快手C++一面,体验感非常nice!!!
公众号:阿Q技术站
来源:https://www.nowcoder.com/discuss/660221651866468352
算法
1、括号匹配
这里暂且以20. 有效的括号来解答。
思路
- 初始化一个空栈:使用栈来存放左括号,每当遇到一个左括号时,就将其压入栈中。
- 遍历字符串:从头到尾遍历字符串中的每个字符。
- 处理括号:
- 如果当前字符是左括号(
'(','{','['),将其压入栈中。 - 如果当前字符是右括号(
')','}',']'),需要判断栈顶的左括号是否与其匹配。如果匹配,则将栈顶的左括号出栈;否则,返回 false。
- 如果当前字符是左括号(
- 判断栈是否为空:在遍历完整个字符串后,需要检查栈是否为空。如果栈为空,说明所有的括号都有匹配的右括号,返回 true;否则,返回 false。
参考代码
C++
#include <iostream>
#include <stack>
#include <unordered_map>
using namespace std;
bool isValid(string s) {
stack<char> stk; // 用于存放左括号的栈
unordered_map<char, char> mappings = {
{')', '('},
{'}', '{'},
{']', '['}
}; // 用于存放右括号与其对应的左括号的映射关系
// 遍历输入字符串
for (char c : s) {
// 如果是左括号,压入栈中
if (c == '(' || c == '{' || c == '[') {
stk.push(c);
} else {
// 如果是右括号
// 判断栈是否为空或者栈顶元素是否与当前右括号匹配
if (stk.empty() || stk.top() != mappings[c]) {
return false; // 不匹配,返回 false
}
stk.pop(); // 匹配,将栈顶元素出栈
}
}
// 最后判断栈是否为空,如果为空则说明所有括号都匹配
return stk.empty();
}
int main() {
string s = "{[()]}";
cout << isValid(s) << endl; // 输出 1,表示有效
s = "{[(])}";
cout << isValid(s) << endl; // 输出 0,表示无效
return 0;
}
2、数字字符串分割为网络ip
这里以93. 复原 IP 地址来解答。
思路
-
IP 地址的组成规则:IP 地址由四部分组成,每部分是一个 0 到 255 的整数,且不能有前导零(例如,“01” 不是有效的,但 “0” 是有效的)。
-
字符串长度约束:
-
有效的 IP 地址每部分最多有 3 位数字。
-
一个有效的 IP 地址总共最多有 12 个字符(4 部分,每部分最多 3 个字符,且有 3 个点分隔符)。
-
因此,给定的字符串
s如果长度小于 4 或大于 12,则不可能形成有效的 IP 地址。
-
-
回溯法解决问题:
-
需要尝试在不同的位置插入 3 个
.,使得字符串被分成 4 部分。 -
每次递归时,检查当前部分是否可以形成一个有效的 IP 地址部分(范围在 0 到 255 之间,且无前导零)。
-
如果找到一个有效的 IP 地址,将其加入结果集。
-
参考代码
C++
#include <iostream>
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
vector<string> restoreIpAddresses(string s) {
vector<string> result; // 存储所有可能的有效 IP 地址
vector<string> current; // 存储当前正在生成的 IP 地址
backtrack(s, 0, current, result);
return result;
}
private:
// 回溯函数
void backtrack(const string& s, int start, vector<string>& current, vector<string>& result) {
if (current.size() == 4) { // 如果已经形成了 4 段
if (start == s.size()) { // 且用完了所有字符
result.push_back(join(current)); // 将当前形成的 IP 地址加入结果集
}
return;
}
for (int len = 1; len <= 3; ++len) { // 每段 IP 地址的长度可能为 1 到 3
if (start + len > s.size()) break; // 如果剩下的字符不够长度,直接退出循环
string segment = s.substr(start, len); // 取出当前段的字符串
if (isValid(segment)) { // 检查当前段是否为有效 IP 地址段
current.push_back(segment); // 将当前段加入当前 IP 地址
backtrack(s, start + len, current, result); // 递归处理剩余字符串
current.pop_back(); // 回溯,移除最后加入的段
}
}
}
// 检查一个 IP 地址的段是否有效
bool isValid(const string& segment) {
if (segment.size() > 1 && segment[0] == '0') return false; // 不能有前导零
int num = stoi(segment); // 将字符串转为整数
return num >= 0 && num <= 255; // 检查整数是否在 0 到 255 之间
}
// 将 IP 地址的四个部分用 '.' 连接起来形成最终的 IP 地址字符串
string join(const vector<string>& segments) {
string ip;
for (int i = 0; i < segments.size(); ++i) {
if (i > 0) ip += ".";
ip += segments[i];
}
return ip;
}
};
// 主函数
int main() {
Solution solution;
string s = "25525511135";
vector<string> result = solution.restoreIpAddresses(s);
cout << "输出:" << endl;
for (const string& ip : result) {
cout << ip << endl;
}
return 0;
}
C++
1、面向对象三特性?
1. 封装
封装是指将对象的属性(数据成员)和方法(成员函数)捆绑在一起,形成一个独立的单元。通过封装,数据和方法可以隐藏在对象内部,从而控制对数据的访问和修改。这可以通过访问控制符(private, protected, public)来实现。
private:私有成员只能在类的内部访问,不能在类的外部直接访问。protected:受保护成员可以在类的内部及其子类中访问。public:公共成员可以在类的内部和外部访问。
class Car {
private:
int speed; // 私有属性,无法直接从类外部访问
public:
void setSpeed(int s) { // 公有方法,通过方法来访问或修改私有数据
speed = s;
}
int getSpeed() const { // 公有方法,提供访问私有数据的接口
return speed;
}
};
2. 继承
继承是指一个类(子类)可以继承另一个类(基类)的属性和方法,从而重用代码并建立类之间的层次关系。继承允许我们创建一个新类,同时拥有现有类的功能,并能扩展或重写现有功能。
继承的类型主要有:
- 单继承:一个类继承自一个基类。
- 多继承:一个类可以继承自多个基类(C++ 支持多继承)。
class Vehicle {
public:
void move() {
cout << "Vehicle is moving" << endl;
}
};
class Car : public Vehicle { // Car类继承自Vehicle类
public:
void honk() {
cout << "Car is honking" << endl;
}
};
例子中,Car 类继承了 Vehicle 类,所以 Car 对象可以调用 Vehicle 类的 move 方法。
3. 多态
多态是指在继承层次结构中,不同类的对象对同一消息(方法调用)可以作出不同的响应。多态的实现通常通过**函数重载(Overloading)和虚函数(Virtual Functions)**来实现。
- 函数重载:同一个类中可以有多个同名函数,但参数列表不同。
- 虚函数和动态绑定:通过使用虚函数(
virtual关键字),派生类可以重写基类的方法。使用指向基类的指针或引用来调用这些方法时,会根据实际的对象类型调用相应的方法,实现运行时多态。
class Animal {
public:
virtual void speak() { // 声明虚函数
cout << "Animal sound" << endl;
}
};
class Dog : public Animal {
public:
void speak() override { // 重写基类中的虚函数
cout << "Woof" << endl;
}
};
class Cat : public Animal {
public:
void speak() override {
cout << "Meow" << endl;
}
};
int main() {
Animal* animal1 = new Dog(); // 基类指针指向派生类对象
Animal* animal2 = new Cat();
animal1->speak(); // 输出: Woof
animal2->speak(); // 输出: Meow
delete animal1;
delete animal2;
return 0;
}
例子中,Dog 和 Cat 类都继承了 Animal 类,并重写了 speak 方法。通过使用基类指针调用 speak 方法时,根据实际对象类型(Dog 或 Cat)输出不同的结果,体现了多态的特性。
2、一个空类会自动生成哪几个函数?
