前言
最近在读 A Light CNN for Deep Face Representation With Noisy Labels 提到 maxout 激活函数,虽然很好理解,激活的时候选取最大值即可,但是具体细节看了看相关的资料反倒混淆了。参考了一个相关的视频,大致屡清楚为什么说 Maxout 需要 k 组参数,相比传统激活需要额外的参数了。
而 MFM 是 maxout 激活函数的一种变体。
参考链接:
https://www.youtube.com/watch?v=DTVlyP-VihU
正文
普通情况
正常的 relu 激活的隐含层可能是下面这样的。图源前文的参考链接。

我们的重点在于中间的一层,他有5个输入x1,x2,...,x5。要输出 4 维激活值。
我们正常情况下,需要权重 W 的维度 4*5,还有偏置 bias 的维度 4,最后隐含层的每个神经元计算结果后通过激活函数得到 4 维输出。
maxout
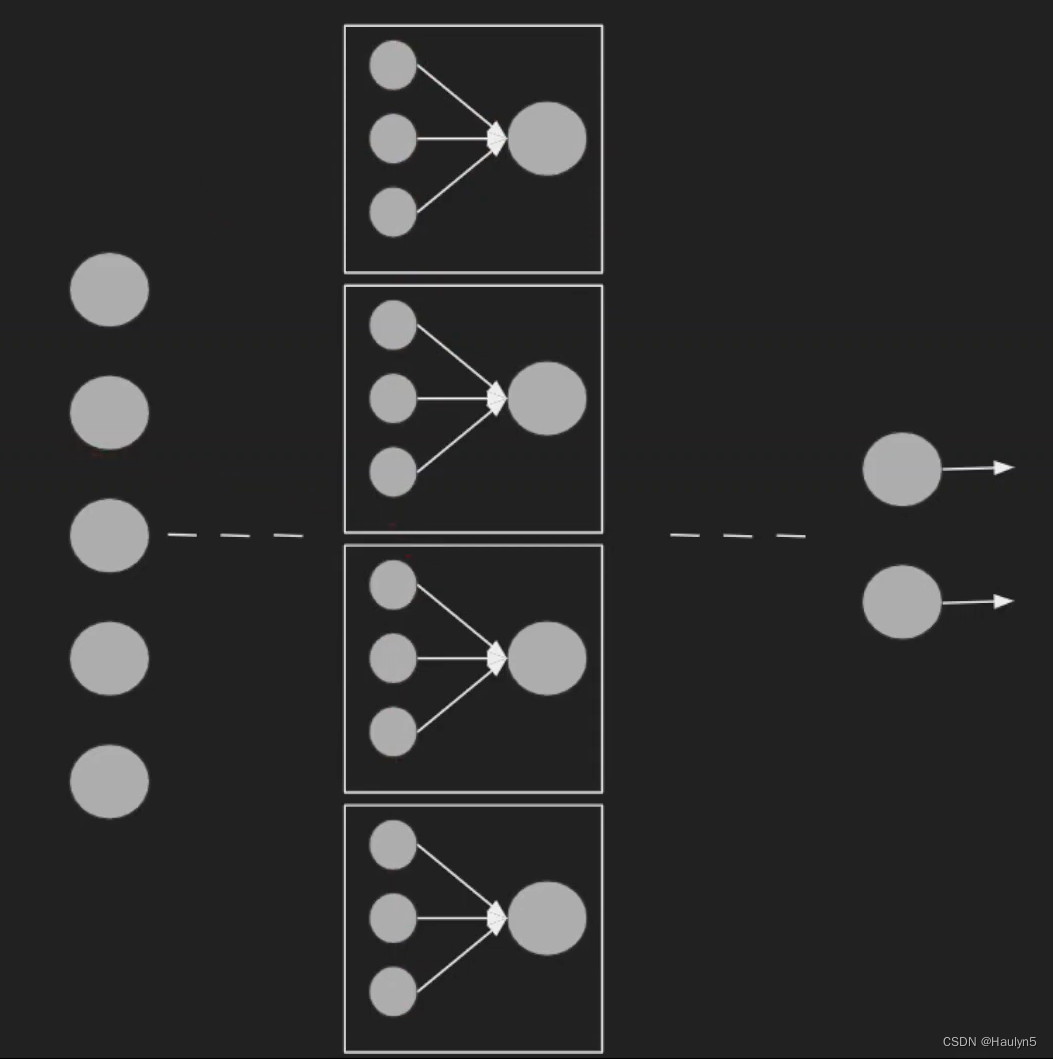
对于 maxout 同样是输入 5 维,输出 4 维,我们把原来的每一个 neuron 神经元替换成一个 block 块 或者叫 group 组,这个组内有 k 个神经元,这个块输出的值是 k 个神经元输出值的最大值,如果从外界看来每个块和原来的神经元没什么不同。注意 k 是 maxout 激活层的一个超参数,需要调。直觉来讲,k决定了参数的数量。越大的 k 意味着每个块内有更多的神经元,更多的参数。
懒得码公式了,希望阅读详细一点的可以去
深度学习(二十三)Maxout网络学习_hjimce的博客-CSDN博客_keras maxout
Max-feature-map (MFM)
MFM 是 maxout 的变体。其实看原文的图是最好理解的。

原来的 Maxout 每组有 k 个神经元输出最大激活值,而 MFM 2/1 输出两个神经元的最大值;MFM 3/2 输出三个神经元的两个,其实就也算是一种 maxout。作者的解释是这样的:
However, the basic motivation of MFM and Maxout are different. Maxout aims to approximate an arbitrary convex function via enough hidden neurons. More neurons are used, better approximation results are obtained. Generally, the scale of a Maxout network is larger than that of a ReLU network. MFM resorts to max function to suppress the activations of a small number of neurons so that MFM based CNN models are light and robust. Although MFM and Maxout all use a max function for neuron activation, MFM cannot be treated as a convex function approximation. We define two types of MFM operations to obtain competitive feature maps.——A Light CNN for Deep Face Representation With Noisy Labels
然而,MFM和Maxout的基本动机是不同的。Maxout的目的是通过足够多的隐藏神经元来逼近一个任意的凸函数。使用更多的神经元,可以获得更好的近似结果。一般来说,Maxout网络的规模要比ReLU网络的规模大。MFM采用最大函数来抑制少量神经元的激活,因此基于MFM的CNN模型是轻巧而稳健的。尽管MFM和Maxout都使用最大函数来激活神经元,但MFM不能被视为凸函数的近似。我们定义了两种类型的MFM操作来获得有竞争力的特征图。
凸函数一说就很有理论分析的感觉了……基础太差不是很能理解作者的动机,似乎就是说设定 k=2 或者 k =3 然后选两个,就能让模型轻量,确实 k 越小越轻量,但是拎出来和 maxout 做区分就感觉很怪……等之后有机会学习吧……