本文翻译整理自:https://ragflow.io/docs/dev/
本文档更多是 RAGFlow 系统操作内容,虽然不难/深刻,但有些细节没有注意,在搭建和使用的时候就容易出各类问题。所以读完这个文档是有必要的。
文章目录
- 快速启动
- 一、先决条件
- 二、启动服务器
- 1、确保 `vm.max_map_count` ≥ 262144:
- 2、克隆存储库:
- 3、构建预构建的Docker映像并启动服务器:
- 三、配置LLM
- 四、创建您的第一个知识库
- 五、文件解析
- 六、设置一个AI聊天
- 配置知识库
- 一、创建知识库
- 二、配置知识库
- 1、选择块方法
- 2、选择嵌入模型
- 3、上传文件
- 4、解析文件
- 5、干预文件解析结果
- 6、运行检索测试
- 三、搜索知识库
- 四、删除知识库
- 开始AI聊天
- 一、开始一个AI聊天
- 二、更新现有对话的设置
- 三、将聊天功能集成到您的应用程序中
- 管理文件
- 一、创建文件夹
- 二、上传文件
- 三、预览文件
- 四、将文件链接到知识库
- 五、将文件移动到特定文件夹
- 六、搜索文件或文件夹
- 七、重命名文件或文件夹
- 八、删除文件或文件夹
- 九、下载上传文件
- 配置您的API密钥
- 一、获取您的API密钥
- 二、配置您的API密钥
- 1、在启动RAGFlow之前配置API密钥
- 2、登录RAGFlow后配置API密钥
- 部署本地LLM
- 一、使用jina部署本地模型
- 1、检查防火墙设置
- 2、安装包
- 3、部署本地模型
- 二、使用Ollama部署本地模型
- 1、检查防火墙设置
- 2、确保Ollama是可访问的
- 3、运行您的本地模型
- 4、添加Ollama
- 5、完成基本的Ollama设置
- 6、更新系统模型设置
- 7、更新聊天配置
- 三、部署一个本地模型
- 1、检查防火墙设置
- 2、启动一个新会议实例
- 3、启动您的本地模型
- 4、添加新元素
- 5、完成基本的新会议设置
- 6、更新系统模型设置
- 7、更新聊天配置
- 四、Deploy a local model using IPEX-LLM
- 1、检查防火墙设置
- 2、使用IPEX-LLM启动Ollama服务
- 2.1 为Ollama安装IPEX-LLM
- 2.2 初始化Ollama
- 2.3 推出Ollama服务
- 3、拉和运行Ollama模型
- 3.1 拉动Ollama模型
- 3.2 运行Ollama模型
- 4、配置RAGflow
- 贡献准则
- 你能贡献什么
- 提交拉取请求(PR)
- 一般工作流程
- 在提交公关申请之前
- 描述你的公关
- 审查和合并PR
- API参考
- 一、基本网址
- 二、授权
- 三、创建对话
- 请求
- 请求URI
- 请求参数
- 响应
- 四、获取对话历史记录
- 请求
- 请求URI
- 请求参数
- 响应
- 响应参数
- 五、得到答案
- 请求
- 请求URI
- 请求参数
- 响应
- 六、获取文档内容
- 请求
- 请求URI
- 响应
- 七、上传文件
- 请求
- 请求URI
- 响应参数
- 响应
- 八、获取文档切片
- Request
- 请求URI
- 请求参数
- 响应
- 九、获取文档列表
- 请求
- 请求URI
- 请求参数
- 响应
- 十、删除文件
- 请求
- 请求URI
- 请求参数
- 响应
- 常见问题
- 一、常见问题
- 1、RAGFlow与其他RAG产品的区别是什么?
- 2、RAGFlow支持哪些语言?
- 3.哪些嵌入模型可以部署在本地?
- 二、变现
- 1、为什么RAGFlow解析文档的时间比LangChain长?
- 2、为什么RAGFlow比其他项目需要更多的资源?
- 三、特征
- 1、RAGFlow支持哪些架构或设备?
- 2、您是否提供与第三方应用程序集成的API?
- 3、你支持流输出吗?
- 4、是否可以通过网址分享对话?
- 5、您是否支持多轮对话,即引用以前的对话作为当前对话的上下文?
- 四、故障排除
- 1、docker映像的问题
- 1.1 How to build the RAGFlow image from scratch?
- 1.2 `process "/bin/sh -c cd ./web && npm i && npm run build"` failed
- 2、huggingface 模型的问题
- 2.1无法访问 [https://huggingface.co](https://huggingface.co/)
- 2.2`MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443)`
- 2.3 `FileNotFoundError`
- 3、RAGFlow服务器的问题
- 3.1`WARNING: can't find /raglof/rag/res/borker.tm`
- 3.2`network anomaly There is an abnormality in your network and you cannot connect to the server.`
- 4、RAGFlow后端服务的问题
- 4.1`dependency failed to start: container ragflow-mysql is unhealthy`
- 4.2`Realtime synonym is disabled, since no redis connection`
- 4.3 为什么我的文档解析在1%以下停滞不前?
- 4.4 为什么我的pdf解析在接近完成时停止,而日志没有显示任何错误?
- 4.5 `Index failure`
- 4.6 如何查看RAGFlow的日志?
- 4.7如何检查RAGFlow中每个组件的状态?
- 4.8 `Exception: Can't connect to ES cluster`
- 4.9 无法启动ES容器并获取`Elasticsearch did not exit normally`
- 4.10 `{"data":null,"retcode":100,"retmsg":"<NotFound '404: Not Found'>"}`
- 4.11 `Ollama - Mistral instance running at 127.0.0.1:11434 but cannot add Ollama as model in RagFlow`
- 4.12 你是否提供使用深度文档解析PDF或其他文件的示例?
- 4.13 为什么我无法将10MB+文件上传到本地部署的RAGFlow?
- 4.14 `Table 'rag_flow.document' doesn't exist`
- 4.15 `hint : 102 Fail to access model Connection error`
- 4.16`FileNotFoundError: [Errno 2] No such file or directory`
- 五、用法[情况](https://ragflow.io/docs/dev/faq#usage)
- 1、如何增加RAGFlow响应的长度?
- 2、空响应是什么意思?如何设置?
- 3、我可以在某个地方设置OpenAI的基本URL吗?
- 4、如何使用本地部署的LLM运行RAGFlow?
- 5、如何链接ragflow和ollama服务器?
- 6、如何配置RAGFlow以100%匹配的结果响应,而不是利用LLM?
- 7、我需要连接到Redis吗?
- 8、`Error: Range of input length should be [1, 30000]`
- 9、如何升级RAGFlow?
快速启动
RAGFlow是一个基于深度文档理解的开源RAG(检索-增强生成)引擎。当与LLM集成时,它能够提供真实的问答功能,并得到来自各种复杂格式数据的有根据的引用的支持。
本快速入门指南描述了以下一般过程:
- 启动本地RAGFlow服务器,
- 创建知识库,
- 干预文件解析,以
- 根据您的数据集建立AI聊天。
一、先决条件
- CPU≥ 4核;
- RAM≥16 GB;
- 磁盘≥50 GB;
- Docker≥24.0.0&Docker Compose≥v2.26.1。
如果尚未在本地计算机(Windows、Mac或Linux)上安装Docker,请参阅安装Docker引擎。
二、启动服务器
本节提供了在Linux上设置RAGFlow服务器的说明。如果您使用的是不同的操作系统,不用担心。大多数步骤都是相似的。
1、确保 vm.max_map_count ≥ 262144:
vm.max_map_count.此值设置进程可能拥有的内存映射区域的最大数量。它的默认值是65530。虽然大多数应用程序需要少于一千个映射,但减少此值可能会导致异常行为,当进程达到限制时,系统会抛出内存不足错误。
RAGFlow v0.10.0使用Elasticsearch进行多次调用。正确设置vm.max_map_count的值对于Elasticsearch组件的正常运行至关重要。
Linux
1.1.检查vm.max_map_count的值:
$ sysctl vm.max_map_count
1.2.重置vm.max_map_count到一个值至少262144如果不是。
$ sudo sysctl -w vm.max_map_count=262144
警告
此更改将在系统重新启动后重置。如果下次启动服务器时忘记更新该值,您可能会收到Can't connect to ES cluster异常。
1.3.为确保您的更改保持永久,请相应地添加或更新**/etc/sysctl.conf**中的vm.max_map_count值:
vm.max_map_count=262144
macOS
如果您在带有Docker Desktop的macOS上,请运行以下命令来更新vm.max_map_count:
docker run --rm --privileged --pid=host alpine sysctl -w vm.max_map_count=262144
警告
此更改将在系统重新启动后重置。如果下次启动服务器时忘记更新该值,您可能会收到Can't connect to ES cluster异常。
要使您的更改持久化,请使用正确的设置创建一个文件:
1.1 创建文件:
sudo nano /Library/LaunchDaemons/com.user.vmmaxmap.plist
1.2 打开文件:
sudo launchctl load /Library/LaunchDaemons/com.user.vmmaxmap.plist
1.3 添加设置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.user.vmmaxmap</string>
<key>ProgramArguments</key>
<array>
<string>/usr/sbin/sysctl</string>
<string>-w</string>
<string>vm.max_map_count=262144</string>
</array>
<key>RunAtLoad</key>
<true/>
</dict>
</plist>
1.4.保存文件后,加载新的守护进程:
sudo launchctl load /Library/LaunchDaemons/com.user.vmmaxmap.plist
注意:如果上述步骤不起作用,请考虑使用此解决方法,它使用容器并且不需要手动编辑macOS设置。
2、克隆存储库:
$ git clone https://github.com/infiniflow/ragflow.git
3、构建预构建的Docker映像并启动服务器:
运行以下命令会自动下载开发版本RAGFlow Docker映像。要下载并运行指定的Docker版本,请在运行以下命令之前将 docker/.env 中的RAGFLOW_VERSION更新到预期版本,例如RAGFLOW_VERSION=v0.10.0。
$ cd ragflow/docker
$ chmod +x ./entrypoint.sh
$ docker compose up -d
核心映像的大小约为9 GB,可能需要一段时间才能加载。
4、服务器启动并运行后检查服务器状态:
$ docker logs -f ragflow-server
以下输出确认系统成功启动:
____ ______ __
/ __ \ ____ _ ____ _ / ____// /____ _ __
/ /_/ // __ `// __ `// /_ / // __ \| | /| / /
/ _, _// /_/ // /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_| \__,_/ \__, //_/ /_/ \____/ |__/|__/
/____/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
如果您跳过此确认步骤并直接登录RAGFlow,您的浏览器可能会提示network anomaly错误,因为此时您的RAGFlow可能尚未完全初始化。
5、在您的Web浏览器中,输入服务器的IP地址并登录RAGFlow。
警告:使用默认设置,您只需要输入http://IP_OF_YOUR_MACHINE(无端口号),因为使用默认配置时可以省略默认HTTP服务端口80。
三、配置LLM
RAGFlow是一个RAG引擎,它需要与LLM一起工作以提供接地气、无幻觉的问答功能。目前,RAGFlow支持以下LLM,并且列表正在扩展:
- OpenAI
- Azure-OpenAI
- Gemini
- Groq
- Mistral
- Bedrock
- Tongyi-Qianwen
- ZHIPU-AI
- MiniMax
- Moonshot
- DeepSeek
- Baichuan
- VolcEngine
- Jina
- OpenRouter
- StepFun
注意:RAGFlow还支持使用Ollama、XINETH或LocalAI在本地部署LLM,但本快速入门指南未涵盖这部分。
要添加和配置LLM:
1、单击页面右上角的徽标>模型提供商:

