🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
应用 Viola-Jones AdaBoost 学习和 Haar 级联分类器进行人脸识别
选择类似 Haar 的特征
创建一个完整的图像
运行 AdaBoost 训练
注意级联分类器
训练级联检测器
使用深度神经网络预测面部关键点
为关键点检测准备数据集
处理关键点数据
在输入到 Keras-Python 代码之前进行预处理
Keras–Python 代码中的预处理
定义模型架构
训练模型进行关键点预测
使用 CNN 预测面部表情
3D人脸检测概述
3D重建硬件设计概述
3D 重建和跟踪概述
参数跟踪概述
概括
面部检测是计算机视觉的重要组成部分,是近年来发展迅速的领域。在本章中,您将从 Viola-Jones 面部和关键特征检测的简单概念开始,然后进入基于神经网络的面部关键点和面部表情检测的高级概念。本章将通过介绍 3D 人脸检测的高级概念来结束。
本章将涵盖以下主题:
- 应用 Viola-Jones AdaBoost 学习和 Haar 级联分类器进行人脸识别
- 使用深度神经网络预测面部关键点
- 使用 CNN 预测面部表情
- 3D人脸检测概述
应用 Viola-Jones AdaBoost 学习和 Haar 级联分类器进行人脸识别
2001 年,Microsoft Research 的 Paul Viola 和 Mitsubishi Electric 的 Michael Jones 通过开发称为Haar 级联分类器的分类器开发了一种革命性的检测图像中人脸的方法https://www.face-rec.org/algorithms/Boosting-Ensemble /16981346.pdf。Haar 级联分类器基于 Haar 特征,这些特征是矩形区域中像素值差异的总和。校准差值的大小以指示面部给定区域的特征,例如鼻子、眼睛等。最终的检测器有 38 个级联分类器,具有 6,060 个特征,包括约 4,916 个人脸图像和 9,500 个非人脸图像。总的训练时间是几个月,但检测时间非常快。
首先,将图像从RGB 转换为灰度,然后应用图像过滤和分割,以便分类器可以快速检测到对象。在接下来的部分中,我们将学习如何构建 Haar 级联分类器。
选择类似 Haar 的特征
Haar 级联分类器算法是基于人脸图像在人脸不同区域具有鲜明的强度特征的思想,例如,人脸的眼睛区域比眼睑底部和鼻子区域更暗比它旁边的两个面部区域更亮。类似 Haar 的特征由黑白相邻的矩形表示,如下图所示。在这张图片中,有几个潜在的 Haar 特征(二矩形、三矩形和四矩形特征):

请注意,矩形部分放置在面部的特征上。由于眼睛区域的强度比脸部暗,矩形的黑色区域靠近眼睛,白色区域位于眼睛下方。同样,由于鼻子区域比其周围区域更亮,因此白色矩形位于鼻子上,黑色矩形位于两侧。
创建一个完整的图像
积分图像用于一次性快速计算矩形特征像素值。为了更好地理解积分图像,让我们看一下其计算的以下细分:
- Haar 样特征的值可以计算为白色区域中的像素值之和与黑色区域中的像素值之和之间的差。
- 像素I ( x , y )之和可以表示为当前像素位置i ( x , y )左上方所有像素的值,包括当前像素值,可以表示如下:
![]()
在下图中,I ( x , y )是由九个像素值(62、51、51、111、90、77、90、79和73)组成的最终积分图像值。将所有这些相加得出的值为 684:
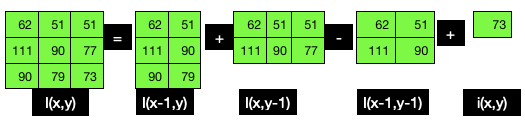
