为什么要分库分表
随着业务量的增加导致数据库中数据量的增加,可能拖慢查询的性能,影响业务的可用性;如果数据库采用读写分离,可能会导致从库的延迟较大,主库进行写操作后,从库因为延迟无法及时同步,会导致出现数据不一致的情况。
分表:应对大数据量。当单表的数据达到百万级时,sql 的执行性能就较差了;当超过千万级时,sql 的执行性能急剧下降,所以要保持 sql 的执行性能,就必须采用分表。
分库:应对高并发。一个健康的单数据库并发最好维持到 1000 个连接左右,超过就可能造成宕机崩溃。采用分库就可以提高数据库的并发能力。
分库分表的原则
在进行分库分表时,我们最好遵循一下原则:
- 优先进行 MySQL 调优,能不分就不分
数据量能稳定在千万级,近几年不会到达亿级,其实是不用着急拆的,先尝试MySQL调优,优化读写性能。只有在MySQL调优已经无法解决慢查询问题时,才可以考虑分库分表。
- 分片的数量尽量少
分片就是将数据存储在多个数据库实例中,在分库中就是将数据拆分到多个独立的数据库中,在分表中就是将一个大表拆分成多个小表,每个小表存储数据的一部分。
如果实例太多,分的太细,那么查询一个 sql 可能要跨越多个分区,降低查询的性能。
- 数据的分布要尽量均匀
数据应该尽量均匀的分布在多个分片中,原因同上,这就涉及到分片建的选择了。
分表方案
分表的应用场景是单表数据量增长速度过快,影响了业务接口的响应时间,但是 MySQL 实例的负载并不高,这时候只需要分表,不需要分库(拆分实例)。
一张表的大小由 字段数量 × 记录数量 构成,也就是说如果表太大,那么要么是表的记录太多,要么就是表的字段太多。这就产生了两种分表方案:
- 垂直分表(拆分字段)
- 水平分表(拆分记录)
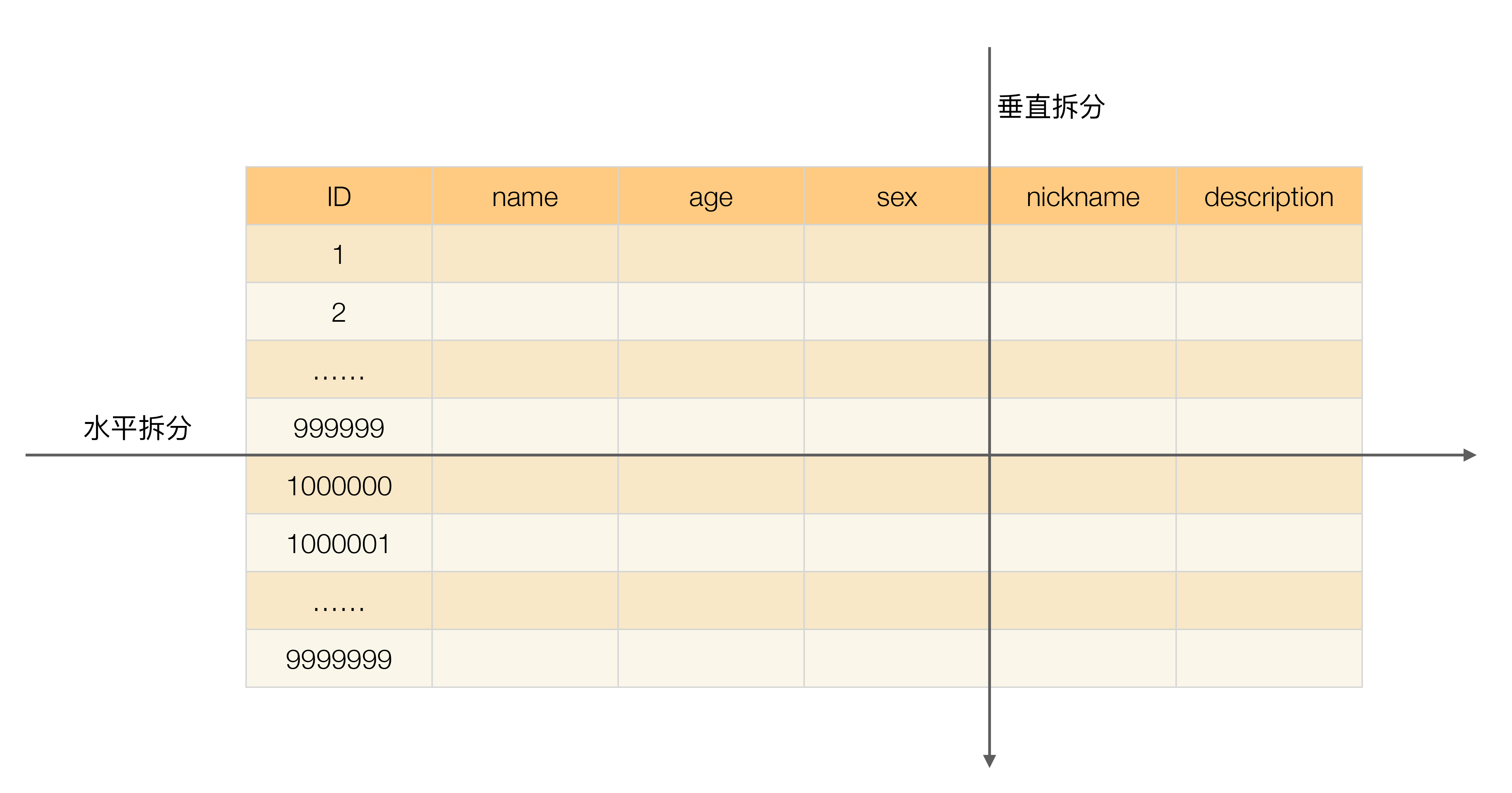
垂直分表
以订单表 orders 为例,按照字段进行拆分,这里面需要考虑一个问题,如何拆分字段才能表上的DML性能最大化。
- 常规的垂直分表方案就是冷热分离拆分(将使用频率高字段放到一张表里,剩下使用频繁低的字段放到另一张表里)。
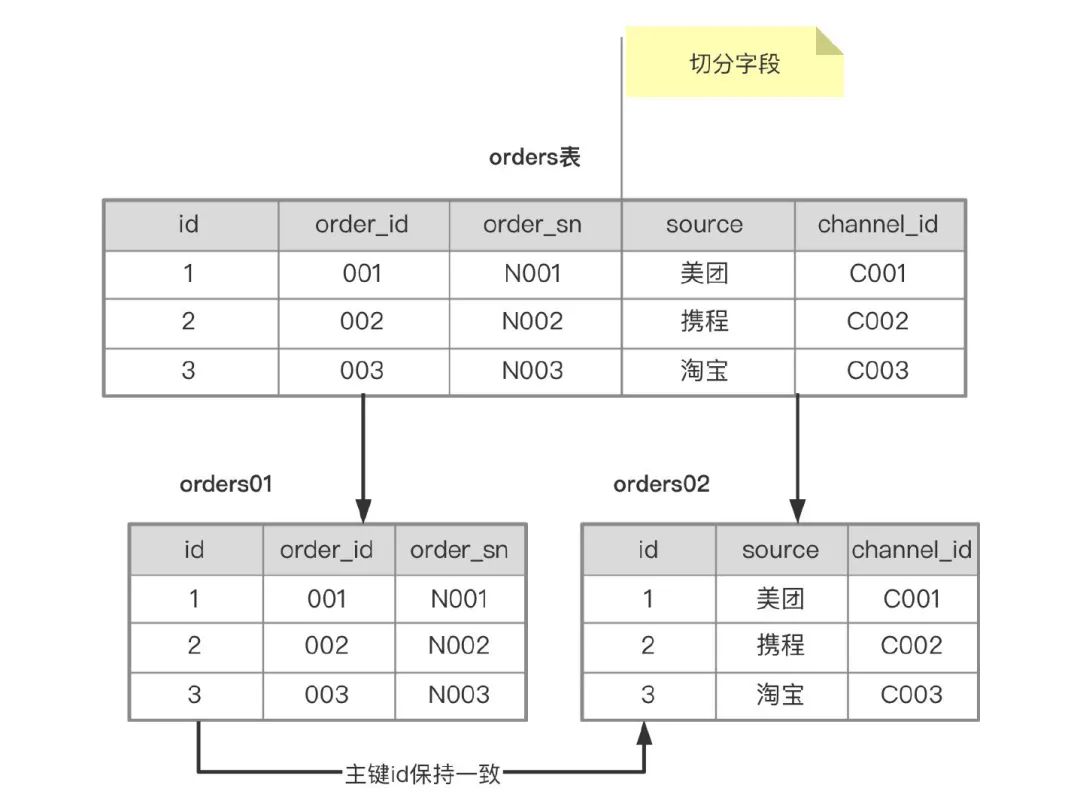
什么情况下可以使用冷热分离?