1. 默认构造函数
- 作用:默认构造函数用于创建类的对象,并执行初始化操作。即使没有定义,编译器也会生成一个不带参数的默认构造函数。
- 形式:
ClassName() {}
class Empty {};
int main() {
Empty obj; // 调用编译器生成的默认构造函数
return 0;
}
代码中,Empty 类没有显式定义构造函数,但编译器会生成一个默认构造函数 Empty()。
2. 拷贝构造函数
- 作用:拷贝构造函数用于创建一个新对象,并将另一个对象的值复制到新对象中。即使没有定义,编译器也会生成一个默认的拷贝构造函数。
- 形式:
ClassName(const ClassName& other)
class Empty {};
int main() {
Empty obj1;
Empty obj2 = obj1; // 调用编译器生成的拷贝构造函数
return 0;
}
代码中,obj2 是通过 obj1 初始化的,编译器会生成一个拷贝构造函数来完成对象的复制。
3. 拷贝赋值运算符
- 作用:拷贝赋值运算符用于将一个对象的值赋给另一个已经存在的对象。即使没有定义,编译器也会生成一个默认的拷贝赋值运算符。
- 形式:
ClassName& operator=(const ClassName& other)
class Empty {};
int main() {
Empty obj1;
Empty obj2;
obj2 = obj1; // 调用编译器生成的拷贝赋值运算符
return 0;
}
代码中,obj2 = obj1 通过编译器生成的默认拷贝赋值运算符来执行赋值操作。
4. 默认析构函数
- 作用:析构函数用于在对象的生命周期结束时清理资源。即使没有定义,编译器也会生成一个默认的析构函数。
- 形式:
~ClassName() {}
class Empty {};
int main() {
Empty obj; // 当 `obj` 超出作用域时,调用编译器生成的默认析构函数
return 0;
}
在上面的代码中,当 obj 超出其作用域时,编译器生成的默认析构函数会被调用来销毁 obj 对象。
3、哪些函数不能是虚函数?
1. 构造函数
构造函数不能是虚函数。构造函数的主要作用是初始化对象的成员数据,在对象创建时被调用。而虚函数的调用依赖于对象的虚函数表(vtable),在对象构造过程中,虚函数表尚未完全建立,因此无法在构造函数中调用虚函数。
class Base {
public:
virtual Base() {} // 错误:构造函数不能是虚函数
};
2. 静态成员函数
静态成员函数不能是虚函数。静态成员函数与类的实例无关,它们通过类名调用,而不是通过对象调用。由于虚函数的多态性依赖于对象的实例来确定调用哪个重写的函数,而静态成员函数没有这种实例依赖,因此不能声明为虚函数。
class Base {
public:
virtual static void func() {} // 错误:静态成员函数不能是虚函数
};
3. 内联函数
虽然虚函数可以在类的定义中是内联的,但是在运行时,多态调用的虚函数往往是非内联的。编译器在静态编译期并不知道将要调用哪个重写函数,因此在多态调用中,虚函数几乎总是被作为非内联函数处理。也就是说,函数可以被标记为 inline,但如果该函数也是虚函数,那么它在多态情况下不会作为内联函数处理。
class Base {
public:
inline virtual void func() {} // 合法,但在多态情况下不会被内联
};
4. 模板函数的特化
模板函数本身可以是虚函数,但模板函数的特化(具体化版本)不能是虚函数。虚函数的多态性依赖于类的继承关系,而模板的特化版本不是通过继承机制实现的,因此不能用作虚函数。
template <typename T>
class Base {
virtual void func(T t) {} // 合法,模板函数可以是虚函数
};
template <>
void Base<int>::func(int t) {} // 错误:特化版本不能是虚函数
5. 友元函数
友元函数不能是虚函数。友元函数不是类的成员函数,它们在类的外部定义,拥有类的私有成员的访问权限。由于友元函数不是通过类的对象调用的,因此无法成为虚函数。
class Base {
friend virtual void func(Base& b); // 错误:友元函数不能是虚函数
};
4、纯虚函数是什么?
定义
一个纯虚函数的定义形式是在虚函数的声明后面加上 = 0。语法如下:
virtual ReturnType FunctionName(ParameterList) = 0;
= 0 表示该函数是纯虚函数,没有实现。
作用
纯虚函数用于创建抽象基类(abstract base class),这种基类不能直接实例化对象。它们提供了一个接口,强制所有派生类必须实现这些纯虚函数。通过这种方式,可以保证所有派生类都有一致的接口。
举个例子:
#include <iostream>
// 定义一个抽象基类 Shape
class Shape {
public:
// 纯虚函数,没有实现
virtual void draw() = 0;
virtual double area() = 0;
virtual ~Shape() {} // 虚析构函数,允许正确删除派生类对象
};
// 派生类 Circle 继承自抽象基类 Shape
class Circle : public Shape {
private:
double radius;
public:
Circle(double r) : radius(r) {}
// 提供纯虚函数的具体实现
void draw() override {
std::cout << "Drawing a circle." << std::endl;
}
double area() override {
return 3.14 * radius * radius;
}
};
// 派生类 Rectangle 继承自抽象基类 Shape
class Rectangle : public Shape {
private:
double width, height;
public:
Rectangle(double w, double h) : width(w), height(h) {}
// 提供纯虚函数的具体实现
void draw() override {
std::cout << "Drawing a rectangle." << std::endl;
}
double area() override {
return width * height;
}
};
int main() {
Shape* shape1 = new Circle(5.0); // 创建一个 Circle 对象
Shape* shape2 = new Rectangle(4.0, 6.0); // 创建一个 Rectangle 对象
shape1->draw(); // 输出:Drawing a circle.
shape2->draw(); // 输出:Drawing a rectangle.
std::cout << "Area of circle: " << shape1->area() << std::endl; // 输出:Area of circle: 78.5
std::cout << "Area of rectangle: " << shape2->area() << std::endl; // 输出:Area of rectangle: 24
delete shape1; // 释放内存
delete shape2; // 释放内存
return 0;
}
- 抽象基类:
Shape类是一个抽象基类,它包含两个纯虚函数draw()和area(),这意味着Shape类不能直接实例化。 - 派生类的实现:
Circle和Rectangle类继承自Shape并提供了纯虚函数draw()和area()的具体实现。 - 多态性:通过将基类指针指向派生类对象(
Shape* shape1 = new Circle(5.0);),可以调用派生类的具体实现,实现多态。
5、如何防止内存泄漏?