每个RAGFlow账号都可以免费使用同易前文的嵌入模型text-嵌入ding-v2。这就是为什么您可以在添加模型列表中看到同易前文。您可能需要稍后更新您的同易前文API密钥。
2、单击所需的LLM并相应地更新API密钥(在本例中为DeepSeek-V2):

您添加的模型如下所示:

3、单击系统模型设置以选择默认模型:
- 聊天模型,
- 嵌入模型,
- 图像到文本模型。

某些模型,例如图像到文本模型qwen-vl-max,是特定LLM的附属模型。您可能需要更新API密钥才能访问这些模型。
四、创建您的第一个知识库
您可以将文件上传到RAGFlow中的知识库并将其解析为数据集。知识库实际上是数据集的集合。RAGFlow中的问答可以基于特定的知识库或多个知识库。RAGFlow支持的文件格式包括文档(PDF、DOC、DOCX、TXT、MD)、表格(CSV、XLSX、XLS)、图片(JPEG、JPG、PNG、TIF、GIF)和幻灯片(PPT、PPTX)。
要创建您的第一个知识库:
1、单击页面顶部中间的知识库选项卡>创建知识库。
2、输入您的知识库名称,然后单击确定以确认您的更改。
您将被带到知识库的配置页面。

3、RAGFlow提供了多种块模板,可满足不同的文档布局和文件格式。为您的知识库选择嵌入模型和块方法(模板)。
重要:一旦您选择了一个嵌入模型并使用它来解析文件,您就不再被允许更改它。显而易见的原因是,我们必须确保特定知识库中的所有文件都使用相同的嵌入模型进行解析(确保它们在相同的嵌入空间中进行比较)。
您将被带到知识库的数据集页面。
4、单击+添加文件>本地文件以开始将特定文件上传到知识库。
5、在上传的文件条目中,单击播放按钮开始文件解析:

文件解析完成后,其解析状态更改为SUCCESS。
注
- 如果您的文件解析卡在1%以下,请参阅常见问题4.3。
- 如果您的文件解析在接近完成时卡住,请参阅常见问题4.4
五、文件解析
RAGFlow具有可见性和可解释性,允许您查看分块结果并在必要时进行干预。为此:
1、单击完成文件解析的文件以查看分块结果:
您将被带到Chunk页面:

2、将鼠标悬停在每个快照上以快速查看每个块。
3、双击分块文本以添加关键字或在必要时进行手动更改:

注:您可以将关键字添加到文件块以增加其相关性。此操作会增加其关键字权重,并可以提高其在搜索列表中的位置。
4、在检索测试中,在测试文本中提出一个快速问题,以仔细检查您的配置是否有效:
从下面可以看出,RAGFlow以真实的引用作为回应。

六、设置一个AI聊天
RAGFlow中的对话基于特定的知识库或多个知识库。创建知识库并完成文件解析后,您可以继续并开始AI对话。
1、单击法师中间顶部的聊天选项卡>创建助手以显示下一个对话的聊天配置对话。
RAGFlow提供了为每个对话选择不同聊天模型的灵活性,同时允许您在系统模型设置中设置默认模型。
2、更新助手设置:
- 为您的助手命名并指定您的知识库。
- 空响应 :
- 如果您希望将RAGFlow的答案限制在您的知识库中,请在此处留下响应。然后当它没有检索到答案时,它会统一地响应您在此处设置的内容。
- 如果您希望RAGFlow在无法从您的知识库中检索答案时即兴发挥,请将其留空,这可能会导致幻觉。
3、更新提示引擎或保持原样开始。
4、更新模型设置。
5、RAGFlow还提供对话API。将鼠标悬停在您的对话>Chat Bot API上以将RAGFlow的聊天功能集成到您的应用程序中:

6、现在,让我们开始表演:


配置知识库
知识库、无幻觉聊天和文件管理是RAGFlow的三大支柱。RAGFlow的AI聊天基于知识库。RAGFlow的每个知识库都作为知识源,将从本地机器上传的文件和文件管理中生成的文件引用解析为未来AI聊天的真正“知识”。本指南演示了知识库功能的一些基本用法,涵盖以下主题:
- 创建知识库
- 配置知识库
- 搜索知识库
- 删除知识库
一、创建知识库
借助多个知识库,您可以构建更灵活、多样化的问答。创建您的第一个知识库:

每次创建知识库时,都会在 root/.knowledgebase 目录中生成一个同名文件夹。
二、配置知识库
以下屏幕截图显示了知识库的配置页面。正确配置您的知识库对于未来的AI聊天至关重要。例如,选择错误的嵌入模型或块方法会导致聊天中意外的语义丢失或答案不匹配。

本节涵盖以下主题:
- 选择块方法
- 选择嵌入模型
- 上传文件
- 解析文件
- 干预文件解析结果
- 运行检索测试
1、选择块方法
RAGFlow提供多个分块模板,方便分块不同布局的文件,并确保语义完整性。在分块方法中,您可以选择适合文件布局和格式的默认模板。下表显示了每个支持的块模板的描述和兼容的文件格式:
| 模板 | 描述 | 文件格式 |
|---|---|---|
| 常规 | 文件根据预设的块令牌编号连续分块。 | DOCX、EXCEL、PPT、PDF、TXT、JPEG、JPG、PNG、TIF、GIF |
| 问答 | EXCEL、CSV/TXT | |
| 手册 | ||
| 表格 | EXCEL、CSV/TXT | |
| 纸 | ||
| 书籍 | DOCX、PDF、TXT | |
| 法律 | DOCX、PDF、TXT | |
| 演示文稿 | PDF、PPTX | |
| 图片 | JPEG、JPG、PNG、TIF、GIF | |
| 一个 | 整个文档被分块为一个。 | DOCX、EXCEL、PDF、TXT |
您还可以在数据集页面上更改特定文件的块模板。

2、选择嵌入模型
嵌入模型在文件块上构建向量索引。一旦您选择了一个嵌入模型并用它来解析一个文件,您就不再被允许更改它。要切换到不同的嵌入模型,您必须删除知识库中所有完成的文件块。显而易见的原因是,我们必须确保使用相同的嵌入模型解析特定知识库中的所有文件(确保它们在相同的嵌入空间中进行比较)。
以下嵌入模型可以在本地部署:
- BAAI/bge-large-zh-v1.5
- BAAI/bge-base-en-v1.5
- BAAI/bge-large-en-v1.5
- BAAI/bge-small-en-v1.5
- BAAI/bge-small-zh-v1.5
- jinaai/jina-embeddings-v2-base-en
- jinaai/jina-embeddings-v2-small-en
- nomic-ai/nomic-embed-text-v1.5
- sentence-transformers/all-MiniLM-L6-v2
- maidalun1020/bce-embedding-base_v1
3、上传文件
- RAGFlow的文件管理允许您将文件链接到多个知识库,在这种情况下,每个目标知识库都包含对文件的引用。
- 在知识库中,您还可以选择将单个文件或文件文件夹(批量上传)从本地计算机上传到知识库,在这种情况下,知识库保存文件副本。
虽然将文件直接上传到知识库似乎更方便,但我们强烈建议将文件上传到文件管理,然后将它们链接到目标知识库。这样,您可以避免永久删除上传到知识库的文件。
4、解析文件
文件解析是知识库配置中的一个关键主题。RAGFlow中文件解析的含义有两个:基于文件布局对文件进行分块,并在这些块上构建嵌入和全文(关键字)索引。选择块方法和嵌入模型后,您可以开始解析文件:

