一、前言
对于任何一个数据存储的框架来说,确保数据的一致性都是其非常重要的组成部分,不管是过程中的强一致性,还是最终一致性,都是数据一致性的解决方案,本篇来聊聊clickhouse中的数据一致性问题。
二、clickhouse 数据一致性
通过查询 CK 官方手册发现,即便对数据一致性支持最好的 Mergetree,也只是保证最终一致性,即clickhouse是采用最终一致性的解决方案;

三、前置准备
1、创建一张数据表
CREATE TABLE test_a(
user_id UInt64,
score String,
deleted UInt8 DEFAULT 0,
create_time DateTime DEFAULT toDateTime(0)
)ENGINE= ReplacingMergeTree(create_time)
ORDER BY user_id;表字段说明:
- user_id 是数据去重更新的标识;
- create_time 是版本号字段,每组数据中 create_time 最大的一行表示最新的数据;
- deleted 是自定的一个标记位,比如 0 代表未删除,1 代表删除数据;
2、给当前表写入100万数据
INSERT INTO TABLE test_a(user_id,score)
WITH(
SELECT ['A','B','C','D','E','F','G']
)AS dict
SELECT number AS user_id, dict[number%7+1] FROM numbers(10000000);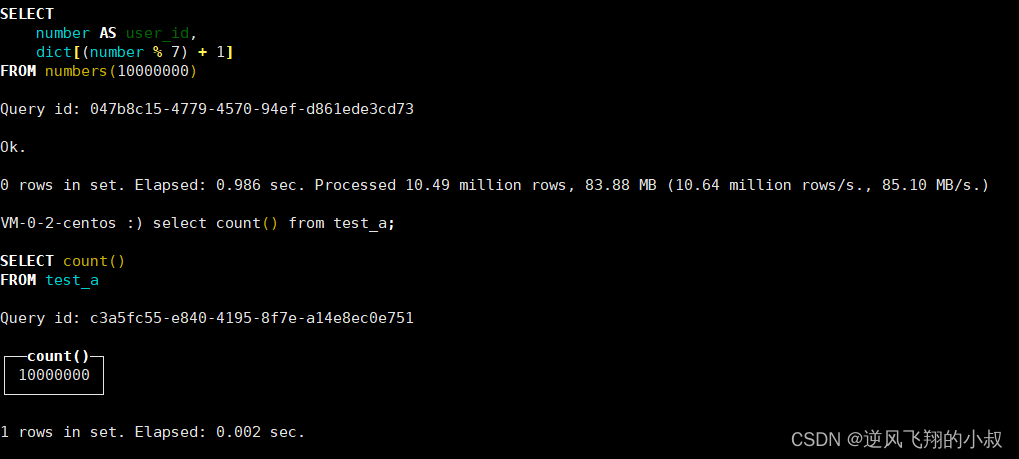
3、修改前 50 万 行数据,修改内容包括 name 字段和 create_time 版本号字段
INSERT INTO TABLE test_a(user_id,score,create_time)
WITH(
SELECT ['AA','BB','CC','DD','EE','FF','GG']
)AS dict