下图是人脸眼睛区域的像素强度和对应的积分图:

如上图所示,矩形区域的像素强度之和是通过将左上角所有像素值相加得到的——例如,917是通过对866求和得到的(即73、79、90之和), 111 ,... 68 , 顺时针) 和10 , 14 , 9和18。请注意,917也可以通过将717相加,然后将50、64、68和 18.
前面的像素方程之和可以改写为:
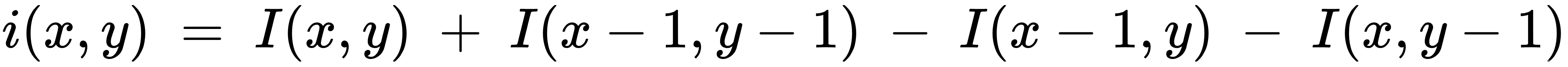
在积分图像中,图像中任何矩形区域的面积可以通过对四个数组求和来计算(如前面的等式所示),而不是对所有单个像素的总和进行六次内存访问。Haar分类器的矩形和可以由上式得到,如下式所示:
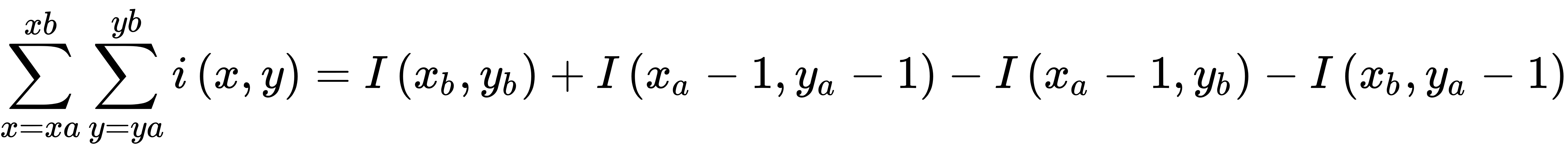
前面的等式可以重新排列如下:
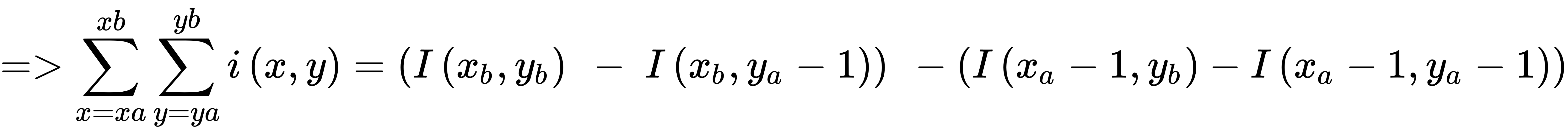
下图显示了转换为整数图像像素值的图像像素值:
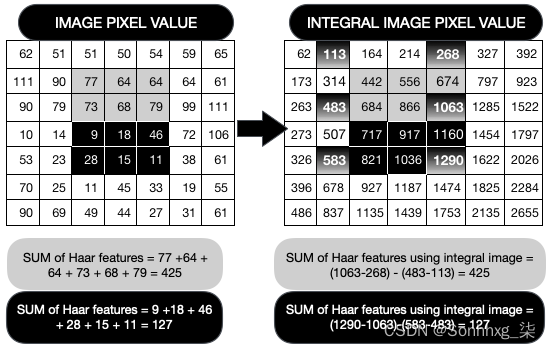
右边的积分图像只是左边像素值的总和——所以 113 = 62 + 51,依此类推。黑色阴影区域像素值表示黑色 Haar 矩形,如前所述。为了计算浅色区域的强度值,我们取积分强度值,例如 1,063 并从中减去 268。
运行 AdaBoost 训练
图像被划分为T个窗口,在这些窗口中应用了 Haar 类特征,并如前所述计算了它们的值。AdaBoost 通过迭代T个窗口的训练集,从大量的弱分类器中构建出一个强分类器。在每次迭代中,弱分类器的权重会根据正样本(人脸)的数量和负样本(非人脸)的数量进行调整,以评估误分类项目的数量。然后,对于下一次迭代,错误分类项目的权重被分配更高的权重,以增加这些被检测到的可能性。最终的强分类器h ( x ) 是弱分类器根据其误差加权的组合。
- 弱分类器:每个弱分类器都有一个特征,f。I t 具有极性p和阈值θ:
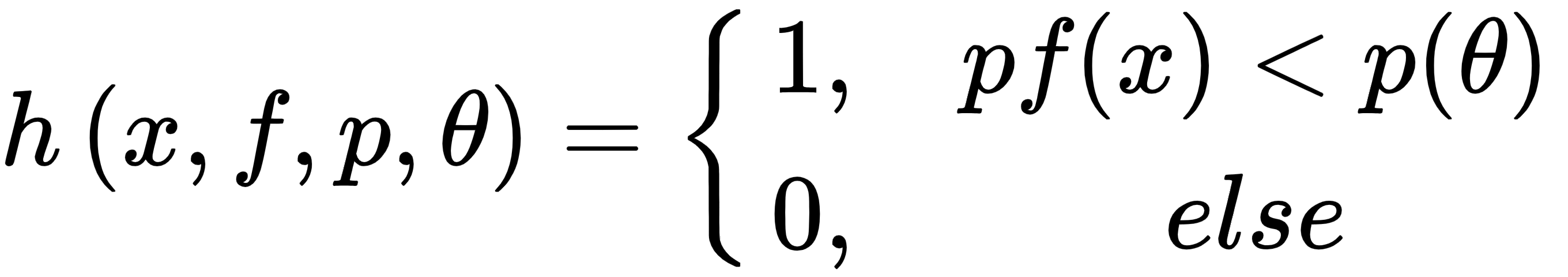
- 强分类器:最终的强分类器h ( x ) 具有最低的误差E t,由下式给出:
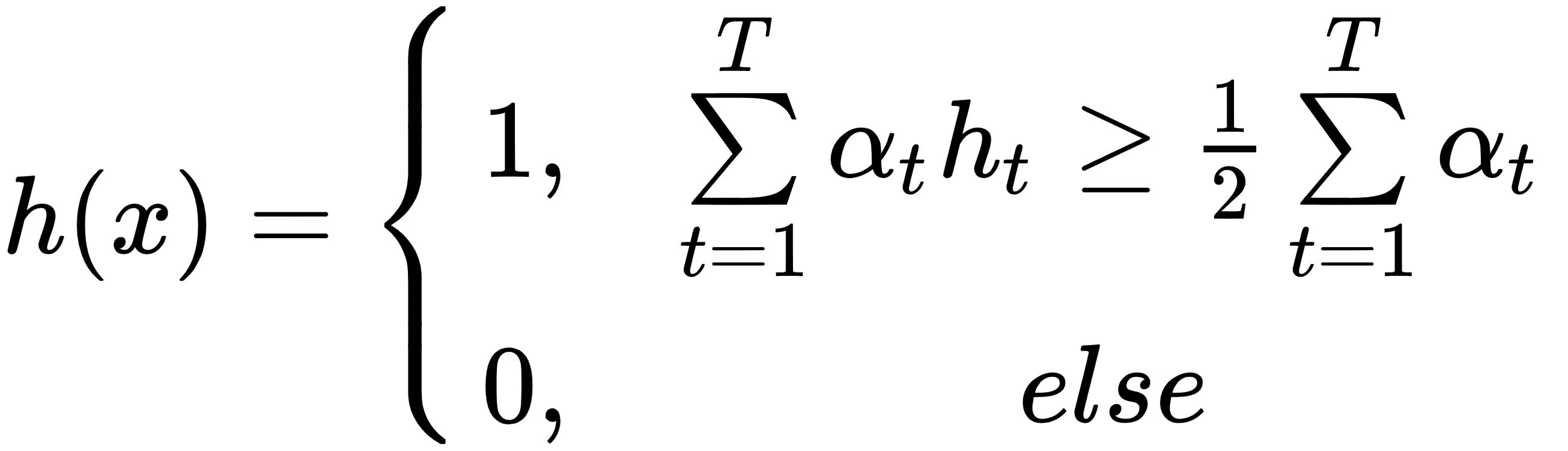
这里,α t = log( 1/β t ) 和β t = E t /( 1 - E t ):
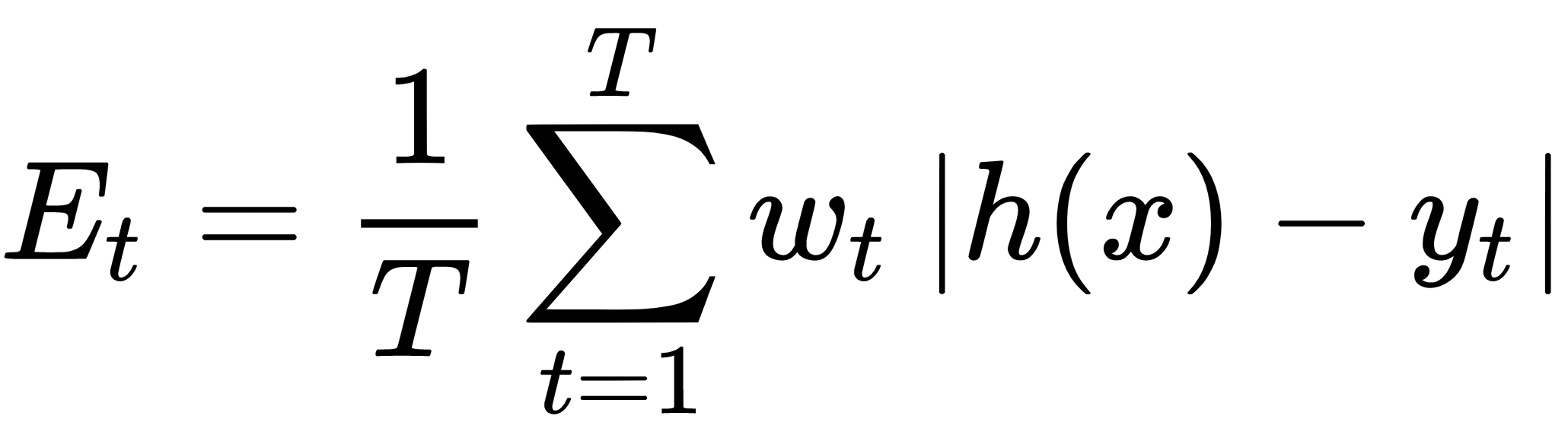
权重(W t)初始化如下:
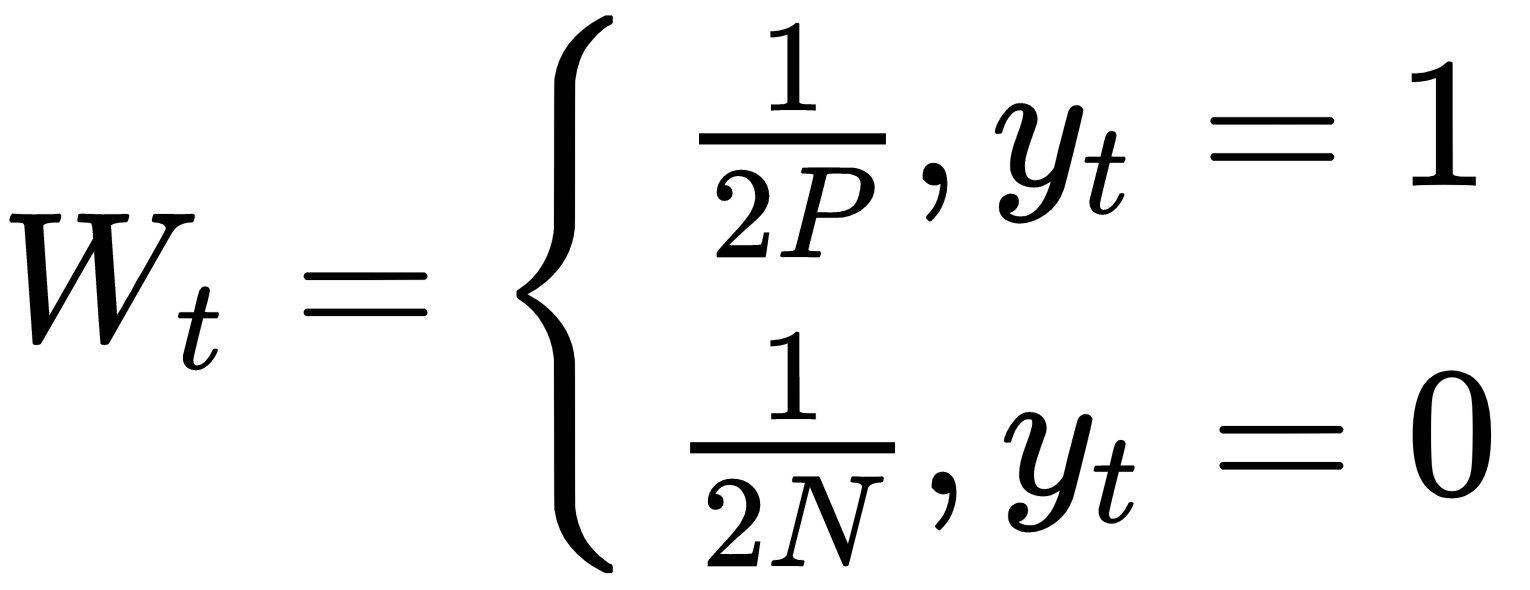
这里,P和N分别是正样本和负样本的数量。权重值更新如下:
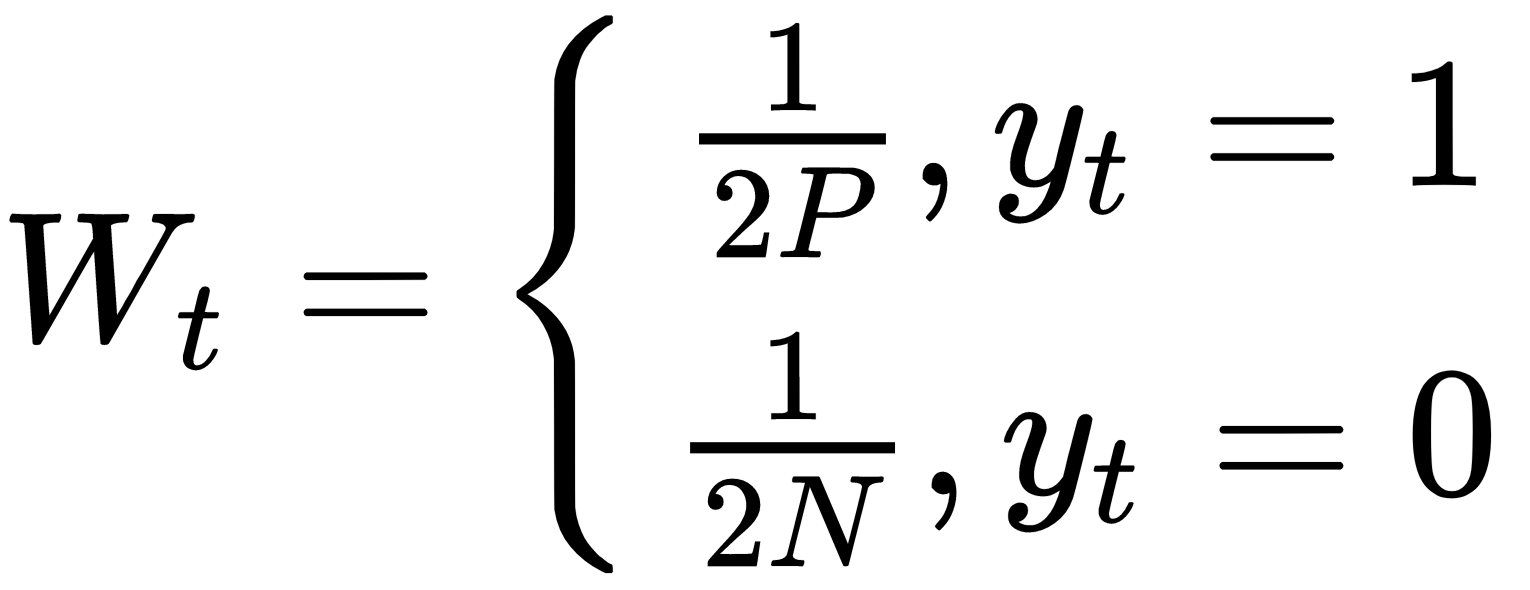
每个弱分类器计算一个特征。注意弱分类器不能单独做分类,但是几个组合起来就可以很好地分类。
注意级联分类器
前面描述的每个强分类器形成一个级联,其中每个弱分类器代表一个阶段,以快速去除负子窗口并保留正子窗口。来自第一个分类器的肯定响应意味着已经检测到面部区域(例如,眼睛区域),然后算法移动到下一个特征(例如,鼻子区域)以触发对第二个分类器的评估分类器等。任何时候的负面结果都会导致该阶段立即被拒绝。下图说明了这一点:
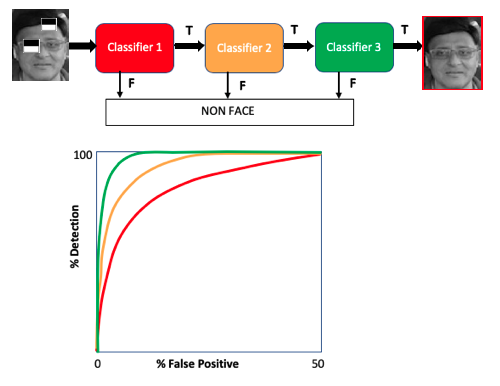
该图像显示负面特征立即被消除。随着分类从左到右移动,其准确性增加。
训练级联检测器
开发了整个训练系统以最大化检测率并最小化假阳性率。Viola 和 Jones通过为级联检测器的每个阶段设置目标检测率和误报率来实现这一点,如下所示:
- 级联检测器每一层的特征数量增加,直到该层达到目标检测率和假阳性目标。
- 如果总体误报率不够低,则添加另一个阶段。
- 一个矩形特征被添加到当前阶段,直到达到其目标速率。
- 当前阶段的假阳性目标用作下一阶段的负训练集。
下图显示了一个用于正面和眼睛的 OpenCV Python Haar 级联分类器,用于检测人脸和眼睛。左右图像都表明它可以正确检测到人脸;然而,在第一张图像中,由于左眼有眩光,仅检测到右眼,而在第二张图像中检测到两只眼睛。Viola-Jones 级联检测方法寻找强度梯度(眼睛区域比下方区域更暗),在这种情况下,由于眼镜右镜片的眩光,它无法在右眼中检测到它:

可在https://github.com/PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0/blob/master/Chapter03/Chapter3_opencv_face%26eyedetection_video.ipynb找到用于在网络摄像头视频中进行面部和眼睛检测的 OpenCV Python 代码. 请注意,为了使代码正常工作,您需要指定 Haar 级联检测器在您的文件夹中的路径。
到目前为止,我们已经了解了 Haar 级联分类器以及如何使用内置的OpenCV代码将 Haar 级联分类器应用于面部和眼睛检测。前面的概念基于使用积分图像检测 Haar-like 特征。这种方法非常适合面部、眼睛、嘴巴和鼻子的检测;然而,不同的面部表情和皮肤纹理可用于情绪(快乐与悲伤)或年龄确定等。Viola-Jones 方法 不太适合处理这些不同的面部表情,因此我们需要使用 Viola-Jones 方法进行人脸检测,然后应用神经网络确定人脸边界框内的人脸关键点。在下一节中,我们将详细学习此方法。
使用深度神经网络预测面部关键点
在本节中,我们将讨论面部关键点检测的端到端管道。面部关键点检测对计算机视觉来说是一个挑战,因为它需要系统检测面部并获得有意义的关键点数据,将这些数据绘制在面部并开发神经网络来预测面部关键点。与目标检测或图像分类相比,这是一个难题,因为它首先需要在边界框中进行面部检测,然后是关键点检测。正常的物体检测只涉及到代表物体周围矩形边界框四个角的四个点的检测,但关键点检测需要多个点(超过10个)在不同的方向。广泛的关键点检测数据及其使用教程可在以下位置找到Facial Keypoints Detection | Kaggle。Kaggle 关键点检测挑战涉及一个 CSV 文件,其中包含指向 7,049 个图像 (96 x 96) 的链接,每个图像包含 15 个关键点。
在本节中,我们不会使用 Kaggle 数据,但会向您展示如何为关键点检测准备自己的数据。有关该模型的详细信息,请访问https://github.com/PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0/blob/master/Chapter03/Chapter3_face%20keypoint_detection.ipynb 。
为关键点检测准备数据集
在本节中,您将学习如何创建自己的数据。这涉及编写代码并执行它,以便您 PC 中的网络摄像头亮起。将您的脸移动到不同的位置和方向并点击空格键,它会在从图像中裁剪出其他所有内容后保存您的脸部图像。此过程的关键步骤如下:
1.首先,我们首先指定 Haar 级联分类器的路径。这应该位于您的OpenCV/haarcascades目录中。那里会有很多.xml文件,所以包括以下路径frontalface_default.xml:
face_cascade = cv2.CascadeClassifier('path tohaarcascade_frontalface_default.xml')2.接下来,我们将使用videoCapture(0)语句定义网络摄像头操作。如果您的 PC 中插入了外部摄像头,则可以使用videoCapture(1):
cam = cv2.VideoCapture(0)3.相机帧使用步骤1cam.read()中定义的 Haar 级联检测器读取数据,然后在每个帧内检测人脸。使用参数在检测到的人脸周围绘制一个边界框。使用该参数,屏幕上只显示检测到的人脸: (x,y,w,h)cv2.imshow
while(True):
ret, frame = cam.read()
faces = face_cascade.detectMultiScale(frame, 1.3, 5)
for (x,y,w,h) in faces:
if w >130:
detected_face = frame[int( y):int(y+h), int(x):int(x+w)]
cv2.imshow("test", detected_face)
if not ret:
break
k = cv2.waitKey(1)4.接下来,将图像大小调整为img_size,定义为299,并将生成的图像保存在您的数据集目录中。请注意,我们299在本练习中使用图像大小,但这可以更改。但是,如果您决定更改它,请确保在创建注释文件时以及在最终模型中更改它,以避免注释和图像之间的不匹配。dataset现在在此 Python 代码所在的目录中创建一个名为的文件夹。请注意,每次您按空格键时,图像文件编号将自动递增:
faceresize = cv2.resize(detected_face, (img_size,img_size))
img_name = "dataset/opencv_frame_{}.jpg".format(img_counter)
cv2.imwrite(img_name, faceresize)为具有不同面部方向的不同人创建大约 100 幅或更多图像(在本次测试中,我总共拍摄了 57 张图像)。如果你有更多的图像,那么检测会更好。请注意,Kaggle 人脸点检测使用 7,049 张图像。获取所有图像并使用 VGG 注释器执行面部关键点注释,您可以从Visual Geometry Group - University of Oxford获得。您可以使用您选择的其他注释工具,但我发现这个工具(免费)非常有用。它绘制边界框,以及不规则形状和绘制点。在本练习中,我加载了所有图像并使用点标记在图像中绘制了 16 个点,如下图所示:

上图中的 16 个点代表左眼 (1-3)、右眼 (4-6)、鼻子 (7)、嘴唇 (8-11) 和外脸 (12-16)。请注意,当我们将图像关键点呈现为数组形式时,它们将表示为 0-15 而不是 1-16。为了获得更高的准确性,您可以只捕获面部的图像,而不是任何周围环境。
处理关键点数据
VGG 注释器工具会生成一个输出 CSV 文件,该文件需要进行两次预处理,以便为每个图像的 16 个关键点中的每一个生成 ( x , y ) 坐标。对于大数据处理来说,这是一个非常重要的概念,您可以将其用于其他计算机视觉任务,主要原因有以下三个:
- 我们的 Python 代码不会直接在目录中搜索大量图像文件,而是会在输入 CSV 中搜索数据路径。
