KCP 是一个轻量级的、高效的、面向 UDP 的传输协议库,专为需要低延迟和高可靠性的实时应用设计。本文针对 KCP 的主要机制和实现与原理进行分析。
1. 术语
| 术语 | 全称 | 说明 |
| TCP | Transmission Control Protocol | 传输控制协议 |
| RTT | Round Trip Time | 往返时延 |
| RTO | Retransmission Time Out | 重传超时 |
| ACK | ACKnowledgement | 确认 |
| NACK | Negative Acknowledgement | 否定确认 |
| SACK | Selective Acknowledgement | 选择性确认 |
| ARQ | Automatic Repeat Query | 自动重传请求 |
ARQ 和 NACK 的区别
An ARQ is usually implemented in a protocol as a way to automatically trigger a retransmission of data that was not received in the time expected.
A NACK is an explicit protocol message sent by a recipient to report that a specific, expected signal must be re-sent for some reason. Protocols that use NACK messages often include the ability to report on the reason the message is being NACKed.
简单总结,ARQ 是发送端根据反馈信息主动进行重传,NACK 是接收端根据丢包情况主动要求发端重传。
2. TCP
KCP 针对 TCP 相关机制做了简化和改进,在分析 KCP 实现原理之前,有必要对 TCP 相关机制做一个简单了解。这部分内容大家都比较熟悉,在网络上也能快速找到,放到这里以备查验,熟悉的同学可以跳过。
2.1 协议头
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|P|R|S|F| |
| Offset| Reserved |R|C|S|S|Y|I| Window |
| | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+Source Port 和 Destination Port:
计算机上的进程要和其他进程通信是要通过计算机端口的,而一个计算机端口某个时刻只能被一个进程占用,所以通过指定源端口和目标端口,就可以知道是哪两个进程需要通信。源端口、目标端口是用16位表示的,可推算计算机的端口个数为2^16个。
Sequence Number:
表示本报文段所发送数据的第一个字节的编号。在TCP连接中所传送的字节流的每一个字节都会按顺序编号。由于序列号由32位表示,所以每2^32个字节,就会出现序列号回绕,再次从 0 开始。
Acknowledgement Number:
表示接收方期望收到发送方下一个报文段的第一个字节数据的编号。也就是告诉发送方:我希望你(指发送方)下次发送的数据的第一个字节数据的编号为此确认号。
Data Offset:
表示TCP报文段的首部长度,共4位,由于TCP首部包含一个长度可变的选项部分,需要指定这个TCP报文段到底有多长。它指出 TCP 报文段的数据起始处距离 TCP 报文段的起始处有多远。该字段的单位是32位(即4个字节为计算单位),4位二进制最大表示15,所以数据偏移也就是TCP首部最大60字节。
URG:
表示本报文段中发送的数据是否包含紧急数据。后面的紧急指针字段(urgent pointer)只有当URG=1时才有效。
ACK:
表示是否前面确认号字段是否有效。只有当ACK=1时,前面的确认号字段才有效。TCP规定,连接建立后,ACK必须为1,带ACK标志的TCP报文段称为确认报文段。
PSH:
提示接收端应用程序应该立即从TCP接收缓冲区中读走数据,为接收后续数据腾出空间。如果为1,则表示对方应当立即把数据提交给上层应用,而不是缓存起来,如果应用程序不将接收到的数据读走,就会一直停留在TCP接收缓冲区中。
RST:
如果收到一个RST=1的报文,说明与主机的连接出现了严重错误(如主机崩溃),必须释放连接,然后再重新建立连接。或者说明上次发送给主机的数据有问题,主机拒绝响应,带RST标志的TCP报文段称为复位报文段。
SYN:
在建立连接时使用,用来同步序号。当SYN=1,ACK=0时,表示这是一个请求建立连接的报文段;当SYN=1,ACK=1时,表示对方同意建立连接。SYN=1,说明这是一个请求建立连接或同意建立连接的报文。只有在前两次握手中SYN才置为1,带SYN标志的TCP报文段称为同步报文段。
FIN:
表示通知对方本端要关闭连接了,标记数据是否发送完毕。如果FIN=1,即告诉对方:“我的数据已经发送完毕,你可以释放连接了”,带FIN标志的TCP报文段称为结束报文段。
Window:
表示现在允许对方发送的数据量,也就是告诉对方,从本报文段的确认号开始允许对方发送的数据量,达到此值,需要ACK确认后才能再继续传送后面数据,由Window size value * Window size scaling factor(此值在三次握手阶段TCP选项Window scale协商得到)得出此值。
Checksum:
提供额外的可靠性。
Urgent Pointer:
标记紧急数据在数据字段中的位置。
Options:
其最大长度可根据TCP首部长度进行推算。TCP首部长度用4位表示,选项部分最长为:(2^4-1)*4-20=40字节。
2.2 流量控制
双方在通信的时候,发送方的速率与接收方的速率是不一定相等,如果发送方的发送速率太快,会导致接收方处理不过来,这时候接收方只能把处理不过来的数据存在缓存区里。如果缓存区满了发送方还在疯狂着发送数据,接收方只能把收到的数据包丢掉,大量的丢包会极大着浪费网络资源,因此,需要控制发送方的发送速率,让接收方与发送方处于一种动态平衡。对发送方发送速率的控制,我们称之为流量控制。
流量控制包含以下几部分逻辑:
1)接收方每次收到数据包,在发送确定报文的时候,同时告诉发送方自己的缓存区还剩余多少是空闲的,把缓存区的剩余大小称之为接收窗口大小,用变量win来表示接收窗口的大小。发送方收到之后,便会调整自己的发送速率,当发送方收到接收窗口的大小为0时,发送方就会停止发送数据,防止出现大量丢包情况的发生。
2)当接收方处理好数据,接收窗口 win > 0 时,接收方发个通知报文去通知发送方,告诉他可以继续发送数据了。当发送方收到窗口大于0的报文时,就继续发送数据。
3)不过这时候可能会遇到一个问题,假如接收方发送的通知报文,由于某种网络原因,这个报文丢失了,这时候就会引发一个问题:接收方发了通知报文后,继续等待发送方发送数据,而发送方则在等待接收方的通知报文,此时双方会陷入一种僵局。为了解决这种问题,TCP采用了另外一种策略:当发送方收到接受窗口 win = 0 时,这时发送方停止发送报文,并且同时开启一个定时器,每隔一段时间就发个测试报文去询问接收方,打听是否可以继续发送数据了,如果可以,接收方就告诉他此时接受窗口的大小;如果接受窗口大小还是为0,则发送方再次刷新启动定时器。
2.3 拥塞控制
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络性能就要变坏,这种情况就叫做网络拥塞。
TCP拥塞控制的两个重要变量:
1)cwnd - Congestion Window:拥塞窗口
2)ssthresh - Slow Start Threshold:慢启动阈值
TCP 拥塞控制分为以下几个阶段:
1)慢启动
cwnd 从 1 开始,收到确认后,指数增加。慢启动是指初始发送报文个数少,但增长发送速率上升并不慢。
2)拥塞避免
当 cwnd 达到 ssthresh 时,进入拥塞避免阶段,拥塞窗口线性增加,直到出现超时重传。
3)超时重传
出现超时重传时,认为网络拥塞非常严重,将 ssthresh 砍半,重新进入慢启动阶段。
4)快速恢复
如果出现快速重传(收到 3 个重复确认),认为网络拥塞不是非常严重,将 ssthresh 砍半,重新进入拥塞避免阶段。

linux3.0 以前,内核默认的 initcwnd 比较小,MSS 为 1460 时,初始的拥塞控制窗口为 3。
linux3.0 以后,采取了 Google 的建议,把初始拥塞控制窗口调到了 10。
2.4 丢包重传
TCP 丢包重传有几种机制,分别是超时重传、快速重传和选择重传。
2.4.1 超时重传
超时重传机制比较好理解,最麻烦的就是超时时间 RTO 的计算。设置太大,则很长时间才进行重传,效率太低;设置太小,可能会引起不必要的重传。因此,RTO 需要根据网络延时动态调整,网络延迟越大,则超时时间应该越长。典型的 RTO 计算有一下两种算法:
1)经典方法
// RTT 是指最新的样本值,这种估算方法叫做「指数加权移动平均」,名字听起来比较高大上,
// 但整个公式比较好理解,就是利用现存的 SRTT 值和最新测量到的 RTT 值取一个加权平均。
SRTT = α·SRTT +(1 - α)·RTT
// 这里面的 ubound 是 RTO 的上边界,lbound 为 RTO 的下边界,β 称为时延离散因子,
// 推荐值为 1.3 ~ 2.0。
RTO = min(ubound, max(lbound, (SRTT)·β))经典方法存在以下两个问题:
1)重传二义性问题
没办法区分 ACK 是正常响应还是重传响应,会导致 RTO 计算不准。
2)对突变 RTT 不敏感
这个算法假设 RTT 波动比较小,因为这个加权平均的算法又叫低通滤波器,对突然的网络波动不敏感。如果网络时延突然增大导致实际 RTT 值远大于估计值,会导致不必要的重传,增大网络负担。
2)标准方法
标准方法的整体思想是结合平均值和平均偏差来进行估算,如下所示。
// 跟经典方法一样,求 SRTT 的加权平均
