前言
MySQL实战的课后作业,作业内容具体见 https://bbs.csdn.net/topics/611904749
截至时间是 2023年2月2日,按时提交的同学有一位。确实这次的作业非常有挑战性,作业用到的内容没有百分之百的学过,需要大家进行深入而有效的搜索和尝试。
其实在解决困难问题的过程中,通过搜索解决方案和试错修正,我们可以快速学习。
下面我给出一个作业问题的解决方案,仅供大家参考。
问题分析
题目描述:创建数据库,将database_asset的表格(5073个证券2022年的交易日数据)全部导入数据库,并将他们合并,合并后,将表格的主键设置为证券代码、日期组成的联合主键。
先看一下给定的数据,5073个数据都是csv文件,数据是2022年全部交易日的交易数据。1月10日在群里另外给大家一个文件securities.csv,其中有证券的基本信息,包括显示名称,字母简称和上市和退市时间等。查看后,发现securities的内容并没有包含证券代码。
所以我们需要根据securities的数据内容,结合外部数据恢复证券代码。由于数据是从聚宽量化获取的,我们需要从数据源下载一份更全面的数据。下载过程(略)具体见聚宽的说明文档,聚宽量化 https://www.joinquant.com/data。下载目前上市的所有股票的资料,存入 all_securities.csv.
解决问题的步骤大致分为以下几步:
1、复原证券列表的代码部分,作为基础数据
2、处理数据,增加一些数据标签,方便以后进行分析
3、建库建表
4、导入个股数据
5、合并数据,增加主键
6、备份数据库
解决方案
1.复原基础数据
使用python进行数据预处理。导入需要的包,这里为了简洁省略了导入包的语句,大家可以自行脑补一下。
首先读入securities.csv
# 读入证券列表数据
securities = pd.read_csv('securities_0110.csv')
读入数据后,预览数据的情况。
securities.head() # 预览证券列表字段
securities.info() #查看空值情况
securities.duplicated().sum() # 查看有多少重复数据
securities表里有五个字段,熟悉证券交易的同学可以一眼看出每个字段的含义。
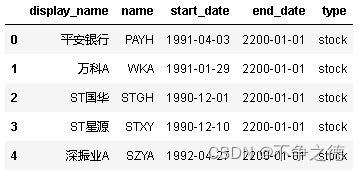
securities,一共5073行,五个字段都不含空值,所以不需要处理空值,行的维度没有重复值。

在已知的字段里找一下唯一标识
# 考察name和display_name是否唯一标识一只股票
l1 = len(securities.display_name.unique()) # 5071
print(l1)
l2 = len(securities.name.unique()) # 4115
print(l2)
l3 = len(securities[['display_name','name']])
print(l3)
securities[securities.display_name.duplicated()] #查看display_name为索引时的重复值
我们发现只有’display_name’,'name’联合在一起才能唯一标识一行数据,而display_name比较接近唯一标识,查看display_name为索引时的重复值项发现有两只固表存在display_name的重复。

查看这两只股票的数据:
securities[securities.display_name == '百联股份']
securities[securities.display_name == '东方明珠']

