索引
官方的定义索引是一种数据结构,从生活维度讲,假如将一本书看成是一张表, 这本书的目录就是表中的索引(Index).在数据库中数据量比较大时,为了快速找到们需要的数据可以使用索引,这样可以提高查询的效率,开发过程中,如果发现查询时频繁使用到的字段,也可以添加索引进行优化
缺点
- 索引会占用额外的存储空间(InnoDB索引和数据存储一起)
- 对更新操作会带来一定的复杂度.(更新记录时需要更新索引)
- 某一字段的索引过多时,不指定索引可能会比较慢
使用场景
索引一般应用于查询操作中,用于提高查询的效率,例如索引可以应用于如下子句的优化逻辑中。
- on 子句
- where 子句
- group by 子句
- having 子句
- order by 子句
索引的SQL操作数据库与SQL
索引存储结构
索引的分类
- 逻辑应用维度 (主键,普通,联合,唯一,空间索引,…)
- 物理存储维度 (聚簇索引-索引和数据存一起,非聚簇索引-索引和数据分开存储)
- 数据存储结构维度(hash,B+Tree,…)
B+树索引、全文索引、Hash索引
B+树索引并不能找到一个给定键值的具体行。B+树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读入到内存,再在内存中进行查找。
哈希索引是自适应的,InnoDB会根据表的使用情况自动为表生成哈希索引,但也可以人为干预生成哈希索引
B+树与B树比较
B+树的进化流程
二叉树->平衡二叉树->排序二叉树->红黑树->多叉树->B树->B+树
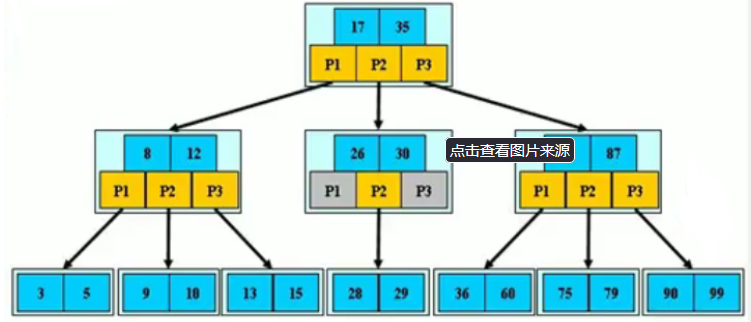
B+树相比于B树的优点
- 一个磁盘可以存储索引数量会更多.(B+树非叶子节点不存储数据,只有索引和指针)
- 相同数据量的B+树相对于B树的高度相对会比较低(因为分叉多了)
- 叶子节点之间B+树有双向链表的连接,可以支持快速的范围查询.
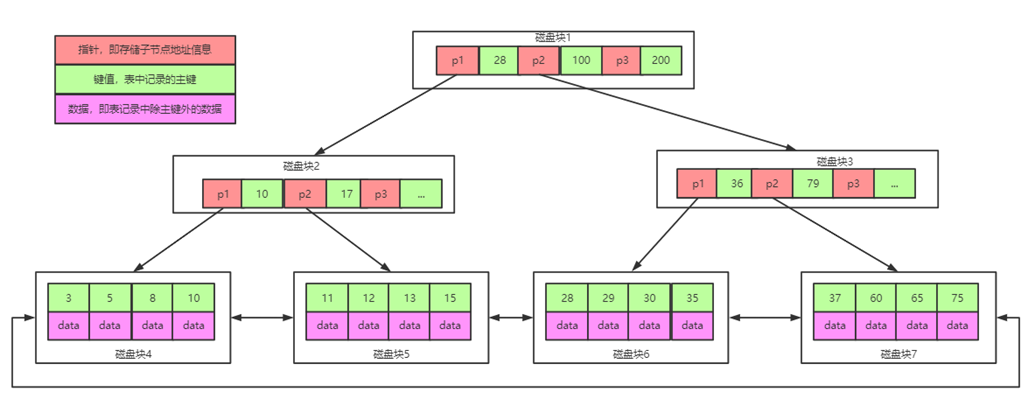
上图是B树,Mysql中的B树是会将data数据存储在树枝节点的,所以当数据量不断增大,树枝节点不仅存放了数据又存放了子节点指针,导致了树的高度不断增加,加剧了搜索消耗资源
下图是B+树,相比于B树,B+树的树枝节点只存放指针和范围,将所有的数据存储在叶子节点,并且叶子节点之间使用双向链表,这样不仅降低了树的高度,还提高了变量和范围查询的速度
B+树操作
B+树的插入
- 当插入位置的叶子页未占满。那么可以直接插入到具体的位置。
- 如果插入的位置的叶子页占满,但是上一级的索引未被占满,那么将当前叶子页的中间数找出,将其放入索引页中,当前页分为两页,小于此中间数的放在左边,大于放右边。转变如下