- 单击UNSTART旁边的播放按钮开始文件解析。
- 如果您的文件解析长时间停顿,请单击红十字图标,然后刷新。
- 如上所示,RAGFlow允许您对特定文件使用不同的块方法,提供超出默认方法的灵活性。
- 如上所示,RAGFlow允许您启用或禁用单个文件,从而更好地控制基于知识库的AI聊天。
5、干预文件解析结果
RAGFlow具有可见性和可解释性,允许您查看分块结果并在必要时进行干预。为此:
5.1 单击完成文件解析的文件以查看分块结果:
您将被带到Chunk页面:

5.2 将鼠标悬停在每个快照上以快速查看每个块。
5.3 双击分块文本以添加关键字或在必要时进行手动更改:

注:您可以将关键字添加到文件块以增加其相关性。此操作会增加其关键字权重,并可以提高其在搜索列表中的位置。
5.4 在检索测试中,在测试文本中提出一个快速问题,以仔细检查您的配置是否有效:
从下面可以看出,RAGFlow以真实的引用作为回应。

6、运行检索测试
RAGFlow在其聊天中使用全文搜索和矢量搜索的多次调用。在设置AI聊天之前,请考虑调整以下参数以确保预期信息始终出现在答案中:
- 相似阈值:相似度低于阈值的块将被过滤。默认设置为0.2。
- 向量相似度权重:向量相似度对总分的贡献百分比。默认设置为0.3。

三、搜索知识库
从RAGFlow v0.10.0开始,搜索功能仍然处于初级形式,仅支持按名称进行知识库搜索。

四、删除知识库
您可以删除知识库。将鼠标悬停在目标知识库卡片的三个点上,出现删除选项。删除知识库后,root/.knowledge 目录下的关联文件夹将自动删除。结果是:
- 直接上传到知识库的文件不见了;
- 您从文件管理中创建的文件引用已消失,但相关文件仍存在于文件管理中。

开始AI聊天
知识库、无幻觉聊天和文件管理是RAGFlow的三大支柱。RAGFlow中的聊天基于特定的知识库或多个知识库。一旦您创建了知识库并完成了文件解析,您就可以继续并开始AI对话。
一、开始一个AI聊天
您通过创建助手来开始AI对话。
1、单击页面中间顶部的聊天选项卡>创建助手以显示下一个对话的聊天配置对话。
RAGFlow为您提供了为每个对话选择不同聊天模型的灵活性,同时允许您在系统模型设置中设置默认模型。
2、更新助手设置:
- 助手名称是您的聊天助手的名称。每个助手对应一个对话,该对话具有知识库、提示、混合搜索配置和大型模型设置的独特组合。
- 空洞的回应 :
- 如果您希望将RAGFlow的答案限制在您的知识库中,请在此处留下响应。然后当它没有检索到答案时,它会统一地响应您在此处设置的内容。
- 如果您希望RAGFlow在无法从您的知识库中检索答案时即兴发挥,请将其留空,这可能会导致幻觉。
- 显示报价:这是RAGFlow的一个关键特性,默认启用。RAGFlow不像黑匣子一样工作。相反,它清楚地显示其响应所基于的信息源。
- 选择相应的知识库。您可以选择一个或多个知识库,但要确保它们使用相同的嵌入模型,否则会发生错误。
3、更新提示引擎:
- 在System中,您填写LLM的提示,您也可以将默认提示保留为开头。
- 相似度阈值为每个文本块设置相似度“栏”。默认值为0.2。相似度分数较低的文本块将从最终响应中过滤掉。
- 向量相似度权重默认设置为0.3,RAGFlow使用混合评分系统,结合关键词相似度和向量相似度,用于评估不同文本块的相关性,该值设置分配给混合评分中向量相似度组件的权重。
- 前N决定了馈送到LLM的最大块数。换句话说,即使检索到更多的块,也只提供前N个块作为输入。
- 变量:
4、更新模型设置:
- 在模型中:您选择聊天模型。虽然您在系统模型设置中选择了默认聊天模型,但RAGFlow允许您为对话选择替代聊天模型。
- 自由是指 LLM 即兴创作的水平。从即兴、精确到平衡,每个自由级别对应于温度、顶部P、存在惩罚和频率惩罚的独特组合。
- 温度:LLM预测随机性的水平。值越高,LLM越有创造力。
- 顶部P也称为“细胞核采样”。有关更多信息,请参阅此处。
- Max Tokens:LLM响应的最大长度。请注意,如果此值设置得太低,响应可能会被缩减。
5、现在,让我们开始表演:


二、更新现有对话的设置
将鼠标悬停在预期对话框上>编辑以显示聊天配置对话框:

三、将聊天功能集成到您的应用程序中
RAGFlow还提供对话API。将鼠标悬停在您的对话>Chat Bot API上以将RAGFlow的聊天功能集成到您的应用程序中:

管理文件
知识库、无幻觉聊天和文件管理是RAGFlow的三大支柱。RAGFlow的文件管理允许您单独或批量上传文件。然后,您可以将上传的文件链接到多个目标知识库。本指南展示了文件管理功能的一些基本用法。
一、创建文件夹
RAGFlow的文件管理允许您使用嵌套文件夹结构建立文件系统。要在RAGFlow的根目录中创建文件夹:

RAGFlow中的每个知识库在 root/.knowledgebase 目录下都有一个对应的文件夹。您不允许在其中创建子文件夹。
二、上传文件
RAGFlow的文件管理支持从本地计算机上传文件,允许单独和批量上传:


三、预览文件
RAGFlow的文件管理支持预览以下格式的文件:
- 文件(PDF、DOCS)
- 表(XLSX)
- 图片(JPEG、JPG、PNG、TIF、GIF)

四、将文件链接到知识库
RAGFlow的文件管理允许您将上传的文件链接到多个知识库,在每个目标知识库中创建文件引用。因此,在文件管理中删除文件将自动删除知识库中所有相关的文件引用。

您可以一次将文件链接到一个知识库或多个知识库:

五、将文件移动到特定文件夹

六、搜索文件或文件夹
从RAGFlow v0.10.0开始,搜索功能仍然处于初级形式,仅支持按名称在当前目录中搜索文件和文件夹(不会检索子目录中的文件或文件夹)。

七、重命名文件或文件夹
RAGFlow的文件管理允许您重命名文件或文件夹:

八、删除文件或文件夹
RAGFlow的文件管理允许您单独或批量删除文件或文件夹。
要删除文件或文件夹:

要批量删除文件或文件夹:

您不允许删除root/.knowledgebase 文件夹。
删除已链接到知识库的文件将自动删除知识库中所有相关的文件引用。
九、下载上传文件
RAGFlow的文件管理允许您下载上传的文件:

从RAGFlow v0.10.0开始,不支持批量下载,也不能下载整个文件夹。
编辑此页
配置您的API密钥
RAGFlow与在线AI模型交互需要API密钥。本指南提供有关在RAGFlow中设置API密钥的信息。
一、获取您的API密钥
目前,RAGFlow支持以下在线LLM。单击相应的链接申请您的API密钥。大多数LLM提供商授予新创建的帐户试用积分(将在几个月内到期)或促销金额的免费配额。
- OpenAI
- Azure-OpenAI
- Gemini
- Groq
- Mistral
- Bedrock
- Tongyi-Qianwen
- ZHIPU-AI
- MiniMax
- Moonshot
- DeepSeek
- Baichuan
- VolcEngine
- Jina
- OpenRouter
- StepFun
注意:如果您发现您的在线LLM不在列表中,请不要感到沮丧。列表正在扩展,您可以向我们提交功能请求!或者,如果您有自定义或本地部署的模型,您可以使用Ollama、新参考或LocalAI将它们绑定到RAGFlow。
二、配置您的API密钥
您有两个选项来配置API密钥:
- 在启动RAGFlow之前,在service_conf. yaml中配置它。
- 登录RAGFlow后在模型提供程序页面上对其进行配置。
1、在启动RAGFlow之前配置API密钥
1.1 导航到 ./docker/ragflow。
1.2 查找入口 user_default_llm:
- 使用您选择的LLM更新
factory。 - 用你的更新
api_key。 - 如果使用代理连接到远程服务,请更新
base_url。
1.3 重新启动系统以使更改生效。
1.4 登录到RAGFlow。
登录RAGFlow后,您会发现您选择的模型出现在模型提供程序页面上的添加模型下。
2、登录RAGFlow后配置API密钥
警告:登录RAGFlow后,通过service_conf. yaml文件配置API密钥将不再生效。
登录RAGFlow后,您只能在Model Providers页面配置API Key:
- 单击页面右上角的徽标>模型提供商。
- 点击添加模型

- 粘贴您的API密钥。
- 如果您使用代理连接到远程服务,请填写您的基本URL。
- 单击确定以确认您的更改。
注意:

部署本地LLM
RAGFlow支持使用Ollama或新会议在本地部署模型。如果您有本地部署的模型来利用或希望启用GPU或CUDA来加速推理,您可以将Ollama或新会议绑定到RAGFlow,并将它们中的任何一个用作与本地模型交互的本地“服务器”。
RAGFlow与Ollama和新意无缝集成,无需进一步的环境配置。您可以使用它们在RAGFlow中部署两种类型的本地模型:聊天模型和嵌入模型。
注:本用户指南不打算涵盖Ollama或新会议的大部分安装或配置细节;它的重点是RAGFlow内部的配置。要获得最新信息,您可能需要查看Ollama或新会议的官方网站。
一、使用jina部署本地模型
Jina 允许您构建通过gRPC、HTTP和WebSockets进行通信的AI服务和管道,然后将它们扩展并部署到生产环境。
要使用Jina部署本地模型,例如gpt2:
1、检查防火墙设置
确保主机的防火墙允许端口12345上的入站连接。
sudo ufw allow 12345/tcp
2、安装包
pip install jina
3、部署本地模型
第1步:导航到rag/svr目录。
cd rag/svr
第二步:使用Python运行jina_server.py脚本,传入模型名称或模型的本地路径(脚本只支持加载从Huggingface下载的模型)
python jina_server.py --model_name gpt2
二、使用Ollama部署本地模型
Ollama使您能够运行本地部署的开源大型语言模型。它将模型权重、配置和数据捆绑到由Modelfile定义的单个包中,并优化设置和配置,包括GPU使用。
注意
- 有关下载Ollama的信息,请参阅此处。
- 有关配置Ollama服务器的信息,请参见此处。
- 有关支持的模型和变体的完整列表,请参阅Ollama模型库。
要使用Ollama部署本地模型,例如Llama3:
1、检查防火墙设置
确保主机的防火墙允许端口11434上的入站连接。例如:
sudo ufw allow 11434/tcp
2、确保Ollama是可访问的
重新启动系统并使用curl或Web浏览器检查您在http://localhost:11434的Ollama服务的服务URL是否可访问。
Ollama is running
3、运行您的本地模型
ollama run llama3
如果你的Ollama是通过Docker安装的,请运行以下命令:
docker exec -it ollama ollama run llama3
4、添加Ollama
在RAGFlow中,单击页面右上角的徽标>模型提供程序并将Ollama添加到RAGFlow:

5、完成基本的Ollama设置
在弹出窗口中,完成Ollama的基本设置:
- 因为llama3是聊天模型,所以选择chat作为模型类型。
- 确保您在此处输入的模型名称与您使用Ollama运行的本地模型的名称完全匹配。
- 确保您输入的基本URL可供RAGFlow访问。
- 可选:如果您的模型包含图像到文本模型,则在是否支持视觉下打开切换。
注
- 如果您的Ollama和RAGFlow在同一台机器上运行,请使用
http://localhost:11434作为基本URL。 - 如果您的Ollama和RAGFlow在同一台机器上运行,并且Ollama在Docker中,请使用
http://host.docker.internal:11434作为基本URL。 - 如果您的Ollama在与RAGFlow不同的机器上运行,请使用
http://<IP_OF_OLLAMA_MACHINE>:11434作为基本URL。
警告:如果您的Ollama在另一台机器上运行,您可能还需要在ollama.service中将 OLLAMA_HOST 环境变量设置为 0.0.0.0 (请注意,这不是基本URL):
Environment="OLLAMA_HOST=0.0.0.0"
更多信息可见:https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
警告:不正确的基本URL设置将触发以下错误:
Max retries exceeded with url: /api/chat (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0xffff98b81ff0>: Failed to establish a new connection: [Errno 111] Connection refused'))
6、更新系统模型设置
单击您的徽标>模型提供商>系统模型设置以更新您的模型:
您现在应该能够从聊天模型下的下拉列表中找到llama3。
如果您的本地模型是嵌入模型,您应该在嵌入模型下找到您的本地模型。
7、更新聊天配置
在聊天配置中相应地更新您的聊天模型:
如果您的本地模型是嵌入模型,请在知识库的配置页面上更新它。
三、部署一个本地模型
Xorbits推理(新推理)使您能够释放尖端AI模型的全部潜力。
注意
- 有关安装新会议Ollama的信息,请参阅此处。
- 有关支持的模型的完整列表,请参阅内置模型。
要部署本地模型,例如Mistral,请使用新约:
1、检查防火墙设置
确保主机的防火墙允许端口9997上的入站连接。
2、启动一个新会议实例
$ xinference-local --host 0.0.0.0 --port 9997
3、启动您的本地模型
启动本地模型(Mistral),确保将${quantization}替换为您选择的量化方法:
$ xinference launch -u mistral --model-name mistral-v0.1 --size-in-billions 7 --model-format pytorch --quantization ${quantization}
4、添加新元素
在RAGFlow中,单击页面右上角的徽标 > 模型提供者并将新会议添加到RAGFlow:

5、完成基本的新会议设置
输入可访问的基本URL,例如http://<your-xinference-endpoint-domain>:9997/v1。
对于重新排名模型,请使用 http://<your-xinference-endpoint-domain>:9997/v1/rerank作为基本URL。
6、更新系统模型设置
单击您的徽标>模型提供商>系统模型设置以更新您的模型。
您现在应该能够从聊天模型下的下拉列表中找到mistral。
如果您的本地模型是嵌入模型,您应该在嵌入模型下找到您的本地模型。
7、更新聊天配置
在 Chat Configuration 相应地更新您的聊天模式:
如果您的本地模型是嵌入模型,请在知识库的配置页面上更新它。
四、Deploy a local model using IPEX-LLM
IPEX-LLM是一个PyTorch库,用于在本地Intel CPU或GPU(包括iGPU或Arc、Flex和Max等离散GPU)上以低延迟运行LLM。它支持Linux和Windows系统上的Ollama。
要使用 IPEX-LLM-acceleratedOllama 部署本地模型,例如Qwen2:
1、检查防火墙设置
确保主机的防火墙允许端口11434上的入站连接。例如:
sudo ufw allow 11434/tcp
2、使用IPEX-LLM启动Ollama服务
2.1 为Ollama安装IPEX-LLM
注:IPEX-LLM在Linux和Windows系统上支持Ollama。
有关为Ollama安装IPEX-LLM的详细信息,请参阅在Intel GPU Guide上使用IPEX-LLM运行llama. cpp:
- 先决条件
- 使用Ollama二进制文件安装IPEX-LLM cpp
安装后,您应该已经创建了一个Conda环境,例如llm-cpp,用于使用IPEX-LLM运行Ollama命令。
2.2 初始化Ollama
2.2.1 激活llm-cppConda环境并初始化Ollama:
- Linux
- 视窗
conda activate llm-cpp
init-ollama
2.2.2 如果安装的ipex-llm[cpp]需要升级到Ollama二进制文件,请删除旧的二进制文件并使用init-ollama(Linux)或init-ollama.bat(Windows)重新初始化Ollama。
指向Ollama的符号链接出现在您的当前目录中,您可以按照标准Ollama命令使用此可执行文件。
2.3 推出Ollama服务
2.3.1 将环境变量OLLAMA_NUM_GPU设置为999,以确保模型的所有层都在Intel GPU上运行;否则,某些层可能默认为CPU。
2.3.2 为了在采用Linux操作系统(内核6.2)的英特尔Arc™A系列显卡上获得最佳性能,请在启动Ollama服务之前设置以下环境变量:
export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
2.3.3 启动Ollama服务:
- Linux
export OLLAMA_NUM_GPU=999
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
source /opt/intel/oneapi/setvars.sh
export SYCL_CACHE_PERSISTENT=1
./ollama serve
注:要使Ollama服务能够接受来自所有IP地址的连接,请使用OLLAMA_HOST=0.0.0.0 ./ollama serve而不是简单地./ollama serve。
控制台显示类似于以下内容的消息:
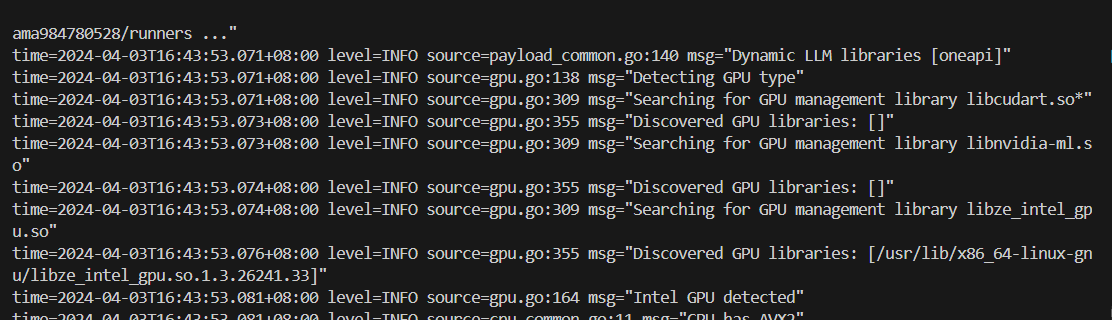
3、拉和运行Ollama模型
3.1 拉动Ollama模型
随着Ollama服务的运行,打开一个新的终端并运行./ollama pull <model_name>(Linux)或ollama.exe pull <model_name>(Windows)以拉取所需的模型。例如,qwen2:latest:

3.2 运行Ollama模型
- Linux
./ollama run qwen2:latest
4、配置RAGflow
要在RAGFlow中启用IPEX-LLM加速Ollama,您还必须完成RAGFlow中的配置。这些步骤与使用Ollama部署本地模型部分中概述的步骤相同:
- 添加Ollama
- 完成基本的Ollama设置
- 更新系统模型设置
- 更新聊天配置
贡献准则
感谢您想为RAGFlow做出贡献。本文档提供了提交贡献的指南和主要注意事项。
- 要报告bug,请向我们提交GitHub问题。
- 如需更多问题,您可以探索现有讨论或在讨论中发起新的讨论。
你能贡献什么
下面的列表提到了你可以做出的一些贡献,但它不是一个完整的列表。
- 提出或实施新功能
- 修复bug
- 添加测试用例或演示
- 发布博客或教程
- 更新现有文档、代码或注释。
- 建议更用户友好的错误代码
提交拉取请求(PR)
一般工作流程
- 分叉我们的GitHub存储库。
- 将您的fork克隆到本地机器:
git clone git@github.com:<yourname>/ragflow.git - 创建本地分支:
git checkout -b my-branch - 在提交消息中提供足够的信息
git commit -m 'Provide sufficient info in your commit message' - 将更改提交到您的本地分支,并推送到GitHub:(包括必要的提交消息)
git push origin my-branch. - 提交拉取请求以供审核。
在提交公关申请之前
- 考虑将大型PR拆分为多个较小的独立PR,以保持可追溯的开发历史。
- 确保您的PR只解决一个问题,或者保持任何不相关的更改很小。
- 在贡献新功能时添加测试用例。它们证明您的代码功能正确,并防止未来更改带来的潜在问题。
描述你的公关
- 确保您的PR标题简洁明了,提供所有必需的信息。
- 如果适用,请参阅PR描述中相应的GitHub问题。
- 在您的描述中包含足够的设计细节以破坏更改或API更改。
审查和合并PR
- 确保您的PR在合并之前通过了所有持续集成(CI)测试。
API参考
RAGFlow提供RESTful API供您将其功能集成到第三方应用程序中。
一、基本网址
https://demo.ragflow.io/v1/
二、授权
RAGFlow的所有RESTful API都使用API密钥进行授权,因此请确保其安全,不要将其暴露给前端。将您的API密钥放在请求标头中。
Authorization: Bearer {API_KEY}
注意:在当前设计中,您从RAGFlow获得的RESTful API密钥不会过期。
要获取您的聊天API密钥或代理API密钥:
对于聊天API密钥:
- 在RAGFlow中,单击页面中间顶部的聊天选项卡。
- 将鼠标悬停在相应的对话框>Chat Bot API上以显示聊天机器人API配置页面。
- 单击API密钥>创建新密钥以创建您的API密钥。
- 复制并确保您的API密钥安全。
对于代理API密钥:
- 在RAGFlow中,单击页面中间顶部的代理选项卡。
- 单击您的代理>Chat Bot API以显示聊天机器人API配置页面。
- 单击API密钥>创建新密钥以创建您的API密钥。
- 复制并确保您的API密钥安全。
三、创建对话
此方法为特定用户创建(新闻)对话。
请求
请求URI
| 方法 | 请求URI |
|---|---|
| GET | /api/new_conversation |
注意:您需要保存响应数据中返回的data.id值,即所有即将进行的对话的会话ID。
请求参数
| 名称 | 类型 | 必需 | 描述 |
|---|---|---|---|
user_id | 字符串 | 是 | 分配给每个用户的唯一标识符。user_id必须小于32个字符,并且不能为空。支持以下字符集: -26个小写英文字母(a-z) -26个大写英文字母(A-Z) -10位数字(0-9) -“_”, “-”, “.” |
响应
{
"data": {
"create_date": "Fri, 12 Apr 2024 17:26:21 GMT",
"create_time": 1712913981857,
"dialog_id": "4f0a2e4cb9af11ee9ba20aef05f5e94f",
"duration": 0.0,
"id": "b9b2e098f8ae11ee9f45fa163e197198",
"message": [
{
"content": "Hi, I'm your assistant, what can I do for you?",
"role": "assistant"
}
],
"reference": [],
"tokens": 0,
"update_date": "Fri, 12 Apr 2024 17:26:21 GMT",
"update_time": 1712913981857,
"user_id": "<USER_ID_SET_BY_THE_CALLER>"
},
"retcode": 0,
"retmsg": "success"
}
四、获取对话历史记录
此方法检索指定对话会话的历史记录。
请求
请求URI
| 方法 | 请求URI |
|---|---|
| GET | /api/conversation/<id> |
请求参数
| 名称 | 类型 | 必需 | 描述 |
|---|---|---|---|
id | 字符串 | 是 | 分配给对话会话的唯一标识符。id必须小于32个字符,并且不能为空。支持以下字符集: -26个小写英文字母(a-z) -26个大写英文字母(A-Z) -10位数字(0-9) -“_”, “-”, “.” |
响应
响应参数
message:指定对话会话中的所有对话。role:"user"或"assistant"。content:用户或助手的文本内容。引用的格式类似于##0$$。中间的数字,在本例中为0,表示它指的是data.引用. chunks中的哪一部分。
user_id:这是由调用者设置的。reference:每个参考对应于助理在data.message-
chunkscontent_with_weight:块的内容。doc_name:命中文档的名称。img_id:块的图像ID。它是仅用于PDF、PPTX和图像的可选字段。调用’GET’ /document/get/来检索图像。positions:[page_number,[upleft角(x,y)],[右下角(x,y)]],块位置,仅适用于PDF。similarity:混合相似性。term_similarity:关键字相似。vector_similarity:嵌入相似性。
-
doc_aggs:doc_id:命中文档的ID。调用’GET’ /document/get/来检索文档。doc_name:命中文档的名称。count:文档中命中块的数量。
-
{
"data": {
"create_date": "Mon, 01 Apr 2024 09:28:42 GMT",
"create_time": 1711934922220,
"dialog_id": "df4a4916d7bd11eeaa650242ac180006",
"id": "2cae30fcefc711ee94140242ac180006",
"message": [
{
"content": "Hi! I'm your assistant, what can I do for you?",
"role": "assistant"
},
{
"content": "What's the vit score for GPT-4?",
"role": "user"
},
{
"content": "The ViT Score for GPT-4 in the zero-shot scenario is 0.5058, and in the few-shot scenario, it is 0.6480. ##0$$",
"role": "assistant"
}
],
"user_id": "<USER_ID_SET_BY_THE_CALLER>",
"reference": [
{
"chunks": [
{
"chunk_id": "d0bc7892c3ec4aeac071544fd56730a8",
"content_ltks": "tabl 1:openagi task-solv perform under differ set for three closed-sourc llm . boldfac denot the highest score under each learn schema . metric gpt-3.5-turbo claude-2 gpt-4 zero few zero few zero few clip score 0.0 0.0 0.0 0.2543 0.0 0.3055 bert score 0.1914 0.3820 0.2111 0.5038 0.2076 0.6307 vit score 0.2437 0.7497 0.4082 0.5416 0.5058 0.6480 overal 0.1450 0.3772 0.2064 0.4332 0.2378 0.5281",
"content_with_weight": "<table><caption>Table 1: OpenAGI task-solving performances under different settings for three closed-source LLMs. Boldface denotes the highest score under each learning schema.</caption>\n<tr><th rowspan=2 >Metrics</th><th >GPT-3.5-turbo</th><th></th><th >Claude-2</th><th >GPT-4</th></tr>\n<tr><th >Zero</th><th >Few</th><th >Zero Few</th><th >Zero Few</th></tr>\n<tr><td >CLIP Score</td><td >0.0</td><td >0.0</td><td >0.0 0.2543</td><td >0.0 0.3055</td></tr>\n<tr><td >BERT Score</td><td >0.1914</td><td >0.3820</td><td >0.2111 0.5038</td><td >0.2076 0.6307</td></tr>\n<tr><td >ViT Score</td><td >0.2437</td><td >0.7497</td><td >0.4082 0.5416</td><td >0.5058 0.6480</td></tr>\n<tr><td >Overall</td><td >0.1450</td><td >0.3772</td><td >0.2064 0.4332</td><td >0.2378 0.5281</td></tr>\n</table>",
"doc_id": "c790da40ea8911ee928e0242ac180005",
"doc_name": "OpenAGI When LLM Meets Domain Experts.pdf",
"img_id": "afab9fdad6e511eebdb20242ac180006-d0bc7892c3ec4aeac071544fd56730a8",
"important_kwd": [],
"kb_id": "afab9fdad6e511eebdb20242ac180006",
"positions": [
[
9.0,
159.9383341471354,
472.1773274739583,
223.58013916015625,
307.86692301432294
]
],
"similarity": 0.7310340654129031,
"term_similarity": 0.7671974387781668,
"vector_similarity": 0.40556370512552886
},
{
"chunk_id": "7e2345d440383b756670e1b0f43a7007",
"content_ltks": "5.5 experiment analysi the main experiment result are tabul in tab . 1 and 2 , showcas the result for closed-sourc and open-sourc llm , respect . the overal perform is calcul a the averag of cllp 8 bert and vit score . ",
"content_with_weight": "5.5 Experimental Analysis\nThe main experimental results are tabulated in Tab. 1 and 2, showcasing the results for closed-source and open-source LLMs, respectively. The overall performance is calculated as the average of CLlP\n8\nBERT and ViT scores.",
"doc_id": "c790da40ea8911ee928e0242ac180005",
"doc_name": "OpenAGI When LLM Meets Domain Experts.pdf",
"img_id": "afab9fdad6e511eebdb20242ac180006-7e2345d440383b756670e1b0f43a7007",
"important_kwd": [],
"kb_id": "afab9fdad6e511eebdb20242ac180006",
"positions": [
[
8.0,
107.3,
508.90000000000003,
686.3,
697.0
],
],
"similarity": 0.6691508616357027,