SRTT = α·RTT + (1 - α)·SRTT
// 计算 SRTT 与真实值的差距(称之为绝对误差|Err|),同样用到加权平均
rttvar = (1 - h)·rttvar + h·(|RTT - SRTT |)
// RTO为平滑RTT加上4倍平均偏差
RTO = SRTT + 4·rttvar2.4.2 快速重传
基于 RTO 的重传,可以认为链路已经非常拥塞,情况比较严重,直接切换到慢启动阶段,比较低效。事实上,引起丢包的原因可能是多样的,比如乱序、误码以及其他随机事件,如果仅仅因为一个丢包,就重新进入慢启动阶段,有点太过激进。因此,TCP 引入了快速重传机制:如果连续收到3次相同的 ACK,发送端立即重传丢失报文,不用等到 RTO 超时。
2.4.3 选择重传
快速重传还有个问题不能解决,那就是不知道要重传多少个报文。为了解决这个问题,TCP 引入了 SACK 机制,简单理解,就是在快速重传基础上,加上收到报文段的序列号范围,这样,发送端就知道哪些数据已经被接收到。
SACK 特性是 TCP 的一个可选特性,是否启用需要收发双发进行协商,通信双发在 SYN 段或SYN+ACK 段中添加 SACK 允许选项通知对端本端是否支持 SACK,如果双发都支持,那么后续连接态通信过程中就可以使用 SACK 选项了。SACK 允许选项只能出现在 SYN 段中。
3. KCP
3.1 整体架构
KCP 整体架构可以用下图表示。可以将 KCP 看成是应用层协议栈,应用层调用接口向 KCP 发送数据和从 KCP 接收报文;同时,需要将从网络接收的报文送入 KCP 以及提供向网络发送数据的回调接口;另外,还需要定时调用 KCP 接口驱动其内部运行(也有其他方式)。

3.2 对外接口
KCP 核心接口不多,设计简洁,易于理解,值得借鉴。
// 创建和释放KCP上下文,每个连接对应一个上下文
ikcpcb* ikcp_create(IUINT32 conv, void *user);
void ikcp_release(ikcpcb *kcp);
// 设置数据发送接口,KCP内部会使用设置的接口向网卡发送数据
void ikcp_setoutput(ikcpcb *kcp, int (*output)(const char *buf, int len,
ikcpcb *kcp, void *user));
// 调用此接口从KCP收取数据
int ikcp_recv(ikcpcb *kcp, char *buffer, int len);
// 调用此接口向KCP发送数据
int ikcp_send(ikcpcb *kcp, const char *buffer, int len);
// 周期调用此接口驱动KCP内部运转(定时器驱动),内部会调用ikcp_flush
void ikcp_update(ikcpcb *kcp, IUINT32 current);
// 调用此接口询问是否需要调用ikcp_update,当没有ikcp_input和ikcp_send调用时,其实没必要
// 调用ikcp_update,从而提升应用性能
IUINT32 ikcp_check(const ikcpcb *kcp, IUINT32 current);
// 从网卡收到数据调用此接口将报文送入KCP处理
int ikcp_input(ikcpcb *kcp, const char *data, long size);
// 正常是通过ikcp_update调用,支持手动调用
void ikcp_flush(ikcpcb *kcp);
// 查询接收队列下一个报文大小
int ikcp_peeksize(const ikcpcb *kcp);
// 设置MTU,默认是1400,KCP基于MTU进行报文分片
int ikcp_setmtu(ikcpcb *kcp, int mtu);
// 设置最大发送窗口和最大接收窗口,发送窗口和接收窗口默认为32,单位是报文
int ikcp_wndsize(ikcpcb *kcp, int sndwnd, int rcvwnd);
// 查询发送队列和发送缓冲区总的报文大小
int ikcp_waitsnd(const ikcpcb *kcp);
// fastest: ikcp_nodelay(kcp, 1, 20, 2, 1)
// nodelay: 0:disable(default), 1:enable
// interval: 定时器调用间隔,单位ms,默认100ms
// resend: 快速重传开关,0:关闭(default), 1:打开
// nc: 拥塞控制开关,0:打开(default), 1:关闭
int ikcp_nodelay(ikcpcb *kcp, int nodelay, int interval, int resend, int nc);3.3 报文结构
KCP 报文头占用 24 各字节,有些报文携带数据,有些报文只有报文头,各字段如下图所示。虽然报文头不够紧凑,没有有效利用到所有bit位,但整体看起来比较整齐(字节对齐),便于程序实现。