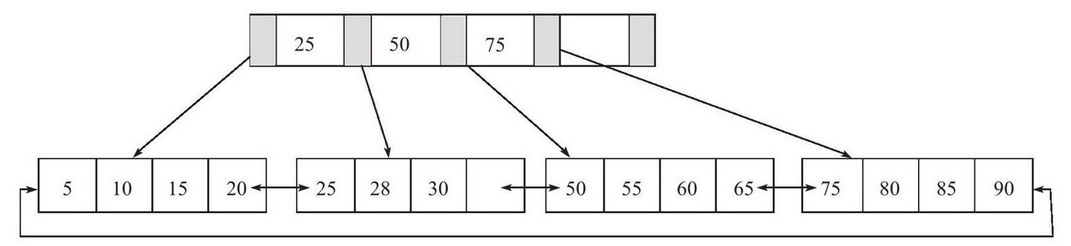
- 插入70
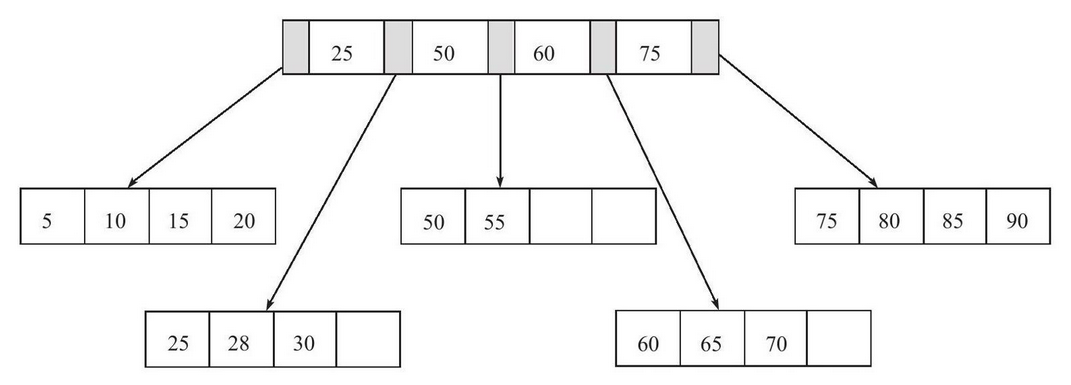
- 如果插入位置的叶子页占满,同时索引页也被占满,那么就会将索引页和叶子页同时拆分。如下的转变
- 插入95
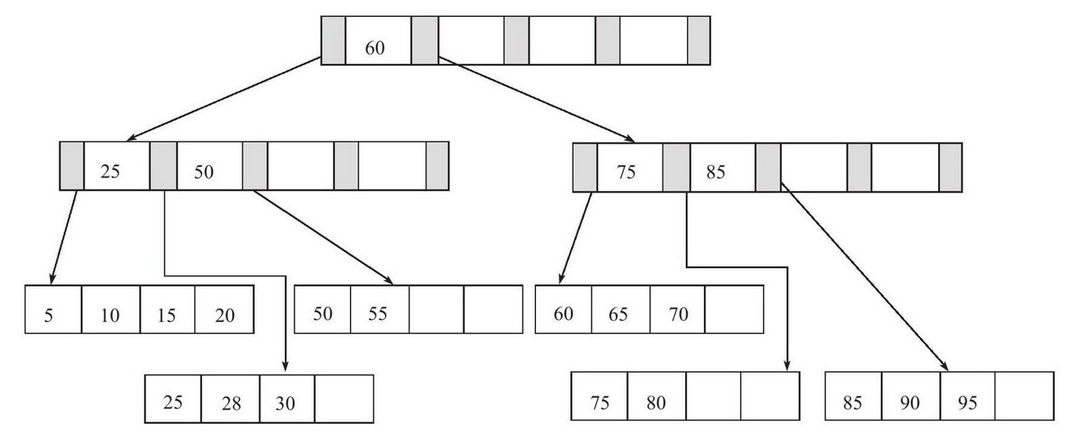
- 除了拆分,InnoDB还会将数据进行类似于平衡二叉树的旋转,将数据向当前插入叶子的节点的左续节点转移,空余出的位置就拿来存放数据。
B+树的删除
- B+树使用填充因子(fill factor)来控制树的删除变化,50%是填充因子可设的最小值。
- 当叶子节点大于填充因子,中间节点也大于填充因子
- 直接将记录删除,如果此记录还是索引页的节点,则用该记录的右节点替代
- 叶子节点小于填充因子,中间节点大于填充因子
- 合并叶子节点和它的兄弟节点,同时更新索引页
- 叶子节点小于填充因子,中间节点小于填充因子
- 合并叶子节点和它的兄弟节点,同时更新索引页,再合并索引页以及索引页的兄弟节点。
Hash索引有什么优势和劣势
hash索引的等值查询效率比较高,但是不支持范围查询.
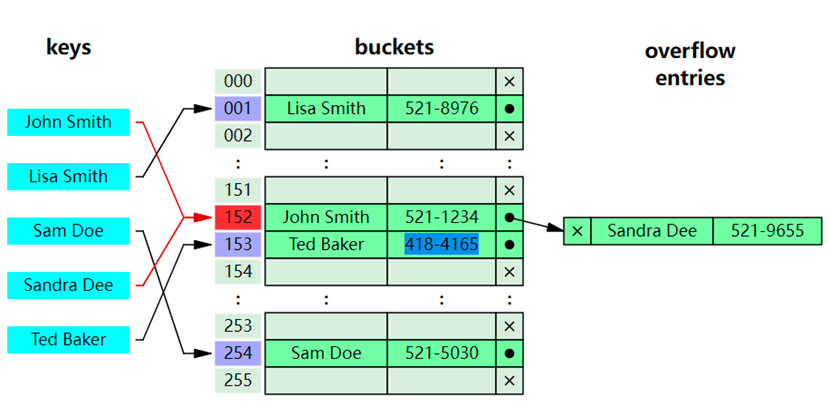
聚簇索引和非聚簇索引
- 聚簇索引:聚簇索引也叫聚集索引,索引和数据存储在一起,也就是索引与数据是不分离。 InnoDB存储引擎就是聚簇索引。
- 非聚簇索引:非聚簇索引是索引与数据是分离的,索引和数据是单独存储的。MyISAM存储引擎是非聚簇索引。
- 非聚簇索引结构 —索引结构只不过叶子结点存放的数据地址
- 非聚簇索引寻找数据时,如果查询的数据不完全在此索引的数据节点中还会回表查询
创建索引注意Cardinality的值
什么是Cardinality
| id | age | sex |
|---|---|---|
| 1 | 21 | M |
| 2 | 22 | M |
| 3 | 23 | F |
- Cardinality主要是表示索引中不重复的记录数量,如上,如果用sex列作为索引,那么它的Cardinality值为2,表示有两列值是不同的,相当于使用set去重。
- Cardinality值/总行数越接近1属于拥有高选择性,使用B+树非常合适,其次不然。
Cardinality的统计
- 在大表的情况下Cardinality统计是一件非常耗时的事情,因为想要知道哪些值重复,哪些值不同,想要得到精确的值只能遍历统计。
- Cardinality统计是存储引擎层进行实现,不同的存储引擎有不同的统计方式
- 在InnoDB下Cardinality统计会在以下两种情况下触发执行