"term_similarity": 0.6999011754270821,
"vector_similarity": 0.39239803751328806
},
],
"doc_aggs": [
{
"count": 8,
"doc_id": "c790da40ea8911ee928e0242ac180005",
"doc_name": "OpenAGI When LLM Meets Domain Experts.pdf"
}
],
"total": 8
},
],
"update_date": "Tue, 02 Apr 2024 09:07:49 GMT",
"update_time": 1712020069421
},
"retcode": 0,
"retmsg": "success"
}
五、得到答案
此方法从RAGFlow Chat或RAGFlow Agent检索用户最新问题的答案。
请求
请求URI
| 方法 | 请求URI |
|---|---|
| POST | /api/completion |
请求参数
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
conversation_id | 字符串 | 是 | 对话会话的ID。调用’GET’ /new_conversation检索ID。 |
messages | json | 是 | JSON表单中的最新问题,如[{"role": "user", "content": "How are you doing!"}] |
quote | bool | 否 | 默认值:false |
stream | bool | 否 | 默认值:true |
doc_ids | 字符串 | 否 | 用逗号分隔的文档ID,如c790da40ea8911ee928e0242ac180005,23dsf34ree928e0242ac180005。检索到的内容将仅限于这些文档。 |
响应
answer:用户最新问题的答案。reference-
chunks:检索到的有助于答案的块。-
content_with_weight:块的内容。 -
doc_name:命中文档的名称。 -
img_id:块的图像ID。它是仅用于PDF、PPTX和图像的可选字段。调用’GET’ /document/get/来检索图像。 -
positions:[page_number,[upleft角(x,y)],[右下角(x,y)]],块位置,仅适用于PDF。 -
similarity:混合相似性。 -
term_similarity:关键字相似。 -
vector_similarity:嵌入相似性。
-
-
doc_aggs:doc_id: ID of the hit document. Call ‘GET’ /document/get/ to retrieve the document.doc_name: Name of the hit document.count: The number of hit chunks in this document.
-
{
"data": {
"answer": "The ViT Score for GPT-4 in the zero-shot scenario is 0.5058, and in the few-shot scenario, it is 0.6480. ##0$$",
"reference": {
"chunks": [
{
"chunk_id": "d0bc7892c3ec4aeac071544fd56730a8",
"content_ltks": "tabl 1:openagi task-solv perform under differ set for three closed-sourc llm . boldfac denot the highest score under each learn schema . metric gpt-3.5-turbo claude-2 gpt-4 zero few zero few zero few clip score 0.0 0.0 0.0 0.2543 0.0 0.3055 bert score 0.1914 0.3820 0.2111 0.5038 0.2076 0.6307 vit score 0.2437 0.7497 0.4082 0.5416 0.5058 0.6480 overal 0.1450 0.3772 0.2064 0.4332 0.2378 0.5281",
"content_with_weight": "<table><caption>Table 1: OpenAGI task-solving performances under different settings for three closed-source LLMs. Boldface denotes the highest score under each learning schema.</caption>\n<tr><th rowspan=2 >Metrics</th><th >GPT-3.5-turbo</th><th></th><th >Claude-2</th><th >GPT-4</th></tr>\n<tr><th >Zero</th><th >Few</th><th >Zero Few</th><th >Zero Few</th></tr>\n<tr><td >CLIP Score</td><td >0.0</td><td >0.0</td><td >0.0 0.2543</td><td >0.0 0.3055</td></tr>\n<tr><td >BERT Score</td><td >0.1914</td><td >0.3820</td><td >0.2111 0.5038</td><td >0.2076 0.6307</td></tr>\n<tr><td >ViT Score</td><td >0.2437</td><td >0.7497</td><td >0.4082 0.5416</td><td >0.5058 0.6480</td></tr>\n<tr><td >Overall</td><td >0.1450</td><td >0.3772</td><td >0.2064 0.4332</td><td >0.2378 0.5281</td></tr>\n</table>",
"doc_id": "c790da40ea8911ee928e0242ac180005",
"doc_name": "OpenAGI When LLM Meets Domain Experts.pdf",
"img_id": "afab9fdad6e511eebdb20242ac180006-d0bc7892c3ec4aeac071544fd56730a8",
"important_kwd": [],
"kb_id": "afab9fdad6e511eebdb20242ac180006",
"positions": [
[
9.0,
159.9383341471354,
472.1773274739583,
223.58013916015625,
307.86692301432294
]
],
"similarity": 0.7310340654129031,
"term_similarity": 0.7671974387781668,
"vector_similarity": 0.40556370512552886
},
{
"chunk_id": "7e2345d440383b756670e1b0f43a7007",
"content_ltks": "5.5 experiment analysi the main experiment result are tabul in tab . 1 and 2 , showcas the result for closed-sourc and open-sourc llm , respect . the overal perform is calcul a the averag of cllp 8 bert and vit score . here , onli the task descript of the benchmark task are fed into llm(addit inform , such a the input prompt and llm\u2019output , is provid in fig . a.4 and a.5 in supplementari). broadli speak , closed-sourc llm demonstr superior perform on openagi task , with gpt-4 lead the pack under both zero-and few-shot scenario . in the open-sourc categori , llama-2-13b take the lead , consist post top result across variou learn schema--the perform possibl influenc by it larger model size . notabl , open-sourc llm significantli benefit from the tune method , particularli fine-tun and\u2019rltf . these method mark notic enhanc for flan-t5-larg , vicuna-7b , and llama-2-13b when compar with zero-shot and few-shot learn schema . in fact , each of these open-sourc model hit it pinnacl under the rltf approach . conclus , with rltf tune , the perform of llama-2-13b approach that of gpt-3.5 , illustr it potenti .",
"content_with_weight": "5.5 Experimental Analysis\nThe main experimental results are tabulated in Tab. 1 and 2, showcasing the results for closed-source and open-source LLMs, respectively. The overall performance is calculated as the average of CLlP\n8\nBERT and ViT scores. Here, only the task descriptions of the benchmark tasks are fed into LLMs (additional information, such as the input prompt and LLMs\u2019 outputs, is provided in Fig. A.4 and A.5 in supplementary). Broadly speaking, closed-source LLMs demonstrate superior performance on OpenAGI tasks, with GPT-4 leading the pack under both zero- and few-shot scenarios. In the open-source category, LLaMA-2-13B takes the lead, consistently posting top results across various learning schema--the performance possibly influenced by its larger model size. Notably, open-source LLMs significantly benefit from the tuning methods, particularly Fine-tuning and\u2019 RLTF. These methods mark noticeable enhancements for Flan-T5-Large, Vicuna-7B, and LLaMA-2-13B when compared with zero-shot and few-shot learning schema. In fact, each of these open-source models hits its pinnacle under the RLTF approach. Conclusively, with RLTF tuning, the performance of LLaMA-2-13B approaches that of GPT-3.5, illustrating its potential.",
"doc_id": "c790da40ea8911ee928e0242ac180005",
"doc_name": "OpenAGI When LLM Meets Domain Experts.pdf",
"img_id": "afab9fdad6e511eebdb20242ac180006-7e2345d440383b756670e1b0f43a7007",
"important_kwd": [],
"kb_id": "afab9fdad6e511eebdb20242ac180006",
"positions": [
[
8.0,
107.3,
508.90000000000003,
686.3,
697.0
]
],
"similarity": 0.6691508616357027,
"term_similarity": 0.6999011754270821,
"vector_similarity": 0.39239803751328806
}
],
"doc_aggs": {
"OpenAGI When LLM Meets Domain Experts.pdf": 4
},
"total": 8
}
},
"retcode": 0,
