- 💡统一使用 YOLOv7 代码框架,结合不同模块来构建不同的YOLO目标检测模型。
- 🌟本项目包含大量的改进方式,降低改进难度,改进点包含
【Backbone特征主干】、【Neck特征融合】、【Head检测头】、【注意力机制】、【IoU损失函数】、【NMS】、【Loss计算方式】、【自注意力机制】、【数据增强部分】、【标签分配策略】、【激活函数】等各个部分
文章目录
- 一、SPD论文理论部分
- 网络架构
- 模块结构
- 二、将其应用到YOLOv7中
- YOLOv7网络配置文件
- 核心代码
- 其他配置
- 三、YOLOv5配置
- YOLOv5添加SPD.yaml配置文件
- 核心代码
在这篇文章中,将SPD结构加入到 YOLOv7结构中
一、SPD论文理论部分
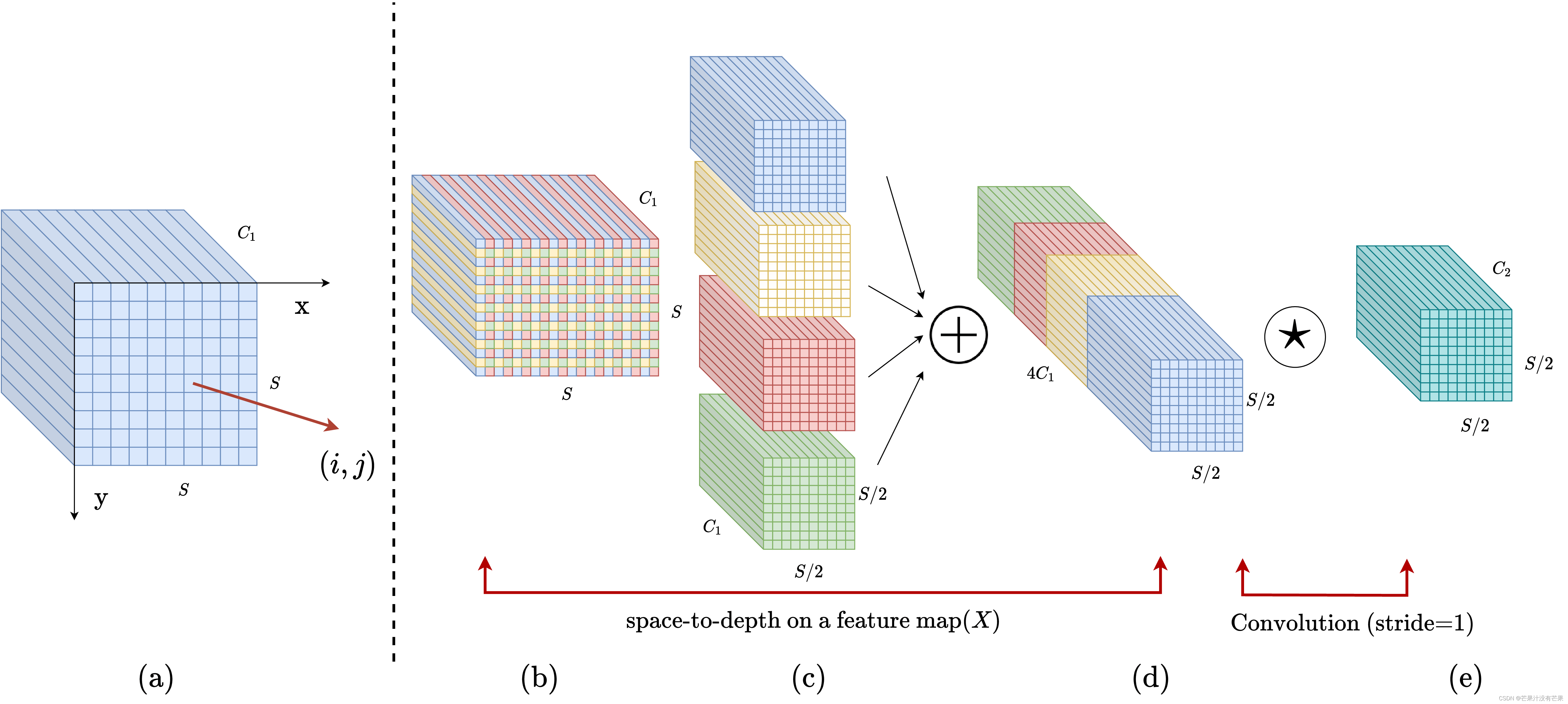
卷积神经网络 (CNN) 在许多计算机视觉任务(例如图像分类和对象检测)中取得了巨大成功。然而,它们的性能在图像分辨率低或物体很小的更艰巨的任务中迅速下降。在本文中,我们指出,这源于现有 CNN 架构中存在缺陷但常见的设计,即使用跨步卷积和/或池化层,这会导致细粒度信息的丢失和对不太有效的特征表示的学习. 为此,我们提出了一个名为SPD-Conv的新 CNN 构建块来代替每个跨步卷积层和每个池化层(因此完全消除了它们)。SPD-Conv 由空间到深度(SPD) 层后跟非跨步卷积 (Conv) 层,可以应用于大多数(如果不是全部)CNN 架构。我们在两个最具代表性的计算机视觉任务下解释了这种新设计:对象检测和图像分类。然后,我们通过将 SPD-Conv 应用于 YOLOv5 和 ResNet 来创建新的 CNN 架构,并通过经验证明我们的方法明显优于最先进的深度学习模型,尤其是在具有低分辨率图像和小物体的更艰巨任务上。

网络架构
YOLO 是一系列非常流行的目标检测模型,其中我们选择了最新的 YOLOv5 [14]来演示。YOLOv5 使用 CSPDarknet53 [4]带有 SPP [12]模块作为其主干,PANet [23]作为它的脖子,和 YOLOv3 的头部 [26]作为其检测头。此外,它还使用了来自 YOLOv4 的各种数据增强方法和一些模块 [4]用于性能优化。它使用带有 sigmoid 层的交叉熵损失来计算对象性和分类损失,以及 CIoU 损失函数 [38]用于定位损失。CIoU 损失比 IoU 损失考虑更多细节,例如边缘重叠、中心距离和宽高比。
