7月24日,阿里云飞天发布时刻产品发布会围绕阿里云大数据AI平台的新能力和新产品进行详细介绍。人工智能平台PAI、云原生大数据计算服务MaxCompute、开源大数据平台E-MapReduce、实时数仓Hologres、阿里云Elasticsearch、向量检索Milvus等产品均带来了相关发布的深度解读。
大数据AI一体化趋势解读
在AI大模型爆发的时代,如何将大数据和AI进行更好的融合是阿里云今年重点探索的课题。阿里云大数据 AI平台产品负责人徐晟带来了阿里云大数据 AI一体化趋势分享和产品矩阵解读。
徐晟认为,大数据技术的经历了从传统数仓到数据湖,再到数据湖仓一体的演变历程。建设真正的数据湖仓一体,关键在于统一数据湖存储的数据表格式以及统一数仓读写湖数据的SDK。这样,数据湖上各类数仓引擎无需自建仓内存储,整个湖仓系统中只有一份大数据(One-Copy)被数仓调用,进而达到性能与成本的优化。此外,在数据湖上,除了表格文件,还有文本、图片、视频等各类非结构文件,在大模型训练环节也是至关重要的生产资料,通过上述One-Copy的方案,可实现AI计算引擎对数据的灵活调用,推动大数据与AI更好地融合。
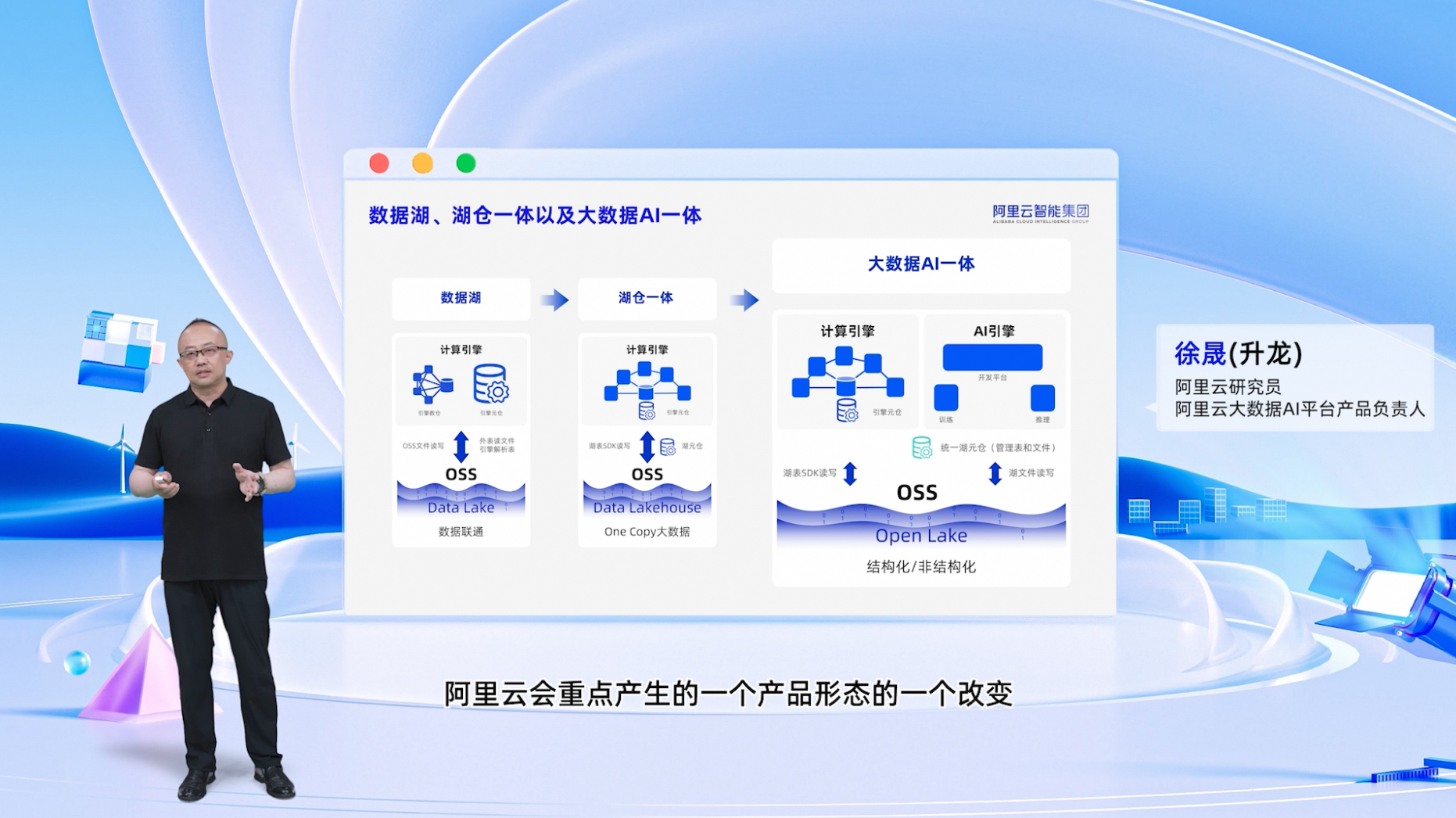
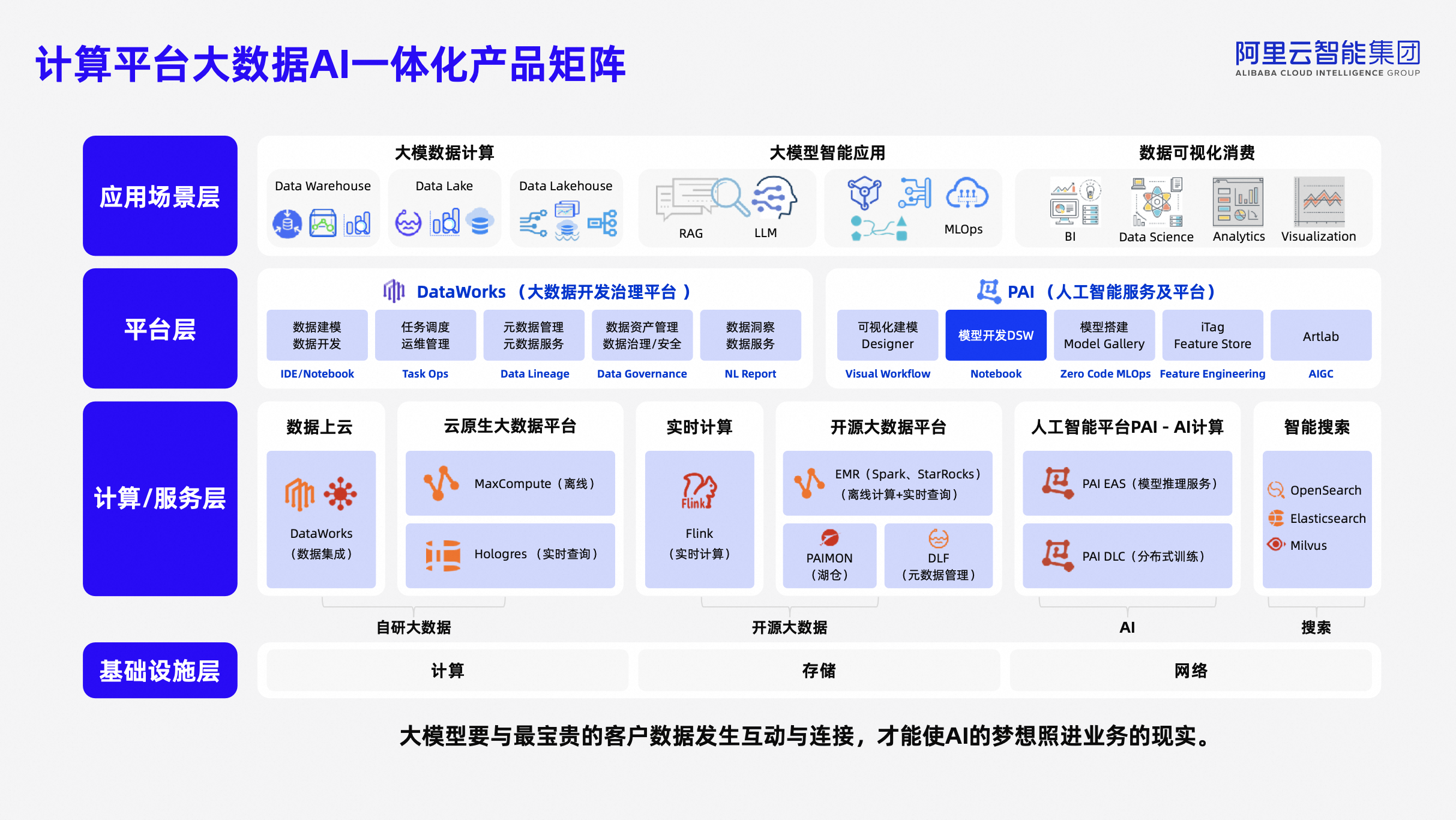
阿里云大数据和AI产品体系中,包含批处理、流处理、实时交互式查询在内的大数据计算引擎服务,AI训练和推理引擎服务,以及上层的大数据和AI开发平台。在此之上,今年阿里云将推出统一的大数据和AI湖仓能力支持,实现整个系统内数据的高效计算和流转。未来,阿里云将继续在大数据和 AI 领域深耕,为用户带来更优质、高效的服务和体验。