C++ 中,内存泄漏(Memory Leak)是指在程序运行过程中动态分配的内存没有被正确释放,导致内存资源无法被回收和重用。内存泄漏会导致程序占用越来越多的内存资源,最终可能导致程序崩溃或系统性能下降。
1. 使用智能指针(Smart Pointers)
智能指针是 C++11 引入的标准库组件,自动管理动态分配的内存,确保在智能指针对象超出作用域时释放内存。
#include <iostream>
#include <memory> // 包含智能指针的头文件
class MyClass {
public:
MyClass() { std::cout << "MyClass constructor\n"; }
~MyClass() { std::cout << "MyClass destructor\n"; }
};
int main() {
{
std::unique_ptr<MyClass> ptr1 = std::make_unique<MyClass>(); // 创建 unique_ptr
} // 这里 ptr1 超出作用域,自动释放内存
{
std::shared_ptr<MyClass> ptr2 = std::make_shared<MyClass>(); // 创建 shared_ptr
std::shared_ptr<MyClass> ptr3 = ptr2; // 共享同一块内存
} // 这里 ptr2 和 ptr3 都超出作用域,自动释放内存
return 0;
}
2. 遵循 RAII 原则
RAII 原则是一种编程技术,通过对象的构造函数和析构函数来管理资源。构造函数在对象创建时分配资源,析构函数在对象销毁时释放资源。这样可以确保资源总是被正确地释放。
#include <iostream>
#include <fstream>
class FileHandler {
std::fstream file;
public:
FileHandler(const std::string& filename) {
file.open(filename, std::ios::out | std::ios::app);
if (!file.is_open()) {
throw std::runtime_error("Unable to open file");
}
}
~FileHandler() {
if (file.is_open()) {
file.close(); // 确保文件在析构时被正确关闭
}
}
void write(const std::string& data) {
file << data << std::endl;
}
};
int main() {
try {
FileHandler handler("example.txt");
handler.write("Hello, World!");
} catch (const std::exception& e) {
std::cerr << e.what() << std::endl;
}
return 0;
}
3. 匹配 new 和 delete 使用
当使用 new 进行动态内存分配时,必须使用 delete 来释放分配的内存。对于数组使用 new[] 分配的内存,必须使用 delete[] 释放。
int* ptr = new int(5); // 使用 new 动态分配内存
delete ptr; // 使用 delete 释放内存
int* arr = new int[10]; // 使用 new[] 分配数组
delete[] arr; // 使用 delete[] 释放数组内存
4. 避免手动管理内存
在可能的情况下,尽量使用 STL 容器(如 std::vector, std::string)和智能指针,而不是手动管理内存。STL 容器和智能指针会自动管理内存和资源,可以有效避免内存泄漏。
#include <vector>
#include <string>
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5}; // 使用 vector 而不是手动分配数组
std::string str = "Hello, World!"; // 使用 string 而不是手动分配 char 数组
return 0;
}
5. 检查动态内存分配和释放是否匹配
在复杂代码中,确保每一个 new 对应一个 delete,每一个 new[] 对应一个 delete[]。这是手动管理内存的基本要求。
6. 使用内存泄漏检测工具
使用工具检测内存泄漏可以帮助识别和修复内存管理错误。这些工具包括:
- Valgrind:一个强大的内存泄漏和错误检测工具。
- AddressSanitizer:GCC 和 Clang 编译器支持的内存错误检测工具。
- Visual Studio 内存分析工具:适用于 Windows 的内存泄漏检测工具。
6、raii?
RAII(Resource Acquisition Is Initialization,资源获取即初始化)是一种在 C++ 中常用的编程惯用法。核心思想是将资源的获取和释放绑定到对象的生命周期内,利用对象的构造函数和析构函数来管理资源,确保资源的正确释放,从而防止资源泄漏和未定义行为。
RAII 的核心概念
- 资源获取即初始化:资源的获取(如内存分配、文件打开、锁定一个线程等)在对象的构造函数中进行初始化。
- 资源释放在析构函数中自动进行:当对象的生命周期结束时(超出作用域、被销毁等),析构函数会自动调用,负责释放资源。
通过这种方式,RAII 确保了资源的获取与释放是成对发生的,避免了内存泄漏、文件句柄泄漏、死锁等问题。
RAII 使用
1. 动态内存管理
#include <iostream>
class IntArray {
private:
int* array;
size_t size;
public:
// 构造函数:分配动态内存
IntArray(size_t s) : size(s), array(new int[s]) {
std::cout << "Array of size " << size << " created." << std::endl;
}
// 析构函数:释放动态内存
~IntArray() {
delete[] array;
std::cout << "Array of size " << size << " deleted." << std::endl;
}
// 访问数组元素
int& operator[](size_t index) {
return array[index];
}
};
int main() {
{
IntArray arr(5); // 动态内存分配在构造函数中完成
arr[0] = 10;
arr[1] = 20;
// 作用域结束时,析构函数被调用,自动释放内存
} // arr 超出作用域,内存自动释放
return 0;
}
2. 文件管理
#include <iostream>
#include <fstream>
#include <string>
class FileManager {
private:
std::fstream file;
public:
// 构造函数:打开文件
FileManager(const std::string& filename) {
file.open(filename, std::ios::out | std::ios::app);
if (!file.is_open()) {
throw std::runtime_error("Unable to open file");
}
std::cout << "File opened: " << filename << std::endl;
}
// 析构函数:关闭文件
~FileManager() {
if (file.is_open()) {
file.close();
std::cout << "File closed." << std::endl;
}
}
// 写入文件
void write(const std::string& data) {
if (file.is_open()) {
file << data << std::endl;
}
}
};
int main() {
try {
FileManager fm("example.txt");
fm.write("Hello, World!");
// 文件操作完成,FileManager 超出作用域,自动关闭文件
} catch (const std::exception& e) {
std::cerr << e.what() << std::endl;
}
return 0;
}
3. 线程锁管理
在多线程环境中,RAII 可以用于自动管理线程锁,防止死锁。
#include <iostream>
#include <mutex>
#include <thread>
std::mutex mtx;
void print_message(const std::string& msg) {
std::lock_guard<std::mutex> lock(mtx); // RAII 风格的锁管理,自动加锁和解锁
std::cout << msg << std::endl;
}
int main() {
std::thread t1(print_message, "Hello from thread 1");
std::thread t2(print_message, "Hello from thread 2");
t1.join();
t2.join();
return 0;
}
RAII 的优势
- 自动化资源管理:通过构造函数和析构函数管理资源,减少了手动释放资源的需求,降低了出现资源泄漏的风险。
- 简化代码:代码更简洁、易于维护,不需要显式调用资源释放函数。
- 异常安全性:在异常发生时,C++ 会自动调用栈上对象的析构函数,确保资源得到释放,避免了资源泄漏问题。
- 提高代码的可读性:RAII 将资源管理的责任交给对象,代码更具表达力和可读性。
7、shared,weak,unique智能指针的点基本都问了?
