最近放假在超星总部河北燕郊园区实习,本来是搞前后端开发岗位的,然后带我的副总老大哥比较关照我,了解我的情况后得知我大三选的方向是大数据,于是建议我学学python、Hadoop,Hadoop我看了一下内容比较多,而且我现在大二暑假不着急这么快学完,公司暂时也没这个项目可以给我学,于是我就先学了两天python,把基础python学完了。
然后副总老大哥来问我学完了Python是吧,直接给我一个项目好好了解一下,然后我看了这个项目的文档,PyTorch??是啥??
这给我搞迷糊了,他跟我解释这是一个ai深度学习的框架语言,于是我又开始了新的学习,这里以这篇文章开始记录我对PyTorch的学习。
一、PyTorch是啥?
本人语言能力较差,也只是小白,所以这里直接用权威的百度百科简单介绍:
简单来说就是基于Python语言编写的深度学习框架,现如今学习人工智能就是学深度学习,而深度学习单纯用python来写要写巨海量的代码,我们这些小卡拉米根本没这个能力,所以就需要一个深度学习框架帮我们省去很多代码,就像前端后端都需要框架语言一样,下面是百度百科:






二、安装与配置
1、安装ANACONDA
ANACONDA是一个工具库,里面有很多我们后面学习需要的工具包,就像你的java后端maven里可以下载大量依赖包、pycharm可以下载大量依赖包一样,ANACONDA就是这么个玩意。
最新版下载官方地址(不能选版本):Anaconda | The Operating System for AI
(可选旧版本的下载地址):Anaconda Installers and Packages
(1)第一个最新版下载地址的下载步骤
下载步骤是:(当然这个版本不太稳定,但是没办法,我本人已经安装了最新版python......只好对应安装最新版anaconda)







(2)可选旧版本的下载步骤:
当然有的人用的是旧版本的Python,可能旧版本的Python就需要旧的的anaconda支持,所以你们需要根据自己的python版本来找对应的anaconda版本
查看python版本可以直接cmd,输入python
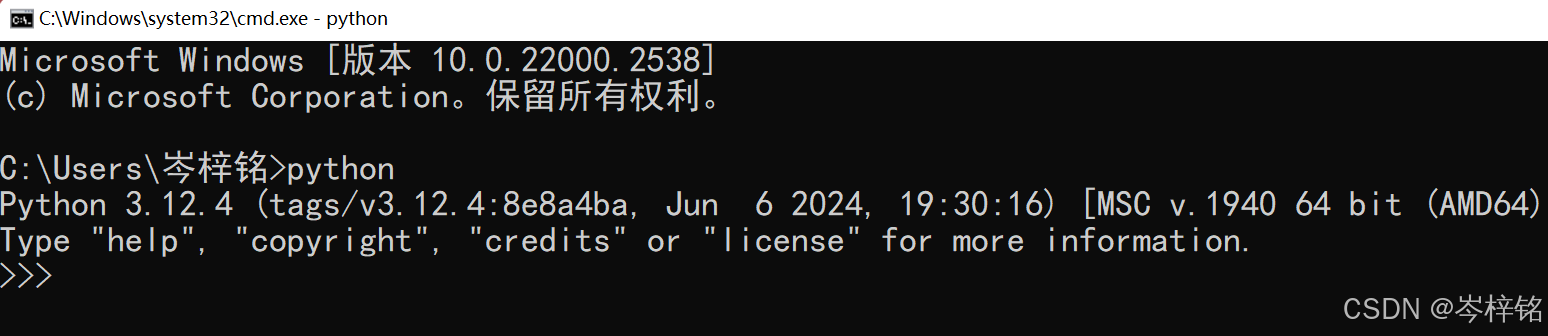
下面是一些对应关系的表:
Anaconda版本与Python版本对应关系_conda22.9.0是什么版本-CSDN博客

然后下载步骤:
也可以直接点这个网址:Index of /
然后选择你要的版本点击下载


(3)安装步骤:
......省略后面,一直next就行了
然后弹出这个,爽!当然我这是最新版的安装,就版本大差不差,基本就是你只要改一下默认安装路径,然后其他的就直接点【next】【skip】【finish】一直往下就ok了,全都默认就行
这里他还提醒我还有一个新版本可以更新,我现在只想用它,就懒得更新了,直接No,然后开始使用吧
最后,检查安装,点击桌面【开始】看看有没有Anaconda Prompt这个应用,点击只会正常弹出黑框,就大功告成
最后最后,进去应用里登陆一下就行,没账号的就先注册,这个Anaconda就先告一段落












