笔记整理:韩林峄,天津大学博士
论文发表期刊:Transactions on Software Engineering and Methodology (TOSEM)
动机
软件漏洞对推进漏洞分析和安全研究具有巨大的潜力,人们往往使用自然语言来描述软件漏洞的关键特征,并在其中混合了特定领域的名称或概念,这使得自动分析文本中嵌入的漏洞知识成为一个重大的挑战,现有的方法需要花费大量精力进行手动数据标注以进行模型训练。因此,本文提出了一种无监督的方法来标记和提取文本漏洞描述(TVD)中重要的漏洞概念,通过提出一个源-目标神经网络模型来进行词性标注,实验显示此标注器优于(4.45%-5.98%)基于自然语言概念设计的标注器,使用Categorical Variational Autoencoders (CaVAE)将离散路径投影到一个低维的潜在空间中并通过聚类生成相同类型概念的集群,实验显示聚类结果中漏洞概念的准确率为83%-89%。在本文中,通过概念分类和序列标记模型来证明无监督标注概念的有效性,实验显示,使用我们的无监督标记的漏洞概念训练的模型表现优于(3.9%-5.14%)先前工作中使用手动标注数据集训练的模型。
亮点
本文的亮点主要包括:
(1)提出了一个源-目标神经网络模型,该模型在特定领域上进行词性标注;
(2)设计并实现了一种无监督的机器学习技术,该方法能够标记并提取TVD中重要的漏洞概念;
概念及模型
基于短语的漏洞概念类型
在TVD中描述漏洞特征的概念通常是名词短语。表1展示了六种类型的基于短语的漏洞概念以及在文中旨在提取的一些具有代表性的示例。