1. std::unique_ptr
- 概述:
std::unique_ptr是一种独占所有权的智能指针,即一个对象的所有权只能被一个std::unique_ptr拥有。 - 特点:
- 独占所有权:一个对象只能由一个
std::unique_ptr实例拥有,不能被复制。 - 转移所有权:可以通过
std::move将所有权转移到另一个std::unique_ptr。 - 自动释放内存:当
std::unique_ptr超出其作用域或被销毁时,会自动调用delete释放所指向的对象。 - 轻量级:由于不需要维护引用计数,相比
std::shared_ptr,std::unique_ptr更加轻量。
- 独占所有权:一个对象只能由一个
#include <memory>
#include <iostream>
void example() {
std::unique_ptr<int> ptr1 = std::make_unique<int>(10);
std::cout << *ptr1 << std::endl; // 输出 10
// std::unique_ptr<int> ptr2 = ptr1; // 错误:`unique_ptr` 不可复制
std::unique_ptr<int> ptr2 = std::move(ptr1); // 使用 std::move 转移所有权
if (!ptr1) {
std::cout << "ptr1 is now null" << std::endl;
}
}
2. std::shared_ptr
- 概述:
std::shared_ptr是一种具有共享所有权的智能指针,多个shared_ptr可以指向相同的对象,并通过引用计数来管理对象的生命周期。 - 特点:
- 共享所有权:多个
std::shared_ptr可以共享同一个对象的所有权。 - 引用计数:内部维护一个引用计数器,当引用计数变为 0 时,自动释放内存。
- 线程安全:增加和减少引用计数的操作是线程安全的。
- 共享所有权:多个
#include <memory>
#include <iostream>
void example() {
std::shared_ptr<int> ptr1 = std::make_shared<int>(20);
std::shared_ptr<int> ptr2 = ptr1; // 共享同一个对象
std::cout << *ptr1 << std::endl; // 输出 20
std::cout << ptr1.use_count() << std::endl; // 输出 2(引用计数)
}
3. std::weak_ptr
- 概述:
std::weak_ptr是一种不影响引用计数的智能指针,通常与std::shared_ptr搭配使用,用于解决循环引用的问题。 - 特点:
- 不共享所有权:
std::weak_ptr不影响std::shared_ptr的引用计数。 - 用于观察:
std::weak_ptr用于观察但不拥有对象,适合用于避免循环引用。 - 检查对象有效性:可以使用
expired()检查对象是否已经被释放,也可以使用lock()从weak_ptr创建一个shared_ptr(如果对象还存在)。
- 不共享所有权:
#include <memory>
#include <iostream>
void example() {
std::shared_ptr<int> sharedPtr = std::make_shared<int>(30);
std::weak_ptr<int> weakPtr = sharedPtr; // 不影响引用计数
std::cout << "Shared pointer count: " << sharedPtr.use_count() << std::endl; // 输出 1
if (auto lockedPtr = weakPtr.lock()) { // 使用 lock() 创建 shared_ptr
std::cout << *lockedPtr << std::endl; // 输出 30
}
}
4. std::auto_ptr(已弃用)
- 概述:
std::auto_ptr是一种早期的智能指针类型,已在 C++11 中被弃用,并在 C++17 中被移除。它的语义与std::unique_ptr类似,但有一些问题。 - 特点:
- 独占所有权:类似于
std::unique_ptr,但auto_ptr会在复制时转移所有权(使用复制语义),容易导致意外的所有权转移。 - 已弃用和移除:因为
auto_ptr存在易用性和所有权语义问题,它在 C++11 中被弃用,之后在 C++17 中被完全移除。
- 独占所有权:类似于
智能指针的对比
| 智能指针类型 | 所有权 | 引用计数 | 主要特点 | 使用场景 |
|---|---|---|---|---|
std::unique_ptr | 独占所有权 | 无 | 独占所有权,不能复制,只能移动 | 确定只有一个所有者,避免资源泄漏 |
std::shared_ptr | 共享所有权 | 有 | 共享所有权,通过引用计数管理对象生命周期 | 多个所有者共享资源,动态内存管理 |
std::weak_ptr | 弱引用 | 无 | 与std::shared_ptr配合使用,不增加引用计数,解决循环引用问题 | 观察共享对象,不影响其生命周期,解决循环引用 |
8、map与unordered_map区别?
1. 内部实现
map:基于 红黑树(或其他平衡二叉搜索树)实现,元素按键的顺序(排序规则)存储。unordered_map:基于 哈希表 实现,元素按键的哈希值存储,不保证元素顺序。
2. 元素存储顺序
map:自动按键的顺序排序,使用的默认排序准则是<运算符。插入元素时,按照排序规则插入合适位置。unordered_map:不保证元素的顺序,元素的顺序可能会随着插入和删除操作的进行而变化。
3. 查找/插入/删除的时间复杂度
map:由于是基于红黑树实现,查找、插入和删除的平均时间复杂度为 O(log n)。unordered_map:由于是基于哈希表实现,查找、插入和删除的平均时间复杂度为 O(1),但在最坏情况下(例如所有元素都被哈希到同一个桶中)时间复杂度可能退化为 O(n)。
4. 内存使用
map:由于是平衡二叉树实现,map的节点结构较复杂,需要存储额外的指针(父节点、左右子节点等)用于维护树的结构。因此内存开销相对较大。unordered_map:哈希表的实现相对简单,一般只需要存储键值对和哈希桶结构,因此内存开销通常较小。不过,如果哈希表装载因子过高,可能会触发重新哈希,导致额外的内存分配和复制。
5. 使用场景和选择
map:适用于需要对键进行排序的情况,或者需要经常进行范围查询(如查找特定范围内的元素)。unordered_map:适用于对元素顺序不关心且频繁进行查找、插入和删除操作的情况,能够提供更好的平均性能。
6. 特性和接口
map:支持所有的 STL 关联容器接口,如lower_bound,upper_bound,equal_range等,还可以通过迭代器轻松遍历有序键值对。unordered_map:由于不保证顺序,不支持有序的迭代器访问和范围查询。
计算机网络
1、计网四层模型与对应的协议?