- **数据走到终态后只有读没有写的需求。**例如订单完结后基本只会读不会改。
- **用户能接受新旧数据分开查询。**比如有些电商网站默认只让查询3个月内的订单,如果要查询3个月前的订单,还需要访问其他的页面。
orders 表通过拆分之后,就变成了 orders01 和 orders02 两张表,在磁盘上就会存储两个数据文件 orders01.ibd 和 orders02.ibd,orders 表最大尺寸就是 4TB 了,拆分完之后,该怎么查询呢?举个例子:

分析下上面的 SQL,select 后面的列分别位于两张表中(order_id,order_sn在orders01中,source在orders02中),上面的SQL可以查询重写为如下形式。

一般数据库中间件就会自动实现查询重写,但是每次解析SQL时都需要根据原表名 + 字段名去获取需要的子表,然后再改写 SQL,执行 SQL 返回结果,这种代码改造量太大,而且容易出错。
业务场景举例:
- 邮件系统:邮件系统中最近邮件是用户经常访问和修改的,三个月前的邮件或已归档的邮件不经常访问的。可以将用户的收件箱、发件箱里最近三个月的邮件放在一个库里(热库),之前的邮件或者已读的邮件放在另一个库里(冷酷)。
- **日志系统:**在大型应用中,日志数据是非常庞大的,但并不是所有日志都需要经常查询或分析。可以将最近一段时间的活动日志存放在热库中,而将过去的历史日志存放在冷库中,以减轻热库的负载和优化查询性能。
- 社交媒体平台:社交媒体平台上的用户数据量通常很大,但是只有少部分用户是活跃的,并且只有少量用户的数据会频繁访问和更新,如果所有用户都放在同一个库里,势必会影响活跃用户的查询效率。可以将活跃用户的个人信息、好友关系等存放在热库中,而将不活跃用户的数据存放在冷库中,以提升热库的性能和减少冷库的存储成本。
- **电商平台:**电商平台上的商品数据也可以进行冷热分离。热库中存放热门商品的基本信息和库存等,以支持频繁的查询和更新操作,而将不活跃或下架的商品信息存放在冷库中,以减少热库的负载和优化查询性能。