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| conv |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| cmd | frag | wnd |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ts |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| sn |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| una |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| len |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
| data(optional) |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+conv: conversation id
会话标识,可以将高 16 位和低 16 位分别分配给客户端和服务器使用,用来标识本地会话,而且一起标识一个唯一会话。
cmd: command
KCP 定义的报文类型非常简洁,总共只有四种报文。
const IUINT32 IKCP_CMD_PUSH = 81; // cmd: push data
const IUINT32 IKCP_CMD_ACK = 82; // cmd: ack
const IUINT32 IKCP_CMD_WASK = 83; // cmd: window probe (ask)
const IUINT32 IKCP_CMD_WINS = 84; // cmd: window size (tell)frag: fragment
分片标识,KCP 基于 MTU 来进行分片,减少 IP 层分片几率,提升抗丢包能力。
wnd: window size
接收队列长度,接收窗口大小减去在接收队列中还未被应用层收取的报文数。
static int ikcp_wnd_unused(const ikcpcb *kcp)
{
if (kcp->nrcv_que < kcp->rcv_wnd) {
return kcp->rcv_wnd - kcp->nrcv_que;
}
return 0;
}ts: timestamp
每个报文发送都需要打上时间戳
sn: serial number
报文序列号,只有 IKCP_CMD_PUSH 报文才有序列号,其他报文的序列号为0。
una: un-acknowledged serial number
通告在此之前的报文都已经收到,结合 ACK,发送方能够进行快速重传。
3.4 核心概念
要搞清楚 KCP 的传输机制,需要理解其中几个核心概念和它们之间的关系,以及它们如何配合完成传数据传输、拥塞控制等复杂逻辑。下图是 KCP 传输机制的一个抽象表达,里面包含了 KCP 中的几个重要变量。
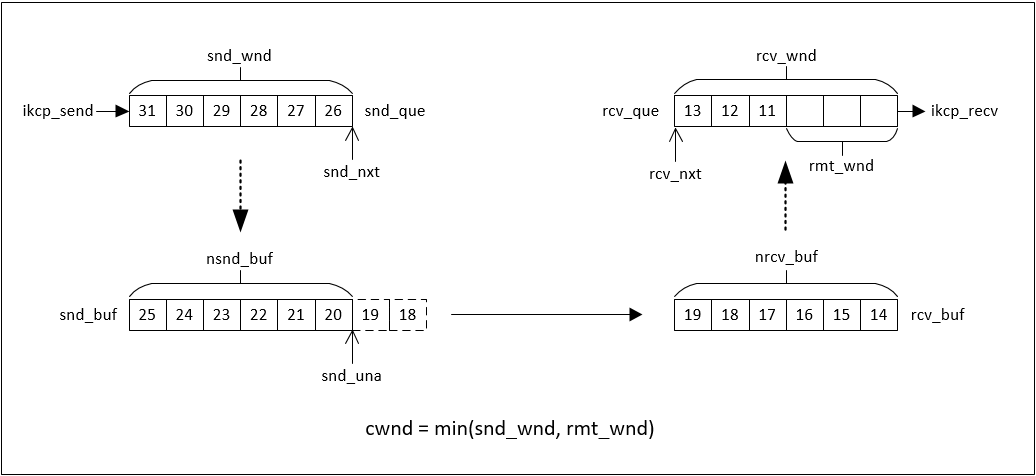
1)snd_wnd
发送窗口,对应snd_que的最大长度,用来控制发送速率。
2)rcv_wnd
接收窗口,对应rcv_que的最大长度,用来控制接收速录。
3)rmt_wnd
接收端反馈给发送端的接收窗口剩余空间大小,用来做流量控制。
4)cwnd
拥塞窗口,拥塞窗口的计算如上图所示:cwnd = min(snd_wnd, rmt_wnd),用来做拥塞控制。
KCP传输机制大概可以描述如下:
1)发送端和接收端设置发送窗口和接收窗口大小。
2)发送端调用ikcp_send发送报文,报文放到snd_que后立即返回。
3)发送端应用层周期性调用ikcp_update,触发报文发送。
4)发送端根据地拥塞窗口大小,将一定数量的报文移动snd_buf,并发送到网络。
5)接收端收到报文后,将报文放入rcv_buf正确的位置(排序)。
6)接收端根据rcv_nxt,从rcv_buf中将排序好的报文移动到rcv_que。
7)接收端应用层周期性调用ikcp_update,触发发送ACK到发送端。
8)发送端根据ACK的SN将对应报文从snd_buf中移除。3.5 具体实现
3.5.1 RTO
RTO 决定重传超时时间,它是一个动态值,准确的 RTO 计算,有利于提高重传效率,因此 RTO 的计算非常重要。
3.5.1.1 RTO 初始化
通过 nodelay 来设置 rx_minrto 的下限值
int ikcp_nodelay(ikcpcb *kcp, int nodelay, int interval, int resend, int nc)
{
if (nodelay >= 0) {
kcp->nodelay = nodelay;
if (nodelay) {
kcp->rx_minrto = IKCP_RTO_NDL;
}
else {
kcp->rx_minrto = IKCP_RTO_MIN;
}
}
...