2、(可选,非必选)安装英伟达NVIDIA
这个玩意吧就是加快机器深度学习效率的显卡,打游戏的屌丝们肯定不陌生,那么不安装也不影响深度学习,自己看着来吧,我是拯救者r8000,电脑自带NVIDIA,所以我这就懒得再做安装演示了
如何检查自己有没有NVIDIA驱动?
打开任务管理器——>性能——>GPU,能看到NVIDIA就ok


3、利用conda管理、切换Python、PyTorch版本
就跟我们前端的NVM一样,conda来自于Anaconda工具包,它的作用就是控制管理我们多个Python、PyTorch版本之间的切换。如果你不这样弄,你如果有一个项目需要用python 1.2,而你的是别的版本,那只能在本地环境中卸载原版本,再安装python 1.2,很麻烦
原理就是你的电脑依旧有两个版本的Python或者PyTorch,但是也对应存在了两个环境,默认本地的原环境是【base】,当你要切换到比如Python 1.0版本,那么我们直接切换一个环境到适用于这个版本的一个环境。
打比方:你娶了两个妻子,但正房跟二房两个水火不容、争风吃醋,那你今晚想跟1号妻子睡你就到她住的那个房子里睡,明晚你想跟2号妻子睡你就换到她的房子里睡......
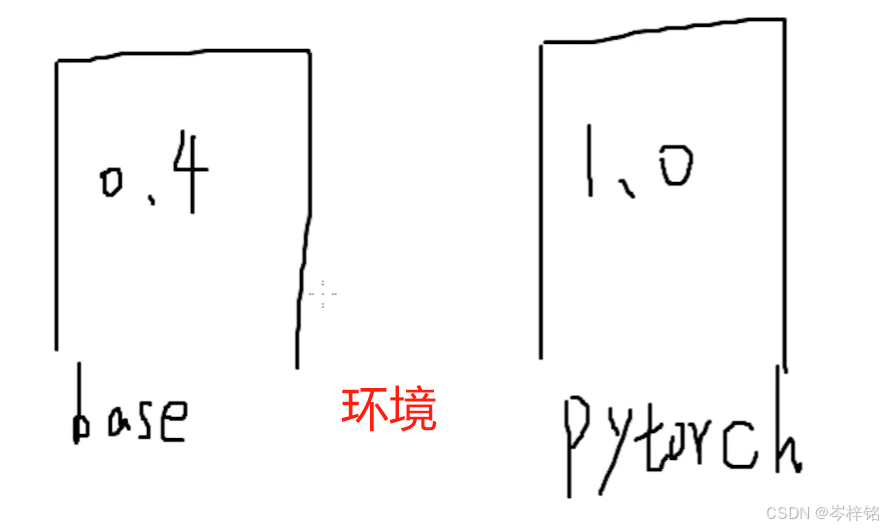
那么前面我也说了,公司里的老大哥给我的项目就需要python 3.8,而我的是3.12,虽然都版本3,但是我还是尽量按照他的要求来,切换成python 3.8的
点击打开Anaconda Prompt
/
输入:conda create -n 这个版本的环境别名 python=要切换的版本号
。
然后会问你是否安装以上依赖,默认输入【y】表示确认
。
然后安装完毕,会询问你:“是否想激活切换到这个版本”
是的话我们输入:【conda activate 刚刚给这个版本起的环境别名】
然后就能发现环境以及切换了





4、安装PyTorch
输入:【pip list】可以看到我们这个Python环境下,Python安装的所有依赖包
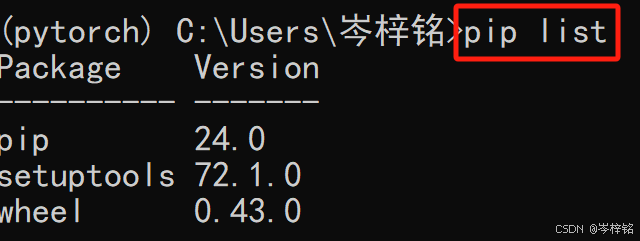
那么可以发现,我们并没有PyTorch,那么终于来到这一步,安装PyTorch
PyTorch安装官网:PyTorch
依旧是两种安装:
(1)新版本安装:
如果你没有特别要求,那么你安装新版本就行了
进入官网,往下拉找到这个地方
,
如果下载安装得很慢的话,可以去这个链接下载这两个程序:
https://pan.baidu.com/s/1CvTIjuXT4tMonG0WltF-vQ?pwd=jnnp 提取码: jnnp
复制粘贴到anacondas的安装路径下的pkgs这个路径
然后再重新执行刚才的安装命令就会变快了
,
最后输入:【pip list】检查是否存在【torch】这个依赖包,有就成功了;没有就重新安装一遍
/
最后最后最后
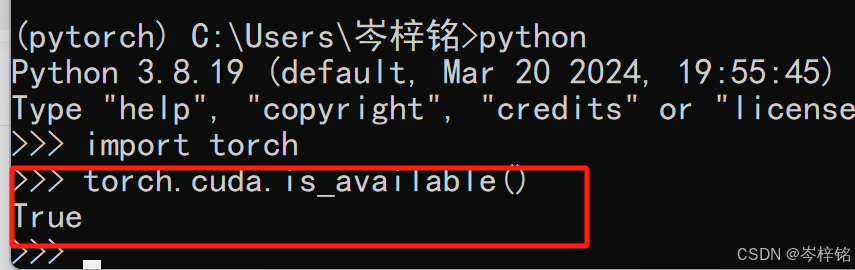
输入【python】切换到python环境,然后输入【import torch】,如果没有报错就无敌!成功!完美!