- 客服工单:在我们日常操作时,经常能看到查询历史工单时会有个“近三个月工单”的选项,实际业务场景中,用户基本只会关注近三个月工单,而且这些工单也会经常需要进行修改、删除的操作,而对很早期的历史订单基本就没有修改、删除的需求,只有少量的查询需求。
- 还可以根据业务的层面来进行拆分:将混合业务拆分为独立业务。
业务场景举例:
- **电商网站:**一个典型的混合业务,包含用户信息、订单信息、商品信息等。可以将用户信息、订单信息和商品信息分别拆分到不同的库或表中,以减少数据冗余并提高访问效率。
- 社交媒体平台:包含用户信息、好友关系、动态信息等。可以将用户信息和好友关系分离存储,以便更好地支持好友关系的查询和更新。
- **在线游戏:**涉及角色信息、道具信息、战斗日志等。可以将角色信息和道具信息拆分到不同的表中,以提升查询效率,并将战斗日志存储到日志数据库中,以减轻主数据库的负载。
- 物流系统:包含订单信息、配送信息、运输信息等。可以将订单信息、配送信息和运输信息分别拆分到不同的表中,以便更好地支持订单的查询和跟踪。
- 还有如果业务表中有 text 长文本类型的字段需要存储。这时可以利用垂直拆分来减少表大小,将 text 字段拆分到子表中。
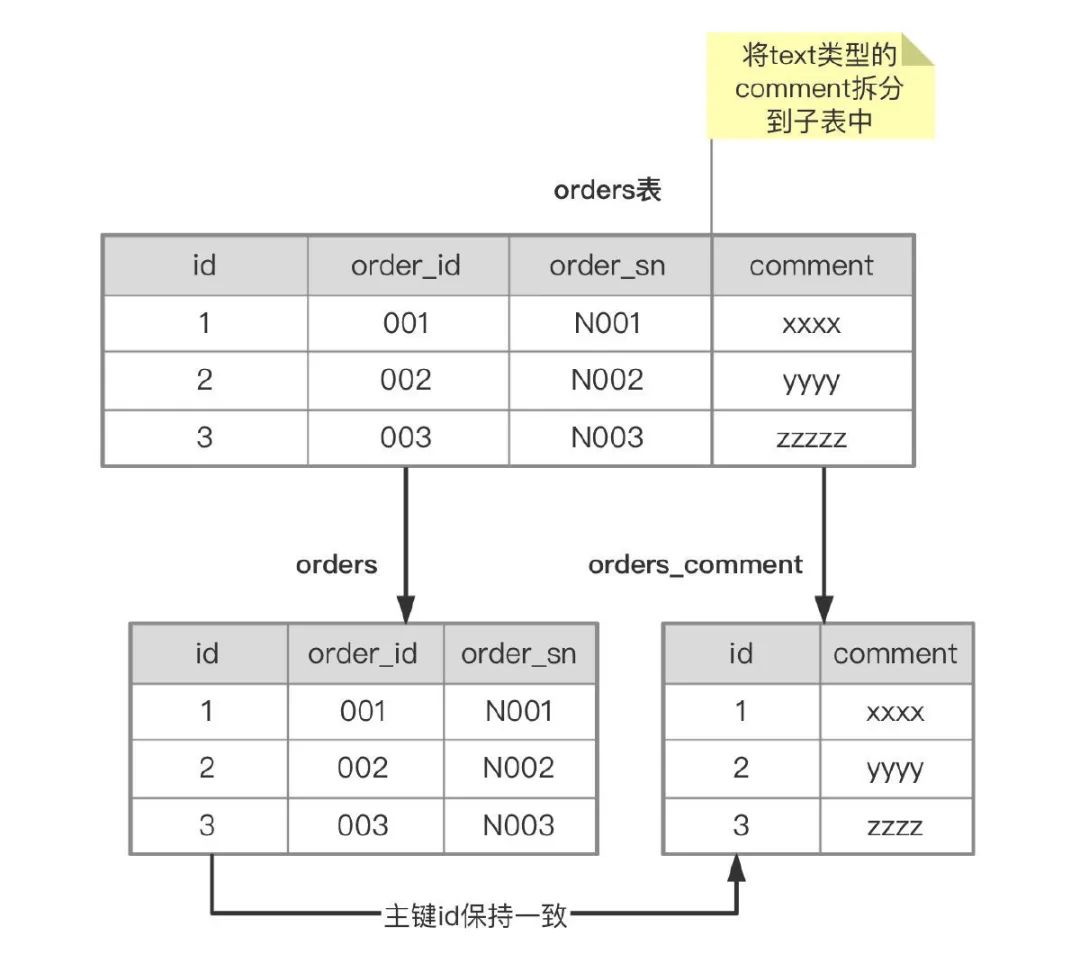
这样将 text 类型拆分放到子表中之后,原表的平均行长度就变小了,就可以存储更多的数据了。
水平分表
水平拆分表就是按照表中的记录进行分片,举个例子,目前订单表 orders 有 2000w 数据,根据业务的增长,估算一年之后会达到1亿,同时参考阿里云 RDS for MySQL 的最佳实践,单表不建议超过 500w,1亿数据分20个子表就够了。
问题来了,按照什么来拆分呢?主键id还是用户的user_id,按主键ID拆分数据很均匀,通过ID查询 orders 的场景几乎没有,业务访问 orders 大部分场景都是根据 user_id来过滤的,而且 user_id 的唯一性又很高(一个 user_id 对应的 orders 表记录不多,选择性很好),按照 user_id 来作为 Sharding key能满足大部分业务场景,拆分之后每个子表数据也比较均匀。