}const IUINT32 IKCP_RTO_NDL = 30; // no delay min rto
const IUINT32 IKCP_RTO_MIN = 100; // normal min rto
const IUINT32 IKCP_RTO_DEF = 200;
const IUINT32 IKCP_RTO_MAX = 60000;平滑 RTO 初始设置为默认值
ikcpcb* ikcp_create(IUINT32 conv, void *user)
{
ikcpcb *kcp = (ikcpcb*)ikcp_malloc(sizeof(struct IKCPCB));
if (kcp == NULL) return NULL;
...
kcp->rx_rto = IKCP_RTO_DEF;
kcp->rx_minrto = IKCP_RTO_MIN;
...
return kcp;
}3.5.1.2 RTO 计算
每个连接的 RTO 独立计算,主要参考 TCP 的 RTO 算法。基本原理是基于 ACK 计算出来的 RTT 来更新 RTO。
static void ikcp_update_ack(ikcpcb *kcp, IINT32 rtt)
{
IINT32 rto = 0;
if (kcp->rx_srtt == 0) {
kcp->rx_srtt = rtt;
kcp->rx_rttval = rtt / 2;
} else {
long delta = rtt - kcp->rx_srtt;
if (delta < 0) {
delta = -delta;
}
// h = 1/4
kcp->rx_rttval = (3 * kcp->rx_rttval + delta) / 4;
// α = 1/8
kcp->rx_srtt = (7 * kcp->rx_srtt + rtt) / 8;
if (kcp->rx_srtt < 1) {
kcp->rx_srtt = 1;
}
}
rto = kcp->rx_srtt + _imax_(kcp->interval, 4 * kcp->rx_rttval);
kcp->rx_rto = _ibound_(kcp->rx_minrto, rto, IKCP_RTO_MAX);
}
TCP 的 RTO 计算方法可以简单用下面的公式表示。
//---------------------------------------------------------------------
// 1) SRTT <- (1 - α)·SRTT + α·RTT
// 2) rttvar <- (1 - h)·rttvar + h·(|RTT - SRTT|)
// 3) RTO = SRTT + 4·rttvar
//---------------------------------------------------------------------3.5.2 丢包重传
KCP 属于可靠协议,因此会对丢失报文要进行重传,直到重传成功。KCP 的重传机制有以下两种:
3.5.2.1 基于 RTO 超时的重传
前面已经讲过,KCP 中 RTO 的计算是参考 TCP 实现。简单解释,报文第一次发送设置报文的RTO,后面每次重传都会增加 RTO。其中,第一次发送设置的 RTO 会加上rtomin,rtomin的计算比较奇怪,受 nodelay 影响,这里还没探究这样做的真实效果。
void ikcp_flush(ikcpcb *kcp)
{
...
// 开始发送数据
for (p = kcp->snd_buf.next; p != &kcp->snd_buf; p = p->next) {
IKCPSEG *segment = iqueue_entry(p, IKCPSEG, node);
int needsend = 0;
// 第一次发送
if (segment->xmit == 0) {
needsend = 1;
segment->xmit++;
segment->rto = kcp->rx_rto;
// 基于RTO设置重传时间
segment->resendts = current + segment->rto + rtomin;
}
// 超时重传
else if (_itimediff(current, segment->resendts) >= 0) {
needsend = 1;
segment->xmit++;
kcp->xmit++;
// 更新RTO
if (kcp->nodelay == 0) { // delay模式:重传一次,RTO加倍(至少)
segment->rto += _imax_(segment->rto, (IUINT32)kcp->rx_rto);
} else { // nodelay模式:重传一次,RTO加的少一些
// kcp->nodelay < 2?