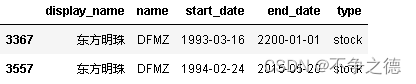
可以看到重复项的上市时间和退市时间存在分歧,所以必须借助证券代码来处理数据。
#获取额外数据来找到证券代码作为证券的唯一标识
alls = pd.read_csv('all_securities.csv')
因为聚宽的数据是dataframe格式的,会有一个格是Unnamed,通过下图所示的方式处理一下。
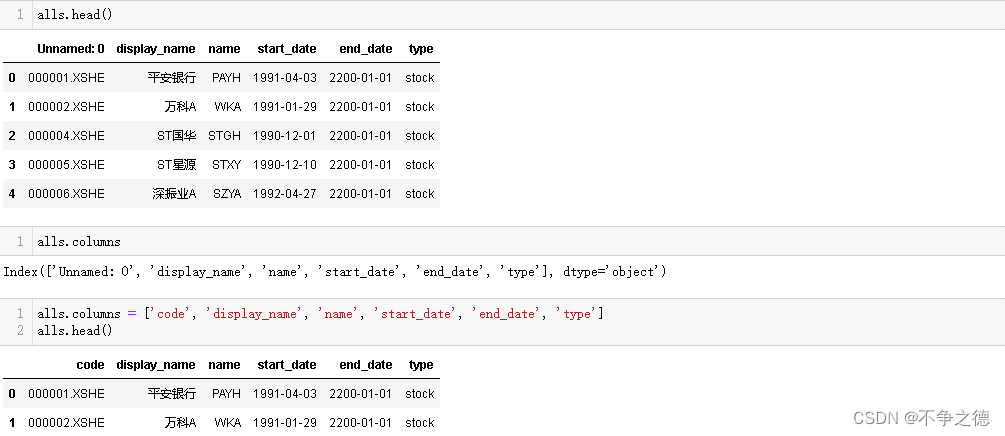
通过merge函数重新组装数据
#s = pd.merge(securities,alls,on=['display_name','name'],how='inner')
s = pd.merge(alls,securities,on=['display_name','name'],how = 'inner')
print(s)
s[s.code.duplicated()]
合并后的表有重复项4项。

去掉重复项后,去掉重复列(过程略),得到一个5070行的数据表。将s命名为final并修改字段名称为[‘code’, ‘display_name’, ‘name’, ‘start_date’, ‘end_date’]
2. 处理数据,添加标签
增加一列 ‘exit’,提示股票是否在2022年底已经退市。
final['exit'] = final.end_date<='2022-12-31'
final[final['exit']] ## 168只股票已经退市
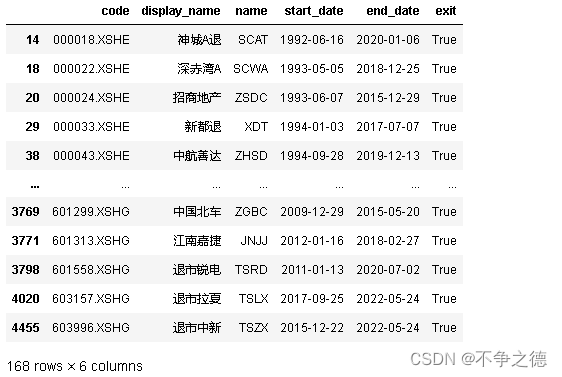
增加一个新股的提示字段 new,提示是否股票为新股
final['new'] = final.start_date>'2022-01-01'
final[final.new]
# 2022年有346只新股, 发现有一只股票 688506是2023年才上市的
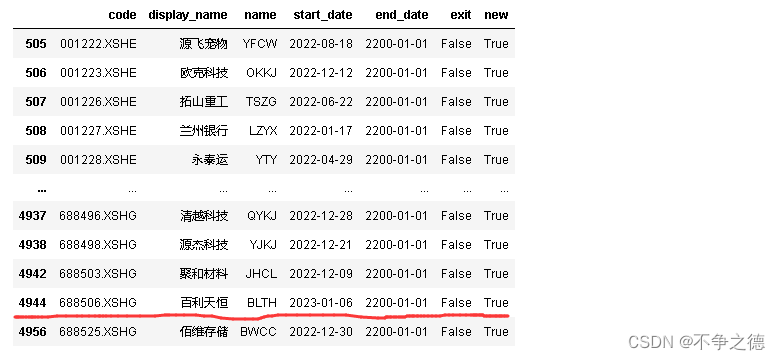
因为该股不在我们的统计周期,故去掉这条数据。
# 删除688506的数据
final2 = final.drop([4944], axis=0)
新股的交易日不覆盖全年,我们的数据表中存在它们还未交易的数据行,所以需要计算条过的无效行的数量,增加一列row_skip, 统计新股发行前在2022年的交易日数量。
final2['row_skip']= np.nan
# 使用trade_days为skip_row赋值
for i in final2.index:
final2.row_skip[i] = trade_days('2022-01-01',final2.start_date[i])
#查看赋值情况
final2[final2['new']]
trade_days(start_date,end_date)是我们自己定义的函数,主要使用calender包统计交易日,这里略过。赋值后,新股都有了相应的值。
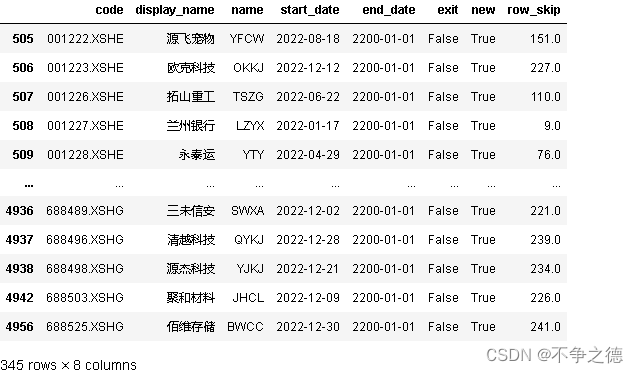
至此,数据处理完成,将处理结果导出
final2.to_csv('stockList.txt',index = None,encoding='utf8')
之所以存成.txt文件,是因为.csv文件莫名会把数字字符串转成数字存储,也可能是显示方式的问题,总之会导致数据出问题,所以我们选择txt文件。
3. 建库建表
使用csdn的云容器,4核4G的MySQL技能树。
先创建数据库stocks;代码略。
在库里建表stockList存放我们刚才处理好的基础数据。
CREATE TABLE stockList(
