目录
- 前言
- 一,确定目标
- 二,发送请求
- 三, 解析数据
- 四, 保存数据
- pyecharts进行可视化
- “某站”数据排名前10视频类型
- “某站”标题标签可视化
- “某站”喜欢视频分类概况
- 总结
前言
本项目将会对“某站”热搜排行的数据进行网页信息爬取以及数据可视化分析 本教程仅供学习参考!
首先,准备好相关库
requests、pandas、pyecharts等
因为这是第三方库,所以我们需要额外下载
下载有两种方法(以requests为例,其余库的安装方法类似):
pip install requests

点击回车后,就会自动帮我们进行安装,如果有的同学安装过程中是非常慢,半天看不到效果,建议大家可以使用镜像文件:在指令中添加-i 网址
pip install numpy -i https://mirrors.aliyun.com/pypi/simple/
常见镜像有:
镜像名称 网址
阿里云 https://mirrors.aliyun.com/pypi/simple/
豆瓣 https://pypi.douban.com/simple/
清华大学(推荐) https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学 http://pypi.hustunique.com/
山东理工大学 http://pypi.sdutlinux.org/
这些都是我们在准备工具,准备好工作后,我们就可以开始进行我们的爬虫工作啦.
一,确定目标

import requests
# 1确定目标
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"}
url="https://api.某站(自己可以找到网址,平台不允许放).com/x/web-interface/popular?ps=20&pn=1"
二,发送请求

response=requests.get(url=url,headers=headers)
三, 解析数据

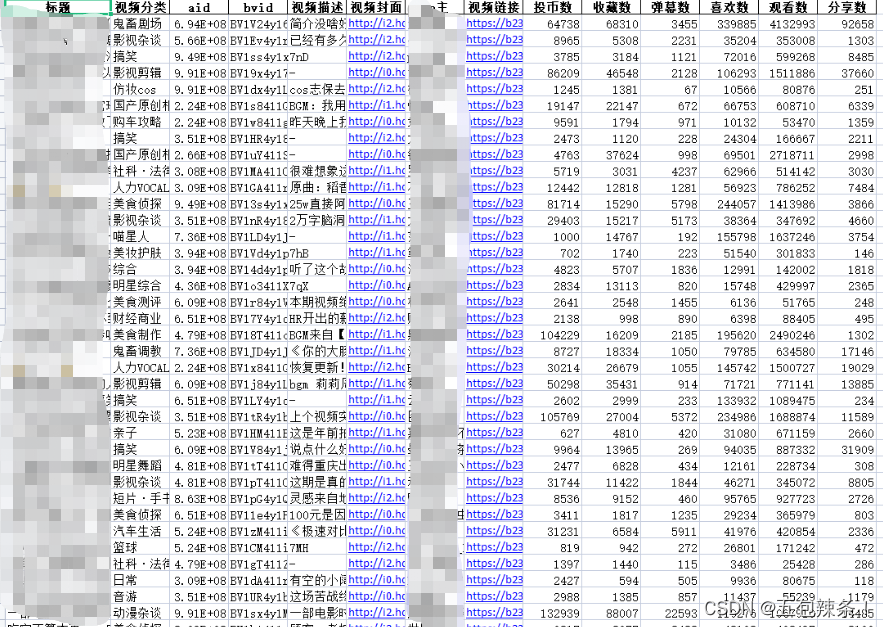
datas=response.json()['data']['list']
results=[]
for data in datas:
result={
'标题':data['title'],
'视频分类':data['tname'],
'aid':data['aid'],
'bvid': data['bvid'],
'视频描述': data['desc'],
'视频封面': data['pic'],
'up主': data['owner']['name'],
'视频链接': data['short_link'],
'投币数': data['stat']['coin'],
'收藏数': data['stat']['favorite'],
'弹幕数': data['stat']['danmaku'],
'喜欢数': data['stat']['like'],
'观看数': data['stat']['view'],
'分享数': data['stat']['share'],
}
results.append(result)