1. 应用层
功能:应用层负责为用户提供网络服务的接口,是与用户直接交互的层。它支持各种网络应用程序和协议,为应用程序提供直接的通信。
常见协议:
- HTTP/HTTPS:超文本传输协议/安全超文本传输协议,主要用于浏览网页和传输数据。
- FTP:文件传输协议,用于文件的上传和下载。
- SMTP:简单邮件传输协议,用于发送电子邮件。
- POP3/IMAP:邮件接收协议,用于接收电子邮件。
- DNS:域名系统,用于将域名解析为IP地址。
- SSH:安全外壳协议,用于安全地远程登录和命令执行。
2. 传输层
功能:传输层的主要功能是提供主机之间的进程到进程的通信。它负责数据的传输,并提供可靠的传输和错误检测与恢复机制。
常见协议:
- TCP (Transmission Control Protocol):传输控制协议,提供面向连接的、可靠的数据传输服务。TCP确保数据按顺序、无差错地传输,适用于需要高可靠性的应用(如网页浏览、文件传输、电子邮件等)。
- UDP (User Datagram Protocol):用户数据报协议,提供面向无连接、不可靠的数据传输服务。UDP没有拥塞控制,适用于实时性要求较高但对可靠性要求不高的应用(如实时音频视频传输、在线游戏等)。
3. 网络层
功能:网络层负责为分组在网络中选择路径和转发分组,是数据在不同主机和网络之间传输的桥梁。
常见协议:
- IP (Internet Protocol):互联网协议,负责数据包的地址编制和路由选择。IP协议有两个版本:IPv4 和 IPv6。
- ICMP (Internet Control Message Protocol):互联网控制消息协议,用于在网络设备之间传输控制消息(如网络可达性测试)。
- ARP (Address Resolution Protocol):地址解析协议,用于将网络层地址(IP地址)解析为数据链路层地址(MAC地址)。
- RARP (Reverse Address Resolution Protocol):反向地址解析协议,用于将MAC地址解析为IP地址(主要用于无盘工作站)。
4. 链路层
功能:链路层,也称为数据链路层或网络接口层,负责在同一链路上(物理层面的)直接相连的两个节点之间传输数据帧。它定义了与传输媒介直接相连的协议和硬件设备。
常见协议和技术:
- Ethernet(以太网):局域网中最常用的链路层技术,定义了数据帧格式、传输介质访问控制方式等。
- Wi-Fi:无线局域网协议(基于IEEE 802.11标准),用于无线通信。
- PPP (Point-to-Point Protocol):点对点协议,主要用于串行通信和拨号网络连接。
- Frame Relay:帧中继,面向连接的分组交换技术,常用于广域网。
- MAC (Media Access Control):介质访问控制协议,负责控制设备在网络上的数据传输权限。
图示
+---------------------+
| 应用层 | 应用协议 (HTTP, FTP, SMTP, etc.)
+---------------------+
| 传输层 | TCP, UDP
+---------------------+
| 网络层 | IP, ICMP, ARP, RARP
+---------------------+
| 链路层 | Ethernet, Wi-Fi, PPP, etc.
+---------------------+
2、点对点和端到端的区别?
1. 点对点
定义:点对点通信是指两个直接相连的节点之间的通信。在这种模式下,数据在两个节点之间传输,没有中间设备(如路由器或交换机)的干扰或中转。
特点:
- 直接连接:两个节点通过物理线路(如串行电缆或无线链路)直接连接。
- 简单拓扑:适用于简单的、直接的连接环境,如串行通信、拨号连接等。
- 独占带宽:在点对点连接中,通信链路的带宽是独占的,没有其他设备共享该链路的带宽。
应用场景:
- 调制解调器和计算机之间的拨号连接。
- 局域网中的串行或并行数据传输。
- 两个网络设备之间的专用通信(如两个路由器通过串行链路连接)。
2. 端到端
定义:端到端通信是指在网络中两个终端设备(如计算机、服务器、智能手机)之间进行通信的方式。端到端通信涵盖了从源端设备到目标端设备的整个路径,包括中间的所有网络设备(如路由器、交换机等)。
特点:
- 网络层次更高:端到端通信通常关注传输层(如TCP、UDP)和应用层(如HTTP、FTP)的通信特性。
- 可靠性和完整性:端到端原则强调传输数据的可靠性和完整性。它关注的是从源头到目的地整个路径的通信质量。
- 跨越多跳网络:数据可以通过多个网络设备中转,最终从一个端到另一个端。
应用场景:
- 互联网通信:如客户端与服务器之间的HTTP请求/响应、电子邮件传输。
- 视频流媒体:客户端和服务器之间的流媒体数据传输。
- 文件传输:如通过FTP从一个计算机端到另一个计算机端传输文件。
3. 区别总结
| 特性 | 点对点(Point-to-Point) | 端到端(End-to-End) |
|---|---|---|
| 连接模式 | 两个直接相连的节点之间的通信 | 两个终端设备之间的通信(跨越网络) |
| 中间设备 | 无中间设备,直接连接 | 可以包含多个中间设备(如路由器) |
| 适用层次 | 通常在数据链路层和物理层 | 通常在传输层和应用层 |
| 通信范围 | 单一链路 | 整个网络范围(可能经过多跳) |
| 应用场景 | 专用的短距离通信(如串行链接) | 广泛的网络应用(如互联网通信) |
| 带宽共享 | 独占通信链路的带宽 | 带宽可以被多个传输共享 |
4. 实际例子
- 点对点:你使用两台计算机通过一根交叉网线直连进行文件传输,此时这两台计算机之间的通信就是点对点的。
- 端到端:你从家里的计算机访问一个远程服务器时,数据包可能经过多个路由器和交换机,最终从你的计算机(源端)到达服务器(目标端),这是一个端到端的通信。
3、arp怎么工作的?
