⭐️ 变量常量与基本数据类型及数据类型转换
📍 来自:中南林业科技大学软件协会学术部:谢添
⏲ 时间:2022 - 10 - 29 至 2022 - 10 - 30
🏠 官网:https://www.csuftsap.cn/
✏️ 本章所有提供代码均已测试,读万卷书不如行万里路,一定要把代码都自己敲一遍并测试
💬 如果这个世界真有奇迹,那也只是努力的另外一个名字,据说,每个降临到这个世界的人都自带粮草和地图,会迷途都是因为陷在眼前的一亩三分地,那些去看世界的人脚下一直有远方。

【在本篇文章中,你会学习到的内容如下】
1.数据在内存中的存储(二进制形式存储)
关于进制、原码反码补码、存储单位的具体,查看文章:https://blog.csdn.net/qq_62982856/article/details/126052638?spm=1001.2014.3001.5501
计算机要处理的信息是多种多样的,如数字、文字、符号、图形、音频、视频等,这些信息在人们的眼里是不同的。但对于计算机来说,它们在内存中都是一样的,都是以二进制的形式来表示。
📍 存储单位的 bit 和 byte
1️⃣ bit(比特)
大名鼎鼎的比特币就是以此命名的。。
bit 是计算机内存中的最小单位(也称原子单位),它的简写为小写字母 “b” 。
电脑是以二进制存储以及发送接收数据的。二进制的一位,就叫做 1 bit。也就是说 bit 的含义就是二进制数中的一个数位,即 0或者 1。
2️⃣ byte(字节)
byte 是计算机系统中最小的存储单位,它的简写为大写字母 “B"。
字节 Byte 和比特 bit 的换算关系是 1 Byte = 8 bit 。
存储单位和网速的单位,不管是 B 还是 b,代表的都是字节 Byte。
带宽的单位,不管是 B 还是 b,代表的都是比特 bit。
2.基本数据类型简介
2.1 C语言数据类型参考

2.2 为什么需要数据类型
C语言为什么要引入这么多的数据类型呢?因为C语言归根结底只是一门编程语言,一种让计算机为我们做事情的工具。引入这么多的数据类型是为了更加方便的表现现实世界中事物。C语言提供的多种数据类型让程序更加灵活和高效,同时也增加了学习成本。
首先我们看数据类型在内存中的表示,我们知道0 和 1 作为信息的载体,数据都是以二进制的形式存放在内存中。二进制的数据本身是没有意义的,如果我们要使得二进制数据有意义,必须人为的加上数据类型。
📝 比如说(4个字节,32位):
00000000 00000001 00000000 00000001
如果没有数据类型,它只是数据,0和1是信息的载体,它们具体是什么含义,我们并不知道。当我们把类型加上以后,就很明显的知道了具体含义。
类型是对内存数据施加的约束:
- 约束一:要把要把几个字节或几个存储单元看成一个整体进行解析。
- 如果上述二进制我们用整型
int类型来识别它,那我们把这四个字节作为一个整体进行解析。 - 如果我们用短整型
short类型来识别它,我们把两个字节作为一个整体进行解析。 - 如果我们用字符型
char类型来识别它,我们把一个字节作为一个整体进行解析。
- 如果上述二进制我们用整型
- 约束二:是对二进制的解析方式不同。同样是4个字节,按照int和float类型解释得到完全不同的值。
- 约束三:类型约束了数据参与运算操作的集合,即我们的数据能够参与哪些运行,或者说类型告诉了编译器如何解释这个数值以及这个数值能够参与到哪些运算中。 比如说int类型的数据可以参与位运算,但如果你定义了一个数据的类型为double,该数据是不可以参与位运算的。
📍 由于类型的约束,使得计算机能够清晰的理解我们程序员的意图,就是说在我们编程的时候, 我们告诉了编译器此数据类型的数据采取什么样子的指令去参与运算,计算机就根据程序员所定义的类型来进行运算。数据类型用来说明数据的类型,确定了数据的解释方式,让计算机和程序员不会产生歧义。
💬 类型开辟内存空间的大小,大小决定了使用范围。
- Java、C++、C#等在定义变量时也必须指明数据类型,这样的编程语言称为强类型语言。
- 而PHP、JavaScript等在定义变量时不必指明数据类型,编译系统会自动推演,这样的编程语言称为弱类型语言。
那C语言是强类型还是弱类型语言呢?有人说强类型,也有人说是弱类型,其实争论这个本身没有意义。我们关注如何正确、安全的使用类型变量,避免隐式类型提升和转换才是正道。
3.整型
3.1 字节大小(长度)与取值范围
sizeof 操作符:用来获取某个数据类型或变量所占用的字节数。sizeof 是C语言中的操作符,不是函数。
📍 win64环境下的字节大小:
#include<stdio.h>
int main()
{
printf("有符号短整型 short:%lld\n", sizeof(short));
