始化时,存储了对象的初始状态信息,后续会根据锁状态和GC标记等变化。
-
Class Pointer:设置为指向该对象所属类的元数据,确保能够查找该类的结构、方法等。
4. 构造方法调用
一旦内存分配和对象头设置完成,JVM会调用类的构造方法进行对象的初始化:
-
调用父类构造方法:如果当前类有父类,JVM会首先调用父类的构造方法。如果父类没有显式定义构造方法,JVM会隐式调用父类的无参构造方法。
-
初始化实例变量:构造方法通过传递参数初始化实例变量。如果类中有实例初始化块(
{}),它会在构造方法之前执行。 -
执行构造器中的代码:构造方法中的代码执行后,实例变量就被初始化为最终的值。
5. 实例变量初始化
对象创建的过程中,实例变量会被初始化为默认值(如null、0等),然后通过构造方法或初始化块进行进一步的初始化。
-
默认值:JVM会将实例变量初始化为默认值(例如,
int类型的默认值是0,对象类型的默认值是null)。 -
初始化块:如果类中有实例初始化块(
{}),它们会在构造方法调用之前执行,用来对实例变量进行额外初始化。
6. 返回对象引用
构造方法执行完毕后,JVM会完成对象的创建,并将对象的引用返回给调用者。这个引用通常是一个指向堆中对象的内存地址。
MyClass obj = new MyClass();
此时,obj保存的就是对新创建的MyClass对象的引用。
对象头的内存结构
Java对象的内存布局不仅仅包括实例变量,还包括对象头,它的结构是这样的:
| 偏移量 | 字段 | 说明 |
|---|---|---|
| 0 ~ 3 | Mark Word | 存储对象的哈希码、锁信息、GC标记等 |
| 4 ~ 7 | Class Pointer | 指向类的元数据(类信息、方法等) |
| 8 ~ N | 实例变量 | 存储对象的实例字段 |
对象头的作用
对象头对于对象管理至关重要,主要体现在以下几个方面:
-
垃圾回收:Mark Word部分用于存储对象的GC标记信息,帮助垃圾回收器判断对象的存活状态。
-
锁管理:Mark Word也用于存储锁的状态。JVM通过Mark Word管理偏向锁、轻量级锁和重量级锁,以便进行并发控制。
-
类元数据访问:Class Pointer用于指向对象所属类的元数据,确保JVM能够通过类信息找到对象的方法、字段等信息。
对象创建过程中的内存管理
-
堆内存分配:在堆内存中为对象分配空间,堆中存储对象的实例变量、对象头和数据等。
-
栈内存分配:对象的引用变量通常存放在栈内存中。栈中的引用变量指向堆内存中的对象。
-
GC与对象头的关系:垃圾回收器通过对象头中的Mark Word来追踪对象的生命周期,决定哪些对象可以回收,哪些对象需要保留。
总结
Java对象的创建过程非常复杂,涉及到多个步骤,从类的加载、内存分配、对象头的初始化到构造方法的调用。对象头作为对象的第一部分,它存储了重要的元数据,包括哈希码、锁状态、类指针以及垃圾回收信息。每个对象的内存布局不仅仅是实例变量的存储,还包括了与对象的生命周期和状态管理相关的关键信息。通过理解对象头和对象创建的过程,我们可以更好地理解Java的内存管理、并发机制以及性能优化技术。
JVM内存参数
JVM内存参数配置是调优Java应用程序性能的重要环节。JVM内存主要分为以下几个区域,每个区域都有其对应的配置参数。理解这些内存区域及其配置参数,能够帮助我们在实际开发中更好地调优应用程序的内存性能,避免内存泄漏、堆溢出等问题。
JVM内存区域
-
堆(Heap)
-
方法区(Method Area)
-
栈(Stack)
-
本地方法栈(Native Stack)
-
程序计数器(Program Counter)
-
直接内存(Direct Memory)
1. 堆内存(Heap)
堆是JVM中最大的一块内存区域,用于存储对象实例和数组。大多数对象都在堆中分配内存。
-
新生代(Young Generation):存储新创建的对象,垃圾回收的频率较高。新生代内存又可以分为:Eden区、Survivor区(S0和S1)。
-
老年代(Old Generation):存储长期存活的对象,垃圾回收的频率较低。
-
永久代/元空间(Permanent Generation/Metaspace):用于存储类的元数据,在JDK 8之前存在永久代(PermGen),JDK 8及以后版本使用元空间(Metaspace)来替代永久代,元空间不再受JVM堆内存限制。
2. 方法区(Method Area)
方法区用于存放类的结构信息,包括类的字段、方法、常量池等。它被视为JVM的“永久代”部分(在JDK 8之前),但从JDK 8开始,永久代被**元空间(Metaspace)**取代。方法区的配置主要关注类的加载和元数据存储。
3. 栈内存(Stack)
每个线程都有自己的栈,用于存储局部变量、方法调用栈帧等。栈的空间由JVM为每个线程分配,栈内存主要存储局部变量和方法的调用信息。
-
局部变量:方法中定义的局部变量、方法参数等。
-
方法调用栈帧:每次方法调用时,JVM会为该方法在栈上分配一个栈帧,用于存储局部变量、操作数栈等。
4. 本地方法栈(Native Stack)
本地方法栈用于管理Java调用本地方法(Native方法)时的相关信息。每个线程也会有自己的本地方法栈,它和栈内存类似,但是专门用于执行原生方法。
5. 程序计数器(Program Counter)
程序计数器是线程私有的,JVM通过程序计数器来跟踪当前线程的执行位置。对于每个线程,JVM维护一个程序计数器,用于指示当前线程正在执行的字节码位置。