"retmsg": "success"
}
六、获取文档内容
此方法检索文档的内容。
请求
请求URI
| 方法 | 请求URI |
|---|---|
| GET | /document/get/<id> |
响应
二进制文件。
七、上传文件
此方法将特定文件上传到指定的知识库。
请求
请求URI
| 方法 | 请求URI |
|---|---|
| POST | /api/document/upload |
响应参数
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
file | 文件 | 是 | 要上传的文件。 |
kb_name | 字符串 | 是 | 要上传文件的知识库名称。 |
parser_id | 字符串 | 否 | 要使用的解析方法(块模板)。 -“朴素”:一般; -“qa”:问答; -“手册”:手册; -“表格”:表格; -“纸张”:纸张; -“法律”:法律; -“演示文稿”:演示文稿; -“图片”:图片; -“一”:一。 |
run | 字符串 | 否 | 1:自动启动文件解析。如果未设置parser_id,RAGFlow默认使用通用模板。 |
响应
{
"data": {
"chunk_num": 0,
"create_date": "Thu, 25 Apr 2024 14:30:06 GMT",
"create_time": 1714026606921,
"created_by": "553ec818fd5711ee8ea63043d7ed348e",
"id": "41e9324602cd11ef9f5f3043d7ed348e",
"kb_id": "06802686c0a311ee85d6246e9694c130",
"location": "readme.txt",
"name": "readme.txt",
"parser_config": {
"field_map": {
},
"pages": [
[
0,
1000000
]
]
},
"parser_id": "general",
"process_begin_at": null,
"process_duation": 0.0,
"progress": 0.0,
"progress_msg": "",
"run": "0",
"size": 929,
"source_type": "local",
"status": "1",
"thumbnail": null,
"token_num": 0,
"type": "doc",
"update_date": "Thu, 25 Apr 2024 14:30:06 GMT",
"update_time": 1714026606921
},
"retcode": 0,
"retmsg": "success"
}
八、获取文档切片
此方法通过 doc_name 或 doc_id 检索特定文档的块。
Request
请求URI
| 方法 | 请求URI |
|---|---|
| GET | /api/list_chunks |
请求参数
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
doc_name | 字符串 | 否 | 知识库中文档的名称。未设置doc_id不得为空。 |
doc_id | 字符串 | 否 | 知识库中文档的ID。未设置doc_name不得为空。 |
响应
{
"data": [
{
"content": "Figure 14: Per-request neural-net processingof RL-Cache.\n103\n(sn)\nCPU\n 102\nGPU\n8101\n100\n8\n16 64 256 1K\n4K",
"doc_name": "RL-Cache.pdf",
"img_id": "0335167613f011ef91240242ac120006-b46c3524952f82dbe061ce9b123f2211"
},
{
"content": "4.3 ProcessingOverheadof RL-CacheACKNOWLEDGMENTSThis section evaluates how effectively our RL-Cache implemen-tation leverages modern multi-core CPUs and GPUs to keep the per-request neural-net processing overhead low. Figure 14 depictsThis researchwas supported inpart by the Regional Government of Madrid (grant P2018/TCS-4499, EdgeData-CM)andU.S. National Science Foundation (grants CNS-1763617 andCNS-1717179).REFERENCES",
"doc_name": "RL-Cache.pdf",
"img_id": "0335167613f011ef91240242ac120006-d4c12c43938eb55d2d8278eea0d7e6d7"
}
],
"retcode": 0,
"retmsg": "success"
}
九、获取文档列表
此方法从指定的知识库中检索文档列表。
请求
请求URI
| 方法 | 请求URI |
|---|---|
| POST | /api/list_kb_docs |
请求参数
| 名称 | 类型 | 必需 | 描述 |
|---|---|---|---|
kb_name | 字符串 | 是 | 知识库的名称,从中获取文档列表。 |
page | int | 否 | 页数,默认值:1。 |
page_size | int | 否 | 每个页面的文档数,默认值:15。 |
orderby | 字符串 | 否 | chunk_num、create_time或size,默认值:create_time |
desc | bool | 否 | 默认值:True。 |
keywords | 字符串 | 否 | 文档名称的关键字。 |
响应
{
"data": {
"docs": [
{
"doc_id": "bad89a84168c11ef9ce40242ac120006",
"doc_name": "test.xlsx"
},
{
"doc_id": "641a9b4013f111efb53f0242ac120006",
"doc_name": "1111.pdf"
}
],
"total": 2
},
"retcode": 0,
"retmsg": "success"
}
十、删除文件
此方法按文档ID或名称删除文档。
请求
请求URI
| 方法 | 请求URI |
|---|---|
| DELETE | /api/document |
请求参数
| 名称 | 类型 | 必需 | 说明 |
|---|---|---|---|
doc_names | 列表 | 否 | 文档名称列表。如果未设置doc_ids,则不得为空。 |
doc_ids | 列表 | 否 | 文档ID列表。如果未设置doc_names,则不得为空。 |
响应
{
"data": true,
"retcode": 0,
"retmsg": "success"
}
常见问题
一、常见问题
1、RAGFlow与其他RAG产品的区别是什么?
尽管LLM显著提高了自然语言处理(NLP),但“垃圾输入垃圾输出”的现状保持不变。作为回应,与其他检索增强生成(RAG)产品相比,RAGFlow引入了两个独特的功能。
- 细粒度的文档解析:文档解析涉及图像和表格,您可以根据需要灵活地进行干预。
- 减少幻觉的可追溯答案:您可以信任RAGFlow的回复,因为您可以查看支持它们的引用和参考文献。
2、RAGFlow支持哪些语言?
英文,简体中文,繁体中文。
3.哪些嵌入模型可以部署在本地?
- BAAI/bge-large-zh-v1.5
- BAAI/bge-base-en-v1.5
- BAAI/bge-large-en-v1.5
- BAAI/bge-small-en-v1.5
- BAAI/bge-small-zh-v1.5
- jinaai/jina-embeddings-v2-base-en
- jinaai/jina-embeddings-v2-small-en
- nomic-ai/nomic-embed-text-v1.5
- sentence-transformers/all-MiniLM-L6-v2
- maidalun1020/bce-embedding-base_v1
二、变现
1、为什么RAGFlow解析文档的时间比LangChain长?
我们使用我们的视觉模型在文档预处理任务中投入了大量精力,例如布局分析、表格结构识别和OCR(光学字符识别)。这有助于增加所需的时间。
2、为什么RAGFlow比其他项目需要更多的资源?
RAGFlow有许多用于文档结构解析的内置模型,这些模型考虑了额外的计算资源。
三、特征
1、RAGFlow支持哪些架构或设备?
目前,我们只支持x86 CPU和Nvidia GPU。
2、您是否提供与第三方应用程序集成的API?
相应的API现在可用。有关详细信息,请参阅 RAGFlow API参考。
3、你支持流输出吗?
不,此功能仍在开发中。欢迎投稿。
4、是否可以通过网址分享对话?
是的,此功能现已可用。
5、您是否支持多轮对话,即引用以前的对话作为当前对话的上下文?
此功能和相关API仍在开发中。欢迎投稿。
四、故障排除
1、docker映像的问题
1.1 How to build the RAGFlow image from scratch?
$ git clone https://github.com/infiniflow/ragflow.git
$ cd ragflow
$ docker build -t infiniflow/ragflow:latest .
$ cd ragflow/docker
$ chmod +x ./entrypoint.sh
$ docker compose up -d
1.2 process "/bin/sh -c cd ./web && npm i && npm run build" failed
- Check your network from within Docker, for example:
curl https://hf-mirror.com
- 如果您的网络运行良好,则问题出在Docker网络配置上。替换Docker构建命令:
docker build -t infiniflow/ragflow:vX.Y.Z.
有了这个:
docker build -t infiniflow/ragflow:vX.Y.Z. --network host
2、huggingface 模型的问题
2.1无法访问 https://huggingface.co
默认情况下,本地部署的RAGflow会从Huggingface网站下载OCR和嵌入模块。如果您的机器无法访问此站点,则会发生以下错误,PDF解析失败:
FileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/huggingface/hub/models--InfiniFlow--deepdoc/snapshots/be0c1e50eef6047b412d1800aa89aba4d275f997/ocr.res'
要解决此问题,请改用https://hf-mirror.com:
- 停止所有容器并删除所有相关资源:
cd ragflow/docker/
docker compose down
- 将
https://huggingface.co替换为ragflow/docker/docker-comp. yml中的https://hf-mirror.com。 - 启动服务器:
docker compose up -d
2.2MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443)
此错误表明您无法访问Internet或无法连接到hf-mirror.com。请尝试以下操作:
- 手动将资源文件从huggingface.co/InfiniFlow/deepdoc下载到本地文件夹**~/Deep doc**。
- 向docker-comp. yml添加一个卷,例如:
- ~/deepdoc:/ragflow/rag/res/deepdoc
2.3 FileNotFoundError
FileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/huggingface/hub/models--InfiniFlow--deepdoc/snapshots/FileNotFoundError: [Errno 2] No such file or directory: '/ragflow/rag/res/deepdoc/ocr.res'be0c1e50eef6047b412d1800aa89aba4d275f997/ocr.res'
2.3.1 从Docker中检查您的网络,例如:
curl https://hf-mirror.com
2.3.2 运行ifconfig检查mtu值,如果服务器的mtu是1450而容器中的NIC的mtu是1500,这种不匹配可能会导致网络不稳定,调整mtu策略如下:
vim docker-compose-base.yml
# Original configuration:
networks:
ragflow:
driver: bridge
# Modified configuration:
networks:
ragflow:
driver: bridge
driver_opts:
com.docker.network.driver.mtu: 1450
3、RAGFlow服务器的问题
3.1WARNING: can't find /raglof/rag/res/borker.tm
忽略此警告并继续。可以忽略所有系统警告。
3.2network anomaly There is an abnormality in your network and you cannot connect to the server.