ARP(Address Resolution Protocol,地址解析协议) 是一种用于将网络层地址(如 IP 地址)解析为数据链路层地址(如 MAC 地址)的协议。
工作原理
-
ARP 请求:
- 当一个设备(主机)需要向另一个设备发送数据时,它需要知道目标设备的 MAC 地址。如果目标设备的 MAC 地址还未缓存,源设备会广播一个 ARP 请求包。
- ARP 请求包包含了以下信息:
- 目标 IP 地址(需要解析的 IP 地址)
- 源 IP 地址(发送 ARP 请求的设备的 IP 地址)
- 源 MAC 地址(发送 ARP 请求的设备的 MAC 地址)
- 目标 MAC 地址(初始化为全 0,因为这是未知的)
这个 ARP 请求是一个广播包,意味着它会被网络上的所有设备接收。
-
ARP 响应:
- 网络上的所有设备都会接收到 ARP 请求包,检查请求中的目标 IP 地址。如果设备的 IP 地址与请求中的目标 IP 地址匹配,该设备会发送一个 ARP 响应包。
- ARP 响应包包含了以下信息:
- 目标 IP 地址(与请求中的目标 IP 地址相同)
- 源 IP 地址(回应设备的 IP 地址)
- 目标 MAC 地址(回应设备的 MAC 地址)
- 源 MAC 地址(回应设备的 MAC 地址)
ARP 响应包是单播包,直接发送到 ARP 请求发起设备的 MAC 地址。
-
缓存 ARP 信息:
- 收到 ARP 响应的设备会将响应中的 IP 地址和对应的 MAC 地址保存到其 ARP 缓存中。这是为了避免重复的 ARP 请求,提高网络效率。
- 缓存中的 ARP 条目有一个过期时间,过期后需要重新进行 ARP 请求以更新 MAC 地址。
-
数据传输:设备现在已经知道了目标设备的 MAC 地址,可以将数据包封装在以该 MAC 地址为目标的帧中,然后通过数据链路层将数据包发送出去。
ARP 的缓存和刷新
- ARP 缓存:存储 IP 地址与 MAC 地址的映射。缓存条目有一个过期时间,当条目过期后,设备会重新发起 ARP 请求。
- ARP 刷新:当网络拓扑发生变化(如设备移动或 IP 地址变更)时,ARP 缓存中的信息可能变得不准确。为了保持准确性,ARP 会定期刷新缓存,并在必要时重新发起 ARP 请求。
ARP 的安全问题
ARP 协议存在一些安全问题,如 ARP 欺骗(ARP Spoofing),其中攻击者发送伪造的 ARP 响应以欺骗网络设备,从而实现中间人攻击(MITM)或数据劫持。为了缓解这些问题,一些网络安全措施如 静态 ARP 条目、动态 ARP 检测 和 ARP 监控 可以被使用。
4、tcp三次握手?
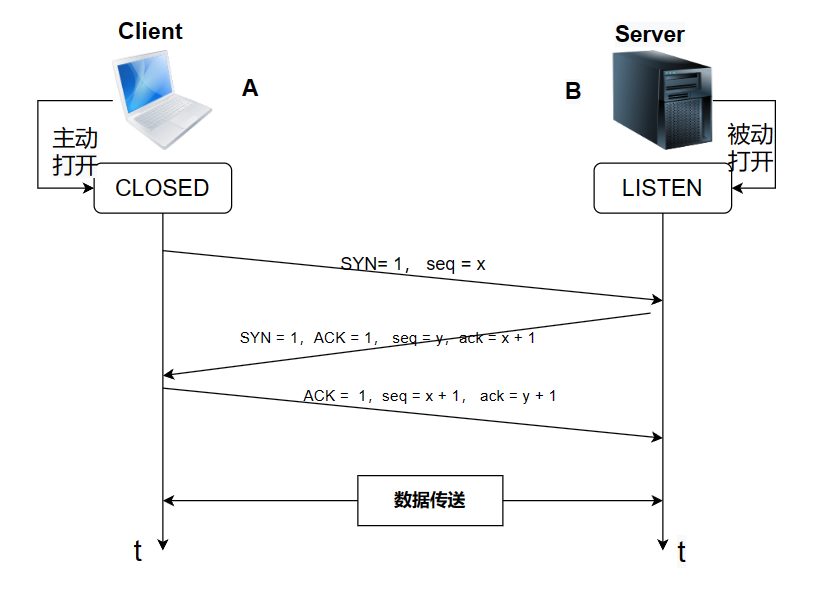
- SYN: 客户端向服务器发送一个 SYN(Synchronize)报文,表示请求建立连接。
- SYN-ACK: 服务器收到 SYN 后,返回一个 SYN-ACK(Synchronize Acknowledgment)报文,表示同意建立连接并确认收到客户端的 SYN。
- ACK: 客户端收到 SYN-ACK 后,发送一个 ACK(Acknowledgment)报文,表示确认连接建立。
通过三次握手,TCP 确保了双方都收到了连接请求,并为即将开始的数据传输建立了可靠的连接。
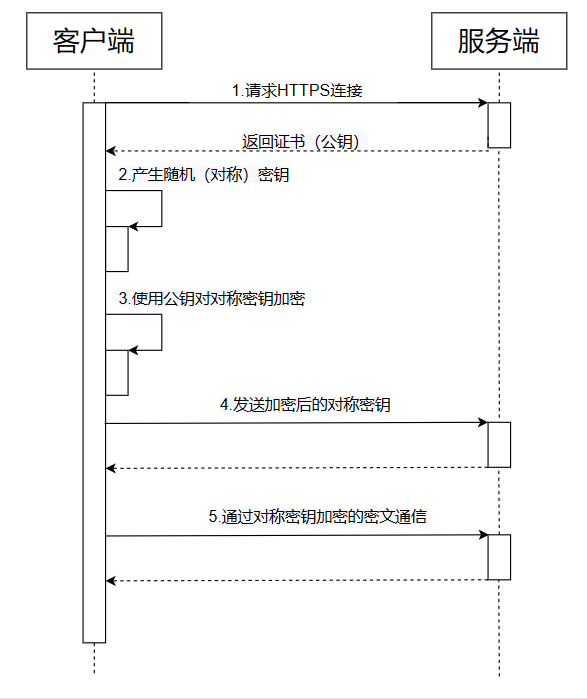
5、https工作流程?
- 客户端向服务端发起第一次握手请求,告诉服务端客户端所支持的SSL的指定版本、加密算法及密钥长度等信息。
- 服务端将自己的公钥发给数字证书认证机构,数字证书认证机构利用自己的私钥对服务器的公钥进行数字签名,并给服务器颁发公钥证书。
- 服务端将证书发给客户端。
- 客服端利用数字认证机构的公钥,向数字证书认证机构验证公钥证书上的数字签名,确认服务器公开密钥的真实性。
- 客户端使用服务端的公开密钥加密自己生成的对称密钥,发给服务端。
- 服务端收到后利用私钥解密信息,获得客户端发来的对称密钥。
- 通信双方可用对称密钥来加密解密信息。
流程图如下:
6、quic协议知道吗?