- 对于每个CSV文件,有 16 个对应的关键点需要处理。
- 这是使用 KerasImageDataGenerator和flow_from_directory方法查看目录中每个文件的替代方法。
为澄清此内容,本节分为以下两个小节:
- 在输入到 Keras-Python 代码之前进行预处理
- Keras–Python 代码中的预处理
让我们详细讨论其中的每一个。
在输入到 Keras-Python 代码之前进行预处理
VGG 注释器工具会生成一个输出 CSV 文件,该文件需要以我们的 TensorFlow 代码可接受的格式进行预处理。注释的输出是一个 CSV 文件,以行格式显示每个关键点,每张图像有 16 行;我们需要对该文件进行预处理,以便每个图像有一行。共有33列表示32个关键点值和1图像值,如下所示:
(x0,y0), (x1,y1), (x2, y2), ....,(x15,y15) , 图像文件名
您可以使用自定义 Python 程序进行转换,尽管此处未显示。GitHub 页面包含已处理的 CSV 文件,供您参考https://github.com/PacktPublishing/Mastering-Computer-Vision-with-TensorFlow-2.0/blob/master/Chapter03/testimgface.csv 。
Keras–Python 代码中的预处理
在本节中,我们将 CSV 文件读取为X和Y数据,其中X是每个文件名对应的图像,Y有 16 个关键点坐标的 32 个值。然后,我们将Y数据分割成每个关键点的 16 个Yx和Yy坐标。详细步骤如下:
1.使用标准 Python 命令读取上一节中的 CSV 文件。在这里,我们使用目录中的两个 CSV,trainimgface.csv和。如果需要,您可以使用其他文件夹:testimgface.csvfaceimagestrain
train_path = 'faceimagestrain/trainimgface.csv'
test_path = 'faceimagestrain/testimgface.csv'
train_data = pd.read_csv(train_path)
test_data = pd.read_csv(test_path)2.接下来,我们在 CSV 文件中找到图片文件对应的列。在以下代码中,图像文件的列名是'image':
coltrn = train_data['image']
print (coltrn.shape[0])3.接下来,我们初始化两个图像数组imgs和Y_train. 我们读取train_data数组以添加图像列的路径,并为coltrn.shape[0]循环中定义的 50 个图像文件中的每一个读取图像文件for,并将其附加到图像的数组中。OpenCV BGR2GRAY使用该命令将读取的每个图像转换为灰度。在同一个for循环中,我们还使用命令读取 32 列中的每一列training.iloc[i,:],并将其附加到数组 for Y_train:
imgs = []
training = train_data.drop('image',axis = 1)
Y_train = []
for i in range (coltrn.shape[0]):
p = os.path.join(os.getcwd(), ' faceimagestrain/'+str(coltrn.iloc[i]))
img = cv2.imread(p, 1)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