printf("无符号短整型 unsigned short:%lld\n", sizeof(unsigned short));
printf("--------------------------------------------------\n");
printf("有符号整型 int:%lld\n", sizeof(int));
printf("无符号整型 unsigned int:%lld\n", sizeof(unsigned int));
printf("--------------------------------------------------\n");
printf("有符号长整型 long int:%lld\n", sizeof(long));
printf("无符号长整型 unsigned long int:%lld\n", sizeof(unsigned long));
printf("--------------------------------------------------\n");
printf("有符号长长整型 long long int:%lld\n", sizeof(long long));
printf("无符号长长整型 unsigned long long int:%lld\n", sizeof(unsigned long long));
return 0;
}

📍 win32环境下的字节大小:
#include<stdio.h>
int main()
{
printf("有符号短整型 short:%ld\n", sizeof(short));
printf("无符号短整型 unsigned short:%ld\n", sizeof(unsigned short));
printf("--------------------------------------------------\n");
printf("有符号整型 int:%ld\n", sizeof(int));
printf("无符号整型 unsigned int:%ld\n", sizeof(unsigned int));
printf("--------------------------------------------------\n");
printf("有符号长整型 long int:%ld\n", sizeof(long));
printf("无符号长整型 unsigned long int:%ld\n", sizeof(unsigned long));
printf("--------------------------------------------------\n");
printf("有符号长长整型 long long int:%ld\n", sizeof(long long));
printf("无符号长长整型 unsigned long long int:%ld\n", sizeof(unsigned long long));
return 0;
}
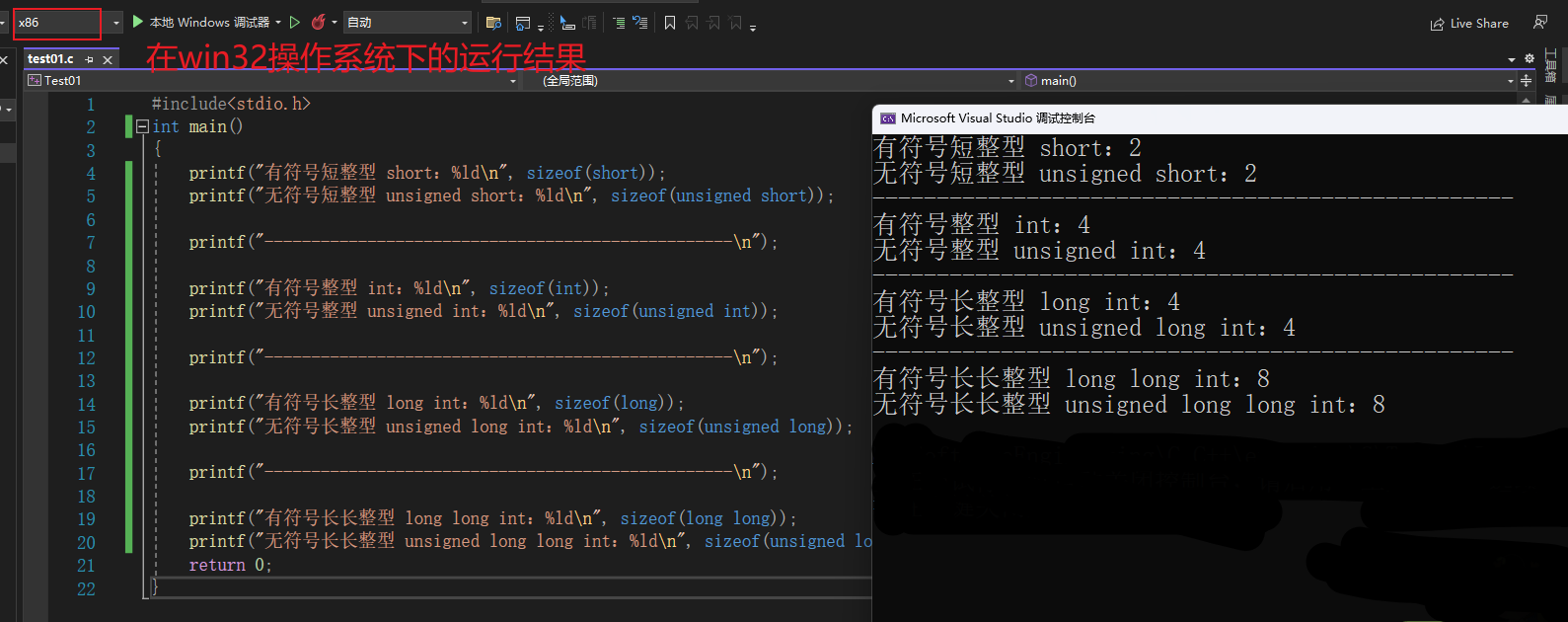
这里就说明了在32 位环境以及 Win64 环境下整型数据类型的所占字节大小是相同的,但是在其它操作系统下计算出的字节大小就可能有所不同,因此使用的时候要注意移植性。
🚩 总结(windows中)
| 数据类型 | 字节大小 | 取值范围 |
|---|---|---|
| short | 2字节 | -32768~32767 |
| unsigned short | 2字节 | 0~65535 |
| int | 4字节 | -2147483648~2147483647 |
| unsigned int | 4字节 | 0~4294967295 |
| long | 4字节 | -2147483648~2147483647 |
| unsigned long | 4字节 | 0~4294967295 |
| long long | 8字节 | 9,223,372,036,854,775,808~9,223,372,036,854,775,807 |
| unsigned long long | 8字节 | 0~18,446,744,073,709,551,616 |
unsigned 是无符号的意思,我们以 short 和 short int 来说明,short 就是有符号数,unsigned short 是 无符号数,但它们占的字节是相同的,则能表示的数的个数也是一致的,short 从 -32768~32767 一共 65536 个整数,unsigned 从 0 ~ 65535 不也是 65536 个整数吗
3.2 整型对应占位符