- 表中1/16的数据已发生过变化。
- stat_modified_counter>2 000 000 000。->避免对某几行数据频繁更改,比如一共160行数据,某9行数据频繁更改,为了避免这种情况,innodb提出总的修改次数>2 000 000 000也会触发
- 需要知道的是,InnoDB并不会在每一次的insert和update都去统计,因为同样很耗时。
- Cardinality的统计并不是遍历统计,而是抽样统计
- 取得B+树索引中叶子节点的数量,记为A。
- 随机取得B+树索引中的8个叶子节点。统计每个页不同记录的个数,即为P1,P2,…,P8。
- 根据采样信息给出Cardinality的预估值:Cardinality=(P1+P2+…+P8)*A/8。
SQL优化
SQL优化
SQL优化原则
- 减少数据量(表中数据太多可以分表,例如超出500万,例如双11是一个小时一张订单表)
- 减少数据访问量(将全表扫描可以调整为基于索引去查询)
- 减少数据计算操作(将数据库中的计算拿到程序内存中计算)
优化的基本逻辑
- 良好SQL编码的习惯(熟悉SQL编码规范、例如避免使用select *)
- 优秀SQL的编写逻辑(例如表关联时小表驱动大表)
- 定位需要优化的慢SQL语句(耗时多长时间的SQL是慢SQL)
- 调整优化策略并进行测试。(SQL结构上的调整、索引应用)
- 按业务进行分库分表。(分表可以在应用逻辑中减少单表数据量)
优秀的SQL编写方案分享
查询时尽量避免使用select *;
- 这样可以减少数据扫描以及网络开销(很多查询不需要查询所有列)。
- 要尽量使用覆盖索引(索引中已经包含你需要的数据)、减少回表查询。
例如,如何查询会基于salary找到雇员id,然后基于雇员id再去查hire_date.(回表)
create index index_salary on employees(salary);
select employee_id,salary,hire_date
from employees
where salary>15000
- 优化方案
create index index_salary on employees(salary,hire_date);
select employee_id,salary,hire_date
from employees
where salary>15000
where子句中不使用or作为查询条件。
- or可能会使索引失效,进而执行全表扫描。
- 全表查询的效率相对基于索引查询的效率会比较低。
create index index_salary on employees(salary);