IINT32 step = (kcp->nodelay < 2) ? ((IINT32)(segment->rto)) : kcp->rx_rto;
segment->rto += step / 2;
}
// 更新下次重传时间
segment->resendts = current + segment->rto;
lost = 1;
}
// 快速重传
else if (segment->fastack >= resent) {
if ((int)segment->xmit <= kcp->fastlimit || kcp->fastlimit <= 0) {
needsend = 1;
segment->xmit++;
segment->fastack = 0;
// 基于RTO设置下次重传时间
segment->resendts = current + segment->rto;
change++;
}
}
...
}
...
}3.5.2.2 基于 ACK 的快速重传
收到一个 ACK,从前往后遍历发送缓冲区,对 SN 号小于 ACK SN 号的报文标记一次 fastack。
static void ikcp_parse_fastack(ikcpcb *kcp, IUINT32 sn, IUINT32 ts)
{
struct IQUEUEHEAD *p, *next;
if (_itimediff(sn, kcp->snd_una) < 0 || _itimediff(sn, kcp->snd_nxt) >= 0)
return;
for (p = kcp->snd_buf.next; p != &kcp->snd_buf; p = next) {
IKCPSEG *seg = iqueue_entry(p, IKCPSEG, node);
next = p->next;
if (_itimediff(sn, seg->sn) < 0) {
break; // 比第一个segmetn的sn小,不用再遍历了
}
// sn大于segment的sn,则累加跳过次数
else if (sn != seg->sn) {
#ifndef IKCP_FASTACK_CONSERVE
seg->fastack++;
#else
if (_itimediff(ts, seg->ts) >= 0)
seg->fastack++;
#endif
}
}
}在 ikcp_flush 处理流程中,如果发现发送缓冲区中报文的 fastack 超过设置的快速重传上限,则触发快速重传。