模型结构
为了以无监督的方法来标注和提取文本漏洞描述( TVD )中的重要漏洞概念,本文提出的模型主要由四部分组成,整体框架如下:
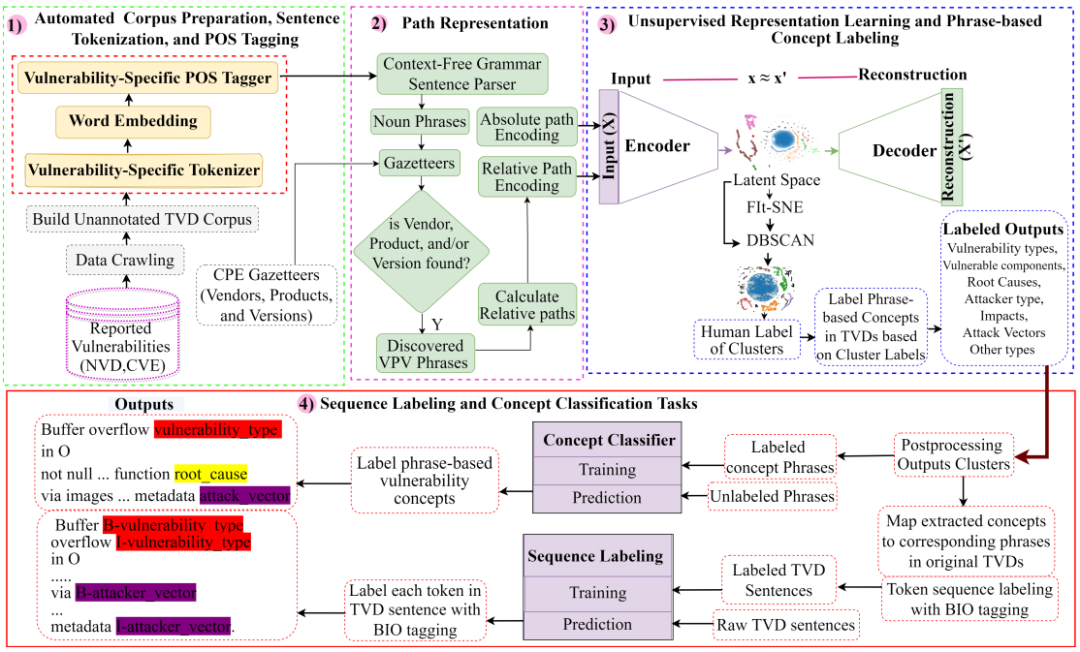
主要由四部分组成:
1)句子标记化、词性标注和句法分析:对TVDs中的句子进行词性标注与句法分析,用于下一步的路径表示。
2)路径表示:本文发现,对于相同类型的短语,不管它们在句子结构和短语表达上如何不同,它们在句法分析树中通常具有相似的句法路径,因此为每个非VPV短语构造了一条绝对路径和一些相对路径。
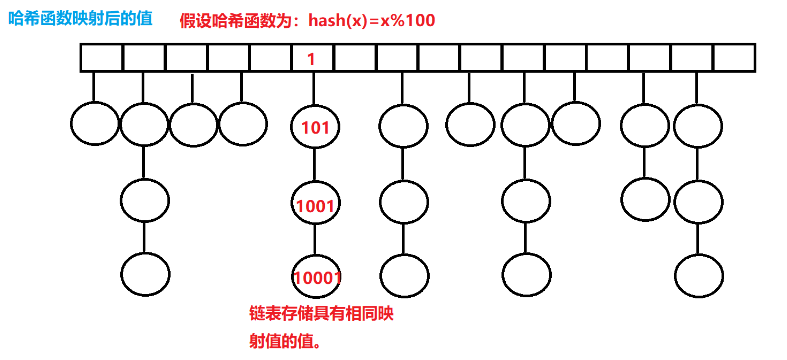
3)无监督的概念标注:其将每个不同的路径视为词汇表中的一个单词,并使用Categorical Variational Autoencoders (CaVAE)将离散路径(即高维one-hot向量)投影到一个低维的潜在空间中,该空间中的路径相似性可以用欧氏距离来衡量。之后根据非VPV短语在潜在空间中的紧密程度对它们进行聚类。本文使用三种不同的聚类设置:CaVAE → Fit-SNE,CaVAE → Fit-SNE → DBSCAN和CaVAE → DBSCAN分别进行测试。
4)有监督的概念提取:前面的无监督标记方法提供带有概念类型的标记漏洞短语。为研究通过无监督标记获得的漏洞短语对于机器学习任务的适用性。这里采用两种有监督的概念提取方法,分别是概念分类和序列标记方法,以确认无监督标记的漏洞短语的质量。
