进程控制
- 进程创建
- fork函数
- 写时拷贝
- fork常规用法
- fork调用失败的原因
- 进程终止
- 进程等待
- 进程程序替换
- 程序替换的原理
- 如何程序替换
进程创建
fork函数
fork之前父进程独立运行,fork之后,父子两个执行流分别执行。
进程具有独立性,代码和数据必须独立的,代码只能读取,数据通过写时拷贝实现独立。
fork之后,是否只有fork之后的代码是父子进程共享的?
fork之后,父子共享所有的代码
子进程执行的后续代码!=共享的所有代码,只不过子进程只能从这里开始执行
在
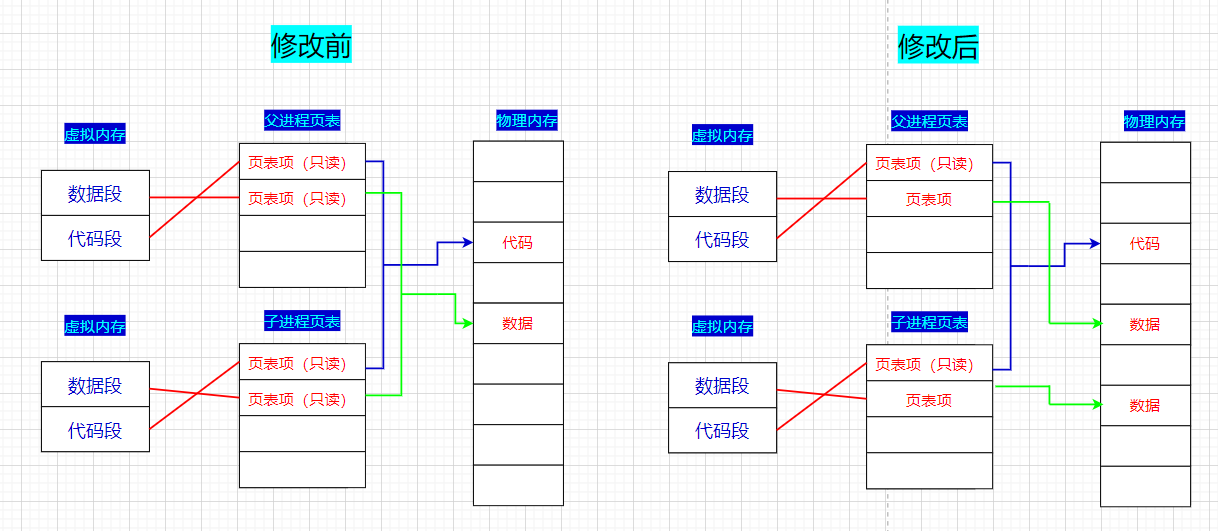
fork之后,会给子进程分配内存块和内核数据结构,将父进程的部分数据结构内容拷贝到子进程的数据结构中,在父进程的pcb中的上下文数据中存在一个程序计数器(eip/pc指针),eip中存储正在运行指令的下一条指令,因为子进程的pcb是用父进程的pcb初始化的,所以现在子进程pcb中的eip中存储的内容和父进程相同,那么子进程只能从这里开始执行。**补充:**程序进行循环,跳转,都是修改
eip来实现写时拷贝
写时拷贝本身就是由
os的内存管理模块完成的页表中除了映射关系还有读写属性
当刚创建子进程时,子进程的映射关系继承自父进程,会把父进程页表,子进程页表的映射关系都设置为只读的,当发生修改时,再将修改的数据拷贝到另一个空间,修改子进程的映射关系,把这个数据的读写属性改为可写。
为什么要写时拷贝?
创建子进程的时候,就把数据分开,不行吗?
父进程的数据,子进程并不一定要修改,不修改,就没有必要再拷贝一份,如果全部拷贝一份,会导致浪费空间。
如果fork的时候,就无脑拷贝数据的子进程,会增加fork的成本(内存和时间)
写时拷贝是延迟拷贝
因为,拷贝数据的最小拷贝成本就是只拷贝修改的数据
既然拷贝成本依旧存在,我们不再一开始拷贝,而是等到需要时,再拷贝。
那么在需要这个空间之前,把这个空间先给别人使用,变相提高了内存的使用率
fork常规用法
一个父进程希望复制自己,使父子进程同时执行不同的代码段(比如:通过fork的返回值判断父子进程执行不同的代码)
int main() { pid_t id=fork(); if(id==0) { printf("我是子进程\n"); } else { printf("我是父进程\n"); } return 0; }一个进程要执行一个不同的程序(比如:子进程从fork返回后,调用exec函数(程序替换))
int main() { pid_t id=fork(); if(id==0) { printf("我是子进程\n"); } else { printf("我是父进程\n"); execlp("ls","ls",NULL); } return 0; }fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程超出了限制
进程终止
在C/C++中,我们写
main函数,都会在结尾return 0;
- 这个0是return给谁的?