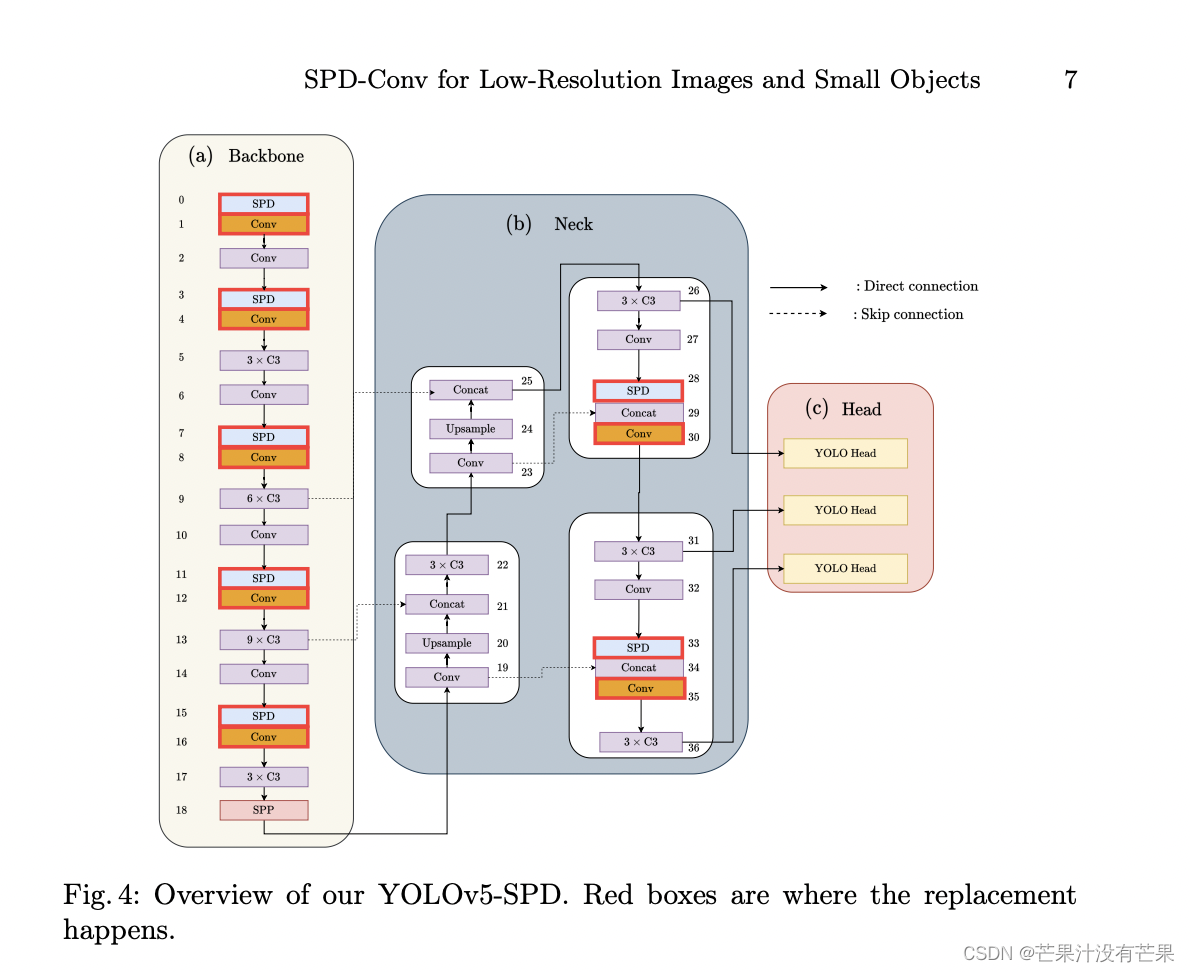
模块结构

二、将其应用到YOLOv7中
YOLOv7网络配置文件
增加以下yolov7_spd.yaml文件
代码演示
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[-1,1,space_to_depth,[1]], # 2 -P2/4
[-1, 1, Conv, [512, 1, 1]], # 103
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[103, 1, RepConv, [1024, 3, 1]],
[[104,105,106], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
核心代码
./models/common.py文件增加以下模块
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
其他配置
不需要
三、YOLOv5配置
YOLOv5添加SPD.yaml配置文件
增加以下yolov5_spd.yaml文件
# Parameters
nc: 80 # number of classes
depth_multiple: 1 # model depth multiple
width_multiple: 1 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 1]], # 1
[-1,1,space_to_depth,[1]], # 2 -P2/4
[-1, 3, C3, [128]], # 3
[-1, 1, Conv, [256, 3, 1]], # 4
[-1,1,space_to_depth,[1]], # 5 -P3/8
[-1, 6, C3, [256]], # 6
[-1, 1, Conv, [512, 3, 1]], # 7-P4/16
[-1,1,space_to_depth,[1]], # 8 -P4/16
[-1, 9, C3, [512]], # 9
[-1, 1, Conv, [1024, 3, 1]], # 10-P5/32
[-1,1,space_to_depth,[1]], # 11 -P5/32
[-1, 3, C3, [1024]], # 12
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 14
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15
[[-1, 9], 1, Concat, [1]], # 16 cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]], # 18
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 19
[[-1, 6], 1, Concat, [1]], # 20 cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 1]], # 22
[-1,1,space_to_depth,[1]], # 23 -P2/4
[[-1, 18], 1, Concat, [1]], # 24 cat head P4
[-1, 3, C3, [512, False]], # 25 (P4/16-medium)
[-1, 1, Conv, [512, 3, 1]], # 26
[-1,1,space_to_depth,[1]], # 27 -P2/4
[[-1, 14], 1, Concat, [1]], # 28 cat head P5
[-1, 3, C3, [1024, False]], # 29 (P5/32-large)
[[21, 25, 29], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
核心代码
./models/common.py文件增加以下模块
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)