四, 保存数据
import pandas as pd
df=pd.DataFrame(results)
df.to_excel("某站数据01.xlsx",index=False)
 ]
]
pyecharts进行可视化
爬虫到这里就结束了,接下来,我们就通过pyecharts进行可视化吧
先进行数据读取
import pandas as pd
data=pd.read_excel("./B站.xlsx")
print(data)
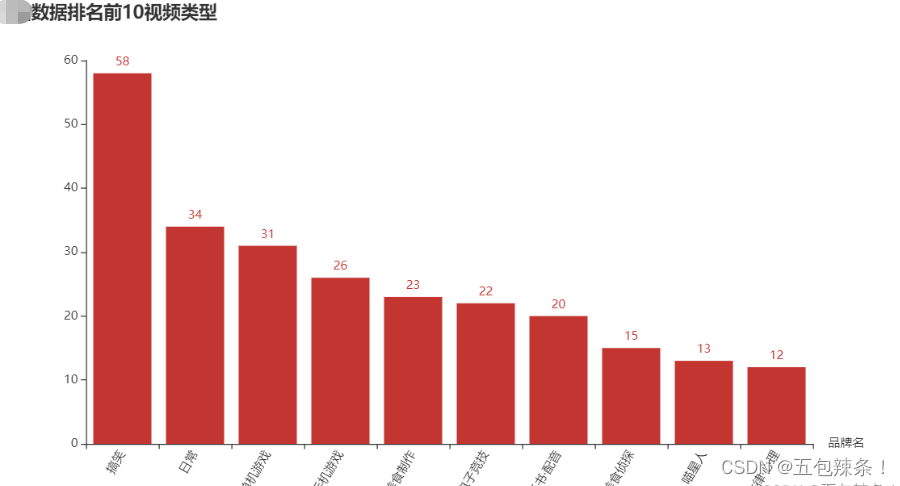
“某站”数据排名前10视频类型
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = (Bar()
.add_xaxis(sp_data)
.add_yaxis('',sl_data)
.set_global_opts(title_opts=opts.TitleOpts(title="B站数据排名前10视频类型"),xaxis_opts=opts.AxisOpts(name_rotate=0,name="品牌名",axislabel_opts={"rotate":60}))
)
bar.render_notebook()
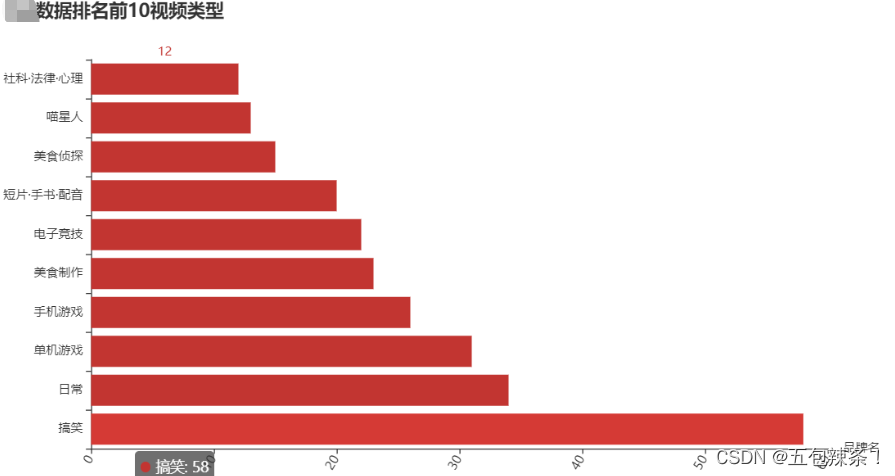
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = (Bar()
.add_xaxis(sp_data)
.add_yaxis('',sl_data)
.reversal_axis()
.set_global_opts(title_opts=opts.TitleOpts(title="B站数据排名前10视频类型"),xaxis_opts=opts.AxisOpts(name_rotate=0,name="品牌名",axislabel_opts={"rotate":60}))
)
bar.render_notebook()
“某站”标题标签可视化
from pyecharts import options as opts
from pyecharts.charts import Page, WordCloud
from pyecharts.globals import SymbolType
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", most_common_words, word_size_range=[20, 100])
.set_global_opts(title_opts=opts.TitleOpts(title="B站标题标签可视化"))
)
return c
wd = wordcloud_base()
wd.render_notebook()

