冒险和预测(三)
- 乱序执行
- 参考
乱序执行
尽管代码生成的指令是顺序的,但是如果后面的指令和前面的指令独立,完全不需要等待前面的指令运算完成,可以先执行。
这种解决方案称为乱序执行(Out-of-Order Execution)。
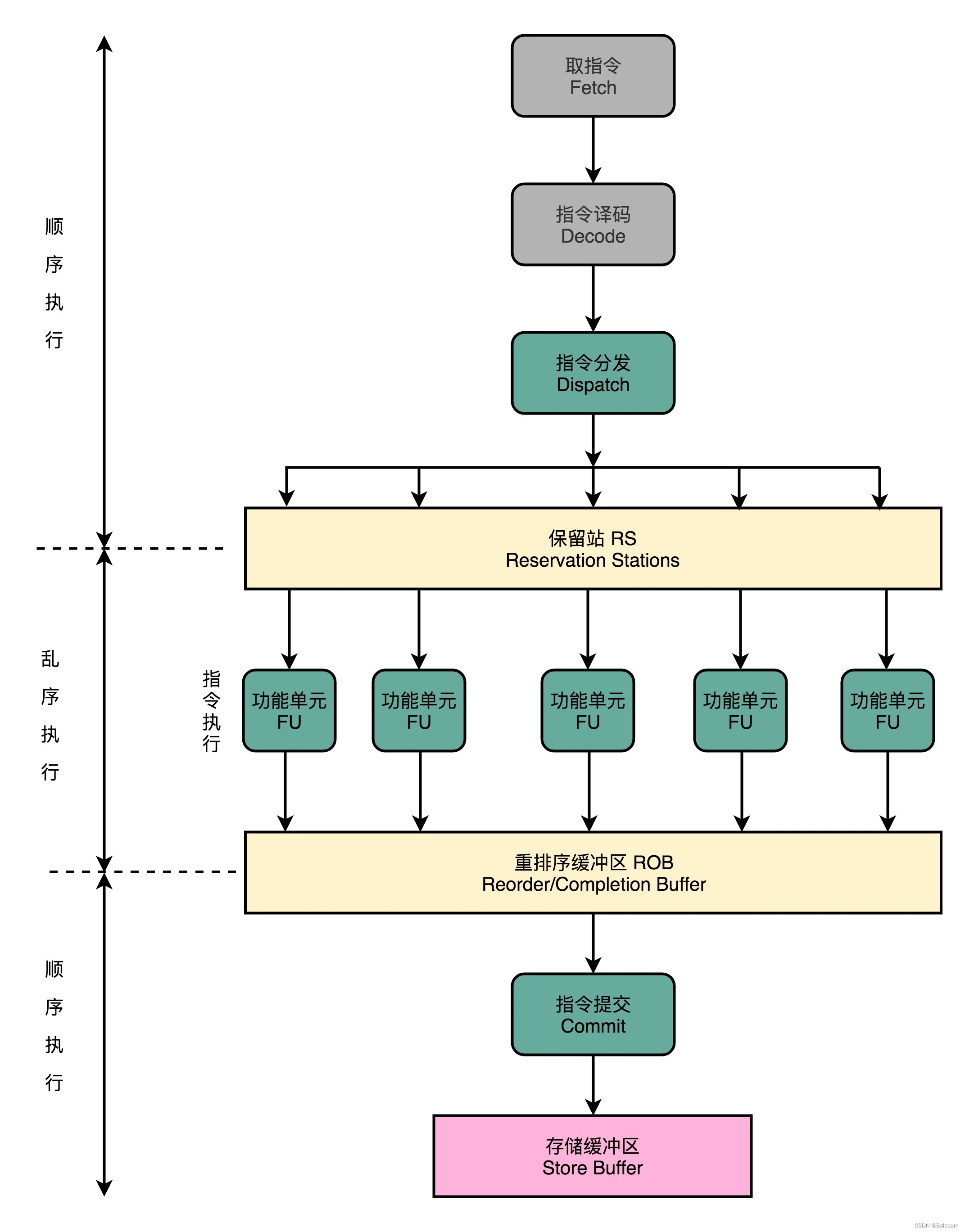
- 在取指令和指令译码的时候,乱序执行的 CPU 和其他使用流水线架构的 CPU 是一样的,它会一级一级顺序地进行取指令和指令译码工作。
- 在译码完成后,CPU 不会直接进行指令执行,而是进行一次指令分发,把指令转发到一个保留栈(Reservation Stations)。
- 这些指令不会立即执行,而是等待它们所依赖的数据传递给它们后才会执行。
- 一旦指令依赖的数据来齐了,指令就可以交到后面的功能单元(Function Unit),其实就是 ALU 去执行。
- 指令执行的阶段完成之后,我们并不能立刻将结果写回到寄存器里,而是把结果再存放到一个叫做重排序缓冲区(Re-Order Buffer)。
- 实际的指令的计算结果数据,并不是直接写到内存或者高速缓存里,而是先写入存储缓冲区(Store Buffer),最终才会写入到高速缓存和内存里面。
在乱序执行的情况下,只有 CPU 内部指令的执行层面,可能是“乱序”的。只要我们能在指令的译码阶段正确地分析出指令之间的数据依赖关系,这个“乱序”就只会在互相没有影响的指令之间发生。
即便指令的执行过程中是乱序的,我们在最终指令的计算结果写入到寄存器和内存之前,依然会进行一次排序,以确保所有指令在外部看来仍然是有序完成的。
整个乱序执行技术,就好像在指令的执行阶段提供一个“线程池”。指令不再是顺序执行的,而是根据池里所拥有的资源,以及各个任务是否可以进行执行,进行动态调度。在执行完成之后,又重新把结果在一个队列里面,按照指令的分发顺序重新排序。即使内部是“乱序”的,但是在外部看起来,仍然是井井有条地顺序执行。
参考
极客时间《深入浅出计算机组成原理》