#include<stdio.h>
int main()
{
short int a = -520;
unsigned short int ua = 520;
printf("有符号短整型 a = %hd\n", a);
printf("无符号短整型 ua = %hu\n\n", ua);
int b = -1314;
unsigned int ub = 1314;
printf("有符号整 型 b = %d\n", b);
printf("无符号整 型 ub = %u\n\n", ub);
long int c = -201314;
unsigned long int uc = 201314;
printf("有符号长整型 c = %ld\n", c);
printf("无符号长整型 uc = %lu\n\n", uc);
long long int d = -5201314;
unsigned long long int ud = 5201314;
printf("有符号长长整型 d = %lld\n", d);
printf("无符号长长整型 ud = %llu\n", ud);
return 0;
}

🚩 总结
| 数据类型 | 占位符 |
|---|---|
| short | %hd |
| unsigned short | %hu |
| int | %d |
| unsigned int | %u |
| long | %ld |
| unsigned long | %lu |
| long long | %lld |
| unsigned long long | %llu |
4.浮点型
4.1 字节大小(长度)与取值范围
浮点数没有无符号数。
int main()
{
printf("单精度浮点数 float:%lld\n\n", sizeof(float));
printf("双精度浮点数 double:%lld\n\n", sizeof(double));
printf("长双精度浮点数 long double:%lld\n\n", sizeof(long double));
return 0;
}

🚩 总结
| 数据类型 | 存储大小 | 值范围 | 精度 |
|---|---|---|---|
| float | 4字节 | 1.2E-38 到 3.4E+38 | 6 位有效位 |
| double | 8 字节 | 2.3E-308 到 1.7E+308 | 15 位有效位 |
| long double | 16 字节 | 3.4E-4932 到 1.1E+4932 | 19 位有效位 |
4.2 浮点数的两种形式
4.2.1 十进制小数形式
📝 合法的浮点数形式举例:
double a = 520.1314; //输出520.131400
double b = 520.; //输出520.000000
double c = 520.0; //输出520.000000
double d = -0.1314; //输出 -0.131400
double e = .1314; //输出 0.131400
4.3.2 指数形式(科学计数法)
C 语⾔允许使⽤科学计数法表示浮点数,使⽤字⺟ e/E 来分隔⼩数部分和指数部分。
- 比如 13.14e+2就等价于 13.14 ∗ 1 0 2 13.14*10^2 13.14∗102 ,即 1314
- 比如 13.14e-2就等价于 13.14 ∗ 1 0 − 2 13.14*10^{-2} 13.14∗10−2 ,即 0.1314
📍 注意事项和细节说明:
- e/E 后面的指数必须为整数。
- e/E 后⾯如果是加号 + ,加号可以省略。
- 科学计数法⾥⾯ e/E 的前后,不能存在空格。
📝 合法的浮点数形式举例:
double a = 520.13e+2; //输出 52013.000000
double b = 520.e+3; //输出 520000.000000
double c = 520.0e-2; //输出 5.200000
double d = .1314e4; //输出 1314.000000
4.3 浮点型对应占位符
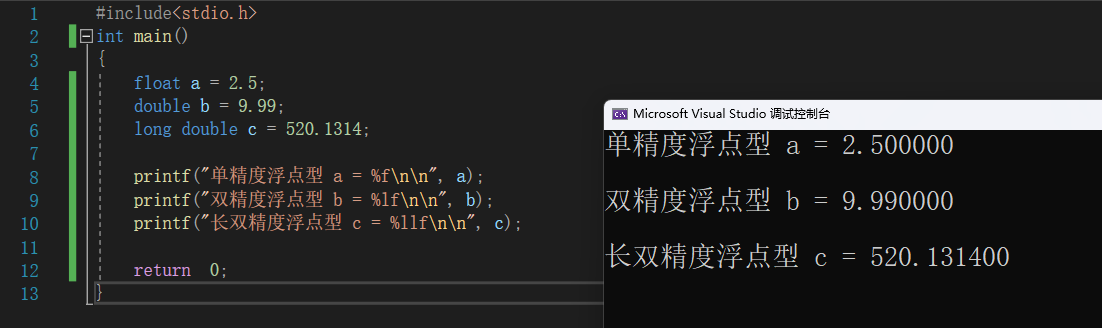
#include<stdio.h>
int main()
{
float a = 2.5;
double b = 9.99;
long double c = 520.1314;
printf("单精度浮点型 a = %f\n\n", a);
printf("双精度浮点型 b = %lf\n\n", b);
printf("长双精度浮点型 c = %llf\n\n", c);
return 0;
}
🚩 总结
| 数据类型 | 形式 | 占位符 |