(2)旧版本安装:
还是得选老版本,因为我要符合老大哥的环境要求

还是这个地方,找到上面一段文字里红色的链接,选旧版本就点他
/
然后找到你要的版本,按照图片这样选择要执行的命令,复制到Anaconda Prompt执行
最后输入:【pip list】检查是否存在【torch】这个依赖包,有就成功了;没有就重新安装一遍
/
最后最后最后
输入【python】切换到python环境,然后输入【import torch】,如果没有报错就无敌!成功!完美!




另外,输入【torch.cuda.is_available()】显示True的话,就说明PyTorch可以使用我们电脑的GPU
5、Python编辑器安装
你得有这个你才能写代码,那么我不打算将这一块,因为我是先学的python再学PyTorch,而且这玩意安装简直是小脑瘫、唐人都可以无脑安装的,你甚至进了官网点下载然后安装一直乱点下去都能安装好,那我就不讲了,自己查。
三、创建适合PyTorch环境的Python项目
我这里用的是PyCharm这款编译器,那么这个最新版的PyCharm来创建配置Condas环境的python项目各种各样,方法很多,可以参考下面这两个,也可以跟着我的文章来都行。
其他博主的最新版配置教学视频:【2024最新版】保姆级Anaconda安装+PyCharm安装和基本使用,Python编程环境安装_哔哩哔哩_bilibili
最新版配置教学文章:Pycharm配置conda环境(解决新版本无法识别可执行文件问题)_conda可执行文件-CSDN博客
1、那么下面是我的个人安装步骤:
我之前用它写过一些代码,用的是python 3.12版本(没有PyTorch的),那么就要切换到我们配置了PyTorch的Python环境中,点击左上角【文件】,点击【新建项目】重新新建一个项目
。
如果是新用户刚刚第一次打开,也是一样,点击【新建项目】
。
给你的项目定一个路径,切记,不可以有中文或奇怪符号
。
然后第一次用的用户,【解析器类型】这选择【基础condas】,然后会有个黄色提示,点击在这个提示右边的【选择路径】
然后这里选择我们刚刚【用Anacondas管理安装的含有PyTorch的这个Python.exe程序】。
具体路径在【你安装Anacondas的路径的 \ envs \ 你起的python环境别名的包 \ python.exe】
。
然后就进入到项目界面,到这还没完,你会发现你的项目是个空文件夹,连展开的那个小箭头都没有,这里是因为我们还需要手动导入【系统解释器】,相当于我们spring boot项目需要导入maven管理、JSP要引入web一样,你有这玩意他才知道 “噢你是condas老大的罩的python”,不然就会把你这个python项目当成 “没人理的流浪汉”。
点击右上角的【文件】,点击【设置】
。
然后选中【项目:xxxx...】(版本控制下面)—>【Python解释器】
然后点击【添加解释器】
/
这里有两种路径来配置这个condas的环境:
(1)第一种:选择【Conda环境】,然后导入Anacondas安装路径下的【Scripts】的【condas.exe】
(我没试过,我用的是第二种)
给
(2)第二种:选择【系统解释器】,不是上一个“Condas环境”!!
然后手动还是把刚刚新建项目时我们导入的Anacondas安装路径下的envs的“环境别名”的python.exe
/
然后返回【设置】,点【应用】【确定】,OK,等待配置扫描安装......