#------------------------------------------------#
select first_name,hire_date,salary
from employees
where job_id='AD_VP' or salary>15000
select first_name,hire_date,salary
from employees
where job_id='AD_VP'
union all
select first_name,hire_date,salary
from employees
where salary>15000;
where 条件中尽量不要出现与null值的比较
条件中包含和null值的比较时可能会不走索引,当然这也跟SQL优化器有关,优化器 有时会因为数据量的多少,对是否走索引进行评估,假如它认为不走索引效率可能 会更高,可能就不走索引了。
select first_name,salary,commission_pct
from employees
where commission_pct is null
避免在查询中存在隐式转换
create table tb_order
(
id int primary key,
user_id varchar(50) not null,
index index_user_id (user_id)
)
# 这里存在隐式转换,有可能不走索引 表创建的varchar,这里使用的为int
select * from tb_order where user_id=1;
select * from tb_order where user_id='2'; 推荐
避免在where子句中使用!=或者<>操作符
实际应用中这个查询是否走索引还与数据量有关。
select first_name
from employees
where job_id!='AD'
使用like查询条件时应尽量避免前缀使用"%"
select first_name,salary
from employees
where first_name like '%A%';
执行查询时尽量采用最左匹配原则?❎8.0.13加入的skip index scan解决了这个问题
MySQL的跳跃式索引
create index 'index_hire_date_salary_pct' on employees (hire_date,salary,commission_pct);
这里相当于是创建了(hire_date),(hire_date,salary),(hire_date,salary,commission_pct)三个索引
假如我们执行如下查询,可能不走索引.