6. 直接内存(Direct Memory)
直接内存不属于JVM内存的一部分,它是通过sun.misc.Unsafe或NIO库直接分配的内存。它通常用于提高I/O性能,比如在文件I/O、网络通信等场景中使用。
常见JVM内存参数
JVM的内存参数可以在启动Java应用时通过命令行参数进行配置,常见的内存参数如下:
1. 堆内存(Heap Memory)
-
-Xms<size>:设置JVM堆的初始大小。例如:-Xms512m表示初始堆大小为512MB。 -
-Xmx<size>:设置JVM堆的最大大小。例如:-Xmx2g表示最大堆大小为2GB。 -
-Xmn<size>:设置年轻代的大小(即新生代)。例如:-Xmn256m表示年轻代大小为256MB。
2. 年轻代和老年代内存分配
-
-XX:NewSize=<size>:设置年轻代的初始大小。 -
-XX:MaxNewSize=<size>:设置年轻代的最大大小。 -
-XX:SurvivorRatio=<ratio>:设置Eden区与Survivor区的大小比例,默认值为8,表示Eden区的大小是每个Survivor区的8倍。 -
-XX:OldSize=<size>:设置老年代的初始大小。 -
-XX:MaxPermSize=<size>(JDK 8之前):设置永久代的最大大小。
3. 垃圾回收(Garbage Collection)
-
-XX:+UseSerialGC:使用串行垃圾回收器,适用于单核机器。 -
-XX:+UseParallelGC:使用并行垃圾回收器,适用于多核机器。 -
-XX:+UseG1GC:使用G1垃圾回收器,这是JVM推荐的垃圾回收器,适用于大内存、大堆的应用。 -
-XX:ParallelGCThreads=<number>:设置并行垃圾回收器使用的线程数,通常根据CPU核心数来设置。 -
-XX:ConcGCThreads=<number>:设置G1垃圾回收器的并发垃圾回收线程数。 -
-XX:MaxGCPauseMillis=<time>:设置垃圾回收时的最大停顿时间,单位为毫秒。G1 GC会尽量在该时间内完成垃圾回收。
4. 方法区/元空间配置
-
-XX:PermSize=<size>(JDK 8之前):设置永久代的初始大小。 -
-XX:MaxPermSize=<size>(JDK 8之前):设置永久代的最大大小。 -
-XX:MetaspaceSize=<size>(JDK 8及以后):设置元空间的初始大小。 -
-XX:MaxMetaspaceSize=<size>(JDK 8及以后):设置元空间的最大大小。
5. 栈内存配置
-
-Xss<size>:设置每个线程的栈内存大小。例如:-Xss512k表示每个线程的栈内存为512KB。此参数适用于每个线程的栈分配大小,通常需要根据系统线程数来调整。
6. 直接内存(Direct Memory)
-
-XX:MaxDirectMemorySize=<size>:设置直接内存的最大大小。例如:-XX:MaxDirectMemorySize=512m表示直接内存的最大大小为512MB。直接内存是JVM以外的内存区域,通常用于NIO(非阻塞I/O)操作。
示例:JVM内存参数的实际使用
假设我们有一款需要大量内存支持的Java应用,并且希望使用G1垃圾回收器,配置堆内存大小和元空间大小:
java -Xms2g -Xmx4g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xss1m -XX:MaxDirectMemorySize=512m -jar myapp.jar
-
-Xms2g:初始堆大小设置为2GB。 -
-Xmx4g:最大堆大小设置为4GB。 -
-XX:MetaspaceSize=128m:元空间的初始大小为128MB。 -
-XX:MaxMetaspaceSize=512m:元空间的最大大小为512MB。 -
-XX:+UseG1GC:使用G1垃圾回收器。 -
-XX:MaxGCPauseMillis=200:设置最大垃圾回收停顿时间为200毫秒。 -
-Xss1m:每个线程的栈内存大小为1MB。 -
-XX:MaxDirectMemorySize=512m:设置直接内存的最大大小为512MB。
总结
JVM内存参数调优是确保应用程序高效运行的关键之一。通过合理设置堆内存、年轻代和老年代的大小、垃圾回收策略、线程栈大小等参数,可以显著提高程序的性能,避免内存泄漏、堆溢出等问题。在实际开发中,需要根据应用程序的具体需求(如内存占用、响应时间要求等)进行内存配置。
GC的回收机制和原理
垃圾回收(GC,Garbage Collection)是Java中管理内存的一项重要机制。它的主要作用是自动管理堆内存中的对象生命周期,自动清理不再使用的对象,从而避免内存泄漏和堆溢出等问题。
在JVM中,垃圾回收是通过标记-清除、复制算法、分代收集等原理实现的。为了提高垃圾回收的效率,JVM采用了分代收集的策略,将堆内存划分为多个区域(如年轻代、老年代等),每个区域使用不同的垃圾回收策略。
下面详细介绍GC的回收机制和原理。
1. 垃圾回收的基本原理
垃圾回收的基本原理就是识别出不可达的对象并将它们清除掉。一般来说,GC的过程包括以下步骤:
-
标记阶段:标记所有活跃的对象。活跃的对象是指仍然可以通过根对象(GC Root)访问到的对象。
-