人工智能平台PAI升级发布
阿里云人工智能平台PAI,是一款是面向开发者和企业的机器学习/深度学习工程平台,底层与阿里云基础设施无缝衔接,中间层即 PAI 的产品主体提供了数据标注、模型构建、模型训练、模型部署、推理优化在内的AI工程全链路服务,上层无缝衔接 ModelScope、ModelStudio 等各类 MaaS 平台。人工智能平台PAI在训练服务、推理服务和AIGC场景化实践三方面带来了相应的能力升级。
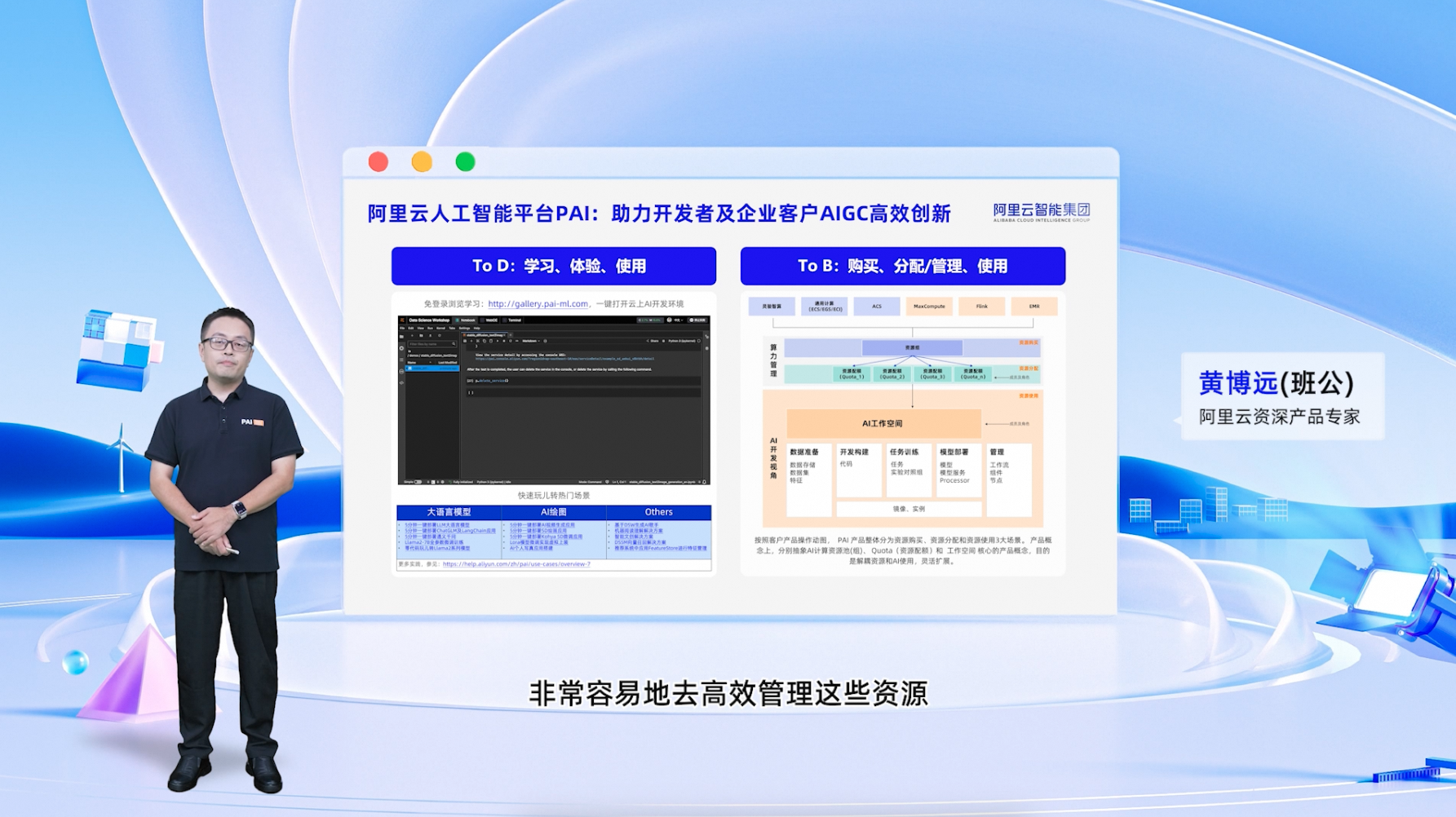
AI训练服务
-
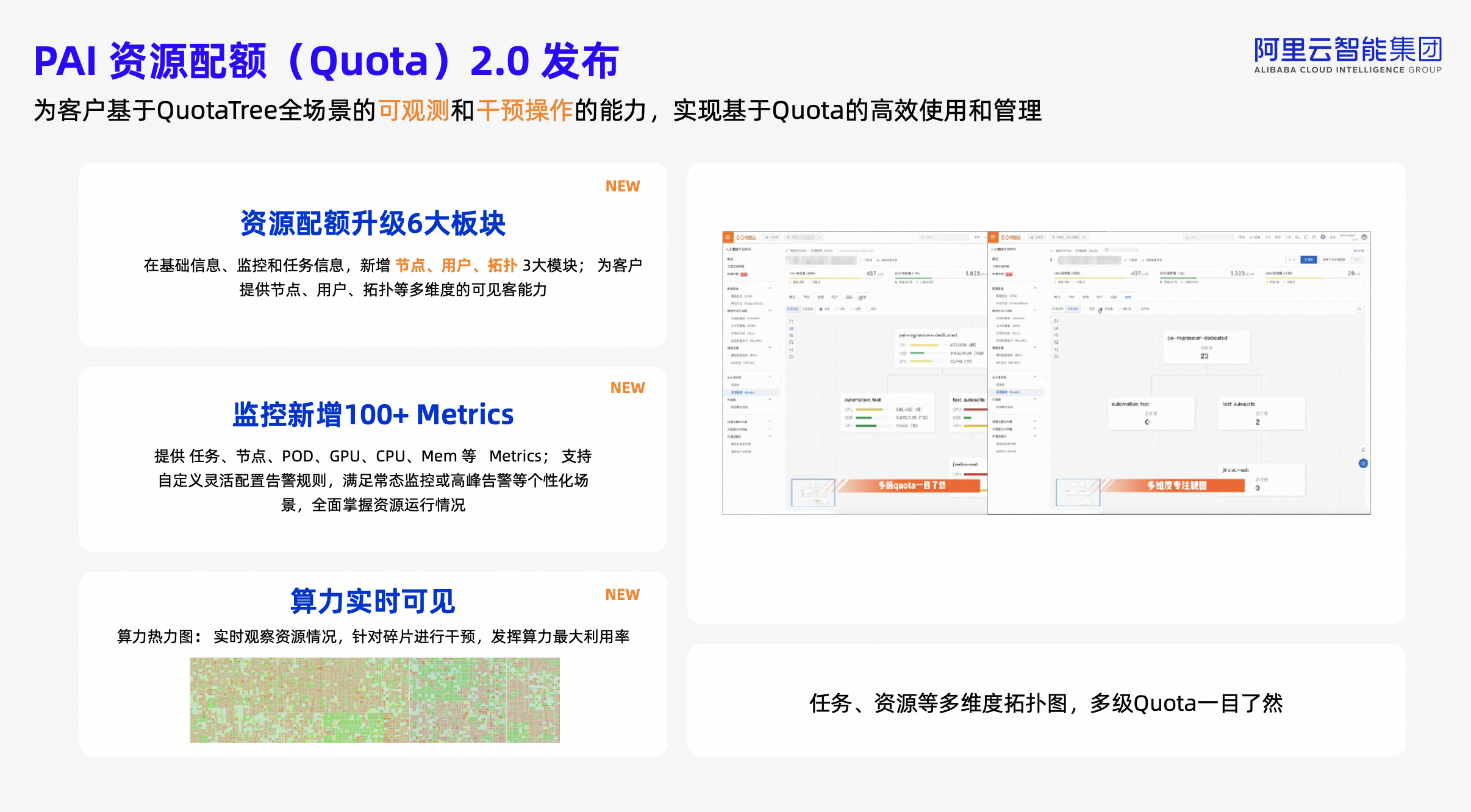
发布资源配额 (Quota) 2.0,提供基于 QuotaTree 全场景的可观测和干预操作能力,支持对训练、推理、开发等多类型任务进行统一的资源监控和管理,并新增了节点、用户、拓扑3大模块进行多维度展示。此外,PAI 资源配额模块增加了任务、节点、POD、GPU、CPU、Mem 等100多项监控 Metrics,满足常态监控和自定义监控和告警需求。企业内部的资源使用情况,通过多维拓扑图实时清晰展现。
-
发布训练竞价任务 (Spot) ,提供任务级别的高可用、高性价比算力,配合PAI平台的自动容错和状态恢复能力,兼顾性价比与稳定性。该功能适用于处于探索期的新业务,以及对时延不敏感的任务。
AI推理服务
-
PAI-EAS 在日本 Region 开服,PAI-EAS 累计覆盖全球16个 Region,包括欧洲、北美、东南亚等海外地区。
-
PAI 异构算力集群全面升级至第8代,支持 H20、L20 等全新机型。
-