实验
数据集
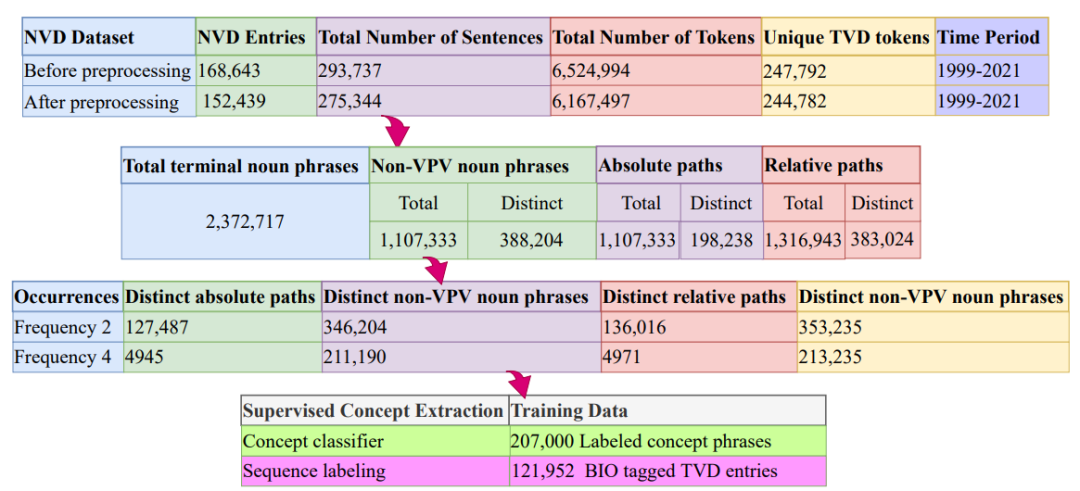
作者设计了一个Web爬虫来从NVD网站自动抓取并构建一个TVD语料库,语料库的数据统计信息如下所示:
模型表现
为了验证模型的有效性,文中进行了大量实验
1)词性标注(Parts-of-Speech Taggers):

结果表明,特定于漏洞的POS标记器在识别漏洞的POS方面是健壮的,这对于后续的句子解析非常有用,可以根据这些POS标记的顺序识别非VPV短语的绝对路径和相对路径。
2)CaVAE的鲁棒性
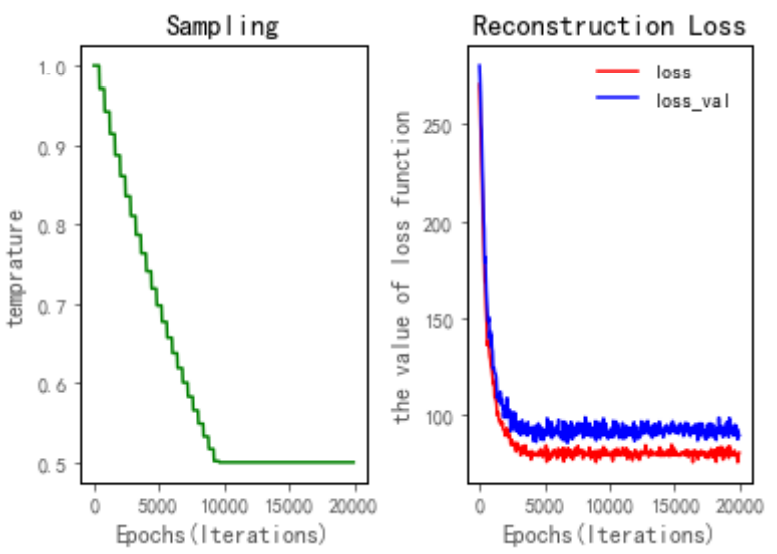
结果表明,CaVAE在学习绝对路径和相对路径的句法结构以及降维方面都是稳健的,从而证明了使用CaVAE进行后续潜在空间聚类的合理性。
3)概念聚类的质量
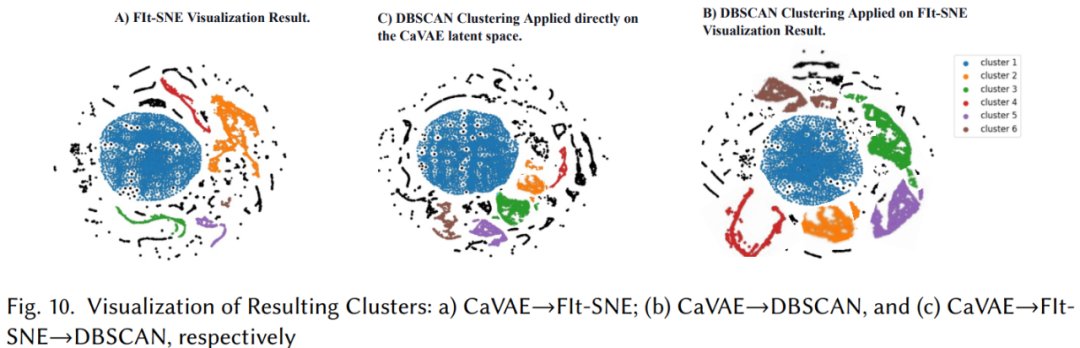
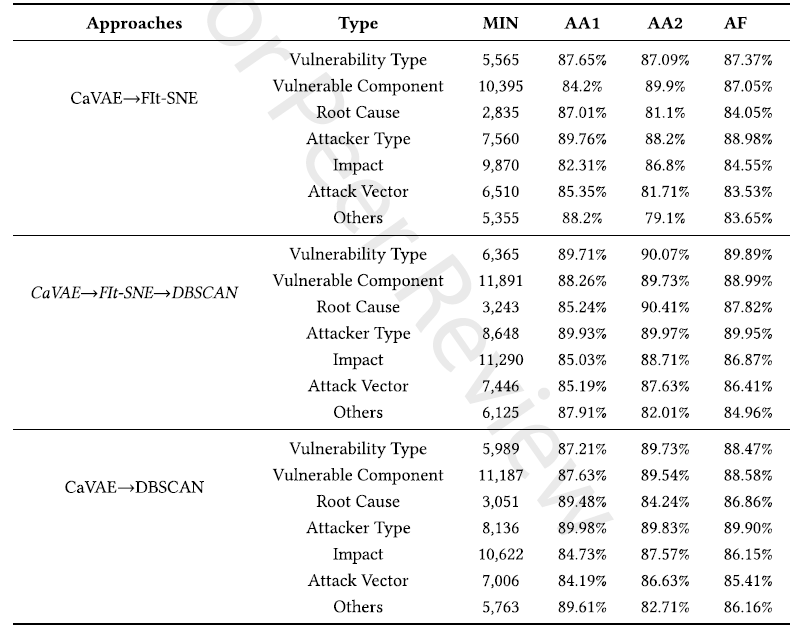
聚类可视化和对结果聚类中非VPV短语的手动检查证实了无监督标记方法的有效性。这证实了句法上相似的非VPV短语(在绝对路径和相对路径方面)通常代表相同类型的漏洞概念。
4)模型变体的比较

结果表明,特定领域的词性标注对下游表示学习更有效。训练编码器-解码器模型中路径的嵌入不能在隐空间中形成有意义的簇。与词嵌入相比,路径表示提高了我们对相同类型的非VPV短语进行聚类的模型性能。绝对路径和相对路径都是有用的。此外,使用Gumbel Softmax增强VAE对于解决路径的分类性质是必要的。