一般使用散列算法,让数据均匀的分摊到不同的库表中。如把原本在一台机器上的数据库存放1000万数据,分摊到n台机上,拆分这1000万的数据和后续的增量。让每个数据库资源来分摊原本需要一台数据库所提供的服务。
公式: sharding_key%N
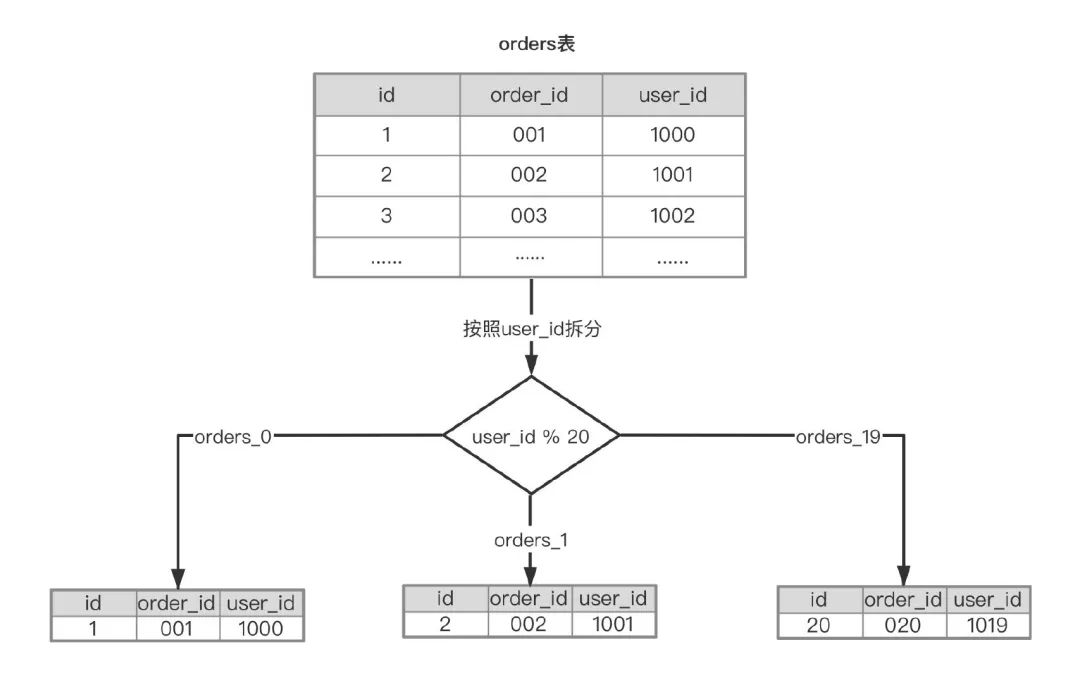
这样就将 orders 表拆分成20个子表,对应到InnoDB的存储上就是20个数据文件(orders_0.ibd,orders_1.ibd等),这时候执行SQL语句select order_id, order_sn, source from orders where user_id = 1001就能很快的定位到要查找记录的位置是在orders_1,然后做查询重写,转化为SQL语句select order_id, order_sn, source from orders_01 where user_id = 1001,这种查询重写功能很多中间件都已经实现了,常用的就是 sharding-sphere 或者 sharding-jdbc 都可以实现。
按日期分表
这种使用方式比较普遍,尤其是按照日期维度的拆分,其实在程序层面的改动很小,但是扩展性方面的收益很大。
- 日维度拆分,如test_20191021
- 月维度拆分,如test_201910
- 年维度拆分,如test_2019
例如对于账务或者计费类系统,每天晚上都会做前一天的日结或日账任务,每月的1号都会做月结或月账任务,任务执行完之后相关表的数据都已静态化了(业务层不需要这些数据),根据业务的特性,可以按月创建表,比如对于账单表 bills,就可以创建按月分表(十月份表bills_202010,202011十一月份表),出完月账任务之后,就可以归档到历史库了,用于数据仓库ETL来做分析报表,确认数据都同步到历史库之后就可以删除这些表释放空间。