select *
from employees
where salary>15000;
假如我们这样执行查询,可能会走索引.
select *
from employees
where hire_date>'2000-01-01' and salary>15000
避免在查询条件中使用一些内置的SQL函数。
select *
from employees
where year(hire_date)='2000';
注意:在mysql8.0中也可以基于函数创建索引了。
其他规则
- 假如in表达式后面的数据太多(一般不建议超过200),尽量避免使用in作为查询条件。
可以使用union all拼接
-
当有多个查询条件、分组条件、排序条件时,尽量使用联合索引(组合索引)
-
表连接时优先使用内连接(inner join),使用小表驱动大表
-
进行表关联的字段尽量使用相同的编码(不能一个字段utf8,一个字段utf8mb4)
-
表设计时字段类型能用简单数据类型不用复杂类型。
能用int就用int不用bigint
-
清空表中数据可优先使用truncate.’
-
插入多条数据时可考虑使用批量插入。
insert into regions (region_id,region_name) values (1,'A');
insert into regions (region_id,region_name) values (2,'B');
修改为
insert into regions (region_id,region_name) values (1,'A'),(2,'B');
慢SQL分析
如何定位慢SQL?
优化 SQL 的前提是能定位到慢 SQL,例如查看慢查询日志,确定已经执行完的慢查询。
基于慢SQL日志查询慢SQL?
使用慢查询日志一般分为四步:
- 开启慢查询日志(一般默认是关闭状态)
- 设置慢查询阀值(响应速度是多长时间被定为是慢查询)
- 确定慢查询日志路径(日志文件在哪里)
- 确定慢查询日志的文件名(具体日志文件是哪个),然后对文件内容进行分析。
- 查看慢查询日志的打开状态?
show variables like '%slow_query_log%';
默认环境下,慢查询日志是关闭的(OFF)。
- 如何开启慢查询日志?
set global slow_query_log=ON
- 查看默认慢查询阈值 (默认为10秒中)
show variables like '%long_query_time%';
- 如何设置慢查询的阈值?
设置慢查询时间阀值(响应时间是多长时间是慢查询)
MySQL5.7
mysql> set long_query_time = 1;
Query OK, 0 rows affected (0.00 sec)
-
如何知道慢查询日志路径?
慢查询日志的路径默认是 MySQL 的数据目录
mysql> show global variables like 'datadir';
+---------------+------------------------+
| Variable_name | Value |
+---------------+------------------------+
| datadir | /mysql/data/ |
+---------------+------------------------+
1 row in set (0.00 sec)
- 如何知道慢查询日志的文件名?
mysql> show global variables like 'slow_query_log_file';
+---------------------+----------------+
| Variable_name | Value |
+---------------------+----------------+
| slow_query_log_file | mysql-slow.log |
+---------------------+----------------+
1 row in set (0.00 sec)
- 执行一个耗时SQL,然后查看慢SQL日志
例如
select * from t1 where id between 10000 and 20000;
打开日志文件,可以对日志文件中的内容进行分析,常用选项说明:
Time:慢查询发生的时间
User@Host:客户端用户和IP
Query_time:查询时间
Lock_time:等待表锁的时间
Rows_sent:语句返回的行数
Rows_examined:语句执行期间从存储引擎读取的行数
- 如何对慢查询进行分析?
