前言
前言:刷「哈希表」高频面试题。
文章目录
- 前言
- 一、简介
- 1、离散化
- 1)什么是离散化
- 2)离散化存储
- 3)离散化映射
- 2、哈希表
- 1)什么是哈希表
- 2)哈希表存储
- 3)哈希函数
- 4)哈希冲突
- 二、参考链接
一、简介
1、离散化
1)什么是离散化
假设一个数组长度为 6,这 6 个元素的数据范围为 1-2000,数据元素范围远大于数组长度范围(2000 > 6)。
2)离散化存储
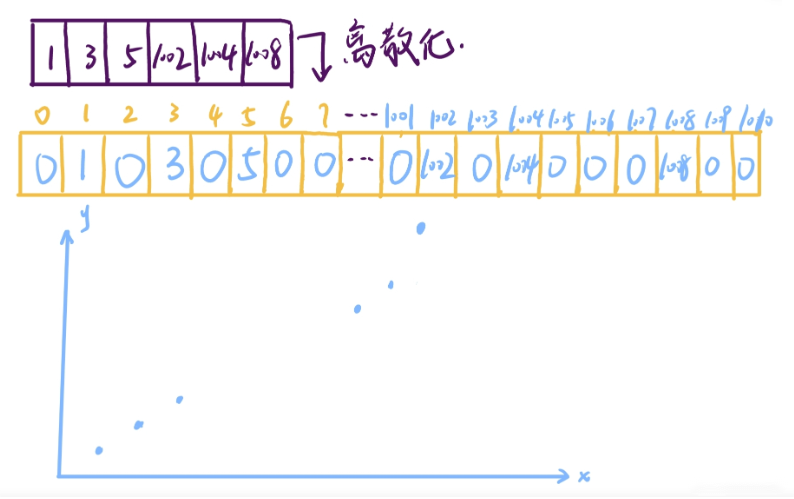
将 6 个数值差距很大的元素,放到离散化数组中,离散化数组的特点就是元素的下标与元素的内容是一致的。这种情况下,我们的离散化数组就会浪费了非常大的空间。
如下图所示,其中紫色数组为原始数组,黄色数组为离散化之后的数组。
3)离散化映射
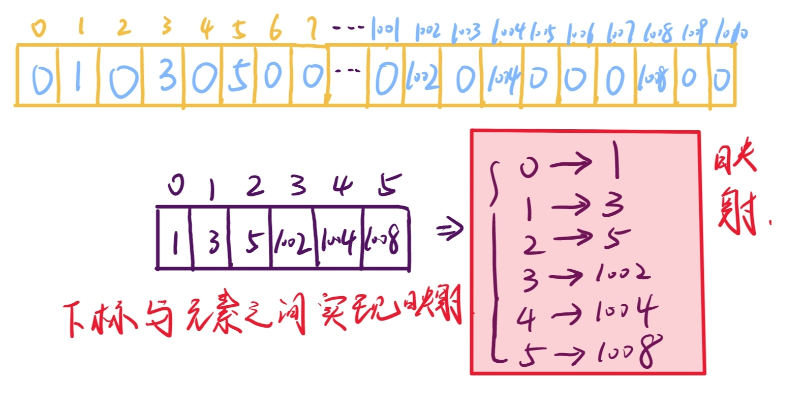
实现映射即通过将几个分散存储的数据通过下标的方式聚合到一起,就可以通过下标访问被聚合到一起的离散化数据,离散化的对象就是每次访问数组的下标,如下图所示。
2、哈希表
1)什么是哈希表
前面讲的离散化需要先排序,效率较低。
哈希表又称散列表,一种以「key-value」形式存储数据的数据结构,哈希表同样是为了解决离散化的问题,时间复杂度为 O ( 1 ) O(1) O(1)
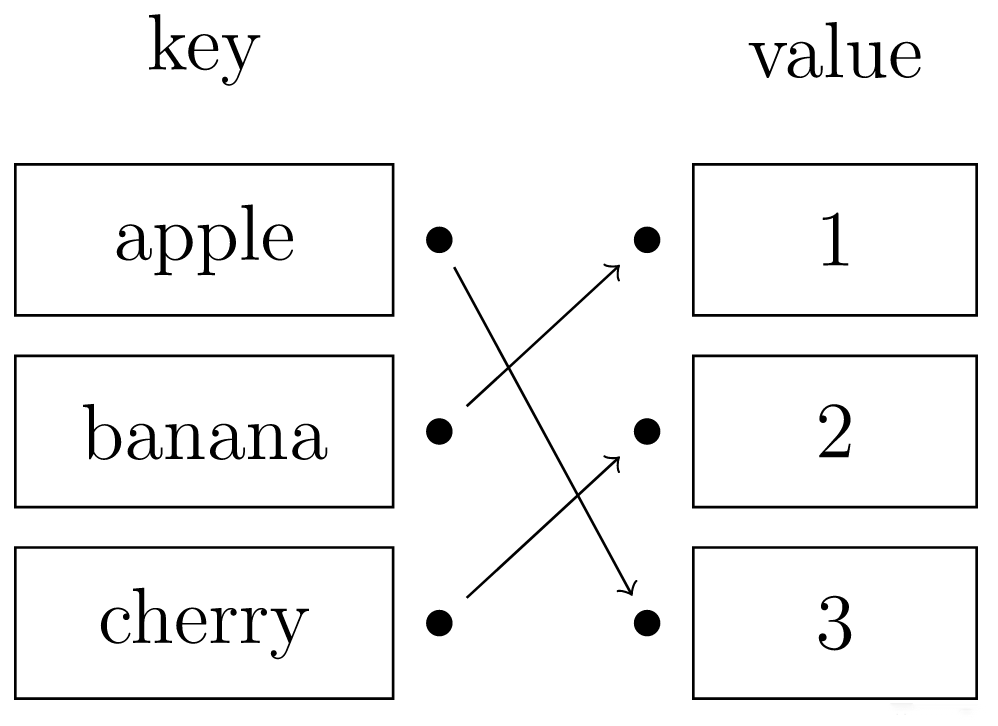
所谓以「key-value」形式存储数据,是指任意的键值 key 都唯一对应到内存中的某个位置。只需要输入查找的键值,就可以快速地找到其对应的 value。可以把哈希表理解为一种高级的数组,这种数组的下标可以是很大的整数,浮点数,字符串甚至结构体,如下图所示。