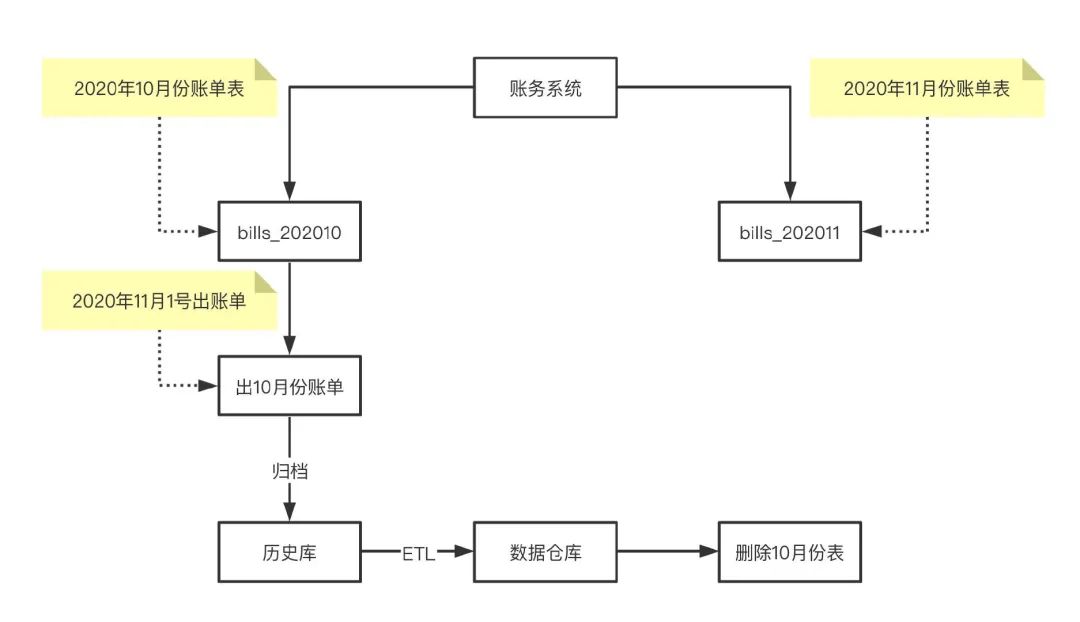
按主键范围分表
例如【1,200w】主键在一个表,【200w,400w】主键在一个表。优点是单表数据量可控。缺点是流量无法分摊,写操作集中在最后面的表。
分库方案
聊了下分表的方案,那什么时候分库呢?我们知道,MySQL 的高可用架构大多都是一主多从,所有写入操作都发生在 Master 上,随着业务的增长,数据量的增加,很多接口响应时间变得很长,经常出现 Timeout,而且通过升级 MySQL 实例配置已经无法解决问题了,这时候就要分库了。
按业务分库
举个例子,交易系统 trade 数据库单独部署在一台 RDS 实例,现在交易需求及功能越来越多,订单,价格及库存相关的表增长很快,部分接口的耗时增加,同时有大量的慢查询告警,升级 RDS 配置效果不大,这时候就需要考虑拆分业务,将库存,价格相关的接口独立出来。
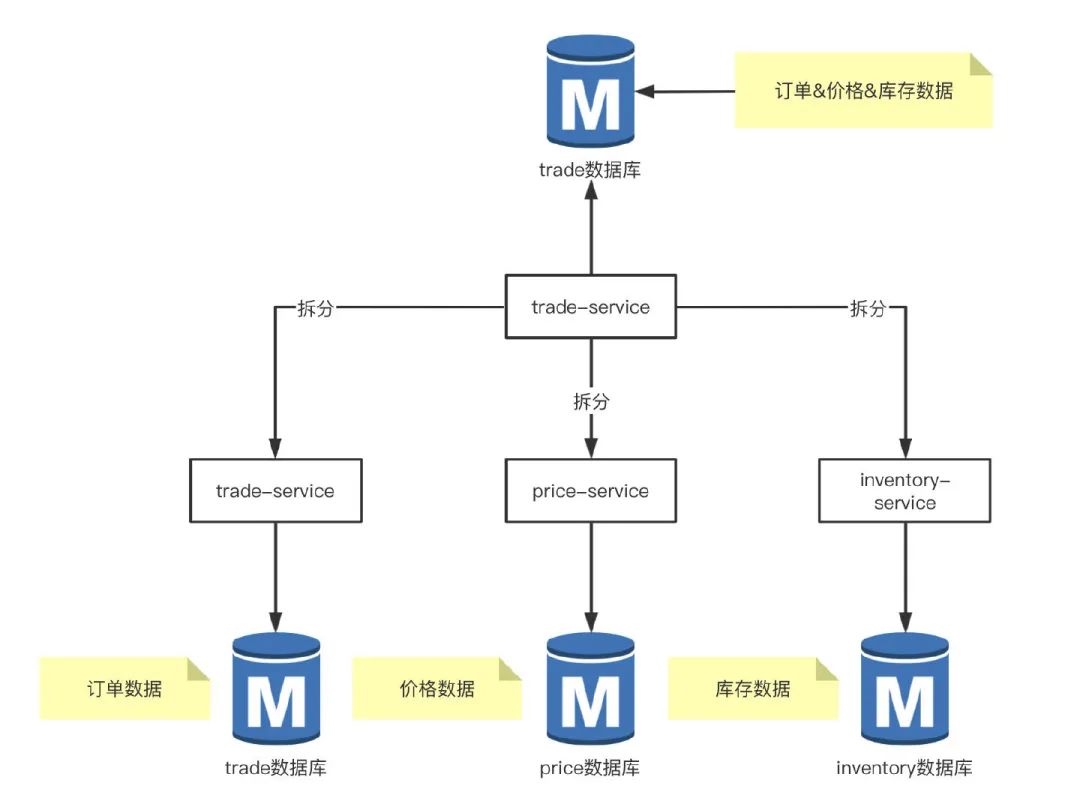
这样按照业务模块拆分之后,相应的 trade 数据库被拆分到了三个 RDS 实例中,数据库的写入能力提升,服务的接口响应时间也变短了,提高了系统的稳定性。
按表分库
上面介绍了分表方案,常见的有垂直分表和水平分表(拆分后的子表都在同一个 RDS 实例中存储),对应的分库就是垂直分库和水平分库,这里的分库其实是拆分 RDS 实例,是将拆分后的子表存储在不同的 RDS 实例中,垂直分库实际业务用的很少,就不介绍了,主要介绍下水平分库。
举个例子,交易数据库的订单表 orders 有2亿多数据,RDS 实例遇到了写入瓶颈,普通的 insert 都需要50ms,时常也会收到 CPU 使用率告警,这时就要考虑分库了。根据业务量增长趋势,计划扩容一台同配置的RDS实例,将订单表 orders 拆分20个子表,每个 RDS 实例10个。