imgs.append(gray_img)
y = training.iloc[i, :]
Y_train.append(y)4.这最终将图像转换为X_train使用以下代码调用的 NumPy 数组,这是 Keras 模型的输入所必需的:
X_train = np.asarray(imgs)
Y_train = np.array(Y_train,dtype = 'float')
print(X_train.shape, Y_train.shape)5.对测试数据重复相同的过程。现在我们已经准备好训练和测试数据。在继续之前,我们应该可视化图像中的关键点,以确保它们看起来不错。这是使用以下命令完成的:
x0=Y_trainx.iloc[0,:]
y0=Y_trainy.iloc[0,:]
plt.imshow(np.squeeze(X_train[0]),cmap='gray')
plt.scatter(x0, y0,color = 'red')
plt.show()在前面的代码中,np.squeeze用于移除最后一个维度,因此我们只有图像中的x和y值。plt.scatter绘制图像顶部的关键点。输出如下图所示:

上图显示了16个关键点叠加在图像的顶部,表示图像和关键点是对齐的。左右图像表示训练图像和测试图像。这种目视检查对于确保所有预处理步骤不会导致不正确的面到关键点对齐至关重要。
定义模型架构
该模型涉及使用卷积神经网络( CNN ) 来处理面部图像及其 16 个关键点。有关 CNN 的详细信息,请参阅第 4 章,图像深度学习。CNN 的输入是训练和测试图像以及它们的关键点,其输出将是与新图像对应的关键点。CNN 将学习预测关键点。模型架构的详细信息如下图所示:
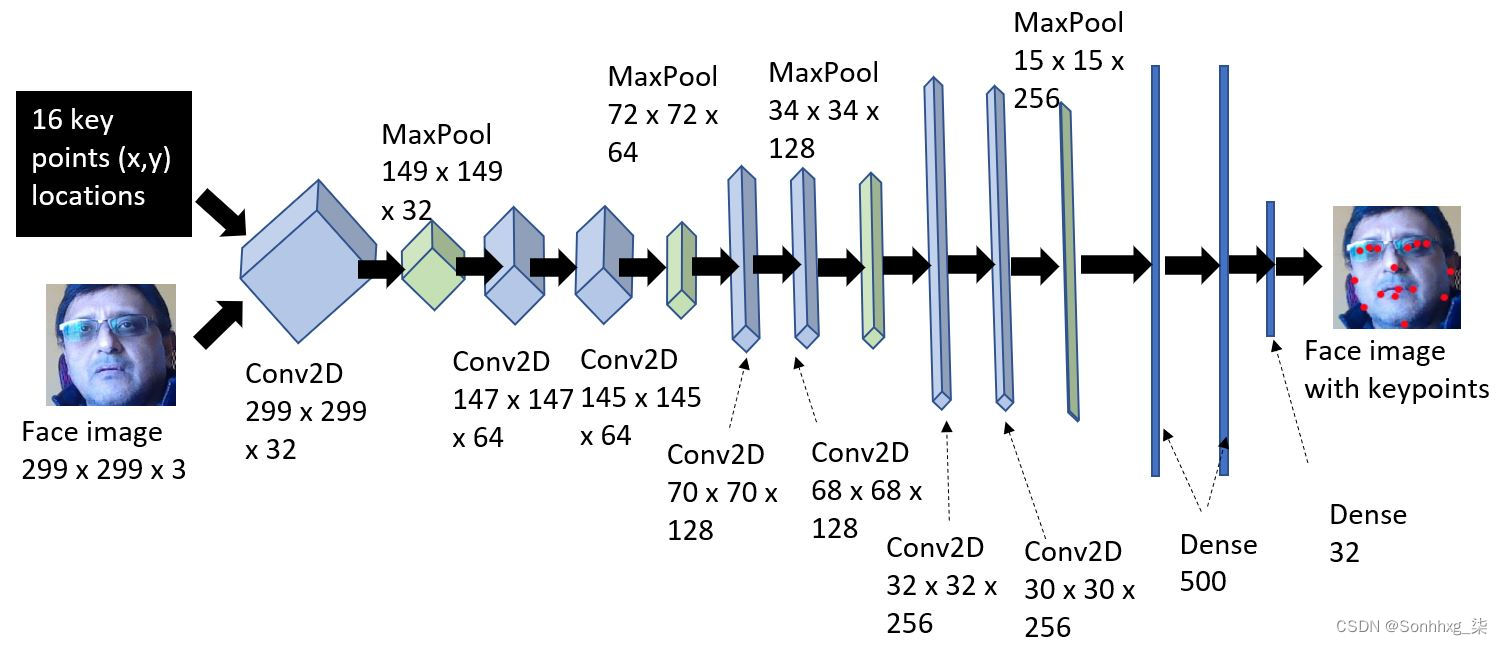
上述模型的代码如下:
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(299,299,1), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Conv2D(256, (3, 3), activation='relu'))
model.add(Conv2D(256, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dense(500, activation='relu'))
model.add(Dense(32))该代码获取一张图像并应用 32 个大小为 (3,3) 的卷积过滤器,然后是激活和最大池化层。它多次重复相同的过程,过滤器数量增加,然后是平坦和密集的层。最后的密集层有 32 个元素,分别代表我们想要预测的 16 个关键点的x和y值。
训练模型进行关键点预测
现在我们已经定义了模型,在本小节中,我们将编译模型,重塑其输入,并通过以下步骤开始训练:
1.我们将首先定义模型损失参数,如下所示:
adam = Adam(lr=0.001)
model.compile(adam, loss='mean_squared_error', metrics=['accuracy'])2.然后将数据重新整形以输入到 Keras 模型中。重塑数据很重要,因为 Keras 需要 4D 形式的数据——数据数 (50)、图像宽度、图像高度、1(灰度):
batchsize = 10
X_train= X_train.reshape(50,299,299,1)