推出多规格抢占型实例、GPU资源共享、serverless模型服务在内一系列全新的服务模式,保证业务在线率的同时降低部署成本,最高可降本90%。

AIGC场景化最佳实践
-
PAI-ArtLab 是为设计专业人士打造的AIGC智能设计平台。PAI-Artlab 支持 ComfyUI 创作工具,支持用户以workflow模式进行图像或视频创作。PAI-Artlab 提供单机版和 Severless 版两种模式,开箱即用。与开源社区版本相比,PAI-Artlab 进行了针对性的推理性能优化,模型加载速度和出图速度实现2~3倍提升。此外,PAI-Artlab 还提供主子账号管理、生成内容合规等企业级能力。
云原生大数据计算服务 MaxCompute 升级发布
MaxCompute 是面向分析的企业级 SaaS 模式云数据仓库,以 Serverless 架构提供快速、全托管的在线数据仓库服务,为大模型时代提供大数据AI一体化的数据基础。
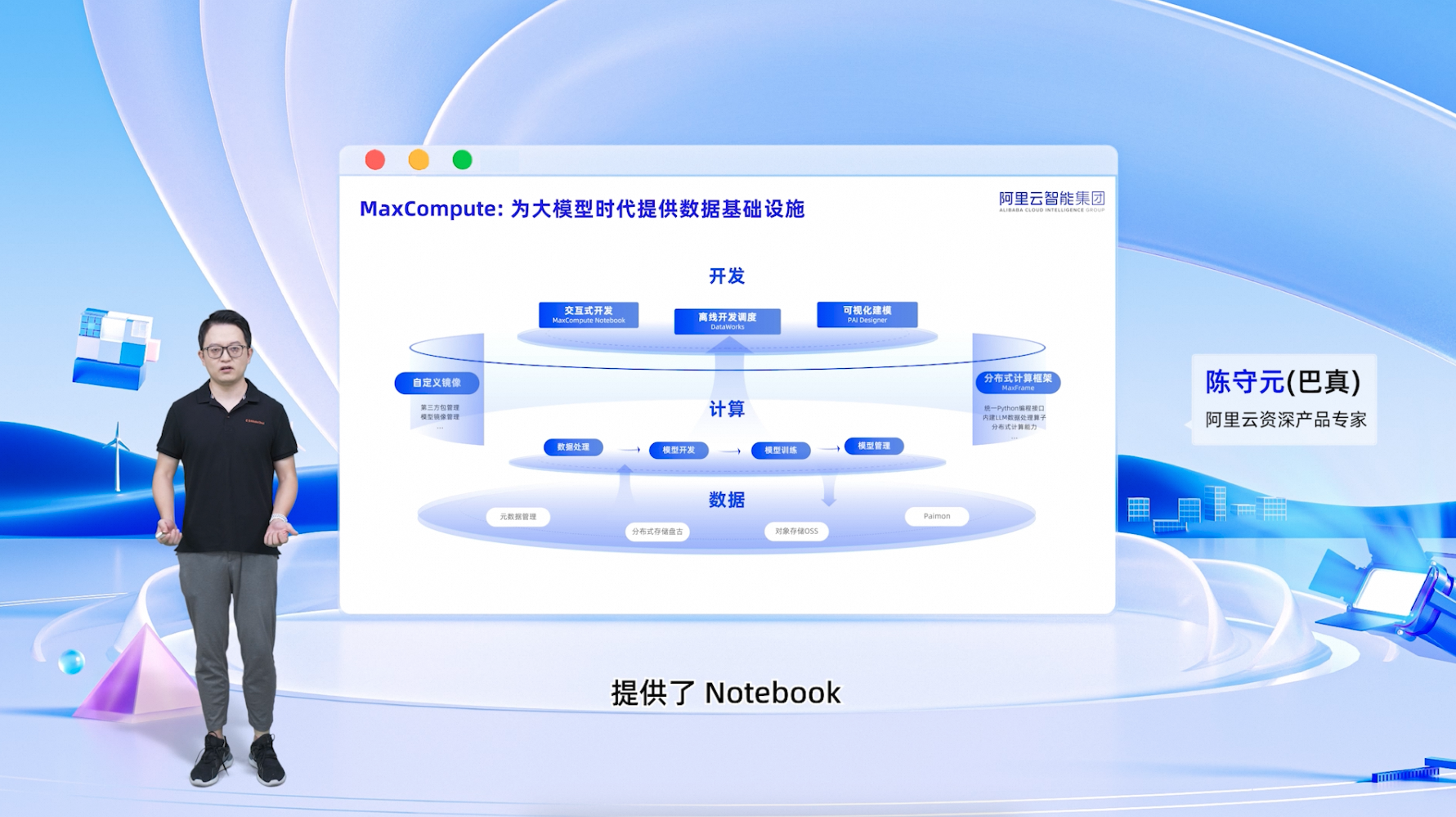
分布式计算框架 MaxFrame
MaxFrame 是阿里云自研的分布式计算框架,支持 Python 编程接口并可直接复用 MaxCompute 计算资源及数据接口,用户可以以更熟悉、高效、灵活的方式利用 MaxCompute 的海量数据计算资源及数据进行大规模数据处理,可视化数据探索分析以及科学计算、ML\AI 开发工作。

优化非结构数据管理 Object Table
湖仓一体为大数据AI提供了自研离线近实时数据处理的计算引擎,各类数据统一管理,计算引擎统一对接。针对一些非结构化数据或半结构化数据,MaxCompute 通过 Object Table 进行相关抽像。