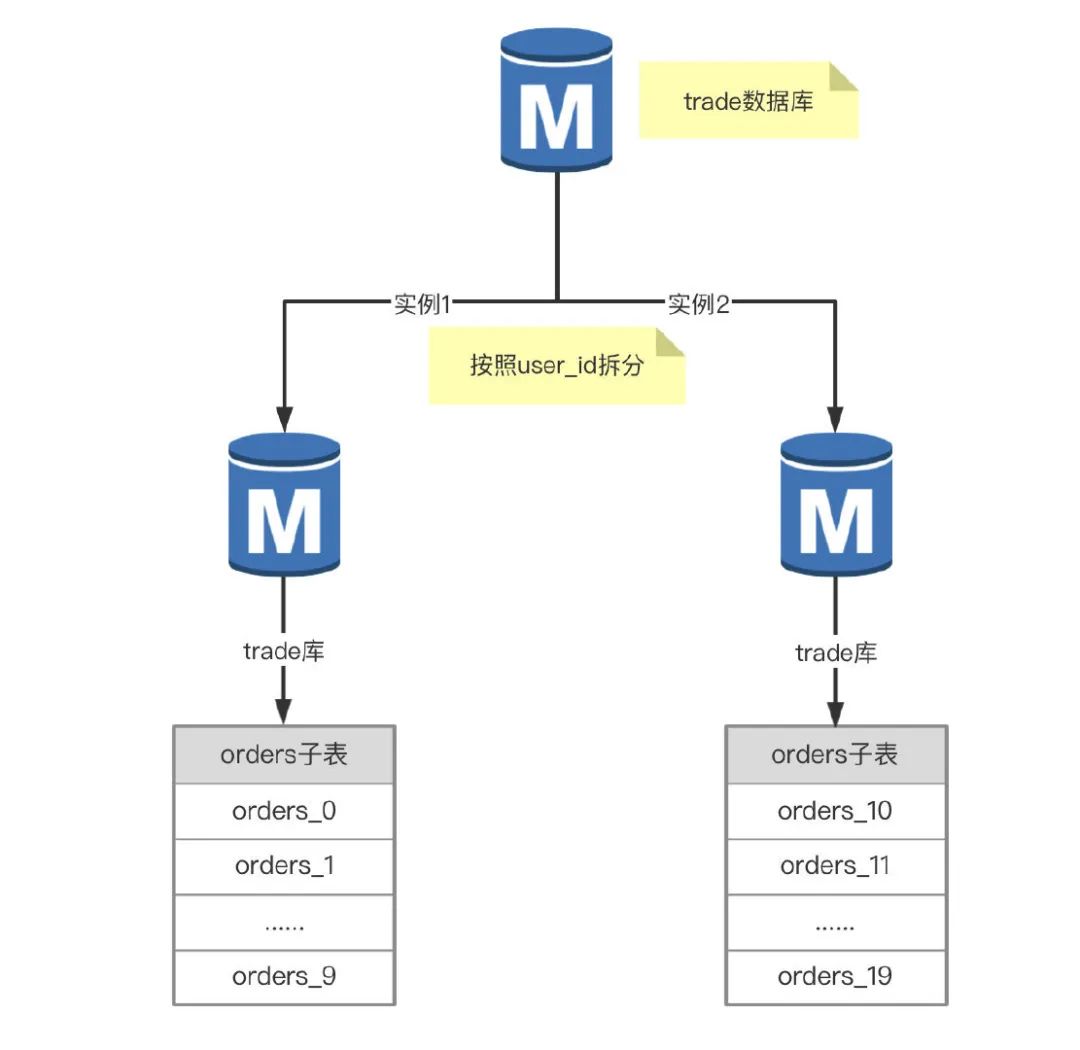 这样解决了订单表 orders 太大的问题,查询的时候要先通过分区键 user_id 定位是哪个 RDS 实例,再定位到具体的子表,然后做 DML操作,问题是代码改造的工作量大,而且服务调用链路变长了,对系统的稳定性有一定的影响。其实已经有些数据库中间件实现了分库分表的功能,例如常见的 mycat,阿里云的 DRDS 等。
这样解决了订单表 orders 太大的问题,查询的时候要先通过分区键 user_id 定位是哪个 RDS 实例,再定位到具体的子表,然后做 DML操作,问题是代码改造的工作量大,而且服务调用链路变长了,对系统的稳定性有一定的影响。其实已经有些数据库中间件实现了分库分表的功能,例如常见的 mycat,阿里云的 DRDS 等。
分片键的选择
选择最佳的分表字段是一个需要仔细考虑的问题。最佳的分表字段应该是能够让数据分布均匀、频繁查询的字段以及不可变的字段。通过选择最佳的分表字段,可以提高系统的性能和查询效率。
常用字段:
- **主键ID:**频繁查询并且唯一,非常适合作分表字段。例如,在用户表中,用户ID作为分表字段是一个不错的选择,因为用户ID是唯一的,而且在查询用户信息时经常会用到。
- **时间字段:**如果业务需要按时间范围查询数据,那么选择时间字段作为分表字段是合理的。例如,在日志表中,可以选择时间戳字段作为分表字段,以便按天、按月或按年分割数据,方便查询和维护。
- **地理信息字段:**如果业务需要按地区查询数据,那么选择地理信息字段作为分表字段是合适的。例如,在订单表中,可以选择订单地区字段作为分表字段,以便将订单数据按地区进行拆分,方便查询和扩展。
- **关联字段:**如果业务需要频繁进行关联查询,那么选择订单号等关联字段作为分表字段。例如,在订单表中,可以选择订单号作为分表字段,因为订单号唯一且包含业务信息,并且日常查询、关联查询都是根据订单号查询的,很少根据id查询,方便查询和维护。
选择分表字段的原则:
\1. 数据分布均匀
最佳的分表字段应该是能够让数据分布均匀的字段,这样可以避免某个表的数据过多,导致查询效率降低。在用户表中,如果以地区作为分表字段,可能会导致某些地区的数据过多,而某些地区的数据过少。