清除阶段:回收那些没有被标记的对象,也就是不可达对象。
-
整理阶段(可选):通过压缩内存、整理存活对象的位置来减少内存碎片,通常发生在垃圾回收的后期(如在老年代的回收中)。
2. GC的根对象(GC Root)
GC Root是GC过程中用来标记活跃对象的一个基础。GC根对象一般包括以下几类:
-
栈上的引用:线程栈中的局部变量。
-
方法区的静态变量:类的静态字段。
-
JNI引用:本地方法栈中的引用。
-
活动线程:所有活动线程都是GC根对象。
这些根对象是GC标记过程的起始点,所有从GC根对象可以访问到的对象,都会被标记为存活的对象。
3. GC的回收算法
垃圾回收算法用于决定如何识别和回收不可达对象。常见的垃圾回收算法包括:
1. 标记-清除算法(Mark-Sweep)
这是最基本的垃圾回收算法,分为两个阶段:
-
标记阶段:从GC Root开始,遍历所有能到达的对象,标记为存活对象。
-
清除阶段:回收那些没有被标记的对象,也就是不可达的对象。
缺点:清除阶段可能会产生内存碎片,因为回收后的内存空间不一定是连续的。这样可能会导致后续的内存分配失败,浪费内存。
2. 复制算法(Copying)
复制算法将堆分为两部分,每次只使用其中的一部分来分配新对象。当某一部分内存用完时,复制算法会将存活的对象复制到另一块空闲的内存区域中。然后,回收整个已用完的内存区域。
-
标记阶段:从GC Root开始,标记存活对象。
-
复制阶段:将存活对象从当前使用的内存区域复制到空闲的内存区域。
-
清除阶段:清除当前内存区域。
优点:复制算法没有内存碎片问题,内存整理十分简单,因为它直接将存活对象复制到新的内存区域。
缺点:它需要额外的内存空间来存放复制的对象,因此它不适用于大型对象的处理。
3. 标记-整理算法(Mark-Compact)
标记-整理算法是对标记-清除算法的改进。与标记-清除算法相比,它不仅会清理掉不可达对象,还会整理存活对象的内存,使得内存不再出现碎片。
-
标记阶段:与标记-清除算法相同,标记所有存活对象。
-
整理阶段:将所有存活对象移到内存的一端,然后清理掉剩余的内存空间。
优点:与标记-清除算法相比,标记-整理算法解决了内存碎片的问题,避免了内存分配失败。
缺点:需要移动对象,因此比标记-清除算法更加消耗时间。
4. 分代收集算法
Java采用了分代收集算法(Generational Collection),将堆内存分为多个区域(年轻代、老年代等),并根据对象的生命周期特征来选择不同的回收策略。这是Java垃圾回收算法中最为常用的策略。
-
年轻代:包含新创建的对象。由于对象在年轻代中的生命周期通常较短,因此对年轻代的回收使用了复制算法(如
Minor GC)。 -
老年代:包含长时间存活的对象。老年代的对象存活时间较长,因此回收时使用标记-清除算法或标记-整理算法(如
Major GC或Full GC)。
分代收集算法通过将对象按年龄划分到不同的区域,并针对不同区域使用不同的垃圾回收算法,可以提高回收效率。
4. 垃圾回收的过程
JVM中的垃圾回收通常涉及以下几种回收:
1. Minor GC
-
回收年轻代:当年轻代内存满时,会发生Minor GC。在Minor GC过程中,首先会对年轻代进行标记-清除或复制回收,回收那些不再使用的对象。
-
影响较小:Minor GC回收的速度较快,通常不会造成应用程序停顿时间过长。
2. Major GC(或Full GC)
-
回收整个堆:当老年代内存满时,发生Major GC。Major GC会回收整个堆,包括年轻代和老年代。由于涉及的内存区域较大,因此Major GC通常会造成更长时间的应用程序停顿。
-
性能开销较大:Major GC的开销较大,因此尽量避免频繁发生。
3. 老年代GC
-
发生条件:老年代内存不足时,会进行老年代的垃圾回收。
-
回收方式:一般使用标记-清除或标记-整理的算法。
5. 常见的GC回收器
JVM提供了不同的垃圾回收器,适应不同的场景:
-
Serial GC:单线程垃圾回收器,适用于小型应用。
-
Parallel GC:多线程垃圾回收器,适用于多核机器,能够加速垃圾回收过程。
-
CMS GC(Concurrent Mark-Sweep):并发标记-清除垃圾回收器,适用于需要低延迟的应用。
-
G1 GC(Garbage-First):以区域为单位进行垃圾回收,适用于大内存、大堆的应用,能够提供可调的暂停时间。
6. GC相关JVM参数
可以通过JVM参数来调节垃圾回收行为:
-
-XX:+UseSerialGC:启用串行垃圾回收器。 -
-XX:+UseParallelGC:启用并行垃圾回收器。 -
-XX:+UseG1GC:启用G1垃圾回收器。 -
-Xms<size>:设置初始堆大小。 -
-Xmx<size>:设置最大堆大小。 -
-XX:MaxGCPauseMillis=<time>:设置垃圾回收的最大停顿时间。 -
-XX:NewSize=<size>:设置年轻代的初始大小。 -
-XX:SurvivorRatio=<ratio>:设置Eden区与Survivor区的大小比例。
总结
垃圾回收是JVM管理内存的重要机制,通过标记-清除、复制、标记-整理等回收算法来自动清理不可达对象。Java采用分代收集策略,根据对象生命周期的不同将堆分为年轻代和老年代,从而优化不同区域的垃圾回收。通过合适的回收器和JVM参数配置,我们可以有效提高应用程序的性能,避免内存泄漏和堆溢出等问题。
Spring框架
什么是Spring?什么是SpringBoot?