X_test= X_test.reshape(7,299,299,1)
print(X_train.shape, Y_train.shape, X_test.shape, Y_test.shape)模型X和Y参数解释如下:
- X_train (50, 299, 299, 1)# 训练数据,图像宽度,图像高度,灰度为 1
- Y_train (50, 32)# 训练数据,# 关键点——这里,我们有 16 个x和y值的关键点,使其成为 32
- X_test (7, 299, 299, 1)# 测试数据,图像宽度,图像高度,灰度为 1
- Y_test (7, 32)# of test data, # of key points——在这里,我们有 16 个x和y值的关键点,使其成为 32
3.训练由model.fit命令发起,如下:
history = model.fit(X_train, Y_train, validation_data=(X_test, Y_test), epochs=20, batch_size=batchsize)训练步骤的输出如下图所示:
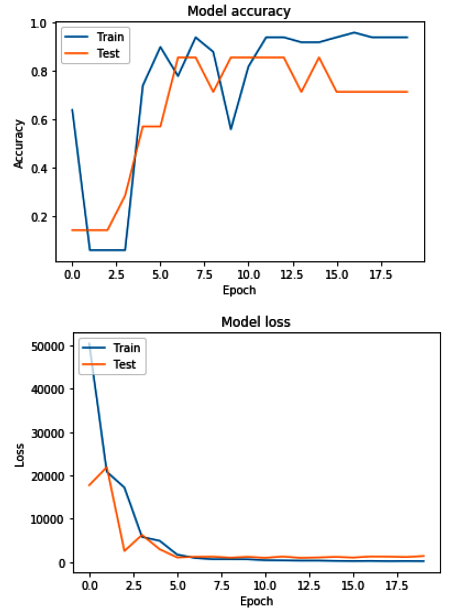
该模型在大约 10 个 epoch 内获得了相当不错的准确率,但损失项约为 7000。我们需要收集更多的图像数据以使损失项低于 1:
4.我们将y_val根据测试数据预测模型输出X_test,使用model.predict。测试数据X_test是图像,但它们已经以模型可以理解的数组形式进行了预处理:
y_val = model.predict(X_test)5.请注意,y_val这里每个预处理图像数组输入有 32 个点。接下来,我们将这 32 个点分解为代表 16 个关键点的x和y列:
yvalx = y_val[::1,::2]
yvaly = y_val[:, 1::2]6.最后,我们使用以下代码在图像顶部绘制预测的 16 个关键点:
plt.imshow(np.squeeze(X_test[6]),cmap='gray')
plt.scatter(yvalx[6], yvaly[6], color = 'red')
plt.show()请注意,对于 50 张图像,模型预测效果不会很好;这里的想法是向您展示该过程,以便您可以通过收集更多图像来构建此代码。随着图像数量的增加,模型的准确率也会提高。尝试为不同的人和不同的方向拍摄图像。此处描述的技术可以扩展到与身体关键点检测一起使用,如第 9 章,使用多任务深度学习的动作识别中所述。此外,第 11 章,具有 CPU/GPU 优化的边缘设备上的深度学习,有一个关于 Raspberry Pi 上 OpenVINO 的部分,其中提供了一个 Python 代码来预测和显示基于 OpenVINO 工具包预训练模型的35 个面部关键点.
使用 CNN 预测面部表情
面部表情识别是一个具有挑战性的问题,因为面部、照明和表情(嘴巴、眼睛睁开的程度等)的变化以及需要开发一种架构和选择可以导致持续高准确性。这意味着挑战不仅在于为一个人在一种照明条件下正确确定一种面部表情,而且在于正确识别所有戴或不戴眼镜、帽子等的人以及在所有照明条件下的所有面部表情。以下 CNN 示例将情绪分为七种不同的类别:愤怒、厌恶、害怕、快乐、悲伤、惊讶和中性。面部表情识别涉及的步骤如下:
- 导入函数Sequential—— , Conv2D, MaxPooling2D, AvgPooling2D, Dense, Activation, Dropout, 和Flatten.
