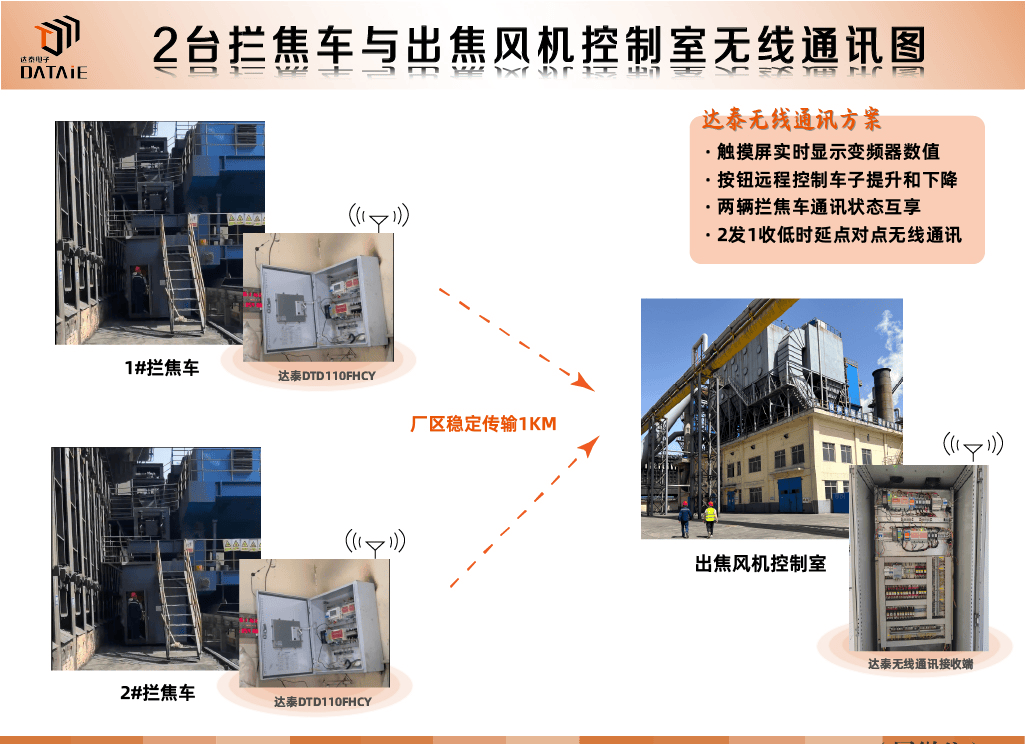
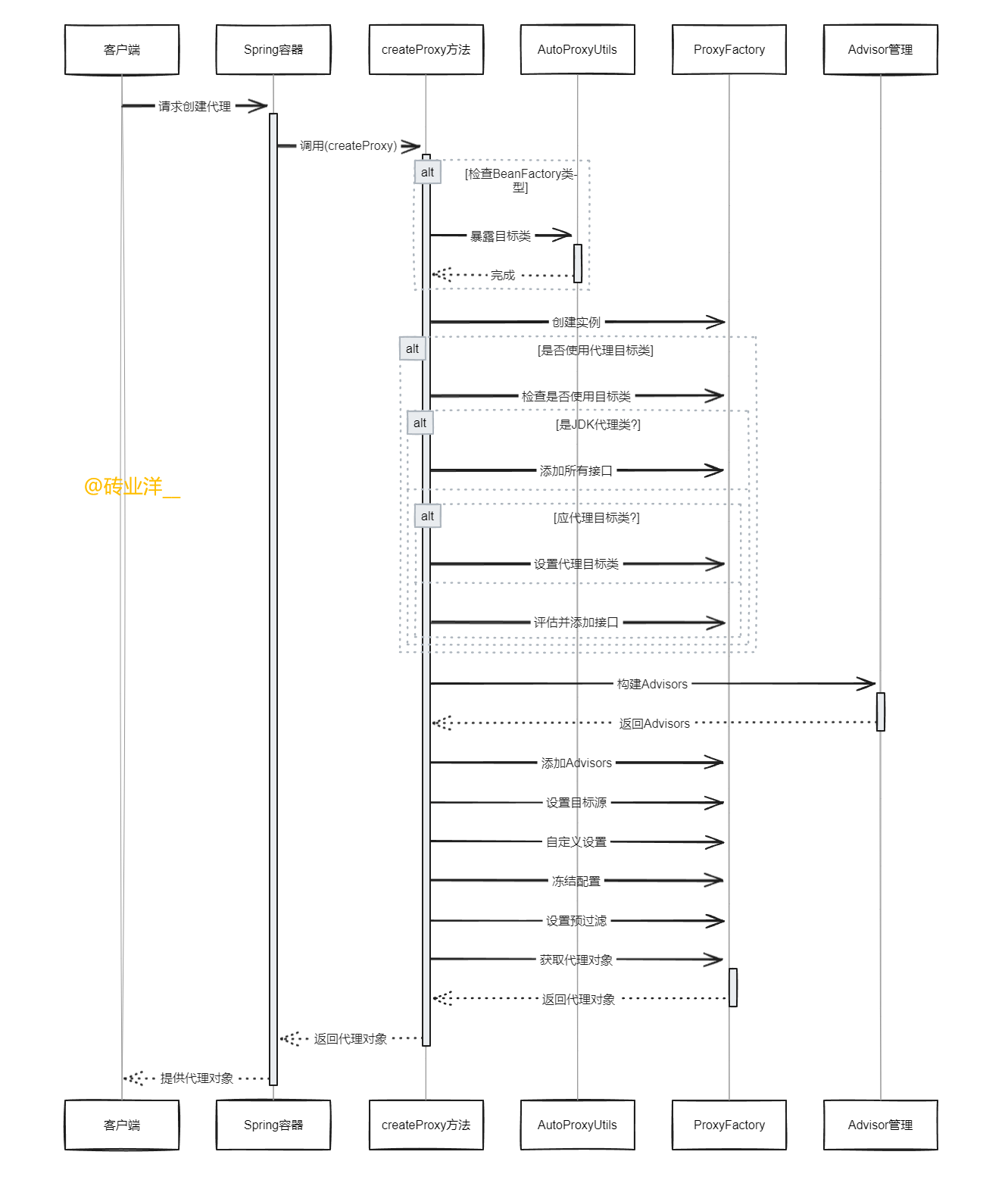