2)哈希表存储
哈希表存储的基本思路是:设要存储的元素个数为 n,设置一个长度为 m (m > n) 连续的内存单元,以每个元素的关键字 ki (1 ≤ i ≤ n),通过一个哈希函数 h 把 ki 映射为内存单元的地址 h(ki),并把该元素存储在内存单元中。
例如,我们可以开辟一个长度大于等于 n 的数组 a,并以 a[h(key)] = value 的方式来存储键值对 (key, value)。
3)哈希函数
假设存在一个哈希函数(hash),作用是将一个大范围的数字映射到一个小范围的数字。
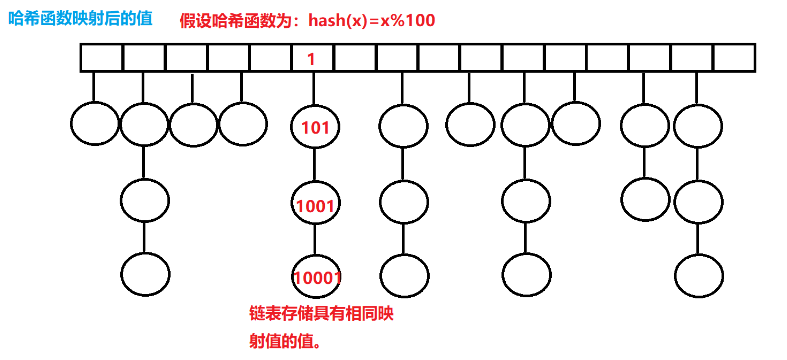
例如,将一系列的数字与 100 取模,最终得到的映射值的范围为 0~99 ,则哈希函数为取模运算,同时哈希函数取模的数,最好取为质数。
但是存在一个问题。例如,101 % 100 = 1,1001 % 100 = 1,101 和 10001 映射到了同一个映射值,发生了冲突。
4)哈希冲突
解决哈希冲突如下如所示,创建一个数组,这个数组存储不同的映射值,每个映射值都连接一个链表,这个链表存储的都是具有相同映射值的原值。
这样的话,可以先去寻找映射后的值,找到对应的链表,再去遍历链表,得到对应的原值。
二、参考链接
[1] https://blog.csdn.net/raelum/article/details/128793474
[2] https://blog.csdn.net/weixin_72060925