- 导入ImageDataGenerator——它生成具有实时增强(方向)的批量张量图像。
- 确定分类的批次大小和时期。
- 数据集——训练、测试和调整大小 (48,48)。
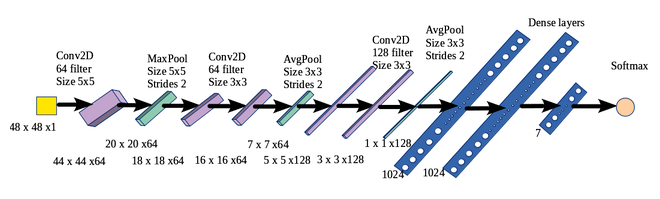
- 建立CNN架构(如下图所示)。
- 使用该fit-generator()函数来训练开发的模型。
- 评估模型。
CNN架构如下图所示:
模型的结果如下图所示。在大多数情况下,它能够正确预测面部表情:
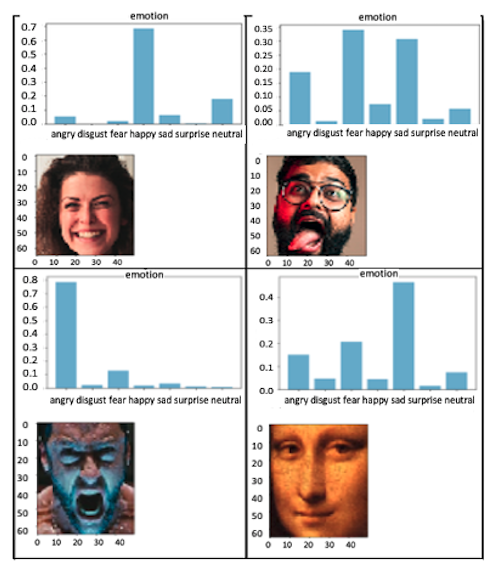
强烈的情绪(笑脸或愤怒的脸)被非常清楚地检测到。CNN 模型能够正确预测各种情绪,甚至是微妙的情绪。
3D人脸检测概述
3D 人脸识别涉及测量人脸刚性特征的几何形状。它通常通过使用飞行时间、测距相机生成 3D 图像或从对象的 360 度方向获取多个图像来获得。传统的 2D 相机将 3D 空间转换为 2D 图像,这就是为什么深度感应是计算机视觉的基本挑战之一。基于飞行时间的深度估计基于光脉冲从光源传播到物体并返回相机所需的时间。光源和图像采集同步以获得深度。飞行时间传感器能够实时估计全深度帧。飞行时间的一个主要问题是空间分辨率低。3D人脸识别可以分为以下三个部分:
- 3D重建硬件设计概述
- 3D 重建和跟踪概述
- 参数跟踪概述
3D重建硬件设计概述
3D 重建涉及相机、传感器、照明和深度估计。用于 3D 重建的传感器可分为三类:
- 多视图设置:具有受控照明的校准密集立体相机阵列。从每个立体对中,使用三角测量重建面部几何形状,然后在强制几何一致性的同时进行聚合。
- RGB 摄像头:组合多个 RGB 摄像头,根据飞行时间方法计算深度。
- RGBD 摄像头: RGBD 摄像头同时捕捉颜色和深度——例如 Microsoft Kinect、Primesense Carmine 和 Intel Realsense。
3D 重建和跟踪概述
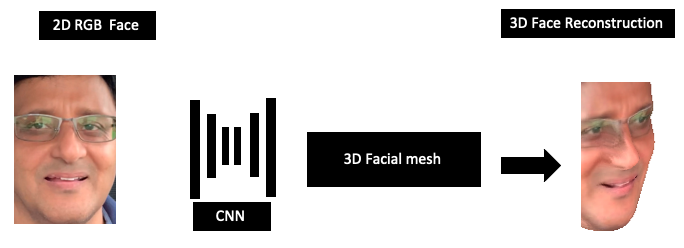
3D 人脸重建涉及通过构建 CNN 回归深度,从相应的 2D 图像估计 3D 人脸的坐标。下图以图形方式说明了这一点:
一些流行的实时 3D 表面映射算法描述如下:
- Kinect Fusion :使用 Kinect 深度传感器进行实时 3D 构建。Kinect 是一种商品传感器平台,其中包含一个 30 Hz 的基于飞行时间的结构化深度传感器。
- 动态融合:使用单个 Kinect 传感器的体积 TSDF(截断符号距离融合)技术的动态场景重建系统。它采用嘈杂的深度图并通过估计体积 6D 运动场来重建实时 3D 运动场景。
- Fusion4D :这使用多个实时 RGBD 摄像机作为输入,并使用体积融合处理多个图像以及使用密集对应场的非刚性对齐。该算法可以处理较大的帧到帧运动和拓扑变化,例如一个人脱掉夹克或快速从左到右改变他们的面部方向。
- Motion2Fusion :该方法是一个 360 度性能捕捉系统,用于实时(每秒 100 帧)重建。它基于具有学习 3D 嵌入的非刚性对齐策略、更快的匹配策略、用于 3D 对应估计的机器学习以及用于复杂拓扑变化的后向/前向非刚性对齐策略。
参数跟踪概述
面部跟踪模型将投影线性 3D 模型用于摄像机输入。它执行以下操作:
- 跟踪从前一帧到当前帧的视觉特征
- 对齐 2D 形状以跟踪特征
- 根据深度测量计算 3D 点云数据
- 最小化损失函数
概括
尽管各种肤色、方向、面部表情、头发颜色和照明条件会引起复杂性,但人脸识别是计算机视觉的成功案例。在本章中,我们学习了面部检测技术。对于这些技术中的每一种,您都需要记住,面部检测需要大量经过训练的图像。人脸检测被广泛用于许多视频监控应用程序,标准 API 可用于谷歌、亚马逊、微软和英特尔等基于云的设备和边缘设备。我们将在第 11 章了解基于云的 API,在边缘设备上使用 CPU/GPU 优化进行深度学习,并在第 4 章了解 CNN 技术,图像深度学习,以及第5 章,神经网络架构和模型。本章简要介绍了用于人脸检测和表情分类的 CNN 模型。