Object Table 优势特点:
-
使用灵活,以表的形式管理非结构化数据,使用高效统一,通过 SQL、Python 对作业进行修改、发布,操作简单。
-
缓存加速,缓存对象列表和元信息,减少直接访问 OSS,基于事务表记录每次更新,实现元信息版本化。
-
查询优化,查询实现列裁剪、过滤条件下推,减少数据访问,支持按照数据对象实际切分,消除数据倾斜。
-
写入支持,支持数据写入能力,形成数据流闭环。
EMR Serverless 产品升级发布
E-MapReduce(以下简称:"EMR")Serverless 为企业提供开源、开放、开箱即用的全托管免运维开源大数据产品。
随着数字化进程的加速,企业对数据分析的需求越来越强烈,然而实际操作中往往会面临一系列问题及挑战,常见的问题有数据栈割裂,数据整合统一难,形成数据孤岛,分析效率低下,不同数据栈有不同的元数据和治理模型。其次是自建难,需要投入大量的成本和资源,以及平台优化与扩展复杂,版本迭代依赖开源社区,没有专业技术团队支持。此次 EMR 产品发布了 Serverless Spark 和 Serverless StarRocks 两项新能力。

EMR Serverless Spark 面向企业数据分析的计算产品
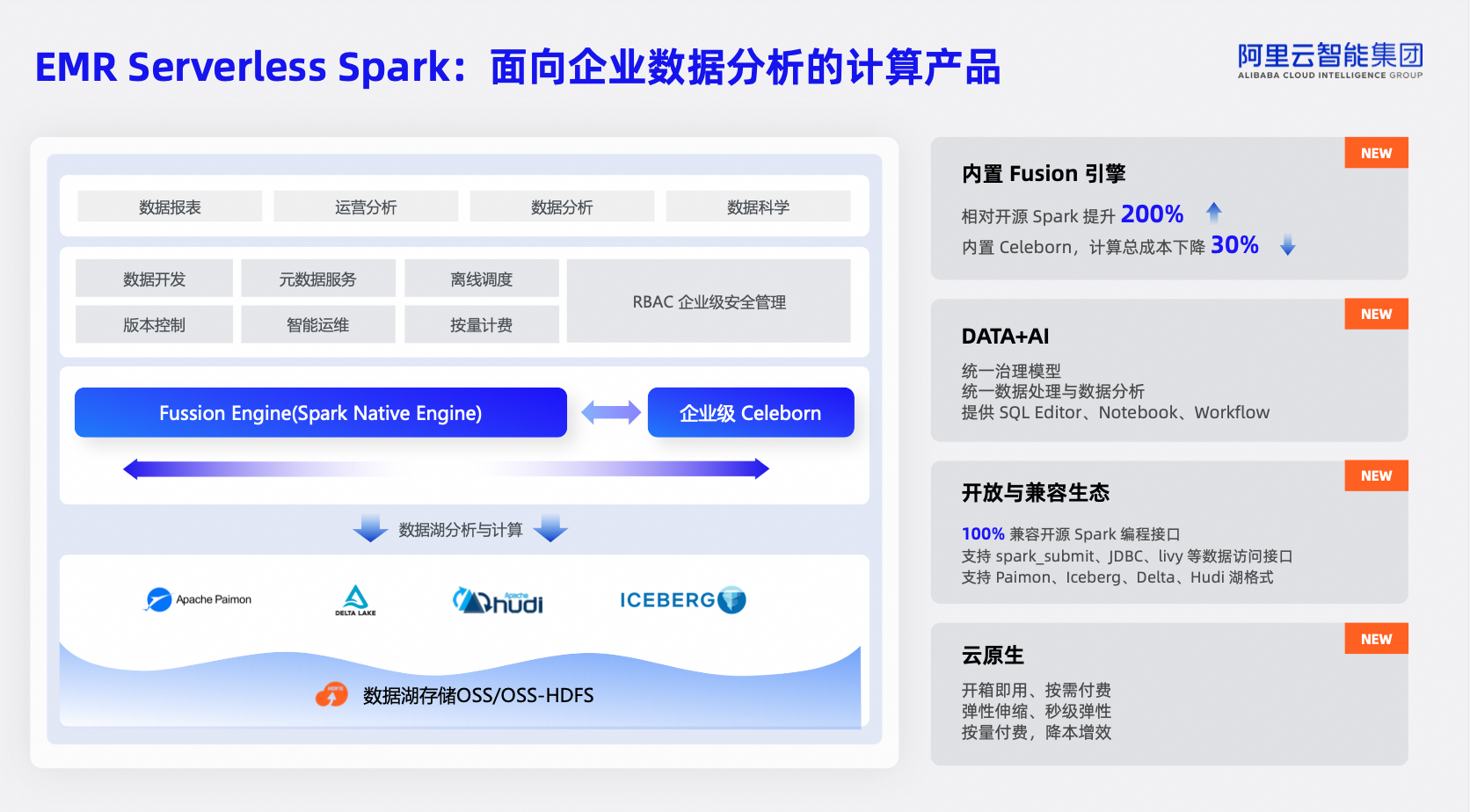
阿里云 EMR Serverless Spark 版是一款云原生,专为大规模数据处理和分析而设计的全托管 Serverless 产品。它为企业提供了一站式的数据平台服务,包括任务开发、调试、调度和运维等,极大地简化了数据处理的全生命周期工作流程。
-