工欲善其事,必先利其器,分析慢查询可以通过 explain、show profile 等工具来实现。
执行计划(Explain)
执行计划是mysql优化器对SQL进行默认调优后,给出的一种执行方案,这个方案我们可以通过explain 这个指令进行查询。例如,对select语句进行分析,并输出select执行时的详细信息,开发人员可以 基于这些信息进行有针对性的优化,例如:
mysql> explain select * from employees where employee_id<100 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: employees
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
分析执行计划的目的
- 检查关联查询的执行顺序
- 查询操作的具体类型
- 哪些索引可能会命中以及实际命中的索引有哪些
- 每张表可能有多少条记录参与到了查询中
执行计划中相关字段说明
id
select 的序列号,有几个select 就有几个 id,id 的顺序是按 select 出现的顺序增长的。 即:id 越大执行优先级越高,id相同则从上往下执行,id 为NULL最后执行。
explain
select last_name,salary
from employees
where employee_id=(
select manager_id
from employees
where employee_id=206);
------------------------
explain
select m.first_name,m.salary
from employees e join employees m
on e.manager_id=m.employee_id
where e.employee_id=206
select_type表示的查询类型
1. SIMPLE : 表示查询语句不包含子查询或 union
2. PRIMARY:表示此查询是最外层的查询
3. UNION:表示此查询是 union 的第二个或后续的查询
4. UNION RESULT:union 的结果
5. DEPENDENT UNION:子查询中的UNION操作,UNION后的所有select都是DEPENDENT UNION。
6. SUBQUERY:SELECT 子查询语句
7. DEPENDENT SUBQUERY:子查询中的第一个SELECT,SELECT 子查询语句依赖外层查询。
8. DERIVED: from 子句后的相对比较复杂子查询(相当于一个临时表),当看到derivedN时,这里N表时查询id
案例分析> select_type为SIMPLE (表示查询语句不包含子查询或 union)
explain
select *
from employees
where employee_id<100;
select_type为PRIMARY、SUBQUERY (PRIMARY表示最外层查询,SUBQUERY表示嵌套查询)
explain
select last_name,salary
from employees
where employee_id=(
select manager_id
from employees
where employee_id=206);
select_type为 UNION(union操作)、UNION RESULT(union的结果)
explain
select first_name,hire_date,salary
from employees
where job_id='AD_VP'
union
select first_name,hire_date,salary
from employees
where salary>15000;
select_type为DEPENDENT UNION (子查询中的UNION操作,UNION后的所有select都是DEPENDENT UNION。)
explain
select *
from employees e3
where first_name in (
select first_name
from employees e1
where job_id = 'AD_VP'
union
select first_name
from employees e2
where salary > 15000
)
select_type 为 DEPENDENT SUBQUERY
求每个部门中薪资最高的那个雇员的信息(雇员id,名字,薪水)
explain
selectfirst_name,salary
from employees e1
where salary=( employee_id,
select max(salary)
from employees e2
where e1.department_id=e2.department_id);
说明,一般出现DEPENDENT SUBQUERY时,SQL的执行效率都会比较低,可以调整为多表查询,例如:
explain
select e2.department_id,e2.employee_id,e2.first_name,e2.salary
(
select department_id,max(salary) max_salary
from employees
group by department_id) e1 join employees e2
e1.department_id=e2.department_id
where e1.max_salary=e2.salary
select_type为DERIVED(这里一般表示from后面的一个衍生表-临时表)
explain
select min(avg_salary)
from (
select avg(salary) avg_salary
from employees
group by department_id) emp;
type表示查询数据的方式。(重点)
type是一个比较重要的一个属性,通过它可以判断出查询是全表扫描还是基于索引的部分扫描。 常用属性值如下,从上至下效率依次增强。调优时,建议type类型至少要为range,才能提高 查询效率。
- ALL:表示全表扫描,性能最差。(数据量小时无所谓)
- index:表示基于索引的全表扫描,先扫描索引再扫描全表数据。
- range:表示使用索引范围查询。使用 >、>=、<、<=、in 等等。
- index_merge: 表示查询中实用到了多个索引,然后进行了索引合并
- ref:表示使用非唯一索引进行单值查询。
- eq_ref:一般情况下出现在多表 join 查询,表示前面表的每一个记录,都只能匹配后面表的一行结果。
- const:表示使用主键或唯一索引做等值查询,常量查询。(效率非常高)
- NULL:表示不用访问表,也没有索引,速度最快。(了解,例如select version())
案例分析:> type为null
explain
select now()
type 为const (基于主键或唯一键执行的查询)
explain
select *
from employees
where employee_id=206
type 为eq_ref (多表join,前面表的每一行记录,只能匹配后面表的一行记录)
explain
select d.department_id,d.department_name,e.first_name
from departments d join employees e on d.manager_id = e.employee_id;
type为 ref (使用非唯一索引进行的等值查询)
create index index_first_name on employees(first_name);
explain
select *
from employees
where first_name='Steven';
create index index_salary on employees (salary);
explain
select salary,first_name from employees where salary=17000;
type 为 index_merge (索引合并,同时应用两个索引)
create index index_salary on employees(salary);
explain
select first_name,hire_date,salary
from employees
where job_id='AD_VP' or salary>15000;
type 为 range (这里的range表示一个范围查询)
create index index_salary on employees (salary);
explain
select first_name,salary
from employees
where salary between 10000 and 30000;
type 为index (基于索引的全表扫描)
explain
select count(*)
from employees
group by department_id;
type 为 all (表示全表扫描)
explain
select *
from employees
Extra中值的含义是什么?