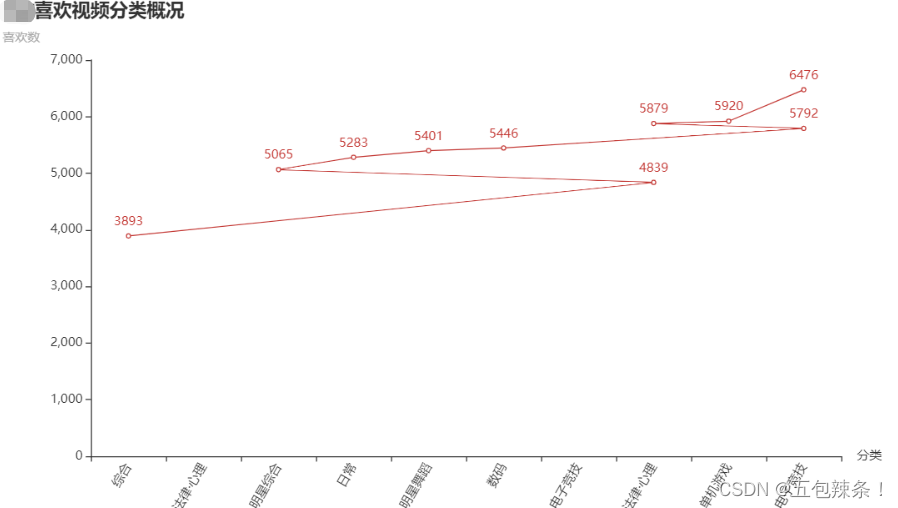
“某站”喜欢视频分类概况
from pyecharts.charts import Line
line = (Line()
.add_xaxis(rea)
.add_yaxis('',res)
.set_global_opts(title_opts=opts.TitleOpts(title="B站喜欢视频分类概况", subtitle="喜欢数"),xaxis_opts=opts.AxisOpts(name_rotate=0,name="分类",axislabel_opts={"rotate":60}))
)
line.render_notebook()
总结
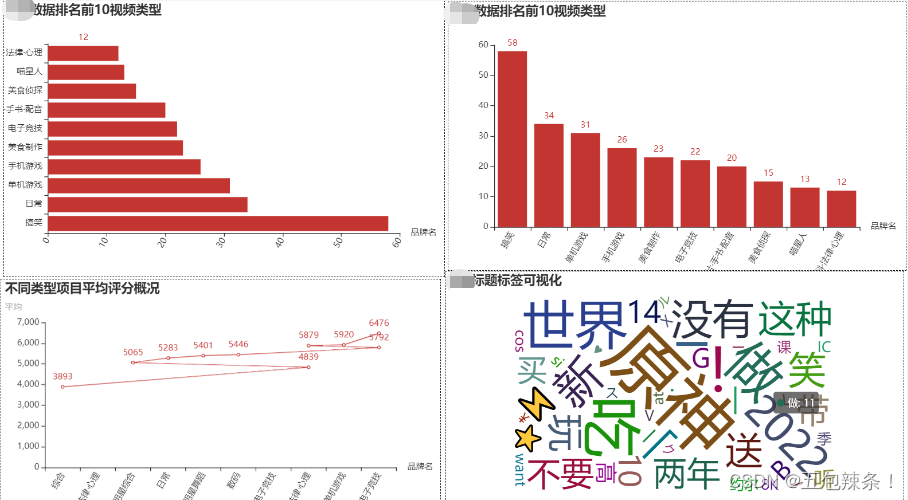
这些就是我们通过python爬虫爬取下来的数据,进行可视化的一个分析,你可以通过图看出什么效果呢。除了这些可视图可以单个放,我们也可以把这些图进行合并,变成我们传说中的大屏.
代码如下:
page = Page(layout=Page.DraggablePageLayout)
# 在页面中添加图表
page.add(
bar2_world(),
bar1_world(),
line1_world(),
wordcloud_base(),
)
page.render('test1.html')
想要源码的同学,可以后台私信我一下哈