|---|---|---|
| float | 十进制 | %f |
| double | 十进制 | %lf |
| long double | 十进制 | %llf |
| float | 指数形式 | %e 或 %E |
| double | 指数形式 | %le 或 %lE |
| long double | 指数形式 | %lle 或 %llE |
4.4 注意事项和细节说明
在实际开发中,我们都不会选用单精度浮点数float,因为该类型很容易导致精度丢失,导致计算错误。我们通常会采用精度更高的double类型。
📝 我们来看一个浮点数精度不准确造成的问题:
#include<stdio.h>
int main()
{
double a = 0.1;
double b = 0.2;
if (a + b == 0.3)
printf("精度未丢失");
else
printf("精度丢失,a + b = %lf",a + b);
return 0;
}
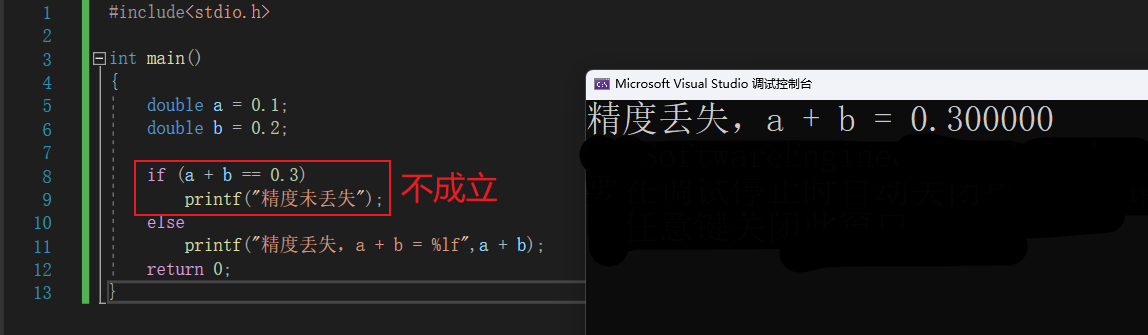
是不是就很匪夷所思,这是因为由于底层存储小数不准确问题导致在计算时 a+b 的结果其实是无限接近于0.3的,但不等于0.3,因此 a+b == 0.3 为 假(false)。
❓ 你是不是不相信我说的话呀?因为你发现 在上图的输出中 的确输出的是 0.300000 呀,但其实呀,有这样一件事我需要和你说清楚,一个女孩说对你有好感❤️ ,可你却以为她是在说喜欢你,可是这是真的吗,其实你并未看到全部,只是你的自作多情和一厢情愿罢了。这里也是一样的道理,我们在打印数据的时候默认只打印到了小数点后六位,我们修改一下打印位数:
#include<stdio.h>
int main()
{
double a = 0.1;
double b = 0.2;
if (a + b == 0.3)
printf("精度未丢失");
else
//我们这里是 .32lf 即打印到小数点后32位
printf("精度丢失,a + b = %.32lf", a + b);
return 0;
}

但是这个问题我们能够怎样解决呢?这里提供一种方式:
#include<stdio.h>
int main()
{
double a = 0.1;
double b = 0.2;
if (a + b - 0.3 < 0.000001)
printf("精度未丢失");
else
//我们这里是 .32lf 即打印到小数点后32位
printf("精度丢失,a + b = %.32lf", a + b);
return 0;
}

5.字符型
5.1 基本使用说明
- 字符常量使用单引号
' '括起来的单个字符。 - C还允许使用转义字符
\来将其后的字符转变为特殊字符型常量。
5.2 字节大小
#include<stdio.h>
int main()
{
printf("有符号字符型的字节大小:%lld\n", sizeof(char));
printf("无符号字符型的字节大小:%lld\n", sizeof(unsigned char));
return 0;
}
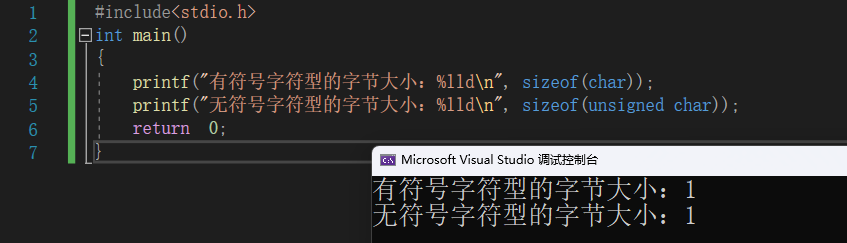
🚩 总结
| 数据类型 | 字节大小 |
|---|---|
| char | 1 |
| unsigned char | 1 |
5.3 字符型对应占位符
| 数据类型 | 占位符 |
|---|---|
| char | %c |
| unsigned char | %c |
5.4 char的本质
关于更加具体的字符编码说明,查看文章:https://blog.csdn.net/qq_62982856/article/details/127440216?spm=1001.2014.3001.5502
- 计算机在存储字符时并不是真的要存储字符实体,而是存储该字符在字符集中的编号(也可以叫编码值)。对于 char 类型来说,它实际上存储的就是字符的 ASCII 码。
- 无论在哪个字符集中,字符编号都是一个整数;从这个角度考虑,字符类型和整数类型本质上没有什么区别。
- 我们可以给字符类型赋值一个整数,或者以整数的形式输出字符类型。反过来,也可以给整数类型赋值一个字符,或者以字符的形式输出整数类型。
char的本质是一个整数,在输出时,是 ASCII码表中对应的字符。

-
因此,可以直接给char赋一个