code char(8),
display_name varchar(20),
name char(5),
start_date date,
end_date date,
exlisting ENUM('True','False'),
newlisting ENUM('True','False'),
row_skip INT
);
使用load data命令导入数据
load data infile '/media/stockList.txt' into table stockList
fields terminated by ','
lines terminated by '\n'
ignore 1 rows;
按照作业要求需要将个股的数据先导入,所以需要为每只个股建立表。考虑到个股的数量在5000以上,手动建表已经没有可行性,所以我们写一个存储过程来实现建表的过程。
创建存储过程create_tables():
delimiter $
CREATE PROCEDURE create_tables()
BEGIN
SET @list := (SELECT GROUP_CONCAT(code) FROM stockList);
SET @counter := 1;
WHILE @counter <= (SELECT COUNT(code) FROM stockList) DO
SET @str := (SELECT SUBSTRING_INDEX( SUBSTRING_INDEX(@list,',',@counter),',',-1));
SET @tablename := CONCAT('price_',@str);
SET @sql_text = CONCAT('CREATE TABLE ' '', @tablename, '(trade_day DATE, op DECIMAL(6,2), cl DECIMAL(6,2), high DECIMAL(6,2), low DECIMAL(6,2), volume BIGINT, money BIGINT );');
PREPARE stmt FROM @sql_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @counter = @counter + 1;
END WHILE;
END $
delimiter ;
我们这里使用自定义变量 @list, @counter, @str帮助我们提取证券代码并轮询建表语句。在存储过程中无法直接create table,需要prepare。
GROUP_CONCAT() 和 SUBSTRING_INDEX( )这两个函数帮了我们大忙。调用时call create_tables(),之后我们就得到5069个表;
4. 导入数据
个股数据的导入直觉上是再写一个存储过程就完事儿啦,但是,很可惜,mysql的存储过程并不能包含LOAD DATA。但是,很幸运,mysql还有mysqlimport这个功能,可以帮助我们很快解决问题。
mysqlimport的语法: mysqlimport --ignore-lines=1 --fields-terminated-by=, --local -u root -p Database TableName.csv
我们可以看出,.csv文件的名称必须是表名,但是我们的.csv文件的名称是证券代码,与表名相比,缺少一个前缀 ‘price_’。不过没有关系,添加前缀也是很方便的。
我们在.csv文件所在的文件夹,使用下面这一行命令就可以完成任务
for f in * ; do mv -- "$f" "price_$f" ; done
万事俱备,只欠东风啦!