SELECT number AS user_id, dict[number%7+1], now() AS create_time FROM
numbers(500000);执行修改sql之后,查询下数据表的记录
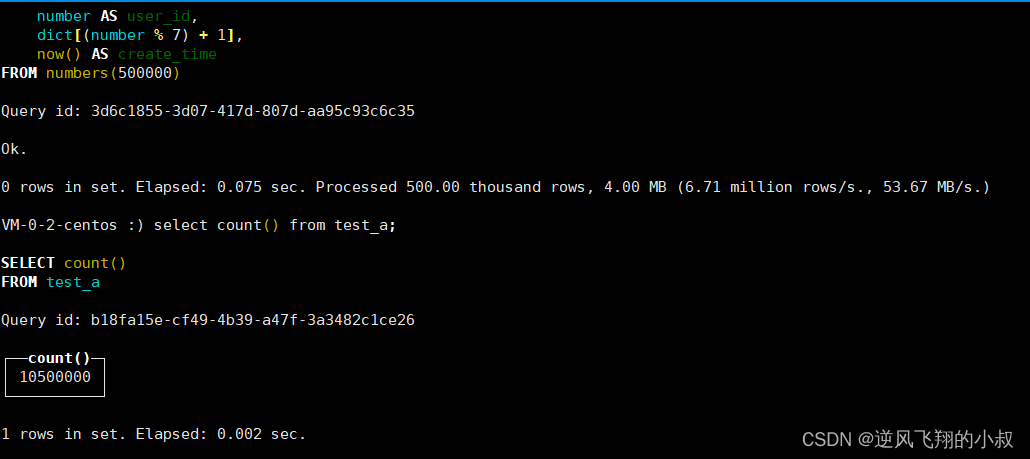
这时候发现数据行为105万了,是因为还未触发分区合并,所以还未去重,因此看到的数据是不一致的;
总结:
在使用 ReplacingMergeTree、SummingMergeTree 这类表引擎的时候,可能会出现短暂数据不一致的情况
四、手动触发OPTIMIZE
在写入数据后,立刻执行 OPTIMIZE 可以强制触发新写入分区的合并动作;
OPTIMIZE TABLE test_a FINAL;对上一步的操作执行上面的sql,再次执行发现数据就变成了100万了

OPTIMIZE 语法补充
OPTIMIZE TABLE [db.]name [ON CLUSTER cluster] [PARTITION partition |PARTITION ID 'partition_id'] [FINAL] [DEDUPLICATE [BY expression]]
五、 通过 Group by 去重
使用下面的去重语句进行查询
SELECT
user_id ,
argMax(score, create_time) AS score,
argMax(deleted, create_time) AS deleted,
max(create_time) AS ctime
FROM test_a
GROUP BY user_id
HAVING deleted = 0;对于该语句中的argMax函数做如下补充说明:
-
argMax(field1 , field2): 按照 field2 的最大值取 field1 的值;
-
当我们更新数据时,会写入一行新的数据,例如上面语句中,通过查询最大的create_time 得到修改后的 score 字段值;
六、 使用视图去重