2. 频繁查询的字段
尽量选择查询频率最高的字段(例如主键id),然后根据表拆分方式选择字段。在一个订单表中,如果经常需要根据用户ID查询订单信息,那么以用户ID作为分表字段是一个不错的选择。
3. 不可变字段
最佳的分表字段还应该是不可变的字段,这样可以避免在数据迁移时出现问题。在一个商品表中,如果选择以商品名称作为分表字段,那么当商品名称发生变化时,就需要将数据移动到不同的表中,这样会增加系统的复杂度。
查询重写
修改代码里的查询、更新语句,以便让其适应分库分表后的情况。通常查询重写是通过一些工具来自动实现,比如 jdbc sharding,mycat 等
查询语句改造:
- **单库查询改为跨库查询:**对于需要查询的字段,需要明确指定查询的库和表,以避免查询到错误的数据。例如,原来的查询语句 “SELECT * FROM users WHERE id = 1” 可以修改为 “SELECT * FROM db.table_name WHERE id = 1”,其中 db 为目标数据库,table_name 为目标表。
- **单表查询改为跨表查询:**例如投诉记录表根据哈希取余的方式分成10个表,如果id%1=0,则查0号表complaint_records_0。
可能出现的问题
- 分布式全局唯一 ID
MySQL InnoDB的表都是使用自增的主键ID,分库分表之后,数据表分布不同的分片上,如果使用自增 ID 作为主键,就会出现不同分片上的主机 ID 重复现象,可以利用 Snowflake 算法生成唯一ID。
- 分片键的选择
选择分片键时,需要先统计该表上的所有的 SQL,尽量选择使用频率且唯一值多的字段作为分片键,既能做到数据均匀分布,又能快速定位到数据位置,例如user_id,order_id等。














![P2048 [NOI2010] 超级钢琴(纪念紫题)](https://i-blog.csdnimg.cn/direct/b714a779fc7642109b7609842f063043.png)