我们再用一行语句完成个股数据的导入。
for f in * ; do mysqlimport --ignore-lines=1 --fields-terminated-by=, --verbose --local -u root stocks /media/database_asset/"$f"; done
照一张表格去一部分数据看一下,
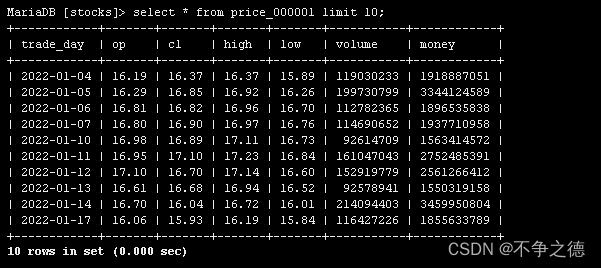
看起来没有问题。
5. 合并数据,增加主键
合并数据的话,依然需要使用存储过程。
当然,首先创建一个合并表:
CREATE TABLE merged_table (
code CHAR(8),
date DATE,
open DECIMAL(6,2),
close DECIMAL(6,2),
high DECIMAL(6,2),
low DECIMAL(6,2),
volume BIGINT,
money BIGINT
);
我们合并表时使用 INSERT INTO … SELECT … FROM … 这样的方式,这样比一行一行的insert要快很多。
创建一个存储过程merge_tables() :
delimiter $
CREATE PROCEDURE merge_tables()
BEGIN
set @list := (SELECT GROUP_CONCAT(code) FROM stockList);
set @counter := 1;
WHILE @counter <= (select count(code) from stockList) DO
SET @str := (select substring_index(substring_index(@list,',',@counter),',',-1));
SET @tablename := CONCAT('price_',@str);
SET @sql_text = CONCAT('INSERT INTO merged_table( code, date , open , close ,high ,low , volume , money ) SELECT ''',@str,''' as code, trade_day , op , cl ,high ,low , volume , money FROM ',@tablename,';');
PREPARE stmt FROM @sql_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET @counter = @counter + 1;
END WHILE;
END $
delimiter ;
调用call merge_tables(), 我们就得到合并的所有数据。数据量122万左右。
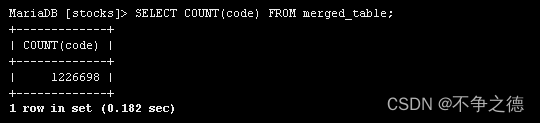
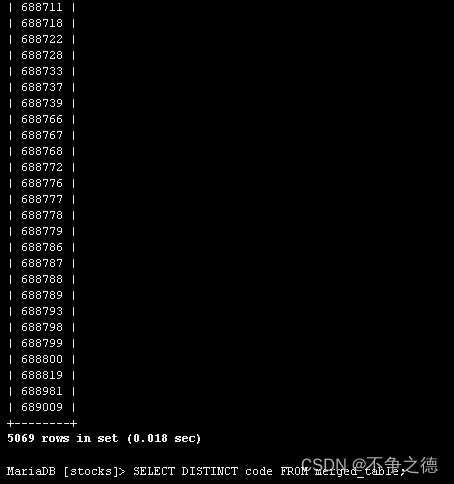
所有的证券代码都导入了。
然后我们使用alter name给merged_table表添加联合主键。
ALTER table merged_table add primary key(code,date);
6.备份数据库
使用mysqldump将数据库备份到/media文件夹下:
mysqldump stocks > /media/stocks_backup.sql
将.sql文件下载到本地,保存,以备后用。
至此,作业已经完成。但是我们还要做一些扫尾工作,记得把刚才建立的存储过程删除哦。
DROP PROCEDURE create_tables;
DROP PROCEDURE merge_tables;
后记
本次作业的过程难点主要在于如何在mysql里使用循环语句,构建存储过程,以及如何快速导入文本数据。
作业的过程中,搜索是一项重要的技能,百度和csdn可能并不能提供完全的解决方案,需要我们试错,并有耐心排除故障,找到问题的所在。
存储过程和用户自定义函数其实在mysql的系统眼里并没有本质区别,自定义函数应该是被当作了带有返回值的存储过程,这一点是在尝试批量导入个股数据表时发现的。因为两种方式的报错信息是完全一样的。
这个作业很难,但是探索完成的过程中,我们很自然的学到了mysql的很多相关知识。希望大家enjoy!