Spring框架
Spring 是一个开源的、轻量级的企业级应用开发框架,广泛应用于Java开发中。Spring框架的核心目的是简化Java应用的开发过程,特别是大型企业应用。它提供了多种服务和功能,帮助开发人员实现松耦合、可维护和可扩展的系统。
Spring的核心特性
-
控制反转(IoC,Inversion of Control):
-
Spring通过**依赖注入(DI,Dependency Injection)**来管理对象的创建和生命周期。开发者不再手动创建对象,而是交给Spring容器来管理,这样可以减少代码中的耦合度,提高模块之间的独立性。
-
-
面向切面编程(AOP,Aspect-Oriented Programming):
-
Spring支持AOP,可以将横切关注点(例如日志记录、事务管理、安全控制等)与核心业务逻辑解耦,从而简化开发过程。
-
-
数据访问支持:
-
Spring提供了一系列简化数据库访问的功能,包括对JDBC(Java数据库连接)操作的封装和对事务的管理。它通过事务管理器来处理声明式事务,使得数据库操作更加简洁。
-
-
持久化支持:
-
Spring支持与各种持久化框架的集成,如Hibernate、JPA(Java Persistence API)等。它提供了简单的配置和强大的集成能力,使得开发者可以专注于业务逻辑。
-
-
Web框架支持:
-
Spring的Web模块(Spring Web)提供了一个强大的Web应用开发环境,包括用于处理HTTP请求的DispatcherServlet、RESTful API支持、以及与Spring MVC的集成。
-
-
测试支持:
-
Spring提供了对JUnit的支持,并且内置了Mock对象、事务管理和依赖注入等特性,可以方便地进行单元测试和集成测试。
-
Spring框架的组成部分
-
Spring Core:提供核心功能,如IoC容器、Bean管理、依赖注入等。
-
Spring AOP:提供面向切面编程的支持,用于实现事务管理、安全、日志等横切关注点。
-
Spring Data Access/Integration:简化数据库访问、JDBC、事务管理等。
-
Spring MVC:Web模块,用于开发基于Servlet的Web应用,支持RESTful服务。
-
Spring Security:提供全面的安全服务,包括认证、授权、防止跨站攻击等。
-
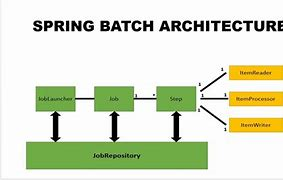
Spring Batch:用于处理批量任务和作业调度。
-
Spring Cloud:用于开发分布式系统,提供微服务架构的支持。
Spring Boot
Spring Boot 是由Spring团队推出的一个快速开发框架,旨在简化基于Spring的应用程序的开发过程。Spring Boot的目标是让开发者无需关注繁琐的配置,可以快速创建独立的、可执行的Spring应用程序。
Spring Boot的一个关键特点是约定优于配置,即它为开发者提供了一些默认配置,减少了配置的复杂度,开发者只需要专注于业务逻辑的实现。
Spring Boot的主要特点
-
自动配置(Auto Configuration):
-
Spring Boot通过自动配置的方式来简化Spring应用的配置。当你添加某个依赖时,Spring Boot会根据你的应用环境自动配置相关的功能。例如,如果你添加了Spring Data JPA依赖,Spring Boot会自动配置数据源、JPA等。
-
-
独立运行(Standalone Application):
-
Spring Boot应用可以打包成一个可执行的JAR文件或者WAR文件,包含所有必要的依赖和内嵌的Web服务器(如Tomcat、Jetty)。这意味着你不需要额外的Web服务器,应用可以独立运行。
-
-
无代码生成(No Code Generation):
-
Spring Boot没有代码生成工具,所有的配置和构建都通过声明式的方式进行。开发者无需生成代码,简化了开发过程。
-
-
内嵌服务器(Embedded Server):
-
Spring Boot内置了常用的Web服务器,如Tomcat、Jetty等,使得开发者不需要依赖外部的Web服务器,应用可以直接以JAR文件运行。
-
-
生产就绪(Production Ready):
-
Spring Boot内置了多个用于生产环境的功能,如健康检查、指标监控、日志管理等,帮助开发者快速部署到生产环境。
-
-
Spring Boot Starter:
-
Spring Boot提供了一系列的Starter依赖,这些依赖为开发者提供了许多常用的功能模块,开发者只需引入相应的Starter就可以快速配置好应用。例如,
spring-boot-starter-web用于Web开发,spring-boot-starter-data-jpa用于JPA持久化开发。
-
-
简化的配置方式(Properties/YAML):
-
Spring Boot支持通过
application.properties或application.yml配置文件来管理配置,简单易懂,减少了复杂的XML配置。
-
Spring Boot的优势
-
减少配置:通过自动配置和约定优于配置的设计理念,Spring Boot大大减少了开发者的配置工作。
-
快速开发:开发者可以通过Spring Boot快速启动一个应用,并专注于业务逻辑。
-
微服务支持:Spring Boot是Spring Cloud的基础,帮助开发者构建和管理微服务架构。
-
集成度高:Spring Boot与Spring生态中的其他项目(如Spring Data、Spring Security、Spring MVC等)有着很好的集成,使得开发者可以快速上手。
Spring与Spring Boot的区别
| 特性 | Spring | Spring Boot |
|---|---|---|
| 配置方式 | 需要大量的XML或Java配置 | 自动配置,约定优于配置,几乎不需要手动配置 |
| 运行方式 | 需要部署到外部应用服务器(如Tomcat、Jetty等) | 可以嵌入Web服务器(如Tomcat、Jetty)独立运行 |
| 启动速度 | 启动时需要进行一些配置加载 | 启动更快,提供快速的开发体验 |
| 开发复杂度 | 配置较为复杂,适合大型复杂应用 | 简化配置,适合快速开发和原型设计 |
| 依赖管理 | 开发者需要手动添加和配置依赖 | 通过Starter依赖自动管理,简化依赖配置 |
总结
-
Spring是一个功能丰富的开发框架,提供了众多模块来支持开发企业级应用,帮助开发者进行松耦合、高内聚的设计。
-
Spring Boot是基于Spring的一个增强框架,旨在简化Spring应用的配置和启动过程,特别适用于快速开发和微服务架构。Spring Boot通过自动配置、内嵌服务器等特性,使得Java应用的开发、部署和维护更加简便。
总的来说,Spring Boot在Spring的基础上做了大量的简化工作,让开发者可以快速开始项目,专注于业务逻辑的实现,而不需要过多关注配置和环境的搭建。
什么是IOC和AOP?AOP是怎么实现的?
1. 什么是IoC(控制反转)?
IoC(Inversion of Control,控制反转)是面向对象设计的一种原则,指的是将对象的控制权从程序员转移到容器中。在传统的编程方式中,程序员会手动创建和管理对象的实例。而在IoC中,控制权被反转,容器负责创建、管理和注入依赖。
IoC的核心思想
在传统的编程中,应用程序会主动创建和管理对象的依赖。IoC的核心思想是让控制权反转,将对象的创建、管理交给容器(如Spring容器),从而简化对象之间的依赖管理。
常见的IoC容器:Spring容器(如ApplicationContext)
IoC的实现方式:依赖注入(DI)
依赖注入(Dependency Injection,DI)是IoC的实现方式之一,它允许通过构造方法、Setter方法或者字段注入来提供对象的依赖。Spring框架通过依赖注入来实现IoC的原理。
依赖注入的方式:
-
构造器注入:通过构造函数注入依赖对象。
-
Setter方法注入:通过Setter方法注入依赖对象。
-
字段注入:通过反射直接将依赖注入到类的字段。
举个例子:
public class Car {
private Engine engine;
// 构造器注入
public Car(Engine engine) {
this.engine = engine;
}
public void start() {
engine.run();
}
}
public class Engine {
public void run() {
System.out.println("Engine is running!");
}
}
在Spring中,你可以通过配置文件或者注解来实现依赖注入,而不需要手动创建Car和Engine对象:
<bean id="engine" class="com.example.Engine"/>
<bean id="car" class="com.example.Car">
<constructor-arg ref="engine"/>
</bean>
通过这种方式,Spring容器会自动管理对象的生命周期和依赖关系。
2. 什么是AOP(面向切面编程)?