QUIC(Quick UDP Internet Connections)是一种传输层网络协议,旨在提高互联网应用的性能和安全性。QUIC 是 Google 提出的,并且在 IETF(Internet Engineering Task Force)标准化过程中发展起来。它主要设计用于改善基于 TCP 的传输层协议(如 HTTP/2)的性能和安全性。
QUIC 的特点和优势
- 基于 UDP:QUIC 使用 UDP 作为传输协议,而不是传统的 TCP。由于 UDP 的低开销和无连接特性,QUIC 可以实现更快速的连接建立和更高效的传输。
- 快速连接建立:QUIC 支持 0-RTT 和 1-RTT 连接建立,这意味着在某些情况下,数据可以在连接建立的初期就开始传输,显著减少延迟。
- 集成加密:QUIC 内置了加密功能,默认使用 TLS 1.3 加密协议。这与 HTTP/2 的传统做法不同,HTTP/2 依赖于 TLS 层来提供加密。QUIC 的内置加密可以减少延迟和复杂性。
- 多路复用:QUIC 支持多路复用,它允许在同一个连接中同时传输多个流,这样可以减少由于多个 TCP 连接而引起的延迟和头部阻塞问题。
- 连接迁移:QUIC 支持连接迁移,即在客户端的 IP 地址发生变化时(如切换 Wi-Fi 网络),QUIC 连接可以保持不变。这在移动设备上尤其重要,可以提升用户体验。
- 减少头部阻塞:QUIC 通过多路复用和无头部阻塞的机制来减少 HTTP/2 中常见的头部阻塞问题,提升传输效率。
- 流量控制:QUIC 实现了基于流的流量控制,可以更精细地控制数据传输速率,避免流量拥塞和网络瓶颈。
QUIC 的工作原理
- 连接建立:QUIC 使用加密握手来建立连接,通常只需一次往返(1-RTT),如果是首次连接还需 0-RTT 数据传输。QUIC 的握手过程包含了加密和身份验证,确保通信的安全性。
- 数据传输:数据在 QUIC 中被分为多个流,每个流独立于其他流传输数据。这使得单个流的阻塞不会影响其他流的传输。
- 拥塞控制:QUIC 实现了自适应拥塞控制算法,可以动态调整传输速率,以应对网络的变化和拥塞情况。
- 重传和纠错:QUIC 通过内置的重传机制和纠错功能来确保数据传输的可靠性。数据包丢失或错误时,QUIC 可以快速重传丢失的数据。
QUIC 的应用
QUIC 被广泛应用于 HTTP/3(HTTP 的最新版本)协议中,HTTP/3 基于 QUIC 实现了更高效的网页加载和数据传输。谷歌的 Chrome 浏览器、Mozilla 的 Firefox 浏览器以及许多其他现代浏览器都已支持 QUIC 和 HTTP/3。QUIC 也被用于提高视频流媒体、在线游戏和其他实时应用的性能。
QUIC 与 TCP 的对比
| 特性 | QUIC | TCP |
|---|---|---|
| 协议类型 | 基于 UDP | 面向连接的协议 |
| 连接建立延迟 | 0-RTT 或 1-RTT | 需要 3 次握手 |
| 加密 | 内置加密(TLS 1.3) | 依赖于应用层(如 TLS) |
| 多路复用 | 支持多路复用 | 多路复用需额外支持(如 HTTP/2) |
| 连接迁移 | 支持 IP 地址迁移 | 不支持 IP 地址迁移 |
| 头部阻塞 | 减少头部阻塞 | 可能发生头部阻塞 |
| 流量控制 | 基于流的流量控制 | 连接级别的流量控制 |
Linux
1、linux的进程通信方式?
1. 管道
- 匿名管道:用于在具有亲缘关系的进程(如父子进程)之间进行通信。匿名管道创建后,数据可以从一个进程写入管道,并从另一个进程读取。匿名管道通常是单向的,即数据只能在一个方向上流动。
- 命名管道(FIFO):允许无亲缘关系的进程之间进行通信。命名管道有一个名字,存在于文件系统中,进程可以通过这个名字访问管道。命名管道支持双向数据流,但每次读写操作都是单向的。
2. 信号量
- 用途:主要用于进程间的同步,避免数据竞争和资源冲突。信号量是一种同步机制,可以用于协调多个进程对共享资源的访问。
- 类型:
- 计数信号量:用于控制对有限数量资源的访问。
- 二值信号量:只有两个状态(0 和 1),类似于互斥锁。
3. 共享内存
- 用途:允许多个进程访问同一块内存区域,以实现高速的数据交换。共享内存的创建和管理是通过
shmget、shmat、shmdt和shmctl等系统调用完成的。 - 特点:共享内存通常比管道和消息队列更高效,但需要额外的同步机制(如信号量)来避免数据竞争。
4. 消息队列
- 用途:允许进程通过队列交换消息。每个消息队列都有一个唯一的标识符,进程可以向队列中写入消息,并从队列中读取消息。
- 特点:消息队列支持异步通信,可以实现进程之间的松耦合。消息队列的创建和管理通过
msgget、msgsnd、msgrcv和msgctl等系统调用进行。
5. 套接字
- 用途:用于进程间通信(IPC)和网络通信。套接字可以用于本地进程之间的通信(即 UNIX 域套接字)或网络上的进程间通信(即网络套接字)。
- 类型:
- UNIX 域套接字:用于在同一台机器上的进程之间进行通信。
- 网络套接字:用于跨网络的进程间通信,可以是 TCP 或 UDP 套接字。
6. 信号
- 用途:用于进程间传递通知和控制信息。信号可以用来通知进程某些事件发生(如终止、挂起、继续执行等)。
- 特点:信号是一种较为粗粒度的通信方式,通常用于进程间的简单控制和通知。
7.内存映射文件
- 用途:允许进程将文件或设备的内容映射到进程的地址空间中。这种映射可以用于在多个进程间共享文件内容。
- 特点:内存映射文件通过
mmap系统调用进行创建,允许高效的文件访问和共享。
各种通信方式的比较
| 方式 | 优点 | 缺点 | 用例 |
|---|---|---|---|
| 管道 | 简单易用,适合父子进程之间的通信 | 仅支持单向通信,不适合无亲缘关系的进程间通信 | 简单的数据流传输 |
| 命名管道(FIFO) | 支持无亲缘关系的进程间通信 | 仍然是单向通信,可能存在性能问题 | 进程间的消息传递 |
| 信号量 | 有效的进程同步机制 | 仅用于同步,不适合数据传输 | 进程间的资源访问控制 |
| 共享内存 | 高效的数据传输,速度快 | 需要额外的同步机制,可能导致数据竞争 | 大量数据的快速交换 |
| 消息队列 | 支持异步通信和消息管理 | 可能存在性能瓶颈,消息长度有限 | 异步消息传递,任务调度 |
| 套接字 | 灵活,支持本地和网络通信 | 对比其他 IPC 机制,可能会有较高的开销 | 网络通信,进程间通信 |
| 信号 | 简单通知机制,适合简单控制 | 功能较为简单,通常用于进程控制 | 进程终止、暂停、继续等 |
| 内存映射文件 | 高效的文件共享和访问 | 可能涉及较复杂的映射管理 | 文件内容共享,大数据传输 |
2、如何查看一个进程监听了什么端口?