- 为什么是0,其他值可不可以?
return + 数字,这个数字叫做进程退出码,当进程退出时,会把进程退出码放到该进程的
pcb中,父进程从子进程的pcb中获取进程退出码,所以这个进程退出码是给父进程的。进程退出分为三种
进程跑完,结果正确
进程跑完,结果错误
进程异常退出
0:表示进程跑完
非0:表示进程异常退出,异常退出的原因不同,数字不同
echo $? //在bash中,最近一次执行完毕时,对应的进程退出码失败的非零值可以自定义
关于终止的常见做法
在main函数中return,为什么其他函数不行
非main函数 return叫做函数调用返回值
main函数return叫做进程退出
在任何一个地方调用exit(参数进程退出码),叫做进程退出
exit()终止进程,会刷新缓冲区
_exit()终止进程,不会刷新缓冲区
关于终止,内核做了什么?
进程终止后,进程就会进入僵尸进程,父进程进程等待子进程,获取子进程的退出信息,子进程进入死亡状态,这时,这个进程才是真正的退出。
进程 = 内核数据结构 + 进程代码 和 数据
退出就要释放这个进程内核的数据结构 + 代码 和 数据
但是操作系统可能不会释放该进程的内核数据结构,创建对象分为两步:1、开辟空间 2、初始化
操作系统会维护一个废弃数据结构链表,进程退出后,会将这个进程放到这个链表中,等到创建一个新进程的内核数据结构时,就将它们从这个链表拿出来,直接初始化,就节省了开辟空间的工作。
这个废弃数据结构链表也叫内核的数据结构缓冲池,slab分派器
进程等待
为什么要进程等待?
- 子进程退出,父进程需要知道子进程的任务做的如何,否则,会导致子进程一直处于僵尸状态,进而造成内存泄漏
- 如果进程进入僵尸状态,就无法杀死(kill -9)
- 父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
如何等待?
waitwait(NULL); //等待任意一个退出的子进程
#include<stdio.h> #include<unistd.h> #include<sys/types.h> //wait所需头文件 #include<sys/wait.h> //wait所需头文件 int main() { pid_t id=fork(); if(id==0) { int cnt=10; while(cnt--) { printf("我是子进程,pid:%d\n",getpid()); sleep(1); } } else { printf("我是父进程,pid:%d\n",getpid()); sleep(20); int ret = wait(NULL); printf("ret:%d\n",ret); int cnt=3; while(cnt--) { sleep(1); } } return 0; }
waitpid
pid_t waitpid(pid_t pid,int *status,int options);//等待一个指定的退出子进程
pid:
pid>0:是几,就代表哪一个子进程,指定等待进程
pid=-1,等待任一进程,等价于wait
status: 输出型参数,从该子进程的pcb中获取通过调用该函数,从函数内部拿出来特定的数据(从子进程的
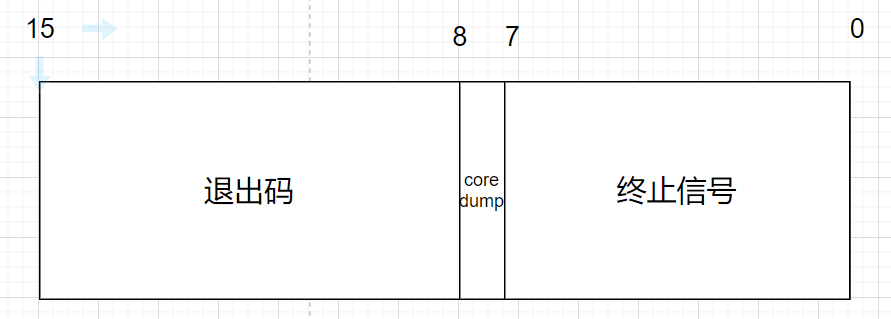
pcb中拿出来子进程退出码)(子进程退出时,会把子进程的退出信息写入到进程的pcb中,代码可以释放)status是一个32位整数,我们只取低16位整数,其中,次低8位为进程退出码,低7位为进程终止信号,低第8位为core dump标志
options: options = 0为阻塞等待,options =WNOHANG为非阻塞等待**阻塞等待:**当父进程等待子进程时,子进程还没有退出,父进程阻塞,等到子进程退出,唤醒父进程,等待子进程
阻塞等待返回值:
返回值>0等待成功,返回子进程
pid返回值<0等待失败
#include<stdio.h> #include<unistd.h> #include<sys/types.h> #include<sys/wait.h> #include<stdlib.h> int main() { pid_t id=fork(); if(id==0) { int cnt=5; while(cnt) { printf("i am a child progress, pid : %d , %d s\n ",getpid(),cnt--); sleep(1); } printf("子进程退出\n"); exit(10); } else { int status=0; int ret=waitpid(id,&status,0); printf("退出码: %d , 退出信号: %d , coredump标志位: %d\n",(status>>8)&0xFF,status&0x7F,status&0x80); } return 0; }**非阻塞等待:**当父进程等待子进程时,子进程还没有退出,父进程先去做自己的事
//非阻塞等待一般多次调用非阻塞接口,轮询检测(循环)
非阻塞等待返回值:
>0,等待成功,返回自己子进程**pid**,
=0,等待成功,子进程还没有退出,父进程做自己的事
<0,等待失败kill -l所有信号,没有零号
如果异常退出,只关心退出信号,退出码没有意义