2、终端验证项目是否成功的报错解决方案
然后我们就可以打开右下角的终端,检查这个condas环境的python项目搭建好了没
但当时我一打开给我报了这么个错,如果有遇到相同情况的朋友,跟着我做,包不会错,很简单
看了别的博主文章才知道:是因为我们之前装java的环境的时候,java的环境变量在path的配置那里有误,【%JAVA_HOME%\bin】和【%JAVA_HOME%\jre\bin】不能两个两个连起来写,要分开
conda 启动报错 Invoke-Expression_windows10 conda invoke-expression : 所在位置 行:1 字符: 1-CSDN博客
切记!!切记!!!修改完系统变量后,PyCharm这边是不会自动更新的,要整个软件关掉、再打开,否则你再试个一百遍都是报错
关掉之后再打开,终端显示正常了:





3、最终验证是否成功
最后我们到(终端上两个,也就是第一个按钮)【Python 控制台】
再输入一次:【import torch】【torch.cuda.is_available()】,都没报错的话就大功告成!完美!!!!
输入一些python语法也正常运行




四、什么是数据集,以及初始Dataset
1、数据集
看了别的文章是这么说

这是一篇较详细的文章:什么是数据集?-CSDN博客
那么鄙人的粗浅见识认为:就是一堆给机器学习用的数据的集合,把人比做机器,那么数据集就是我们从出生到老死一直在听的、看的、吃的的一切的一切,我们看到蓝天知道天空是蓝色,我们闻到屎知道屎是香的,我们吃过老八秘制小汉堡才知道这玩意贼好吃......这一切的一切,都叫数据集,是这一切让我们有了我们人类的一套思考逻辑、判断逻辑、理解逻辑...当然这些还可以细分成各个领域,比如情感认知、学术知识、游戏体验......
那么这里提供一个数据集文件,以供我们后面学习用,大家可以自行下载
链接: https://pan.baidu.com/s/1JHnA4d0EU77r2ljeZlkCow?pwd=hrd4 提取码: hrd4
那么看这个文件下,就能大概知道这是干啥的
就是一些根据图片、文本label来“喂”给机器学习的数据集,一些资料





2、Dataset简单解释
那么Dataset又是什么?
我们把上面那个文件夹的文件当成你刚从毕业学长学姐那捡回来的一堆书、或者你从夸克上下载的一万部小电影,nei叫一个爽,但是,你也不是什么都学、什么都看吧?那堆书里有《厚黑学》、《圣经》、《c语言》、《计算机组成原理》.......夸克磁盘里有“猎奇”、“户外”、“直播录屏”、“兽..”、“欧美”...你不能一锅乱炖乱看吧?总得分个类吧?
那么Dataset就是这么个工具,帮机器把这对杂乱无章的数据分类整理,获取每个数据的label,并告诉机器一共有多少数据。

另外,我刚刚例子里说的那些:《厚黑学》、《圣经》、《c语言》、《计算机组成原理》.......“猎奇”、“户外”、“直播录屏”、“兽..”、“欧美”......这些就是数据集对应的【label】

五、初用Dataset
1、准备好数据集
把刚刚数据集里的【hymenopter_data.zip】解压
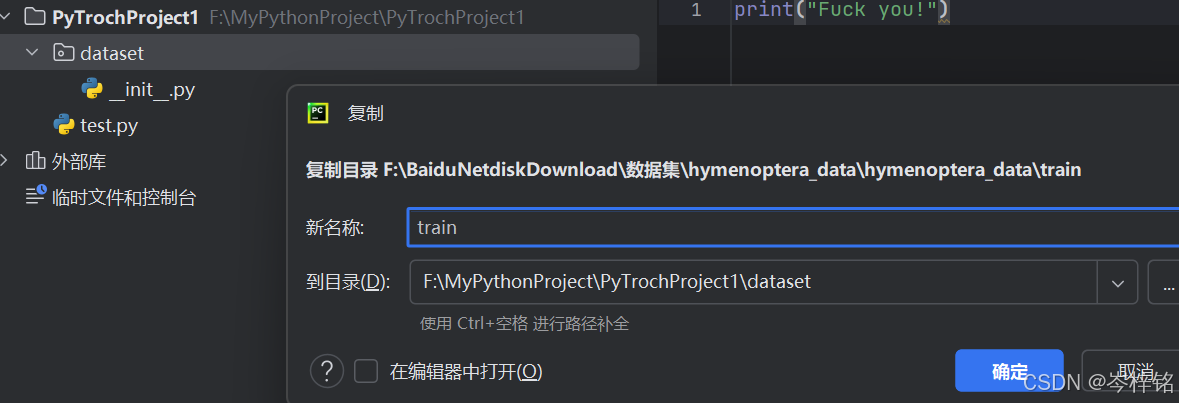
然后复制这个文件夹,直接粘贴到你的PyTorch的python项目里去,最好再新建一个目录叫“dataset”,专门用来放你的数据集的
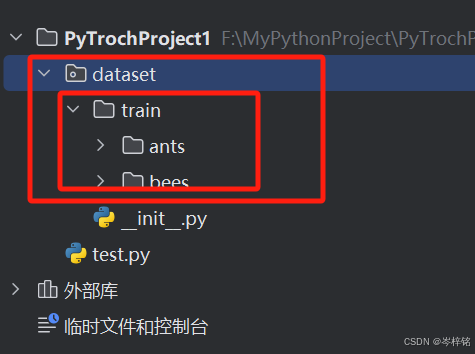
2、学会python的获取图片资源
接下来我们简单了解一下python怎么获取图片,使用图片
(1)首先要用到Image这个工具包,导入Image包
# 首先导入Image包
from PIL import Image(2)然后用一个变量获取某个图片的路径,绝对路径、相对路径都行,看你喜欢
# 然后用一个变量代替图片路径
imgPath = "你的图片路径"这里可以直接右键复制文件的路径
别忘了粘贴时这个【/】符号可能会自动变错,我们自己手动调回来