1.使用 netstat 命令
netstat 是一个用于显示网络连接、路由表、接口统计信息等的工具。可以通过以下命令查看哪些进程监听了哪些端口:
netstat -tulnp
-t:显示 TCP 连接-u:显示 UDP 连接-l:只显示正在监听的端口-n:以数字形式显示地址和端口-p:显示哪个进程在监听端口
这个命令会列出所有正在监听的端口及其对应的进程 ID(PID)。
2.使用 ss 命令
ss 是一个更现代的工具,用于显示套接字统计信息。它可以替代 netstat,并提供更多功能。要查看监听的端口及其进程信息,可以使用:
ss -tulnp
-t:显示 TCP 套接字-u:显示 UDP 套接字-l:显示监听的套接字-n:以数字形式显示地址和端口-p:显示进程信息
3.使用 lsof 命令
lsof 是一个用于列出当前系统打开文件的工具。在网络编程中,端口也被视为文件。要查看哪些进程在监听端口,可以使用:
lsof -i -P -n
-i:列出所有网络相关的文件-P:以端口号显示端口而不是服务名-n:以数字形式显示地址
如果只想查看特定进程的端口,可以将进程 ID 加入到命令中:
lsof -i -P -n | grep <PID>
替换 <PID> 为实际的进程 ID。
4.查看 /proc 文件系统
/proc 文件系统提供了内核和进程的相关信息。你可以通过读取 /proc 目录下的相关文件来查看端口使用情况。例如:
cat /proc/<PID>/net/tcp
其中 <PID> 是进程 ID。这个文件显示了进程使用的 TCP 连接信息。
3、io多路复用?
基本概念
在传统的 I/O 模型中,每个 I/O 操作通常由一个独立的线程或进程来处理,这种方法可能导致线程或进程的开销非常大,尤其是当需要处理大量的 I/O 连接时。I/O 多路复用通过允许单个线程或进程同时处理多个 I/O 操作来解决这个问题,从而减少系统资源的消耗。
常见的 I/O 多路复用技术
1.select
select 是最早的 I/O 多路复用机制之一。它允许进程监视多个文件描述符,检查哪些文件描述符可以进行读、写或异常条件操作。select 的基本用法包括以下步骤:
- 调用
select函数,传入一组文件描述符集(读、写和异常),并设置超时时间。 select会阻塞,直到有一个或多个文件描述符可以进行 I/O 操作,或者超时时间到达。select返回后,进程可以检查哪些文件描述符准备好了相应的 I/O 操作。
#include <sys/select.h>
#include <unistd.h>
#include <iostream>
int main() {
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(STDIN_FILENO, &readfds);
struct timeval timeout;
timeout.tv_sec = 5;
timeout.tv_usec = 0;
int ret = select(STDIN_FILENO + 1, &readfds, NULL, NULL, &timeout);
if (ret == -1) {
std::cerr << "select() error" << std::endl;
return 1;
} else if (ret == 0) {
std::cout << "Timeout occurred!" << std::endl;
} else {
if (FD_ISSET(STDIN_FILENO, &readfds)) {
std::cout << "Data available to read from stdin" << std::endl;
}
}
return 0;
}
2.poll
poll 是对 select 的改进,解决了 select 中的一些限制,例如文件描述符的数量限制。poll 允许监视多个文件描述符,并且使用一个数组来描述待监视的文件描述符。poll 的基本用法包括以下步骤:
- 使用
poll函数,传入一个pollfd结构体数组,其中每个结构体代表一个待监视的文件描述符及其事件。 poll会阻塞,直到有一个或多个文件描述符准备好了 I/O 操作,或者超时时间到达。poll返回后,检查pollfd结构体中的事件,确定哪些文件描述符准备好了相应的 I/O 操作。
#include <poll.h>
#include <unistd.h>
#include <iostream>
int main() {
struct pollfd fds[1];
fds[0].fd = STDIN_FILENO;
fds[0].events = POLLIN;
int ret = poll(fds, 1, 5000);
if (ret == -1) {
std::cerr << "poll() error" << std::endl;
return 1;
} else if (ret == 0) {
std::cout << "Timeout occurred!" << std::endl;
} else {
if (fds[0].revents & POLLIN) {
std::cout << "Data available to read from stdin" << std::endl;
}
}
return 0;
}
3.epoll
epoll 是 Linux 提供的一种高效的 I/O 多路复用机制,设计用于处理大量的并发连接。epoll 的主要优势在于其高效的事件通知机制,特别是在处理大规模 I/O 操作时。epoll 的基本用法包括以下步骤:
- 使用
epoll_create创建一个 epoll 实例。 - 使用
epoll_ctl注册或修改文件描述符的监听事件。 - 使用
epoll_wait等待事件发生,并获取就绪的文件描述符列表。
#include <sys/epoll.h>
#include <unistd.h>
#include <iostream>
int main() {
int epfd = epoll_create1(0);
if (epfd == -1) {
std::cerr << "epoll_create1() error" << std::endl;
return 1;
}
struct epoll_event event;
event.events = EPOLLIN;
event.data.fd = STDIN_FILENO;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, STDIN_FILENO, &event) == -1) {
std::cerr << "epoll_ctl() error" << std::endl;
close(epfd);
return 1;
}
struct epoll_event events[1];
int ret = epoll_wait(epfd, events, 1, 5000);
if (ret == -1) {
std::cerr << "epoll_wait() error" << std::endl;
close(epfd);
return 1;
} else if (ret == 0) {
std::cout << "Timeout occurred!" << std::endl;
} else {
if (events[0].events & EPOLLIN) {
std::cout << "Data available to read from stdin" << std::endl;
}
}
close(epfd);
return 0;
}
4.kqueue (BSD 系统)
kqueue 是 BSD 系统中的 I/O 多路复用机制,提供了一种高效的事件通知机制。kqueue 支持多种事件,包括 I/O 事件、信号、定时器等。它的基本用法包括以下步骤:
- 使用
kqueue创建一个 kqueue 实例。 - 使用
kevent注册感兴趣的事件。 - 使用
kevent等待事件发生,并获取就绪的事件列表。
#include <sys/types.h>
#include <sys/event.h>
#include <unistd.h>
#include <iostream>
int main() {
int kq = kqueue();
if (kq == -1) {
std::cerr << "kqueue() error" << std::endl;
return 1;
}
struct kevent event;
EV_SET(&event, STDIN_FILENO, EVFILT_READ, EV_ADD, 0, 0, NULL);
if (kevent(kq, &event, 1, NULL, 0, NULL) == -1) {
std::cerr << "kevent() error" << std::endl;
close(kq);
return 1;
}
struct kevent events[1];
int ret = kevent(kq, NULL, 0, events, 1, NULL);
if (ret == -1) {
std::cerr << "kevent() error" << std::endl;
close(kq);
return 1;
} else if (ret == 0) {
std::cout << "Timeout occurred!" << std::endl;
} else {
if (events[0].flags & EV_EOF) {
std::cout << "Data available to read from stdin" << std::endl;
}
}
close(kq);
return 0;
}
优点
- 提高效率:通过单个线程或进程管理多个 I/O 操作,减少了线程切换和上下文切换的开销。
- 节省资源:避免了为每个 I/O 操作创建和管理大量线程或进程的需求。
- 可扩展性:适用于高并发环境,如 Web 服务器和网络服务。