整型数据,然后输出时,会按照该整数对应的ASCII字符输出。#include<stdio.h> int main() { int b = 65; char a = b; //因为左边接收类型是 char,整数65对应的ASCII字符是 'A',因此 a 被赋值为 'A' printf("%c\n", a); // %c --> 以ASCII字符形式输出 printf("%d\n\n", a); // %d --> 以ASCII值形式输出 char d = 'D'; printf("%c\n", d); printf("%d\n\n", d); return 0; }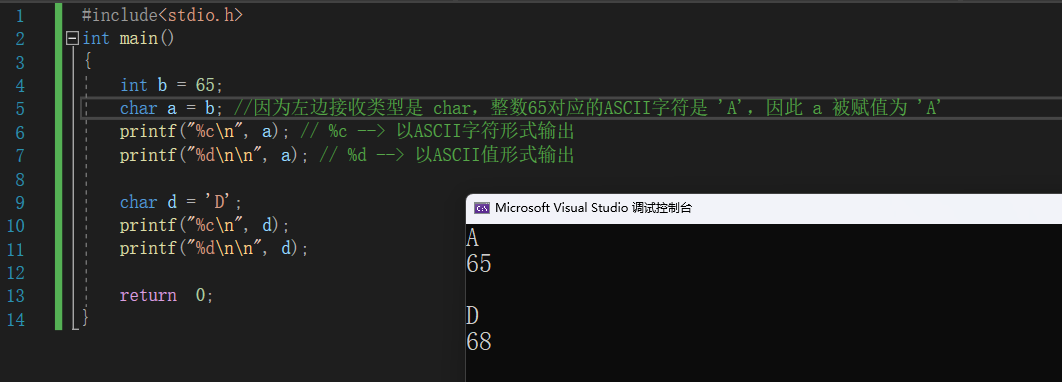
-
char类型是可以进行运算的,相当于一个整数(对应规则来自ASCII表)
#include<stdio.h> int main() { char a = 'A'; char b = a + 1;//'A'对应整数 65,因此 a+1 为66,接收类型为 char,整数66对应的ASCII字符为 'B',因此 b 为 'B' int c = a + 1; //'A'对应整数 65,因此 a+1 为66,接受类型为 int,因此 c 为 66 printf("%d\n", b); // %d --> 以ASCII值形式输出 printf("%c\n\n", b); // %c --> 以ASCII字符形式输出 printf("%d\n", c); printf("%c\n\n", c); return 0; }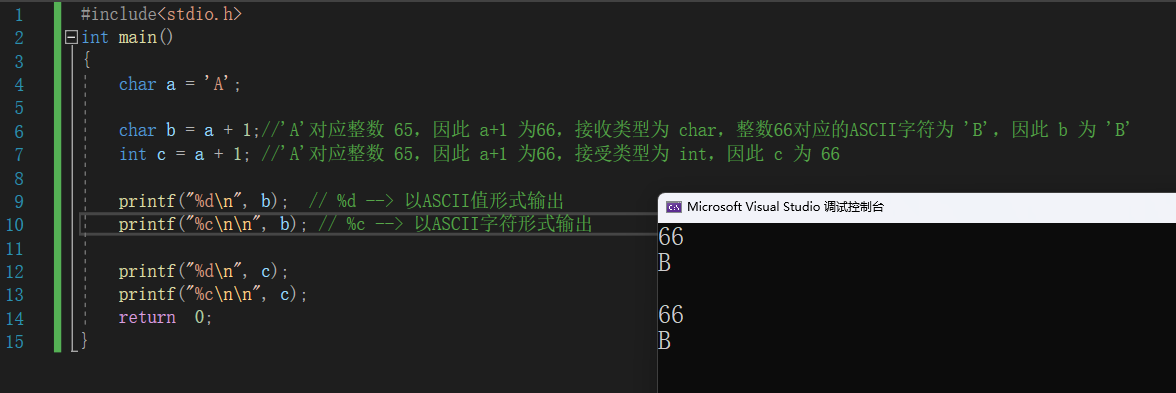
6.补充:布尔类型 bool
6.1 C89标准
C 语言标准 C89 没有定义布尔类型,所以 C 语言判断真假时以 0 为假(false),非 0 为真(true)
#include<stdio.h>
int main()
{
int a = -1;
if (a) // -1 是非0数,因此if语句成立为true
printf("非0为真\n\n");
if (a + 1) // a+1的结果为0,因为0为假,所以if语句不成立为false
printf("输出1:0为假\n\n");
else //因此执行 else语句
printf("输出2: 0为假\n\n");
if (a + 1 == 0) // a+1为0,则0==0说明if语句成立为true
printf("a+1为0成立\n\n");
int b = 0;
if (!b) // b是0,为false,!是取反操作,即false变true
printf("取反为true输出\n\n");
return 0;
}

6.2 C99标准
C 语言标准C99提供了_Bool 型,_Bool 仍是整数类型,但与一般整型不同的是,_Bool 变量只能赋值为 0 或 1,非 0 的值都会被存储为 1,C99 还提供了一个头文件 <stdbool.h> 定义了 bool 代表_Bool,true 代表 1,false 代表 0。只要导入 stdbool.h ,就能方便的操作布尔类型了。
📝 下述代码说明 bool类型 用法:
#include<stdio.h>
#include<stdbool.h>
int main()
{
//bool类型所占字节大小
printf("bool类型所占字节大小:%lld\n\n", sizeof(bool));
// false对应整数
bool a = false;
printf("false对应整数:%d\n\n", a); //输出说明 false 对应 0
//true对应整数
bool b = true;
printf("true对应整数:%d\n\n", b); //输出说明 true 对应 1
if (true)
printf("我曾经很爱很爱你,但再也不会去找你了,夜莺\n\n");
if (!false)//false取反为true
printf("爱一个人,九分喜欢,一分尊严\n\n");
return 0;
}

7.变量与常量
7.1 变量
7.1.1 基本概念
变量相当于内存中一个数据存储空间的表示,可以把变量看做是一个房间的门牌号,通过门牌号可以找到房间,而通过变量名就可以访问到变量值。
7.1.2 三个基本要素:类型 变量名 变量值
不论是使用哪种高级程序语言编写程序,变量都是其程序的基本组成单位。
/*
类型:int
变量名:a
变量值:100
*/
int a = 100;
7.1.3 变量的声明与定义
声明是用来告诉编译器变量的名称和类型,而不分配内存。定义是为了给变量分配内存,可以为变量赋初值。
#include<stdio.h>
int main()
{
int a; //变量声明,未分配内存空间
a = 520; //变量定义,分配内存空间
int b = 1314; //变量声明并定义(也叫 初始化)
return 0;
}
7.1.4 变量使用注意事项
- 变量表示内存中的一个存储区域。不同的变量,类型不同,占用的空间大小也可能不同。