(3)然后调用Image这个工具的open函数,里面传入图片路径的作为参数,就可以用这个图片了
# 然后调用Image的open函数把图片解析,比用一个变量接收
img = Image.open(imgPath)(4)我们可以利用这个图片变量,调用它的属性、函数
比如打印大小
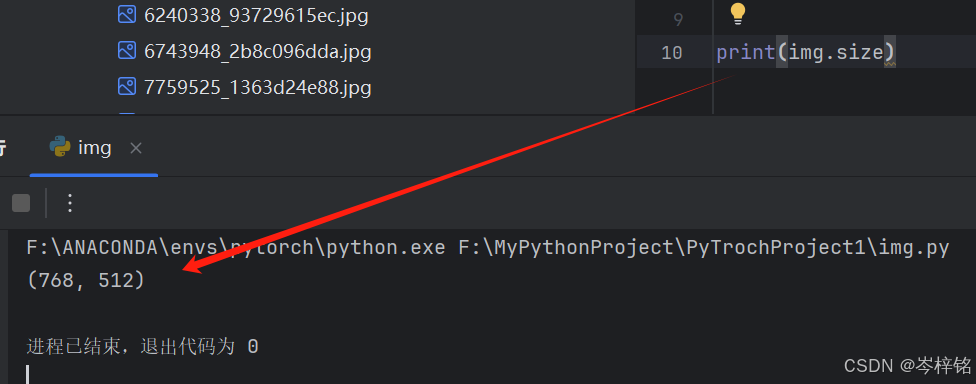
显示图片