1、创建一个测试使用的视图
CREATE VIEW view_test_a AS
SELECT
user_id ,
argMax(score, create_time) AS score,
argMax(deleted, create_time) AS deleted,
max(create_time) AS ctime
FROM test_a
GROUP BY user_id
HAVING deleted = 0;2、插入重复数据,使用视图再次查询
INSERT INTO TABLE test_a(user_id,score,create_time)
VALUES(0,'AAAA',now())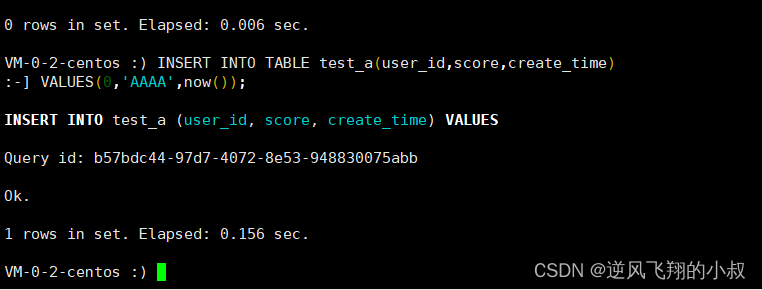
使用视图查询
SELECT *
FROM view_test_a
WHERE user_id = 0;
再次插入一条标记为删除的数据
INSERT INTO TABLE test_a(user_id,score,deleted,create_time)
VALUES(0,'AAAA',1,now());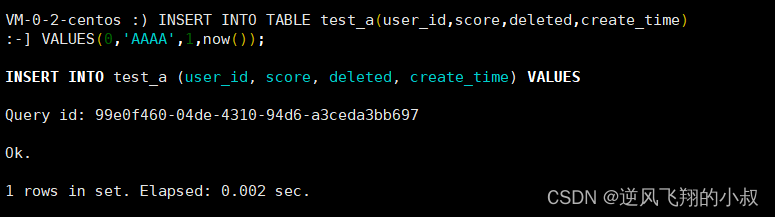
再次使用上面创建的视图查询,刚才那条数据看不到了

注意:这行数据并没有被真正的删除,而是被过滤掉了。在一些合适的场景下,可以结合表级别的 TTL 最终将物理数据删除;
七、 使用final关键字
在查询语句后增加 FINAL 修饰符,这样在查询的过程中将会执行 Merge 的特殊逻辑(例如数据去重,预聚合等);
但是这种方法在早期版本基本没有人使用,因为在增加 FINAL 之后,我们的查询将会变成一个单线程的执行过程,查询速度非常慢;
在 v20.5.2.7-stable 版本中,FINAL 查询支持多线程执行,并且可以通过 max_final_threads参数控制单个查询的线程数。但是目前读取 part 部分的动作依然是串行的;
FINAL 查询最终的性能和很多因素相关,列字段的大小、分区的数量等等都会影响到最终的查询时间,所以还要结合实际场景取舍;