- 该区域有自己的名称(变量名)和类型(数据类型)
- 变量必须先声明,再定义使用。
- 该区域的数据值可以在
同一类型取值范围内不断变化。 - 变量在同一作用域内不能重名。
- 变量 = 数据类型 + 变量名 + 变量值
- 数据类型只在定义变量时指明,而且必须指明;使用变量时无需再指明,因为此时的数据类型已经确定了。
7.2 常量
7.2.1 基本概念
- 常量是固定值,在程序执行期间不能改变。这些固定的值,又叫做字面量。
- 常量可以是任何的基本数据类型,比如整数常量、浮点常量、字符常量,或字符串字面值,也有枚举常量。
- 常量的值在定义后不能进行修改
7.2.2 常量举例
//100就是常量
int a = 100;
// 13.14就是常量
double b = 13.14;
// A就是常量
char c = 'A';
7.2.3 define定义常量
凡是以 # 开头的均为预处理指令,预处理又叫预编译。预编译不是编译,而是编译前的处理。这个操作是在正式编译之前由系统自动完成的。
📍 C 语言中,可以用 #define 定义一个标识符来表示一个常量,用 #define 定义标识符的一般形式为:
#define 标识符 常量值 //注意define最后没有分号
//例如:
#define MAX_VALUE 100 //定义整型变量MAX_VALUE值为100
#define USER_NAME "huge" //定义字符串变量USER_NAME值为"huge"
#define PI 3.1415926 //定义浮点数变量PI值为3.1415926
📝 举例说明:计算半径为2的圆的面积
#include<stdio.h>
//定义一个常量PI,值为3.14
#define PI 3.14
int main()
{
int r = 2;
printf("S = %lf", PI * r * r);
return 0;
}
7.2.4 const定义常量
关键字const用来定义常量,如果一个变量被const修饰,那么它的值就不能再被改变,我想一定有人有这样的疑问,C语言中不是有#define吗,干嘛还要用const呢,我想事物的存在一定有它自己的道理,所以说const的存在一定有它的合理性,与预编译指令相比,const修饰符有以下的优点:
- 预编译指令只是对值进行简单的替换,不能进行类型检查
- 可以保护被修饰的东西,防止意外修改,增强程序的健壮性
- 编译器通常不为普通const常量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的常量,没有了存储与读内存的操作,使得它的效率也很高。
📍 基本语法:
const 数据类型 常量名 = 常量值;
📝 举例说明:计算半径为2的圆的周长
#include<stdio.h>
//定义全局常量 PI,值为3.14
const double PI = 3.14;
int main()
{
//定义局部常量 r ,值为2
const int r = 2;
printf("C = %lf", 2 * PI * r);
return 0;
}
7.2.5 补充:#define与const区别
- const定义的常量时带类型,#define不带类型。
- const是在编译、运行的时候起作用,而define是在编译的预处理阶段起作用。
- #define 只是简单的替换,没有类型检查。简单的字符串替换会导致边界效应。
- const常量可以进行调试的,#define是不能进行调试的,主要是预编译阶段就已经替换掉了,调试的时候就没它了。
- const不能重定义, 不可以定义两个一样的,而#define通 过
undef取消某个符号的定义,再重新定义。 - #define 可以配合
#ifdef、#ifndef、#endif来使用,可 以让代码更加灵活,比如我们可以通过#define来启动或者关闭调试信息。
7.2.6 注意事项和细节说明
-
常量不能作为左值。例如:
// 常量100作为右值,是可以的 int a = 100; // 常量100作为左值,是不可以的,会报错 100 = 20; //将20赋值给100,很明显是一个荒谬的行为 -
常量一旦确定,就无法更改。
const int a = 520; a = 1314; //由于有关键字const修饰,a是常量,因此直接把1314赋值给a会报错。学到了指针小伙伴可能会提出不同的意见,即使定义为常量,也可以通过指针修改值。
但你必须思考这样一件事情:为什么要定义常量?不就是告诉自己与其他程序员不要去修改这个值吗?只需要将它作为一个常量看待即可。这才是常量存在的意义,是const存在的意义,因此,如果你将一个变量用const修饰,又用指针去修改它,这本身就是一个荒谬的事情!