内置 Fusion 引擎,性能相较开源 Spark 提升 200%,同时内置 Celeborn,使计算总体成本下降 30%,大幅提高计算效率。
-
实现 DATA+AI 统一治理模型,将数据处理和数据分析相结合,提供 SQL Editor、Notebook、Workflow 等工具,助力用户进行数据分析和 AI 应用开发。
-
具有开放与兼容的生态,100%兼容开源 Spark 编程接口,支持多种数据访问方式和湖格式。
-
云原生特性显著,开箱即用、按需付费、弹性伸缩,降低使用门槛和成本。
EMR Serverless Spark 结合 Fusion Engine 和企业级 Celeborn,为企业提供了全新的数据分析体验,助力企业更高效地挖掘数据价值。
EMR Serverless StarRocks 数据湖分析版发布
EMR Serverless StarRocks 数据湖分析版是一款基于 StarRocks 技术构建的企业级数据查询和分析产品,具备开箱即用、弹性扩展、监控管理、慢 SQL 诊断分析等全生命周期能力。具备开箱即用、弹性伸缩、兼容 Trino/Presto 语法格式、统一的 Catalog管理、支持 Hive 格式 Paimon/Iceberg/Hudi/Delta Lake 等多种数据湖格式、极致的湖仓分析性能等能力。
此次 EMR Serverless StarRocks 数据湖分析版发布以下功能:
-
弹性伸缩发布,可按需使用,降低计算成本。可应用在业务负载存在时间周期性变化场景,比如AdHoc即时分析场景和ETL加工等场景。
-
多计算组(Multi-Warehouse)发布,实现资源隔离、数据共享、灵活扩缩容,按需弹性伸缩功能。可应用在不同类型任务资源隔离,跨部门协调分析等场景。