快速重传是有上限的,KCP 默认上限是 5,如果报文被重传了 5 次,不管是 RTO 超时的重传还是快速重传,此报文不再启用快速重传机制,而是依赖 RTO 超时重传。
3.5.3 报文分片
KCP 发送的数据如果太长,则会进行分片,叫做 fragment ,不需要分片可以认为只有一个分片,因此,KCP 发送的数据都是 fragment 。
KCP 基于 MTU 对报文进行分片,因为如果依赖 IP 层的分片机制,IP 层如果发生错误(丢包),将导致丢弃整个 IP 数据报,接收方无法进行细粒度的重传。
KCP 在发送端进行分片,在接收端需要将分片的 fragment 重新组包。这里有两个地方需要注意:
1)如果数据包比较长,会被切分为多个分片,若果接收端的接收队列长度太短,无法进行报文重组,就无法接收完整的数据包。因此,KCP 要求设置接收窗口大小时,要考虑分片的影响。
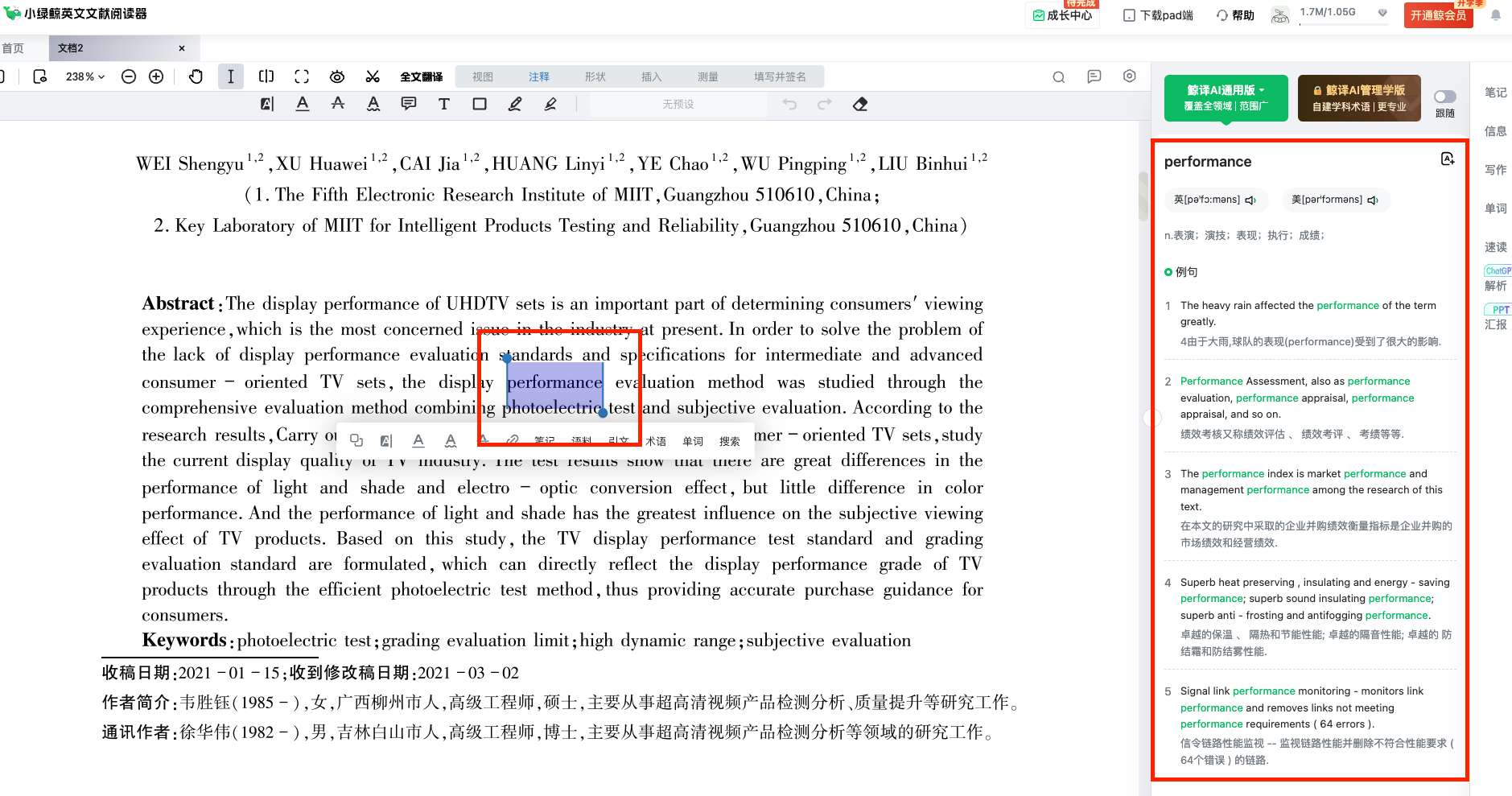
2)KCP 的报文头中只有 fragment 的序号,没有字段标识一个包有多少个 fragment,为了便于接收端区分不同的包,发送端的 fragment 采用从高到低的方式编号,如下图所示:

这种排序下,接收端只要遇到 fragment 为0,知道这个包只有一个 fragment,可以直接送给应用层;如果 fragment 不为0,则将此分片和下一个 fragment 为 0 之间的分片重组为 1个 包送给应用层。

如果采用从低到高的方式编号,这种排序下,接收端遇到 fragment 为 0 的分片,还需要判断下一个fragment 是否为 0,如果下一个 fragment 也为 0,则表示此包只有一个分片,可以直接送给应用层;如果下一个 fragment 不为 0,则将此分片和下一个 framgment 为 0 之间的分片重组为 1 个包送给应用层。
3.5.4 流量控制
KCP 流量控制与 TCP 类似,控制机制可以简单描述为:
1)在报文头部有 wnd 字段,用来通告接收端窗口大小,当接收窗口大小为 0 时,发送端停止发送。
2)当接收窗口从 0 变为正时,接收端会主动通告发送端。
3)发送端收到接收端窗口为 0 时,为了避免由于窗口通告丢失导致“死等”情况,会启动定时器,定时探查接收端窗口大小。
3.5.5 拥塞控制
KCP 的拥塞控制和 TCP 的拥塞控制机制基本类似:
1)当发生快速重传时(change),更新 ssthresh 为 inflight 的一半,cwnd 也相应调整。
2)当发生超时重传时(lost),更新 ssthresh 为 cwnd 的一半,cwnd 重新设置为 1。
void ikcp_flush(ikcpcb *kcp)
{
...