AOP(Aspect-Oriented Programming,面向切面编程)是一种编程范式,用于分离关注点的功能(横切关注点),从而提高代码的模块化程度。横切关注点通常是多个模块共享的行为,如日志记录、事务管理、安全控制等。
在AOP中,核心业务逻辑和横切关注点被解耦,使得开发者可以在不修改业务代码的情况下,为业务方法添加额外的功能。
AOP的核心概念
-
横切关注点:与核心业务逻辑无关,但影响多个模块的功能(如日志、安全、事务等)。
-
切面(Aspect):横切关注点的模块化,是切面编程的核心。一个切面通常由多个通知(Advice)和切点(Pointcut)组成。
-
通知(Advice):指定在连接点处执行的代码。它是AOP的核心,分为不同的类型,如前置通知、后置通知、环绕通知等。
-
连接点(Join Point):程序执行过程中可插入通知的点(如方法的调用)。
-
切点(Pointcut):定义了在什么地方(哪些连接点)应用通知(Advice)。例如,在指定类的某些方法上执行通知。
-
织入(Weaving):将通知应用到切点的过程。织入可以在编译时、类加载时或者运行时进行。
AOP常见通知类型
-
前置通知(Before):在方法执行之前执行。
-
后置通知(After):在方法执行之后执行。
-
返回通知(After Returning):在方法正常执行完后执行。
-
异常通知(After Throwing):在方法抛出异常后执行。
-
环绕通知(Around):可以控制方法是否执行,决定方法执行前后的行为。
AOP的实现方式:
-
JDK动态代理:使用Java的反射机制创建接口的代理类。
-
CGLIB代理:通过生成目标类的子类来实现代理。
Spring AOP是基于代理模式的,可以通过JDK动态代理或者CGLIB字节码增强方式来实现。
3. AOP是怎么实现的?
Spring AOP的实现基于代理模式,通常采用以下两种方式来创建代理对象:
1. JDK动态代理
JDK动态代理基于接口创建代理类。只有当目标对象实现了至少一个接口时,Spring才能通过JDK动态代理创建代理对象。在使用JDK动态代理时,代理对象会实现目标类的所有接口,并将方法的调用转发给InvocationHandler对象。
示例:
假设你有一个接口UserService,并通过JDK动态代理为其添加AOP功能。
public interface UserService {
void addUser();
void updateUser();
}
public class UserServiceImpl implements UserService {
@Override
public void addUser() {
System.out.println("Add User");
}
@Override
public void updateUser() {
System.out.println("Update User");
}
}
Spring会通过动态代理为UserServiceImpl创建代理类,并在其方法调用前后加入AOP通知。
2. CGLIB代理
如果目标对象没有实现接口,Spring会使用CGLIB(Code Generation Library)来生成目标类的子类。CGLIB基于字节码增强技术,通过继承目标类来创建代理类。CGLIB代理可以拦截所有方法,包括private方法(JDK代理不能拦截private方法)。
示例:
假设目标类UserServiceImpl没有实现接口,Spring会通过CGLIB为其创建代理类。
public class UserServiceImpl {
public void addUser() {
System.out.println("Add User");
}
public void updateUser() {
System.out.println("Update User");
}
}
Spring会生成UserServiceImpl的子类来代理方法调用。
3. Spring AOP的实现流程
-
定义切面(Aspect):切面是AOP的核心,它由一个或多个通知(Advice)和一个切点(Pointcut)组成。在Spring中,切面通常通过
@Aspect注解来定义。 -
定义通知(Advice):通知是切面中的实际执行逻辑。你可以定义前置通知、后置通知、环绕通知等。
-
定义切点(Pointcut):切点定义了在哪些方法上执行通知(如某个类的某个方法)。切点通常通过表达式来指定。
-
Spring代理:Spring会为目标对象生成一个代理类,当目标对象的方法被调用时,代理类会在执行目标方法之前或之后调用通知。
示例代码:
@Aspect
@Component
public class LoggingAspect {
// 定义一个切点,表示在UserService的所有方法执行之前执行
@Before("execution(* com.example.service.UserService.*(..))")
public void logBefore(JoinPoint joinPoint) {
System.out.println("Before method: " + joinPoint.getSignature());
}
// 定义一个后置通知,表示在UserService的所有方法执行之后执行
@After("execution(* com.example.service.UserService.*(..))")
public void logAfter(JoinPoint joinPoint) {
System.out.println("After method: " + joinPoint.getSignature());
}
// 定义一个环绕通知,可以控制目标方法是否执行
@Around("execution(* com.example.service.UserService.*(..))")
public Object logAround(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {
System.out.println("Around before method: " + proceedingJoinPoint.getSignature());
Object result = proceedingJoinPoint.proceed(); // 执行目标方法
System.out.println("Around after method: " + proceedingJoinPoint.getSignature());
return result;
}
}
在这个例子中,LoggingAspect类定义了一个切面,它会在UserService的所有方法执行之前和之后打印日志。
总结
-
IoC(控制反转)是Spring的核心概念,它通过**依赖注入(DI)**实现将对象的创建和管理交给容器,减少对象间的耦合。
-
AOP(面向切面编程)是一种通过将横切关注点(如日志、事务、权限等)与业务逻辑解耦来提高代码模块化的编程方法。Spring AOP通常通过代理模式来实现,支持JDK动态代理和CGLIB字节码增强。
什么是Bean?他的创建方式有哪些?相关注解都是啥意思?