StarRocks 的一系列创新,将为湖仓分析领域带来全新变革,为用户提供更高效、可靠、便捷的服务。

实时数仓 Hologres产品发布
Hologres 是阿里云自研的一站式实时数仓引擎,支持海量数据写入、实时更新、实时分析、写入即可查,支持标准的SQL协议,支持PB级数据多维分析和即席分析,支持高并发、低延迟的在线数据服务。与 MaxCompute、FLink、DataWorks 无缝集成。与 DLF、OSS 深度融合,提供离在线一体全栈数仓和湖仓一体的解决方案。支持丰富的开发接口,支持对接十余种主流BI。

Hologres Serverless Computing
Serverless Computing,提供大作业隔离与弹性处理,并降低 20% 成本。通过共享 Serverless 资源执行DML任务,保证大任务隔离与高可用,降低成本并提升性能。同时支持设置单条 SQL 使用 Serverless 的资源上限,支持设置使用 Serverless 资源的SQL优先级。
Hologres 2.2 版本发布
引擎能力优化
-
TPC-H 性能测试结果相对V1.X提升 100%
-
向量执行引擎 HQE 能力提升,Runtime Filter 能力增强
-
查询优化器性能提升,SQL 在 Plan 阶段的处理速度提升 40%。
实时湖仓架构升级
-
湖仓一体,架构升级直读 OSS 性能提升5倍以上,支持 Paimon 湖格式,支持多级缓存和谓词下推过滤。
-
实时离线一体,直读 MaxCompute 存储、支持百万/秒 MaxCompute 与 Hologres 之间同步数据,及更多兼容性能力提升。
新增多种高级函数,行为分析、画像分析能力全场景覆盖
-