接下来,通过上面导入的测试数据表 hits_v1 进行测试;
普通语句查询
select * from visits_v1 WHERE StartDate = '2014-03-17' limit 100 settings
max_threads = 2;查看一下执行计划
explain pipeline select * from visits_v1 WHERE StartDate = '2014-03-17'
limit 100 settings max_threads = 2;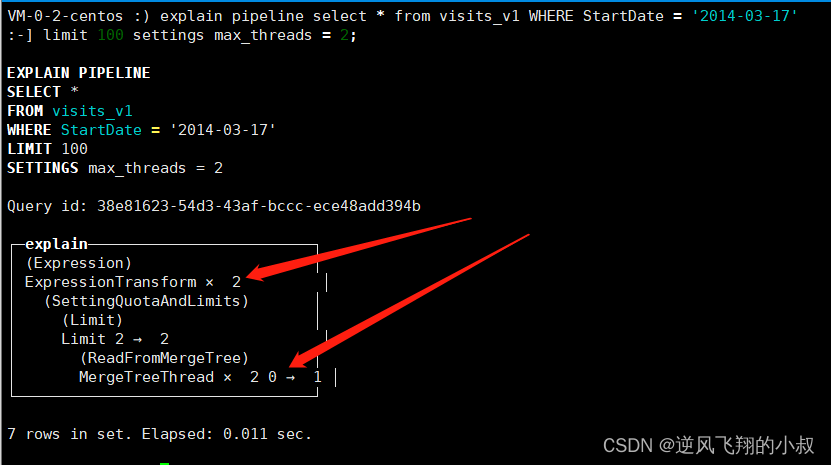
从执行计划结果来看,很明显将由 2 个线程并行读取 part 查询;
使用关键字 FINAL 查询
使用下面的这个加了final关键字的sql进行查询,查询速度没有普通的查询快,但是相比之前已经有了一些提升;
select * from visits_v1 final WHERE StartDate = '2014-03-17' limit 100
settings max_final_threads = 2;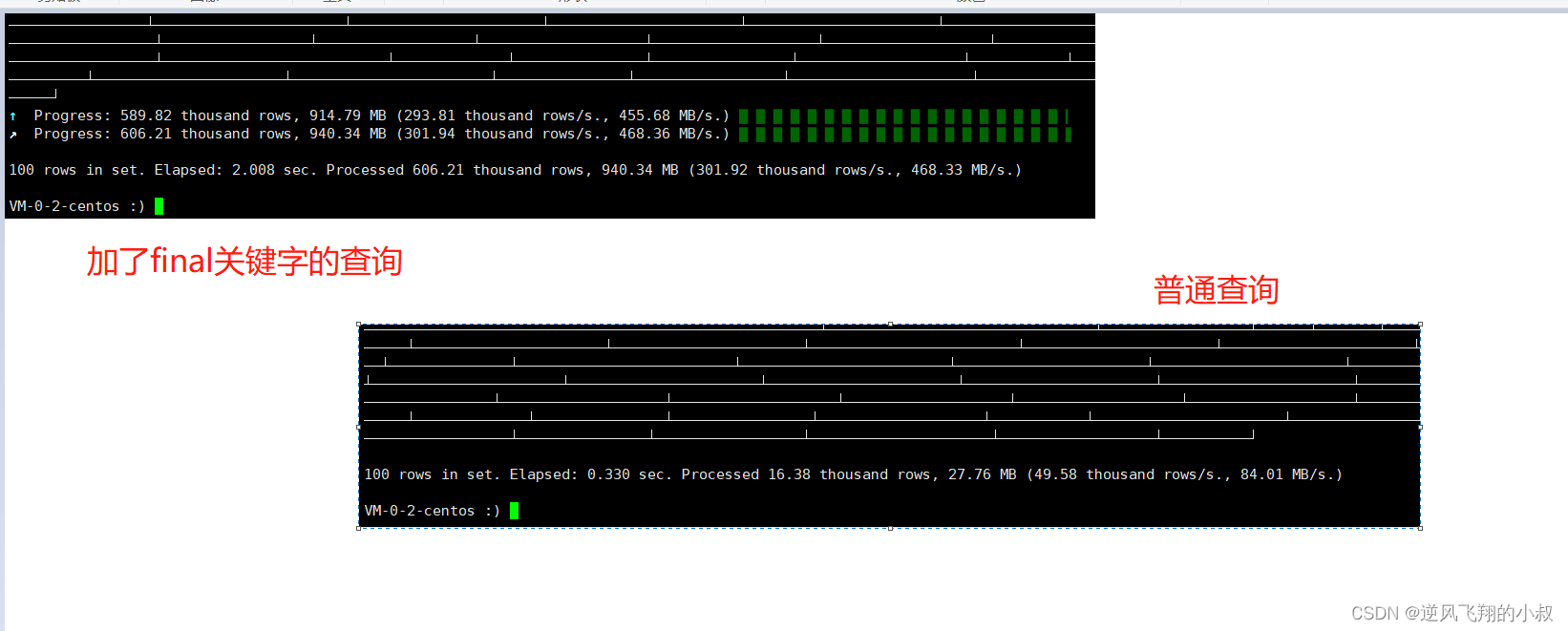
查看一下执行计划
explain pipeline select * from visits_v1 final WHERE StartDate = '2014-03-17'
:-] limit 100 settings max_threads = 2;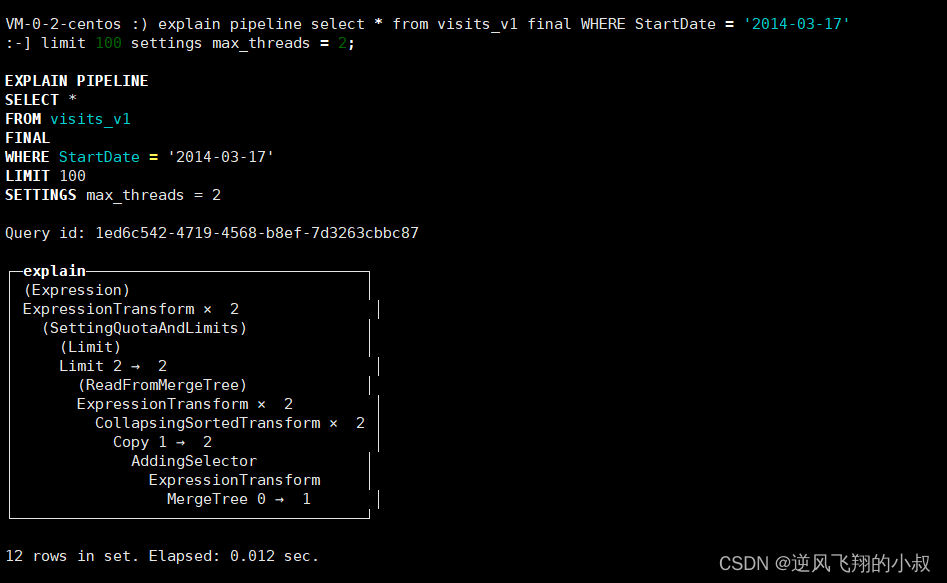







![[NeurIPS 2017] Poincaré Embeddings for Learning Hierarchical Representations](https://img-blog.csdnimg.cn/c983d9214c8a43119bebe6dd8c99b640.png#pic_center)