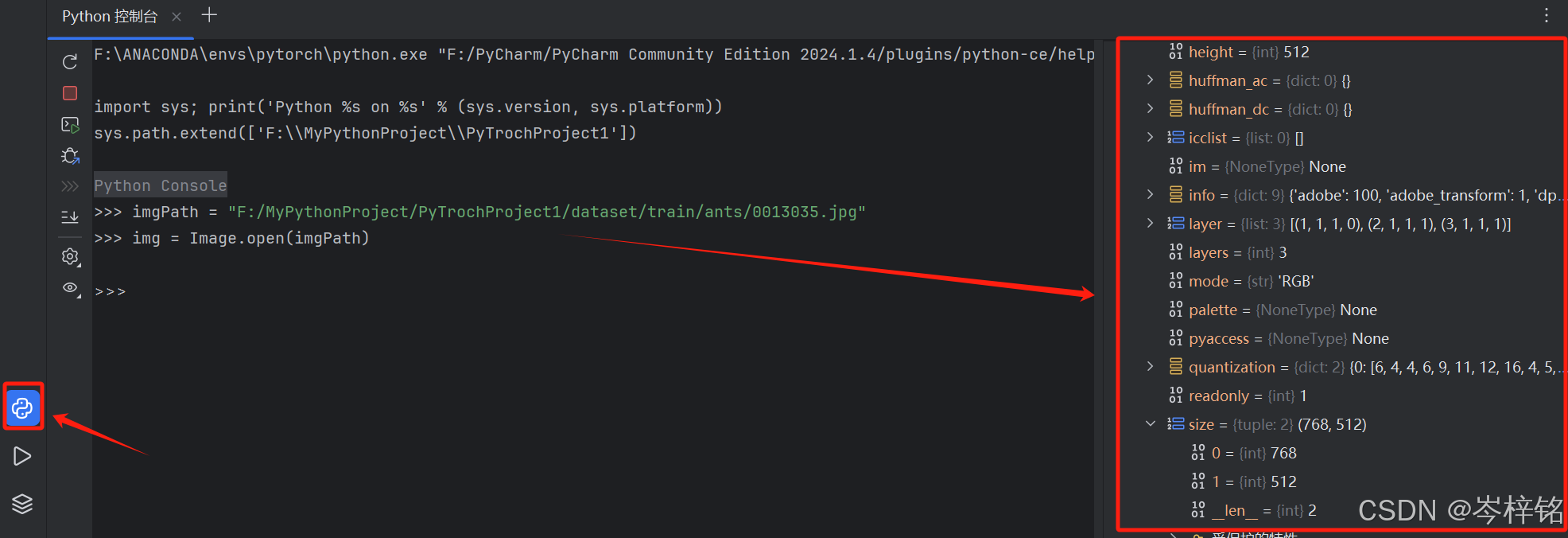
(5)另外:如果我们不知道它有哪些属性、函数可以调用,那么我们可以在【Python控制台】将刚才的python代码再写一遍,右边可以显示对应的属性、函数,方便我们查看
(我有写import PIL import Image,只是控制台隐藏了)
完整代码:
# 首先导入Image包
from PIL import Image
# 然后用一个变量代替图片路径
imgPath = "F:/MyPythonProject/PyTrochProject1/dataset/train/ants/0013035.jpg"
# 然后调用Image的open函数把图片解析,比用一个变量接收
img = Image.open(imgPath)
print(img.size)
img.show()3、利用os库工具获取所有图片
当然刚刚的Image只能对一个图片进行专门的处理,而要想获取所有图片资源,就得用到os这个工具包
1、导入os包
# 导入os包,获取存放所有图片的这个包
import os2、用一个变量接收【存放所有图片的这个包】的【路径】(绝对相对都行,这里我用相对)
# 用一个变量接收存放所有图片的这个包的路径
imgListPath = "你放所有图片的包的路径"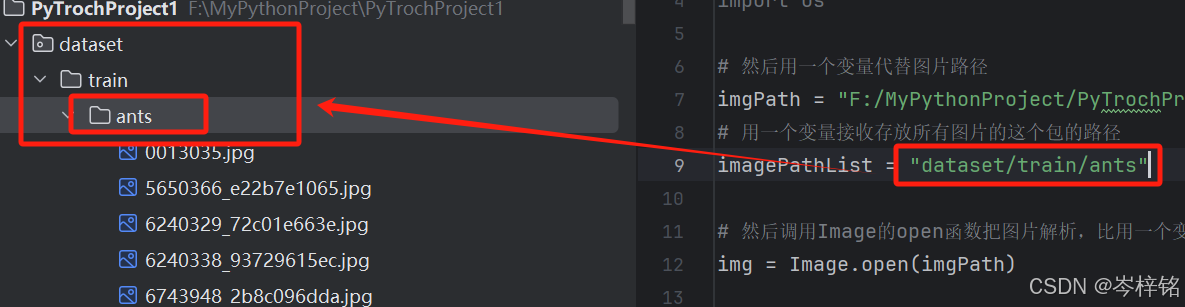
3、然后调用os的listdir函数解析获取这个包,并把存放所有图片的包的路径作为参数传入
# 然后调用os的listdir函数解析获取这个包
imgList = os.listdir(imgListPath)4、如果我们把代码写到【python控制台】,就能看到获取到所有图片,变成一个列表数据
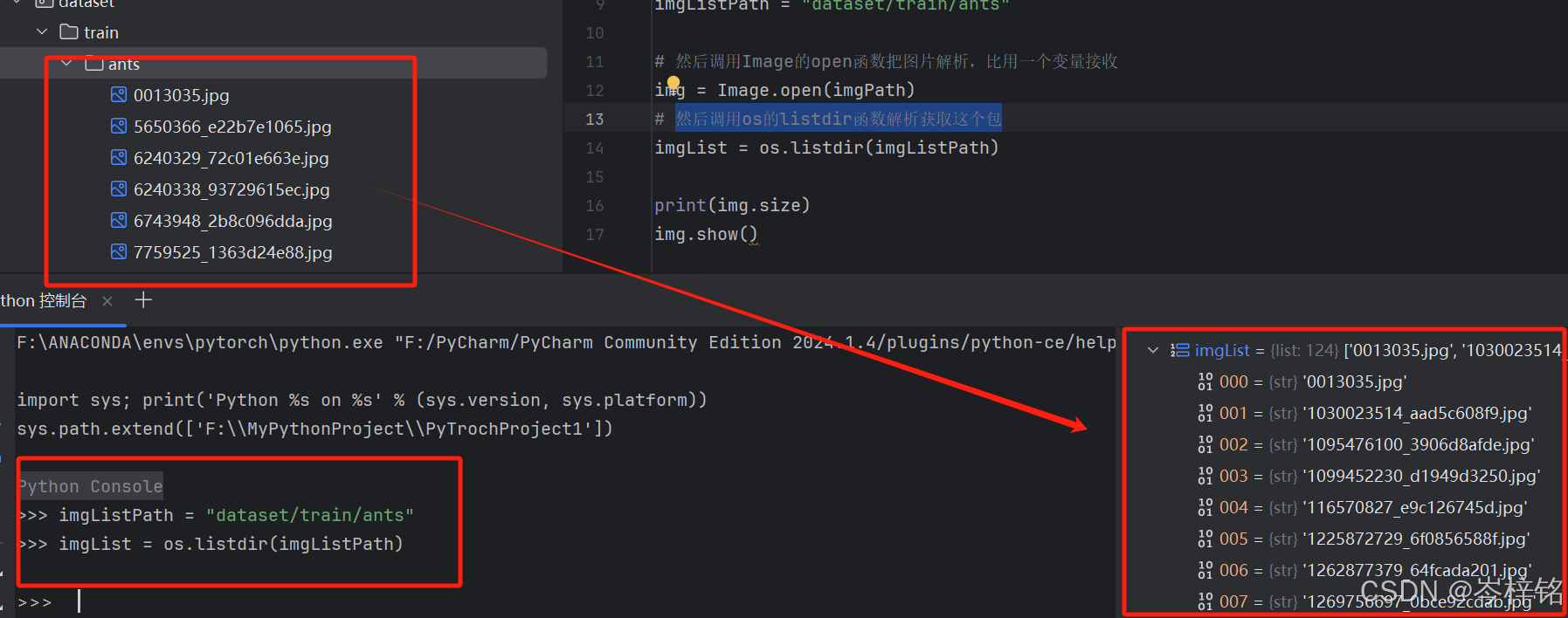
完整代码:
# 导入os包,获取存放所有图片的这个包
import os
# 用一个变量接收存放所有图片的这个包的路径
imgListPath = "dataset/train/ants"
# 然后调用os的listdir函数解析获取这个包
imgList = os.listdir(imgListPath)
print(imgList)
print(type(imgList))4、利用Dataset,把所有图片整合成一个数据集并分类
(1)在这之前补充一下几个知识点
python的类里面可以不用定义成员变量,在函数里想用到的时候【self.成员变量】,就自动加上了
class myClass:
def createName(self):
# 并没有定义name这个变量,但是我直接在函数里加一个
self.name = "KOBE"
classA = myClass()
print(classA.name) #照样打印出来然后【__init__】是构造函数
# 构造方法
def __init__(self, name=None, age=None, sex=None, phone=None):
self.name = name
self.age = age
self.sex = sex
self.phone = phone