新增路径分析、留存分析、漏斗分析、画像分析等多种函数,提升分析性能与效率。
-
Hologres 相比 ClickHouse 和 Doris 等开源技术栈在各场景分析上提供了完整函数,能高效实现行为分析和画像分析,助力业务获取商业洞察。

阿里云Elasticsearch-AI搜索产品发布
1.Elasticsearch-AI搜索
Elasticsearch-AI 搜索拥有丰富的 AI 搜索能力,基于效果更优的 RAG 全链路模型,加强数据预处理及检索增强能力,支持不同场景的业务应用。以搭建 RAG 场景为例,在数据写入时对知识库内容解析处理,在线查询时进行检索增强。使用自研模型准确解析多样化企业知识库数据,切分文档并生成向量,构建索引。用户搜索查询时,通过模型理解意图,进行三路混合检索和重排获取相关内容,补全上下文形成最终答案。完成 RAG 全链路搭建后可进行测评。

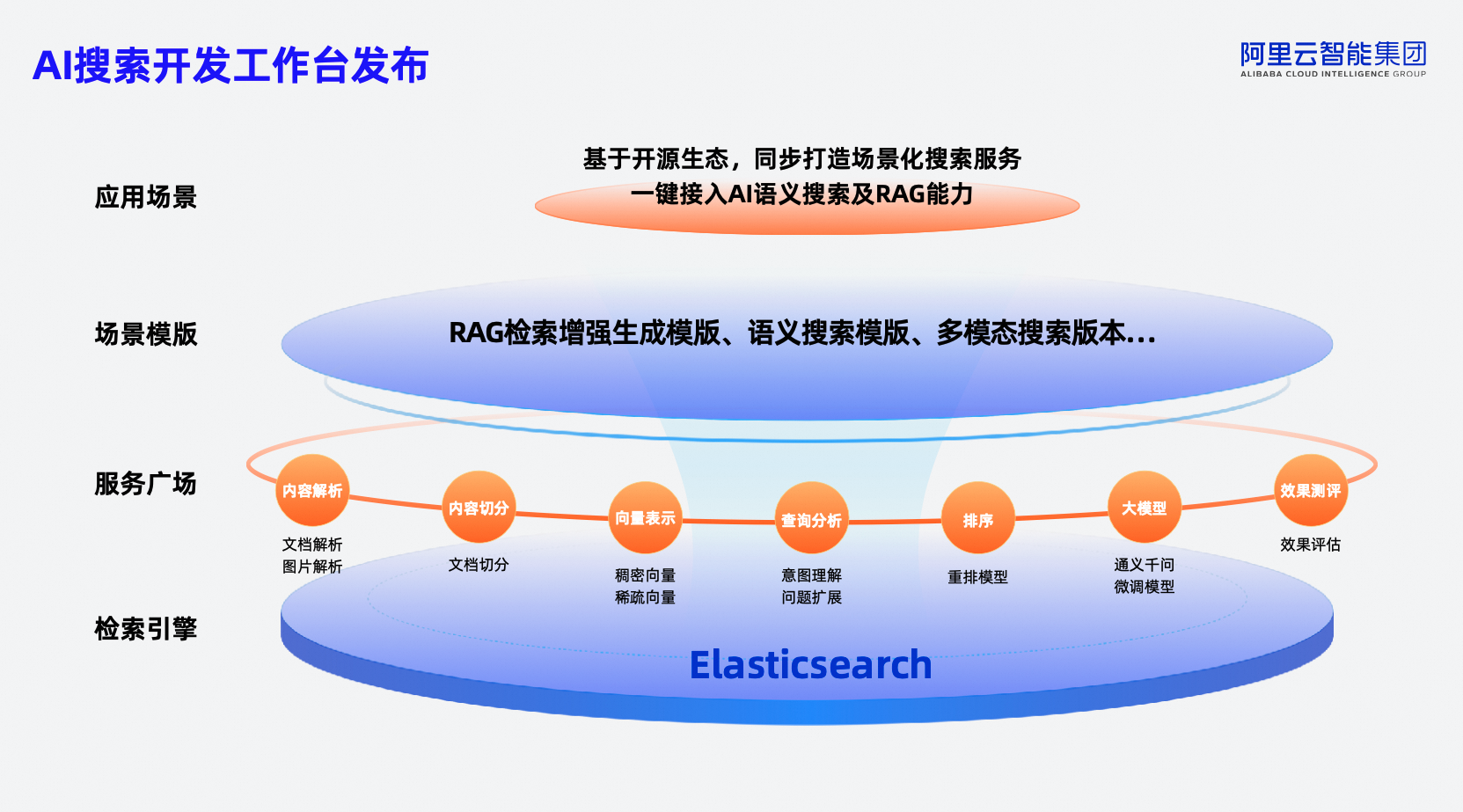
2.搜索开发工作台
阿里云搜索开发工作台内置数据处理、查询分析、排序、效果测评、大模型等服务,结合阿里云搜索引擎及开源引擎,同步打造场景化搜索服务,一键接入 AI 语义搜索及 RAG 能力,帮助企业灵活搭建符合自身业务需要的搜索系统。在实际应用中,AI搜索开发工作台能够兼容主流开源生态,能快捷搭建语义搜索及 RAG 链路,客户全链路效果随使用能力加强显著提升。阿里云 AI 搜索支持三路混合检索和多路召回,结合重排模型可使准确率达 95%。
向量检索服务 Milvus 版新品发布
阿里云向量检索 Milvus 版是阿里云提供的 Serverless Milvus 全托管服务,100% 兼容开源 Milvus,提供高性能、可扩展、大规模 AI 向量数据库相似性检索服务,具备开箱即用、弹性可扩展、全链路监控告警的能力,同时提供开源 Attu 的可视化工具。