Extra 表示很多额外的信息,各种操作会在 Extra 提示相关信息,常见几种如下:
Using where 表示查询需要通过where条件查询数据(可能没有用到索引,也可能一部分用到了索引)。
explain
select *
from hr.employees
where salary>10000;
Using index 表示查询需要通过索引,索引就可以满足所需数据(不需要再回表查询,这里出现了索引覆盖)。
create index index_hire_date_salary on employees(hire_date,salary);
explain
select employee_id,hire_date,salary
from hr.employees
where hire_date>'2000-03-06' and salary>10000;
Using filesort 表示查询出来的结果需要额外排序,数据量小在内存,大的话在磁盘,因此有 Using filesort 建议优化。
explain
select first_name,hire_date,salary
from hr.employees
order by hire_date
Using temprorary 查询使用到了临时表,一般出现于去重、分组等操作(这里一般也需要优化)。
explain
select first_name,salary
from hr.employees
where first_name like 'A%'
union
select first_name,salary
from hr.employees
where first_name like 'B%'
Using index condition 表示查询的记录,在索引中没有完全覆盖(可能要基于where或二级索引对应的主键再次查询-回表查询)。
create index index_hire_date_salary on employees (hire_date,salary)
explain
select employee_id,hire_date,salary,commission_pct
from hr.employees
where hire_date>'2000-03-06' and salary>10000;
性能分析工具(Profile)应用(了解)
什么是Profile?
Profile 是MySQL内置的一个性能分析工具,基于Profile可以更好的了解SQL执行过程中的资源情况。
例如你的CPU,内存,IO等
如何使用Profile?
- 确定你的数据库是否支持Profile。
- 确定Profile是否是关闭的,假如是关闭的需要先开启。
- 执行SQL语句
- 查看执行SQL的query id。
- 通过query id查看SQL每个状态的耗时时间。
确定数据库是否支持Profile?
select @@have_profiling
假如查询结果为yes表示支持。
确定Profile是否是关闭的?
select @@profiling
假如查询结果为0表示没有开启。
开启和查看Profile
set profiling=1
- 执行SQL语句?
select * from employees where salary>5000;
- 查看SQL的query id?
show profiles;
- 查看具体SQL的执行详情?
show profile for query 1;
- Show Profile的常用查询选项
ALL:显示所有的开销信息。
BLOCK IO:显示块IO开销。
CONTEXT SWITCHES:上下文切换开销。
CPU:显示CPU开销信息。
IPC:显示发送和接收开销信息。
MEMORY:显示内存开销信息。
PAGE FAULTS:显示页面错误开销信息。
SOURCE:显示和Source_function,Source_file,Source_line相关的开销信息。
例如
show profile CPU,block io for 6













![P2048 [NOI2010] 超级钢琴(纪念紫题)](https://i-blog.csdnimg.cn/direct/b714a779fc7642109b7609842f063043.png)


![Python 【机器学习】 进阶 之 【实战案例】房价数据中位数分析 [ 项目介绍 ] [ 获取数据 ] [ 创建测试集 ]| 1/3(含分析过程)](https://i-blog.csdnimg.cn/direct/ddd12dffa79646d3adb51a9486c84992.png)