// 快速重传:拥塞窗口和慢启动阈值调整为inflight的一半
if (change) {
IUINT32 inflight = kcp->snd_nxt - kcp->snd_una;
kcp->ssthresh = inflight / 2;
if (kcp->ssthresh < IKCP_THRESH_MIN) {
kcp->ssthresh = IKCP_THRESH_MIN;
}
kcp->cwnd = kcp->ssthresh + resent;
kcp->incr = kcp->cwnd * kcp->mss;
}
// 超时重传:拥塞窗口从1开始,慢启动阈值减半
if (lost) {
kcp->ssthresh = cwnd / 2;
if (kcp->ssthresh < IKCP_THRESH_MIN) {
kcp->ssthresh = IKCP_THRESH_MIN;
}
kcp->cwnd = 1;
kcp->incr = kcp->mss;
}
// 校正cwnd
if (kcp->cwnd < 1) {
kcp->cwnd = 1;
kcp->incr = kcp->mss;
}
}收到 ACK 后,重新调整 cwnd,但 cwnd 永远不会超过 rmt_wnd。可以看到,cwnd < ssthresh时,在 TCP 中定义为慢启动阶段,cwnd 的初始值比较小,但是是以指数增长的。在 KCP 中,cwnd 在这个阶段是线性增长的,但初始值一开始就是参考 rmt_wnd 设置,可以认为没有慢启动阶段,或者说,慢启动起点非常高。
int ikcp_input(ikcpcb *kcp, const char *data, long size)
{
...
// 新拥塞窗口
if (_itimediff(kcp->snd_una, prev_una) > 0) {
if (kcp->cwnd < kcp->rmt_wnd) { // 保证拥塞窗口小于远端接收窗口
IUINT32 mss = kcp->mss;
// 慢启动阶段,cwnd每次+1
if (kcp->cwnd < kcp->ssthresh) {
kcp->cwnd++;
kcp->incr += mss;
// 拥塞避免阶段
} else {
if (kcp->incr < mss) {
kcp->incr = mss;
}
// incr越大cwnd增长越慢,直到cwnd不再增长
kcp->incr += (mss * mss) / kcp->incr + (mss / 16);
if ((kcp->cwnd + 1) * mss <= kcp->incr) {
#if 1
kcp->cwnd = (kcp->incr + mss - 1) / ((mss > 0) ? mss : 1);
#else
kcp->cwnd++;
#endif
}
}
// 校正cwnd
if (kcp->cwnd > kcp->rmt_wnd) {
kcp->cwnd = kcp->rmt_wnd;
kcp->incr = kcp->rmt_wnd * mss;
}
}
}
return 0;
}3.6 其他
3.6.1 线程模型
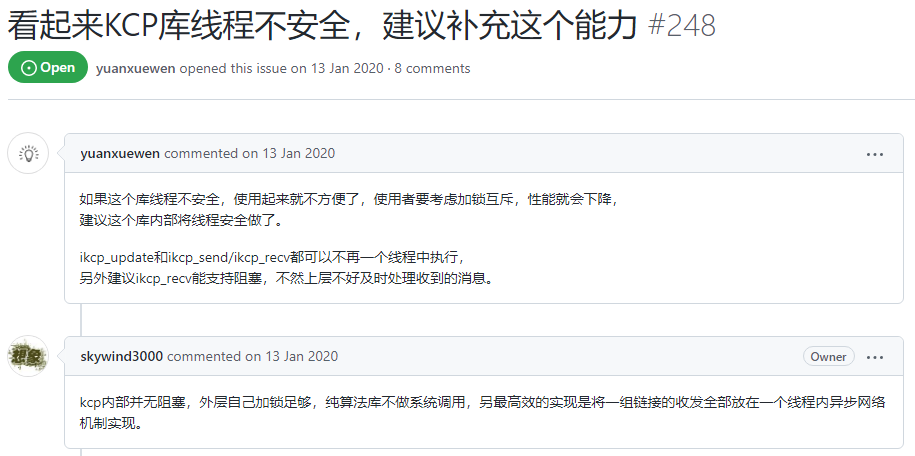
KCP 是纯算法实现,里面没有任何系统调用,连定时器都需要外部驱动,因此不是线程安全的,需要外部做多线程设计和保护。
具体为什么作者要这么设计,以及如何与多线程整合,以下连接做了较详细的回答:
看起来KCP库线程不安全,建议补充这个能力 · Issue #248 · skywind3000/kcp · GitHub
3.6.2 拥塞反馈
KCP 不会向应用层反馈网络拥塞情况,即使出现拥塞,导致网络带宽下降,KCP 也不会拒绝应用层继续发送报文,这些报文都会保存在发送队列中。
3.6.3 IKCP_FASTACK_CONSERVE
如果开启此宏,收到 ACK,更新快速重传计数时,只对在本报文发送时间之后的 ACK 进行计数。
4. 参考文献
KCP 协议与源码分析(一)_kcp源码分析-CSDN博客
TCP的拥塞控制(详解)-CSDN博客
https://zhuanlan.zhihu.com/p/101702312
GitHub - skywind3000/kcp: :zap: KCP - A Fast and Reliable ARQ Protocol