阿里云向量检索 Milvus 版具有以下优势:
-
云原生极速向量检索服务
阿里云向量检索 Milvus 版集成了 Vector 检索库,凭借其高性能、高可用性的特点,支持混合查询,为用户提供高效且稳定的向量数据检索能力。集成商业化内核,相同场景下引擎性能(QPS)是开源社区版的10倍,召回率一致的情况下QPS有5倍提升,而综合考虑QPS和召回率也可实现8倍的提升。同时对计算、存储资源进一步降低,可达到至少30%的自建Milvus上云成本缩减。
-
企业级运维及易用性
云上全托管的向量数据库服务,不仅极大地缩减了集群维护成本,而且开箱即用,内置配置管理、安全管理等功能,并通过云原生架构实现高性能、可扩展性,支持按需节点化伸缩能力;同时,还提供了全面可视化的监控告警链路,以确保系统稳定运行及高效运维。
-
兼容开源 Milvus 生态
阿里云向量检索 Milvus 版全面兼容开源 Milvus 系统,提供了 Attu 等丰富的开源管理工具,更拥有丰富且活跃的生态社区资源。
在多模态检索方面,结合 AI 推理、训练等工程平台和 Embedding 模型的能力,Milvus 可高效索引和检索不同类型的数据,支持快速精准地跨媒体类型进行信息检索,并提供强大的扩展性和灵活的接口。
智能问答&大模型中,Milvus 结合大型语言模型实现智能问答系统,通过向量化处理用户查询,利用其高效检索功能快速匹配“私有知识库”中的信息,并结合大模型,生成准确回应,提供即时、精确、交互式的生成式搜索服务。
了解更多飞天发布内容:飞天发布时刻20240724