-
常量必须一开始就赋值,即声明时完成初始化。
//声明并初始化是可以的 const int a = 520; //先声明,后复制是不可以的,如下代码是错误的 const int b; b = 1314;
8.数据类型转换
数据类型转换就是将数据(变量、数值、表达式的结果等)从一种类型转换为另一种类型。
8.1 自动类型转换
自动类型转换就是编译器默默地、隐式地、偷偷地进行的数据类型转换,这种转换不需要程序员干预,会自动发生。
在赋值运算中,赋值号两边的数据类型不同时,需要把右边表达式的类型转换为左边变量的类型,这可能会导致数据失真,或者精度降低;所以说,自动类型转换并不一定是安全的。对于不安全的类型转换,编译器一般会给出警告。
// 520是int类型常数,因此这里进行了自动类型转换,将int类型的520变成了float类型的520.000000
float a =520;
📍 自动类型转换规则如下:
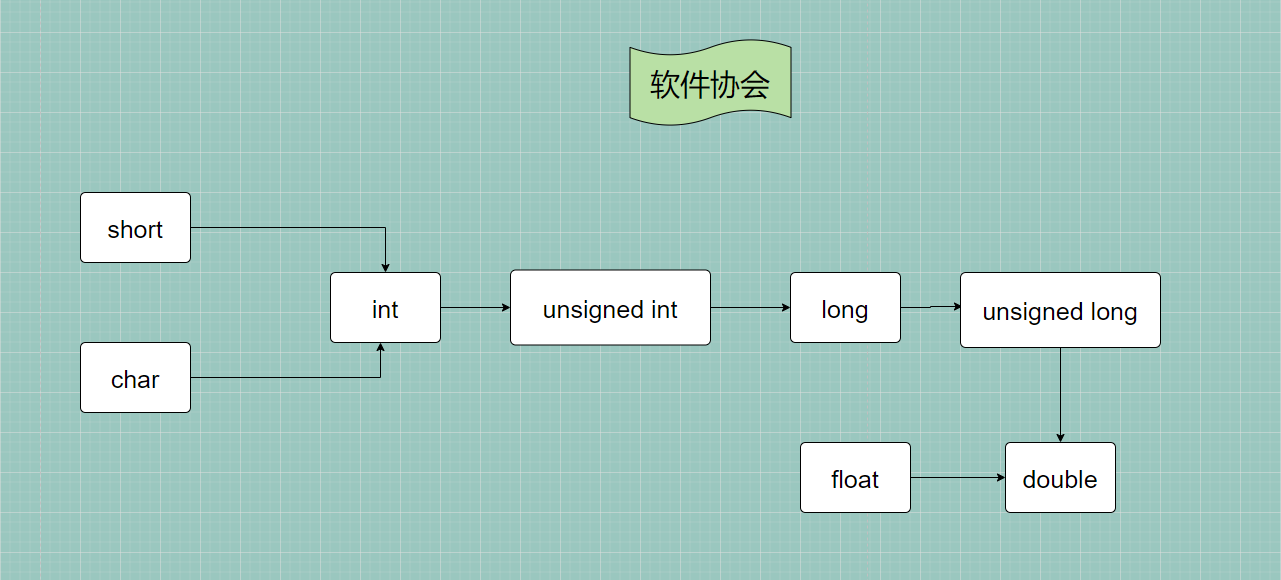
-
参与运算的类型不同,则先转换为同一类型。
int r = 2; double pi = 3.14; /* 1.在计算 pi * r * r时,会先将这三个变量值转换为数据类型一致的值 2.pi为double,r为int,根据上图可以得到double的精度更高 3.因此 r 的变量值2也会先转成double类型的2.000000,再进行计算 4.所以 3.140000 * 2.000000 * 2.000000 得到12.560000 5.但接收类型为int,因此会舍去小数部分,则s为12 */ int s = pi * r * r; -
两种类型字节数不同,转换为高字节数的类型
-
转换按数据长度增加的方向进行,以保证精度不降低。如int型和double型运算时,先把int量转成double型后再进行运算。
/* 1. 在运算9.4 / 2前 2. 发现9.4是double类型(默认),2是int类型 3. 根据自动转换规则,将int类型的2转成double类型的2.000000 4. 因此运算的结果为 4.700000 5. 又发现了接收类型为Int,因此舍去小数部分得到 a 为 4 */ int a = 9.4 / 2; -
若两种类型的字节数相同,且一种有符号,一种无符号,则转换成无符号类型。因此,从这个意义上讲,无符号数的运算优先级要高于有符号数,这一点对于应当频繁用到无符号数据类型的嵌入式系统来说是丰常重要的。
-
所有的浮点运算都是以双精度进行的,即使仅含float单精度量运算的表达式,也要先转换成double型,再作运算。
-
char型和short型参与运算时,必须先转换成int型
char a = 'A'; char b = 'B'; /* 1.运算 a+b 前,发现a和b是字符型,因此先转为int类型 2.'A' --> 65 'B' --> 66 3.所以 a+b 的结果为 131 4.发现 c 是 char类型,因此又会自动转为131对应的ASCII字符为【问号?】 */ char c = a + b; short d = 1; /* 1.运算 d+a 前,发现d是short,a是char 2.因此将这两个都转成int类型 3.short类型的1转成int类型的1,char类型的a转成int类型的65 4.所以 d+a 即计算 1+65 --> 为int类型的66 5.发现接收类型是e,所以e为66,不需要类型转换了 */ int e = d + a;
8.2 强制类型转换