if name is not None and age is not None and sex is not None and phone is not None:
print("构建一个完整对象完毕\n")
else:
print("构建一个空对象完毕\n")【__setitem__函数】、【__getitem__函数】
【__setitem__函数】允许外界根据【索引】设置构造函数里【数据容器】类型成员变量的值
【__getitem__函数】提供索引,允许外界根据【索引】或【切片】形式获取【数据容器】类型成员变量的某个位置值
class myClass:
# 构造函数并没有传参,也即是一个空参函数
# 而items也并不是在函数外定义的一个类的成员变量,而且是【数据容器】类型(列表、元组、字典...)
# 那就没有办法根据索引给这个items某个位值设置值
def __init__(self):
self.items = []
my_class = myClass()
my_class.items = [1, 2, 3, 4, 5]
my_class.items[1] = 23 # 报错,不允许根据索引设置构造函数里设置的成员变量list
#####################################################
class myClass:
def __init__(self):
self.items = []
def __getitem__(self, index):
return self.items[index]
# 利用__setitem__方法,提供给外界允许根据【索引】设置构造函数里定义的【数据容器】值的权限
def __setitem__(self, index, value):
self.items[index] = value
my_class = myClass()
my_class.items = [1, 2, 3, 4, 5]
# 使用索引方式设置元素
my_class.items[1] = 10 # 成功
print(my_list.items) # 输出: [1, 10, 3, 4, 5]
【__len__】是魔法函数里的求长度函数
# __len__魔术方法:返回长度
def __len__(self):
return len(self.name)(2)正式写Dataset代码
首先,导入Dataset的包
from torch.utils.data import Dataset然后别忘了导入Image和os包,获取图片
# 导入Image包
from PIL import Image
# 导入os包,获取存放所有图片的这个包
import os然后,现在我们就可以创建一个专门管理数据集的类了,只需要在创建普通类的基础上,加一个括号,里面传入Dataset这个参数,这就是一个Dataset的类了
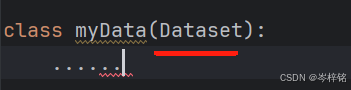
接下来我们细细分析一下我们所需要的东西
【获取所有文件的路径】
。
【其中这两个文件夹名字就是我们要的label】
一个表示“蚂蚁”,一个表示“蜜蜂”
‘
【我们确切要拿到的每一个数据】