除非服务器完全初始化,否则您不会登录到RAGFlow。运行docker logs -f ragflow-server。
如果您的系统显示以下内容,则服务器已成功初始化:
____ ______ __
/ __ \ ____ _ ____ _ / ____// /____ _ __
/ /_/ // __ `// __ `// /_ / // __ \| | /| / /
/ _, _// /_/ // /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_| \__,_/ \__, //_/ /_/ \____/ |__/|__/
/____/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
4、RAGFlow后端服务的问题
4.1dependency failed to start: container ragflow-mysql is unhealthy
dependency failed to start: container ragflow-mysql is unhealthy意味着你的MySQL容器无法启动。尝试替换mysql:5.7.18与mariadb:10.5.8在docker-compose-base. yml.
4.2Realtime synonym is disabled, since no redis connection
忽略此警告并继续。可以忽略所有系统警告。

4.3 为什么我的文档解析在1%以下停滞不前?

单击“解析状态”栏旁边的红叉,然后重新启动解析过程以查看问题是否仍然存在。如果问题仍然存在并且您的RAGFlow部署在本地,请尝试以下操作:
- 检查您的RAGFlow服务器的日志以查看它是否正常运行:
docker logs -f ragflow-server
- 检查task_executor.py进程是否存在。
- 检查您的RAGFlow服务器是否可以访问hf-mirror.com或huggingface.com。
4.4 为什么我的pdf解析在接近完成时停止,而日志没有显示任何错误?
单击“解析状态”栏旁边的红叉,然后重新启动解析过程以查看问题是否仍然存在。如果问题仍然存在并且您的RAGFlow部署在本地,解析过程可能会因RAM不足而终止。尝试通过增加docker/. env中的MEM_LIMIT值来增加内存分配。
注意:确保重新启动RAGFlow服务器以使更改生效!
docker compose stop
docker compose up -d

4.5 Index failure
索引失败通常表示Elasticsearch服务不可用。
4.6 如何查看RAGFlow的日志?
tail -f path_to_ragflow/docker/ragflow-logs/rag/*.log
4.7如何检查RAGFlow中每个组件的状态?
$ docker ps
如果您的所有RAGFlow组件都正常运行,系统会显示以下内容:
5bc45806b680 infiniflow/ragflow:latest "./entrypoint.sh" 11 hours ago Up 11 hours 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp, 0.0.0.0:9380->9380/tcp, :::9380->9380/tcp ragflow-server
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 hours ago Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01
d8c86f06c56b mysql:5.7.18 "docker-entrypoint.s…" 7 days ago Up 16 seconds (healthy) 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp ragflow-mysql
cd29bcb254bc quay.io/minio/minio:RELEASE.2023-12-20T01-00-02Z "/usr/bin/docker-ent…" 2 weeks ago Up 11 hours 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio
4.8 Exception: Can't connect to ES cluster
4.8.1 检查您的Elasticsearch组件的状态:
$ docker ps
RAGFlow中“健康”Elasticsearch组件的状态应如下所示:
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 hours ago Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01
4.8.2 如果您的容器一直重启,请确保vm.max_map_count>=262144符合此自述文件。如果您希望永久保留更改,则需要更新**/etc/sysctl.conf**中的vm.max_map_count值。此配置仅适用于Linux。
4.8.3 如果您的问题仍然存在,请确保ES主机设置正确:
- 如果您使用Docker运行RAGFlow,它位于docker/service_conf. yml中。设置如下:
es:
hosts: 'http://es01:9200'
- 如果您在Docker之外运行RAGFlow,请使用以下命令验证conf/service_conf. yml中的ES主机设置:
curl http://<IP_OF_ES>:<PORT_OF_ES>
4.9 无法启动ES容器并获取Elasticsearch did not exit normally
这是因为您忘记更新**/etc/sysctl.conf**中的vm.max_map_count值,并且您对该值的更改在系统重新启动后被重置。
4.10 {"data":null,"retcode":100,"retmsg":"<NotFound '404: Not Found'>"}
您的IP地址或端口号可能不正确。如果您使用默认配置,请在浏览器中输入http://<IP_OF_YOUR_MACHINE>(不是9380,也不需要端口号!)。这应该行得通。
4.11 Ollama - Mistral instance running at 127.0.0.1:11434 but cannot add Ollama as model in RagFlow
正确的Ollama IP地址和端口对于将模型添加到Ollama至关重要:
- 如果您在demo.ragflow.io,请确保托管Ollama的服务器具有可公开访问的IP地址。请注意,127.0.0.1不是可公开访问的IP地址。
- 如果您在本地部署RAGFlow,请确保Ollama和RAGFlow在同一个LAN中并且可以相互通信。
4.12 你是否提供使用深度文档解析PDF或其他文件的示例?
是的,我们有。请参阅rag/app文件夹下的Python文件。
4.13 为什么我无法将10MB+文件上传到本地部署的RAGFlow?
您可能忘记更新MAX_CONTENT_LENGTH环境变量:
4.13.1 将环境变量MAX_CONTENT_LENGTH添加到ragflow/docker/. env:
MAX_CONTENT_LENGTH=100000000
4.13.2 更新docker-comail. yml:
environment:
- MAX_CONTENT_LENGTH=${MAX_CONTENT_LENGTH}
4.13.3 重新启动RAGFlow服务器:
docker compose up ragflow -d
现在您应该能够上传大小小于100MB的文件。
4.14 Table 'rag_flow.document' doesn't exist
启动RAGFlow服务器时会发生此异常。尝试以下操作:
4.14.1 延长睡眠时间:转到 docker/entrypoint.sh,找到第26行,并将sleep 60替换为sleep 280。
4.14.2 如果使用Windows,请确保entrypoint.sh具有LF端行。
4.14.3 转到docker/docker-comp. yml,添加以下内容:
./entrypoint.sh:/ragflow/entrypoint.sh
4.14.4 更改目录:
cd docker
4.14.5 停止RAGFlow服务器:
docker compose stop
4.14.6 重新启动RAGFlow服务器:
docker compose up
4.15 hint : 102 Fail to access model Connection error

4.15.1 确保RAGFlow服务器可以访问基本URL。
4.15.2 不要忘记将**/v1/附加到http://IP: port**: http://IP: port/v1/
4.16FileNotFoundError: [Errno 2] No such file or directory
4.16.1 检查您的minio容器的状态是否健康:
docker ps
4.16.2 确保 docker/.env 中MySQL和MinIO的用户名和密码设置与 docker/service_conf.yml 中的一致。
五、用法情况
1、如何增加RAGFlow响应的长度?
- 右键单击所需对话框以显示聊天配置窗口。
- 切换到模型设置选项卡并调整最大令牌滑块以获得所需的长度。
- 单击确定以确认您的更改。
2、空响应是什么意思?如何设置?
如果从您的知识库中没有检索到任何内容,您将限制系统对您在空响应中指定的内容的响应。如果您没有在空响应中指定任何内容,您让您的LLM即兴发挥,给它一个幻觉的机会。
3、我可以在某个地方设置OpenAI的基本URL吗?

4、如何使用本地部署的LLM运行RAGFlow?
您可以使用Ollama部署本地LLM。有关详细信息,请参阅此处。
5、如何链接ragflow和ollama服务器?
- 如果RAGFlow是本地部署的,请确保您的RAGFlow和Ollama位于同一个LAN中。
- 如果您使用我们的在线演示,请确保您的Ollama服务器的IP地址是公开且可访问的。
6、如何配置RAGFlow以100%匹配的结果响应,而不是利用LLM?
- 单击页面中间顶部的知识库。
- 右键单击所需的知识库以显示配置对话框。
- 选择问答作为块方法,然后单击保存以确认您的更改。
7、我需要连接到Redis吗?
不,不需要连接到Redis。
8、Error: Range of input length should be [1, 30000]
发生此错误是因为匹配您的搜索条件的块太多。尝试减少TopN并增加相似度阈值来解决此问题:
- 单击页面中间顶部的聊天。
- 右键单击所需的对话>编辑>提示引擎
- 降低TopN和/或提高Silimality阈值。
- 单击确定以确认您的更改。

9、如何升级RAGFlow?
您可以将RAGFlow升级到开发版本或最新版本:
- 开发版本面向开发人员和贡献者。它们每晚发布,可能会崩溃,因为它们没有经过全面测试。我们不能保证它们的有效性,您需要自行承担尝试最新、未经测试的功能的风险。
- 最新版本是指最近正式发布的版本。它很稳定,最适合普通用户。
要将RAGFlow升级到开发版本:
1)拉取最新的源代码
cd ragflow
git pull
2)如果你用了
docker compose up -d
要启动RAGFlow服务器:
docker pull infiniflow/ragflow:dev
docker compose up ragflow -d
3)如果你用了
docker compose -f docker-compose-CN.yml up -d
要启动RAGFlow服务器:
docker pull swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:dev
docker compose -f docker-compose-CN.yml up -d
要将RAGFlow升级到最新版本:
1)更新ragflow/docker/. env如下:
RAGFLOW_VERSION=latest
2)拉取最新源代码:
cd ragflow
git pull
3)如果您使用docker compose up -d来启动RAGFlow服务器:
docker pull infiniflow/ragflow:latest
docker compose up ragflow -d
4)如果使用docker compose -f docker-compose-CN.yml up -d启动RAGFlow服务器:
docker pull swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow:latest
docker compose -f docker-compose-CN.yml up -d
2024-08-28(三)





![P7910[CSP-J2021]插入排序](https://i-blog.csdnimg.cn/direct/5c83867118744ea5965809c54c9882bc.png)