自动类型转换是编译器根据代码的上下文环境自行判断的结果,有时候并不是那么“智能”,不能满足所有的需求。如果需要,程序员也可以自己在代码中明确地提出要进行类型转换,这称为强制类型转换。
- 自动类型转换是编译器默默地、隐式地进行的一种类型转换,不需要在代码中体现出来;
- 强制类型转换是程序员明确提出的、需要通过特定格式的代码来指明的一种类型转换。
换句话说,自动类型转换不需要程序员干预,强制类型转换必须有程序员干预。
📍 强制类型转换的格式为:(type_name) expression 。type_name为新类型名称,expression为表达式。
(float) a; //将变量 a 转换为 float 类型
(int)(x+y); //把表达式 x+y 的结果转换为 int 整型
(float) 100; //将数值 100(默认为int类型)转换为 float 类型
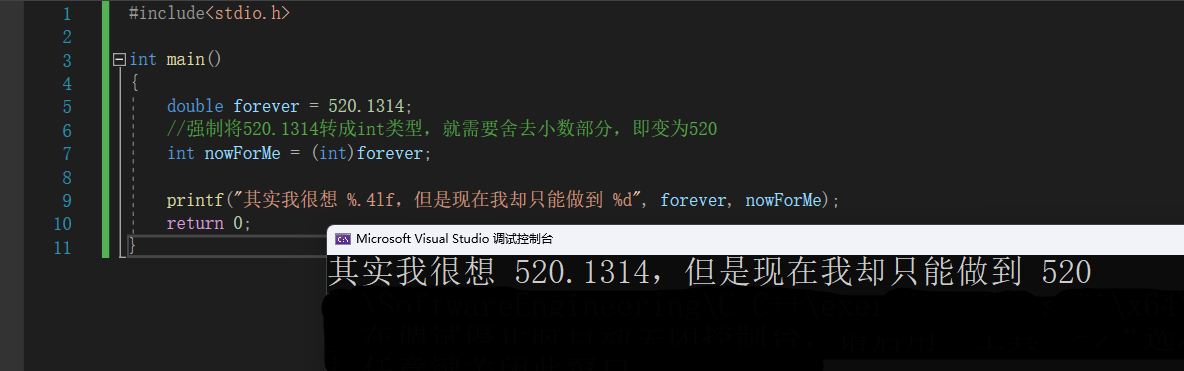
📝 再举一个例子:
#include<stdio.h>
int main()
{
double forever = 520.1314;
//强制将520.1314转成int类型,就需要舍去小数部分,即变为520
int nowForMe = (int)forever;
printf("其实我很想 %.4lf,但是现在我却只能做到 %d", forever, nowForMe);
return 0;
}
8.3 类型转换只是临时性的
无论是自动类型转换还是强制类型转换,都只是为了本次运算而进行的临时性转换,转换的结果也会保存到临时的内存空间,不会改变数据本来的类型或者值。
float a = 13.14;
/*
这里进行了强制类型转换,首先由于()的优先级别高于 * ,因此先进行(int)a 得到该值为13
然后 13 * 10 得到 130,所以 b 为 130
但需要注意:虽然a在运算中转成了int类型,但实际上a依旧为 float 类型
*/
int b = (int)a * 10;
8.4 自动类型转换 VS 强制类型转换
在C语言中,有些类型既可以自动转换,也可以强制转换,例如 int 到 double,float 到 int 等;而有些类型只能强制转换,不能自动转换,例如以后将要学到的 void * 到 int *,int 到 char * 等。
可以自动转换的类型一定能够强制转换,但是,需要强制转换的类型不一定能够自动转换。现在我们学到的数据类型,既可以自动转换,又可以强制转换,以后我们还会学到一些只能强制转换而不能自动转换的类型。
可以自动进行的类型转换一般风险较低,不会对程序带来严重的后果,例如,int 到 double 没有什么缺点,float 到 int 顶多是数值失真。只能强制进行的类型转换一般风险较高,或者行为匪夷所思,例如,char * 到 int * 就是很奇怪的一种转换,这会导致取得的值也很奇怪,再如,int 到 char * 就是风险极高的一种转换,一般会导致程序崩溃。
使用强制类型转换时,程序员自己要意识到潜在的风险。
🔖 小结
💬 最后再啰嗦一句:当格式控制符(占位符)和数据类型不匹配时,编译器会给出警告,提示程序员可能会存在风险。编译器的警告是分等级的,不同程度的风险被划分成了不同的警告等级,而使用%d输出 short 和 long 类型的风险较低,如果你的编译器设置只对较高风险的操作发出警告,那么此处你就看不到警告信息。
💬 遇到任何疑惑请联系软件协会。
🏠 了解更多关注软协官网:https://www.csuftsap.cn/
💚 来自软件协会编辑,注册会员即可获取全部开源.md资源,请勿转载,归软件协会所有。