那么我们就可以理清一下思路:
1、首先我们要获取到存放所有文件的目录的路径
2、这个路径还不能直接直接固定死,要分开,因为我们要单独取出装有两类不同文件的文件夹的名字,作为数据集的【label】
3、我们要把“蚂蚁”、“蜜蜂”这两个数据分类里的所有文件,分别存到两个数据列表;然后在外界我们可以根据索引,单独取出列表中的其中一个图片资源
4、最后,我们要把两个数据分类整合成一个数据集,交由Dataset来管理即可
那么第一步就是创建一个Dataset类,然后在类里面处理好获取所有数据的逻辑,然后一个代表【蚂蚁】,一个代表【蜜蜂】,在外界根据传入不同的路径参数来获取不同的数据,最后整合到一起。
ok,来写代码!
完整代码:
#导入Dataset
from torch.utils.data import Dataset
# 导入Image包
from PIL import Image
# 导入os包,获取存放所有图片的这个包
import os
class myData(Dataset):
def __init__(self, rootPath, labelPath):
# 用变量接收外界传入的路径参数,其中labelPath是对应【蚂蚁】或【蜜蜂】
self.rootPath = rootPath
self.labelPath = labelPath
# 利用os的.path.join()函数,把路径拼接起来(比如xxx和aaa,会自动在中间加一个"/",变“xxx/aaa”)
self.path = os.path.join(self.rootPath, self.labelPath)
# 最后利用os的listdir解析这个包路径下所有文件,并用一个数据列表接收
self.imgListPath = os.listdir(self.path)
print(self.imgListPath) #输出对应label路径下的所有图片的list
# 根据索引获取到单独某个图片资源、图片名、图片label
def __getitem__(self, index):
# 获取当前index位置的图片名、以及解析图片资源
# 这里注意:完整的图片路径是【存放所有图片的包路径(rootPath + labelPath)】+【单个图片的路径】
imgName = self.imgListPath[index]
# imgPath = self.imgListPath[index]
imgPath = os.path.join(self.rootPath, self.labelPath, imgName)
img = Image.open(imgPath)
# 取出它属于哪个label
label = self.labelPath
return img, label
# 利用__len__函数,返回当前这个label分类的图片列表一共有多少条数据
def __len__(self):
return len(self.imgListPath)
rootPath = "dataset/train"
labelPath1 = "ants"
labelPath2 = "bees"
# 传入不同的label的路径,获取创建两个数据集(【蚂蚁】和【蜜蜂】)
ants_dataset = myData(rootPath, labelPath1)
bees_dataset = myData(rootPath, labelPath2)
# 用多返回值就用多变量接收
ant_img, ant_label = ants_dataset[1]
bee_img, bee_label = bees_dataset[1]
# 调用测试一下能不能显示一张蚂蚁和一张蜜蜂的照片
ant_img.show()
bee_img.show()
# 最后,Dataset的整合数据集的大绝招:两个数据集(Dataset类)相加
train_dataset = ants_dataset + bees_dataset
# 验证一下,分别输出两个数据集有几条数据,再看一下整个数据集有几个数据
print(len(ants_dataset)) # 124
print(len(bees_dataset)) # 121
print(len(train_dataset)) # 245 = 124 + 121这里我感觉我的注释足够清晰,我觉得我再多余写过多的文字反而不如看代码来得清晰,所以我在过多阐述......
那么到这,我们就算完成了初步的一个用Dataset整合机器学习所需要的数据集了
那么其实通常情况下,我们还会专门区分图片是图片,label是label,专门有一个label文件夹,里面存放所有对应每一张图片名的txt文件,而里面的内容就是它这个数据所归属的label名


这种形式的数据集又需要重新编写代码,请各位自己写,我累了...