#include<vector> #include<stdio.h> #include<stdlib.h> #include<unistd.h> #include<sys/types.h> #include<sys/wait.h> typedef void(*handler_t)(); std::vector<handler_t> handlers; void fun1() { printf("方法一\n"); } void fun2() { printf("方法二\n"); } void Load() { handlers.push_back(fun1); handlers.push_back(fun2); } int main() { pid_t id=fork(); if(id==0) { int cnt=5; while(cnt) { printf("i am a child progress, pid : %d , %d s\n ",getpid(),cnt--); sleep(1); } printf("子进程退出\n"); exit(10); } else { int status=0; while(1) { int ret=waitpid(id,&status,WNOHANG); if(ret>0) { //等待成功 printf("退出信号: %d , 退出码: %d , coredump标志位: %d\n",(status>>8)&0xFF,status&0x7F,status&0x80); break; } else if(ret==0) { //等待成功,子进程还没退出,父进程做自己的事 if(handlers.empty()) Load(); for(auto f : handlers) { f(); sleep(1); } } else { //等待失败 } } } return 0; }补充:
WITEXITED(status):若为正常终止子进程返回的状态,则为真。(查看进程是否正常退出)
WEXISTATUS(status):若WITEXITED非零,提取子进程退出码。(查看进程的退出码)
进程程序替换
之前都是子进程执行父进程的代码片段
如果我们想让创建出来的子进程,执行权限的程序呢?
进程程序替换
子进程往往需要干两种事
- 执行父进程的代码片段
- 执行磁盘中一个全新程序
程序替换的原理
将磁盘中的程序加载到内存中
为页表重新建立映射关系,映射到这个全新的程序代码
让父进程和子进程彻底分离,并让子进程执行一个全新程序
如何程序替换
通过系统调用完成
int execl(const char *path, const char *arg, ...); int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg,..., char * const envp[]); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execvpe(const char *file, char *const argv[],记忆方法
l(list): 表示参数采用列表v(vector): 参数用数组p(path): 有p自动搜索环境变量PATHe(env): 表示自己维护环境变量
execle函数自己维护的环境变量,是覆盖式的
int main() { pid_t id=fork(); if(id==0) { printf("我是子进程,pid:%d,ppid:%d,将要程序替换\n",getpid(),getppid()); char* const env_[]={(char*)"MYPATH=byld",NULL}; execle("./mycmd","mycmd",NULL,env_); } else { int status=0; int ret = waitpid(id,&status,0); if(ret==id) { sleep(2); printf("我是父进程,pid:%d,ppid:%d\n",getpid(),getppid()); } } return 0; }
如何使用系统提供的环境变量?
extern char** environ;
execle("./mycmd","mycmd",NULL,environ);如何追加环境变量?
在bash中
export MYPATH=1234
进程替换实例:
将
myproc的子进程进程替换成mycmd
myproc.cppint main() { pid_t id=fork(); if(id==0) { printf("我是子进程,pid:%d,ppid:%d,将要程序替换\n",getpid(),getppid()); execl("./mycmd","mycmd",NULL); } else { int status=0; int ret = waitpid(id,&status,0); if(ret==id) { sleep(2); printf("我是父进程,pid:%d,ppid:%d\n",getpid(),getppid()); } } return 0; }
mycmd.cint main() { printf("PATH:%s\n",getenv("PATH")); int n=10; int sum=0; for(int i=1;i<=n;i++) { sum+=i; } printf("%d\n",sum); return 0; }
注意:不带e的程序替换函数,替换后的子进程也有环境变量,同样继承自父进程(从这个实例可知)



为什么会有这么多接口?
execve为什么是单独的?execve才是真正的系统接口,其他的是对这个系统接口的封装,都会转化成对execve这个系统接口的调用,为了适配应用场景