什么是Bean?
在Spring框架中,Bean是指由Spring IoC容器(应用上下文)管理的对象。Spring容器负责创建、配置和管理Bean的生命周期。每个Bean都是一个Spring管理的组件,通常是应用程序中的服务、DAO、控制器、工具类等。
Bean在Spring中一般指的是那些由容器创建并交给容器管理的Java对象,它们可以通过依赖注入的方式向其他类提供服务。简而言之,Bean是Spring容器中的对象,通常是应用程序的构建块。
Bean的创建方式
Spring容器可以通过多种方式来创建Bean,主要的方式包括:
1. XML配置文件方式
这是Spring早期使用的方式,在XML配置文件中通过<bean>标签定义Bean。
<bean id="myBean" class="com.example.MyBean"/>
-
id:Bean的唯一标识符。 -
class:Bean的实现类,指定该Bean是哪个Java类的实例。
2. 注解方式
Spring通过注解方式提供了创建和管理Bean的功能,主要通过@Component及其衍生注解来定义Bean。这是Spring 2.5版本之后引入的特性,简化了XML配置。
相关注解:
-
@Component:这是最通用的注解,用于声明一个Bean。任何被@Component标注的类都会被Spring容器自动识别并注册为一个Bean。@Component public class MyBean { // 类的定义 } -
@Service:专门用于标注服务层(Service)的Bean,@Service继承自@Component,表示该Bean是服务层组件。@Service public class MyService { // 服务层的业务逻辑 } -
@Repository:用于标注持久化层(DAO)的Bean,@Repository继承自@Component,标志该类是数据库操作的组件。@Repository public class MyRepository { // 数据访问逻辑 } -
@Controller:用于标注控制层(Controller)的Bean,@Controller继承自@Component,表示该类是Web控制器,通常与Spring MVC配合使用。@Controller public class MyController { // 控制层的逻辑 } -
@RestController:是@Controller和@ResponseBody的组合,通常用于开发RESTful API。@RestController public class MyRestController { // 用于返回RESTful响应 } -
@Configuration:用来定义一个配置类,表示该类是Spring的配置类,通常包含@Bean定义的方法。@Configuration public class AppConfig { @Bean public MyService myService() { return new MyService(); } } -
@Bean:用于方法上,表示该方法返回的对象将作为一个Bean注册到Spring容器中。@Configuration public class AppConfig { @Bean public MyService myService() { return new MyService(); } }
3. Java Config方式
Spring 3.0引入了Java Config的方式,这种方式不再依赖XML配置,而是通过@Configuration注解和@Bean注解在Java类中直接定义和管理Bean。
@Configuration
public class AppConfig {
@Bean
public MyService myService() {
return new MyService();
}
}
-
**
@Configuration**注解表示这是一个配置类,容器会在启动时扫描这个类,加载其中定义的Bean。 -
**
@Bean**注解定义方法返回的对象作为Spring容器管理的Bean。
4. 自动装配(Autowiring)
Spring支持通过注解进行自动装配,自动将符合条件的Bean注入到需要它们的地方。主要通过@Autowired注解来实现自动注入。
@Component
public class MyService {
@Autowired
private MyRepository myRepository;
}
在这个例子中,MyRepository将被自动注入到MyService中,前提是MyRepository被Spring容器管理。
5. Profile配置方式
Spring的@Profile注解允许根据不同的环境激活不同的Bean,适合开发、测试、生产等不同环境。
@Profile("dev")
@Component
public class DevDataSource {
// 开发环境的数据源配置
}
@Profile("prod")
@Component
public class ProdDataSource {
// 生产环境的数据源配置
}
在启动时,通过设置-Dspring.profiles.active=dev来指定当前激活的Profile,Spring会选择对应的Bean。
Bean的作用域(Scope)
Spring中的Bean有不同的作用域,作用域定义了Bean的生命周期和可见性。Spring支持以下几种常用的作用域:
-
singleton(默认作用域):Spring容器中只会创建一个实例,所有请求该Bean的地方都返回同一个实例。@Scope("singleton") @Component public class MyBean { // ... } -
prototype:每次请求都会创建一个新的Bean实例。@Scope("prototype") @Component public class MyBean { // ... } -
request:在Web应用中,每个HTTP请求都会创建一个新的Bean实例。 -
session:在Web应用中,每个HTTP session都会创建一个新的Bean实例。
这些作用域可以通过@Scope注解进行设置。
Bean的生命周期
Spring中的Bean有一套完整的生命周期,包括初始化、销毁等过程。Spring提供了两种方式来定制Bean的生命周期:
-
通过
@PostConstruct和@PreDestroy注解:-
@PostConstruct:在Bean初始化之后执行的回调方法。 -
@PreDestroy:在Bean销毁之前执行的回调方法。
@Component public class MyBean { @PostConstruct public void init() { System.out.println("Bean初始化后"); } @PreDestroy public void destroy() { System.out.println("Bean销毁之前"); } } -
-
通过
InitializingBean和DisposableBean接口:-
afterPropertiesSet:InitializingBean接口中定义的方法,Bean初始化时调用。 -
destroy:DisposableBean接口中定义的方法,Bean销毁时调用。
-
总结
-
Bean是Spring容器中管理的对象,通常用于表示应用中的服务、组件或数据访问对象。
-
创建方式:可以通过XML配置、注解(
@Component、@Service、@Repository等)和Java Config(@Configuration和@Bean)来创建和管理Bean。 -
作用域:Spring提供了多种Bean的作用域,如
singleton(单例)、prototype(原型)、request、session等。 -
生命周期:Spring允许开发者通过注解或接口来定制Bean的初始化和销毁过程。
Spring如何解决循环依赖的?
Spring如何解决循环依赖的问题?