5)无监督标记数据的作用
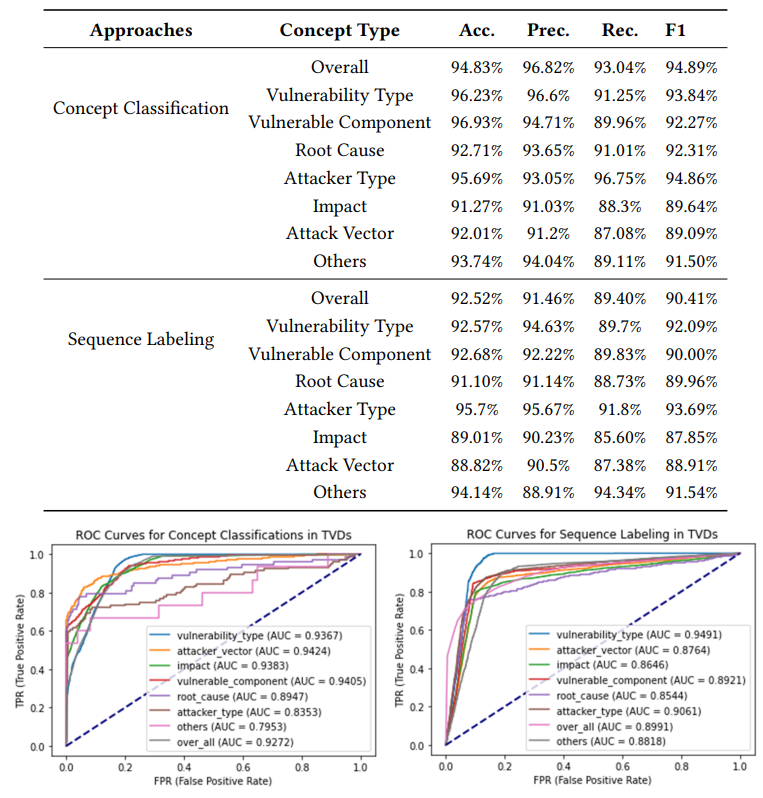
结果表明,无监督标注方法提取的TVD中的漏洞短语可以用于有监督的训练概念提取模型。且使用文中提取的短语训练的概念分类器优于使用BIO标记方案的令牌序列标记训练的序列标记模型。然而,概念分类器可能会遗漏概念跨度的确切起点和终点,并且依赖于句法分析树。序列标注方法可能更具挑战性,但它有潜力准确输出哪些令牌属于漏洞概念,对输入短语和原始TVD语句都有很好的表现。
6)与人工标记的TVDs的比较
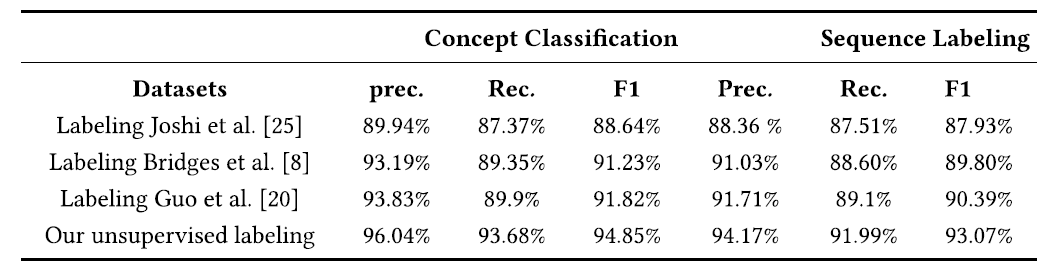
通过文中方法提取的漏洞短语构成了用于训练概念分类器和序列标注模式的高质量数据集。由于文中方法具有一致的边界和类型,使用无监督标注短语训练的概念分类器或序列标注模型优于使用人工标注短语训练的分类器或序列标注模型。
总结
本文提出了一种基于无监督的标记和提取文本漏洞描述(TVD)中基于短语的重要漏洞概念的方法,首先提出一个源-目标神经网络模型来进行特定领域的词性标注,然后通过CaVAE学习特征,并通过聚类将同类型的短语聚类到一起。通过此方法标记的TVD可用于训练其他基于TVD语料库的有监督概念提取模型,通过概念分类和序列标记模型这两种方法,本文证明了无监督标注概念的有效性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。