在Spring中,循环依赖是指两个或多个Bean互相依赖,从而形成了一个依赖环。例如,A依赖B,B依赖A,或者更多Bean相互依赖,造成一个循环。Spring通过不同的策略来解决这种问题,确保容器能够正常创建这些Bean,并且不会进入死循环。
Spring主要通过三级缓存和提前暴露的代理对象来解决循环依赖问题。
1. Spring的三级缓存机制
Spring容器通过 三级缓存 解决循环依赖问题。三级缓存机制指的是Spring在创建Bean的过程中,会通过以下三个缓存来管理Bean的状态:
-
第一级缓存:
singletonObjects(已经完全创建的Bean对象) -
第二级缓存:
earlySingletonObjects(提前暴露的对象,即目标Bean的代理对象) -
第三级缓存:
singletonFactories(Bean的工厂,用于创建Bean的实例)
具体流程
-
创建Bean实例(实例化):当Spring容器需要创建一个Bean时,它会首先检查
singletonObjects缓存,看该Bean是否已经存在于容器中。如果存在,则直接返回该Bean。如果不存在,则继续进行创建过程。 -
创建Bean的工厂方法(
singletonFactories):在创建Bean的过程中,Spring会把该Bean的工厂方法放入singletonFactories缓存。这是因为Bean还没有完全初始化,因此容器需要用工厂来实例化Bean的具体对象。 -
提前暴露Bean(
earlySingletonObjects):如果在创建Bean的过程中发现了循环依赖,Spring会提前暴露一个部分初始化的Bean对象,这个对象并不完全初始化,它可能只是一个代理对象(通常是通过CGLIB或JDK代理实现)。这个对象会被放到earlySingletonObjects缓存中。 -
完成Bean的初始化:当一个Bean被完全初始化并且所有依赖注入都完成后,它会被放到
singletonObjects缓存中。
这样,当Spring容器发现某个Bean是另一个Bean的依赖时,如果两个Bean存在循环依赖,它会使用提前暴露的代理对象来打破循环依赖,然后通过工厂和三级缓存的协作机制,最终完成Bean的初始化。
2. 示例代码
假设我们有两个Bean A 和 B 形成了循环依赖:
@Component
public class A {
@Autowired
private B b;
public void sayHello() {
System.out.println("Hello from A!");
}
}
@Component
public class B {
@Autowired
private A a;
public void sayHello() {
System.out.println("Hello from B!");
}
}
这时,A 和 B 是相互依赖的,Spring在创建这两个Bean时,如何解决循环依赖呢?
Spring的解决方式
-
Spring首先创建
A类的实例,但是A需要依赖B,所以容器会先创建B类的实例。 -
在创建
B类的过程中,B又依赖A,此时Spring会尝试从缓存中查找A,但由于A尚未完全创建,Spring会将A放入**singletonFactories**缓存。 -
在
B的创建过程中,Spring会提前暴露一个部分初始化的A对象,并将其放入**earlySingletonObjects**缓存中。 -
之后,Spring将继续创建
A,并将A的完全初始化对象存放到**singletonObjects**缓存中。 -
最终,Spring通过提前暴露的部分初始化对象解决了循环依赖问题,完成
A和B的依赖注入。
3. 原理与流程
1. 循环依赖的类型
Spring中主要有两种类型的循环依赖:
-
构造器循环依赖:当两个Bean通过构造方法相互依赖时,Spring不能通过默认的方式解决循环依赖问题。因为构造方法是必需的,并且在创建对象时,构造方法会先于依赖注入执行,因此Spring无法提前暴露代理对象来解决这种问题。
解决方法:如果遇到构造器循环依赖,Spring会抛出
BeanCurrentlyInCreationException,说明这种循环依赖不能通过Spring的IoC容器来解决。 -
Setter或字段注入循环依赖:Spring可以通过Setter注入或字段注入来解决循环依赖问题。这是因为Spring可以在Bean实例化后,等待其他依赖注入完成后再注入依赖。
2. 三级缓存机制
-
一级缓存:
singletonObjects缓存用于存储完全初始化完成的Bean对象。 -
二级缓存:
earlySingletonObjects缓存用于存储提前暴露的代理对象(即部分初始化的对象)。 -
三级缓存:
singletonFactories缓存用于存储Bean工厂,这些工厂用于创建Bean实例。
4. 什么时候会遇到循环依赖问题?
循环依赖主要发生在以下几种情况:
-
构造方法注入:当两个Bean通过构造方法互相依赖时,Spring无法创建这两个Bean并注入其依赖。因为构造器是必须执行的,且不能在Bean创建过程中延迟执行。
-
Setter或字段注入:Spring会先实例化Bean,并将其放入
singletonFactories缓存中,等到所有依赖都满足时再进行注入。这样,依赖注入的过程是可控的,可以解决循环依赖问题。
5. 总结
-
Spring通过三级缓存机制解决了大部分的循环依赖问题。
-
构造方法注入会导致无法解决的循环依赖,而Setter方法注入和字段注入可以利用提前暴露的代理对象来打破循环依赖。
-
Spring的容器能够通过提前暴露代理对象的方式,使得循环依赖在Setter和字段注入的情况下能够顺利解决。
注意:尽管Spring可以解决大部分循环依赖,但对于构造方法注入的循环依赖,Spring无法自动解决,开发者需要改用Setter或字段注入,或者通过其他设计方式来避免循环依赖的发生。
详细说明一下Spring IOC的初始化过程
Spring IoC初始化过程
Spring IoC(Inversion of Control)容器负责管理应用中的对象(即Bean)的生命周期,包括它们的创建、依赖注入、初始化和销毁等过程。Spring IoC容器的初始化过程从容器的启动开始,到容器销毁结束,涵盖了许多细节。以下是Spring IoC容器的详细初始化过程:
1. Spring容器的启动
Spring容器的启动通常是通过加载Spring配置文件(如applicationContext.xml)或注解配置类来开始的。根据不同的配置方式,Spring有两种主要的容器类型:
-
ApplicationContext:这是Spring最常用的容器接口,提供了更丰富的功能,适用于大多数场景。 -
BeanFactory:这是Spring容器的最基本实现,功能相对简单,通常用于较小的应用程序。
假设我们使用ApplicationContext作为容器,它通常在main方法中加载,例如:
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
这时,Spring容器的启动过程便开始了。
2. 扫描Bean的定义和配置
容器启动后,Spring会扫描并解析容器中的配置,识别所有的Bean定义。此过程会根据容器配置的方式而有所不同:
-
XML配置:Spring通过
<bean>标签读取XML配置文件。 -
注解配置:Spring通过
@Configuration、@ComponentScan等注解扫描类路径,并注册相关的Bean。
例如,@ComponentScan会扫描指定包下所有使用@Component、@Service、@Repository等注解标注的类,将它们注册为Bean。
@Configuration
@ComponentScan(basePackages = "com.example")
public class AppConfig {
// 配置类,容器启动时会扫描该包下的所有Bean
}
3. Bean定义解析
在扫描过程中,Spring会根据配置文件或者注解解析每个Bean的定义,并将其存储在一个内部的**BeanDefinition**对象中。BeanDefinition包含了Bean的元数据,如类名、作用域、生命周期、依赖关系等信息。
此时,Spring容器知道了哪些类是Bean,如何实例化它们,以及它们之间的依赖关系等。
4. BeanFactory容器的实例化
Spring IoC容器会首先初始化一个BeanFactory,这是一个简单的容器,它管理所有Bean的定义以及Bean的实例化。当容器初始化时,BeanFactory会加载所有的Bean定义,建立Bean与其依赖关系的映射。
-
Singleton Bean:这些Bean会被立即加载到内存中,只会实例化一次,且在容器运行期间保持唯一。
-
Prototype Bean:这些Bean只有在请求时才会实例化,每次请求都会返回一个新的实例。
5. 实例化Bean
接下来,Spring容器会根据BeanDefinition中的配置信息实例化Bean对象。Spring的实例化有几种方式:
-
无参构造器实例化:Spring默认使用无参构造器实例化Bean对象。如果Bean类没有无参构造器,Spring会尝试使用
@Autowired注解标记的构造器进行构造注入。 -
工厂方法实例化:如果
<bean>标签中配置了factory-method属性,Spring将通过该工厂方法来实例化Bean。
6. 依赖注入
在实例化Bean之后,Spring会对Bean进行依赖注入(DI)。这时,Spring会根据Bean的定义以及字段、构造器或Setter方法上的注解(如@Autowired、@Value等),将依赖注入到Bean中。
-
构造器注入:Spring会自动调用构造器并注入依赖。
-
Setter方法注入:Spring会调用Setter方法并将依赖注入到Bean中。
-
字段注入:通过
@Autowired注解,Spring会直接将依赖注入到字段中。
7. Bean的初始化
如果Bean实现了InitializingBean接口或者定义了@PostConstruct注解,Spring会调用相应的初始化方法。在初始化方法中,可以进行Bean的其他设置或资源的初始化。
-
InitializingBean接口:提供afterPropertiesSet()方法,在Bean完成依赖注入后执行。 -
@PostConstruct注解:在Bean的所有依赖注入完成后执行。
例如:
@Component
public class MyService implements InitializingBean {
@Override
public void afterPropertiesSet() throws Exception {
// 初始化逻辑
System.out.println("Bean初始化完成!");
}
}
或者使用@PostConstruct:
@Component
public class MyService {
@PostConstruct
public void init() {
// 初始化逻辑
System.out.println("Bean初始化完成!");
}
}
8. AOP代理的创建
如果该Bean涉及到AOP(面向切面编程),Spring会在此时创建代理对象。AOP代理是用来处理横切逻辑的,在Bean初始化后,Spring会为Bean创建代理对象(通常使用JDK动态代理或CGLIB代理)。
-
JDK动态代理:如果目标Bean实现了接口,Spring会创建JDK代理。
-
CGLIB代理:如果目标Bean没有实现接口,Spring会使用CGLIB生成代理类。
9. Bean的注册到容器
当所有Bean初始化完成后,它们会被注册到Spring的容器中。对于单例Bean,Spring会将其实例放入singletonObjects缓存中,以便后续的请求可以直接从缓存中获取,而不需要重新创建。
10. 容器的准备完成
此时,Spring容器的初始化过程已经完成。Spring容器开始为用户提供服务,进行依赖注入,管理Bean的生命周期。
11. 容器销毁
当应用程序结束或者Spring容器被关闭时,Spring容器会调用Bean的销毁方法。如果Bean实现了DisposableBean接口,Spring会调用destroy()方法;如果Bean定义了@PreDestroy注解的方法,Spring会执行这些方法。Spring还会销毁单例Bean对象并释放相关资源。
@Component
public class MyService implements DisposableBean {
@Override
public void destroy() throws Exception {
// 销毁资源
System.out.println("Bean销毁!");
}
}
总结:Spring IoC容器初始化过程
-
容器启动:通过
ApplicationContext或者BeanFactory启动Spring容器。 -
扫描Bean定义:Spring通过XML、注解或Java Config加载Bean定义。
-
解析Bean定义:容器解析所有Bean的定义,并将其保存在
BeanDefinition对象中。 -
实例化Bean:根据
BeanDefinition的信息实例化Bean对象。 -
依赖注入:Spring将Bean的依赖注入到实例化的对象中。
-
初始化:调用Bean的初始化方法,如
InitializingBean接口、@PostConstruct注解等。 -
AOP代理:如果Bean需要代理,Spring会在此时创建AOP代理对象。
-
Bean注册到容器:Bean被注册到Spring容器中,单例Bean会被缓存。
-
容器准备完毕:容器已准备好,提供依赖注入和其他功能。
-
容器销毁:在容器关闭时,调用Bean的销毁方法,释放资源。
这个过程确保了Spring能够管理Bean的生命周期和依赖关系,帮助开发者更好地进行解耦和自动化管理。


![[reinforcement learning] 是什么 | 应用场景 | Andrew Barto and Richard Sutton](https://i-blog.csdnimg.cn/img_convert/6f2e7478c9968695e6b5f486c58d1dca.png)
![[从零开始学数据库] 基本SQL](https://i-blog.csdnimg.cn/img_convert/3368be73fa23a926fd7a54d3b2f66c57.png)