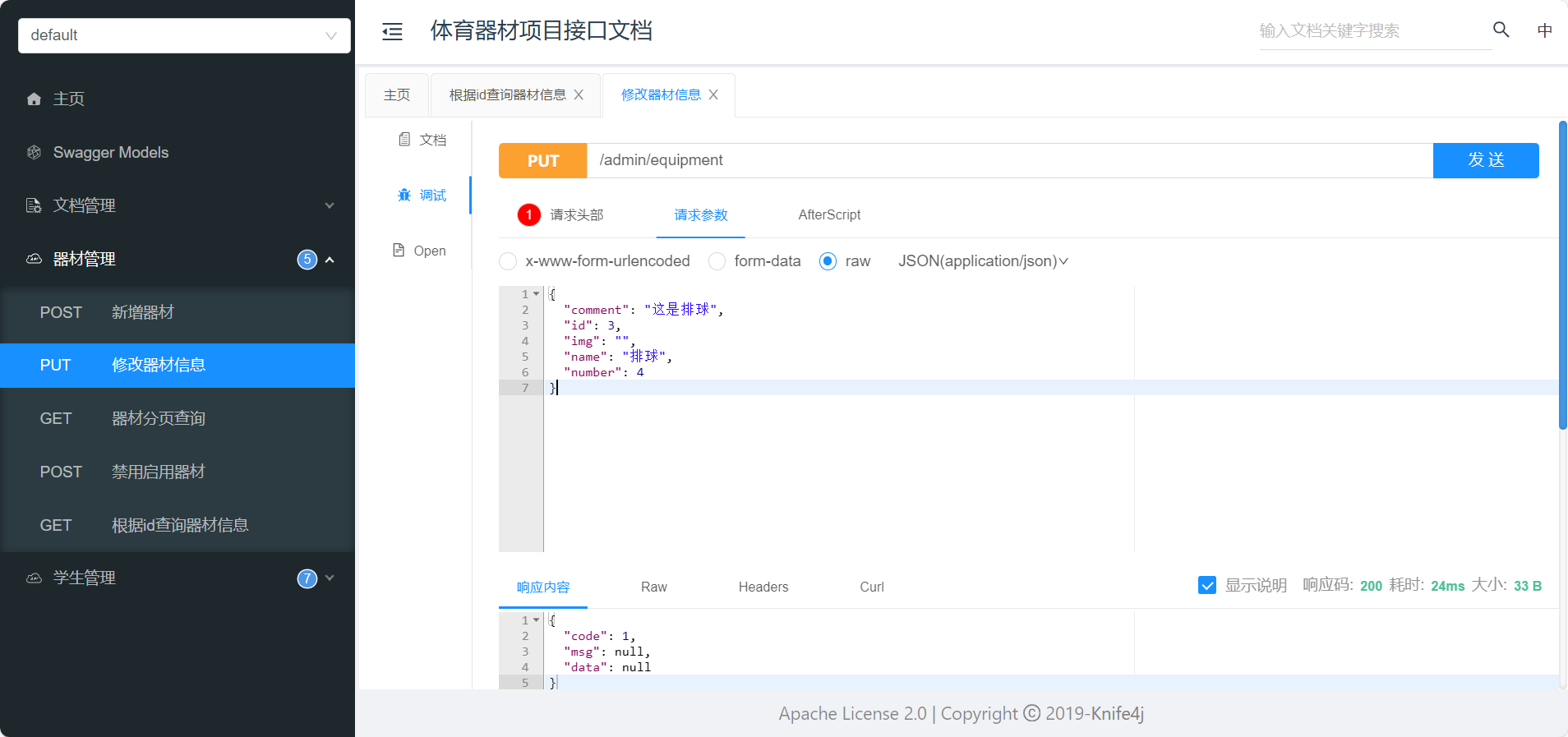
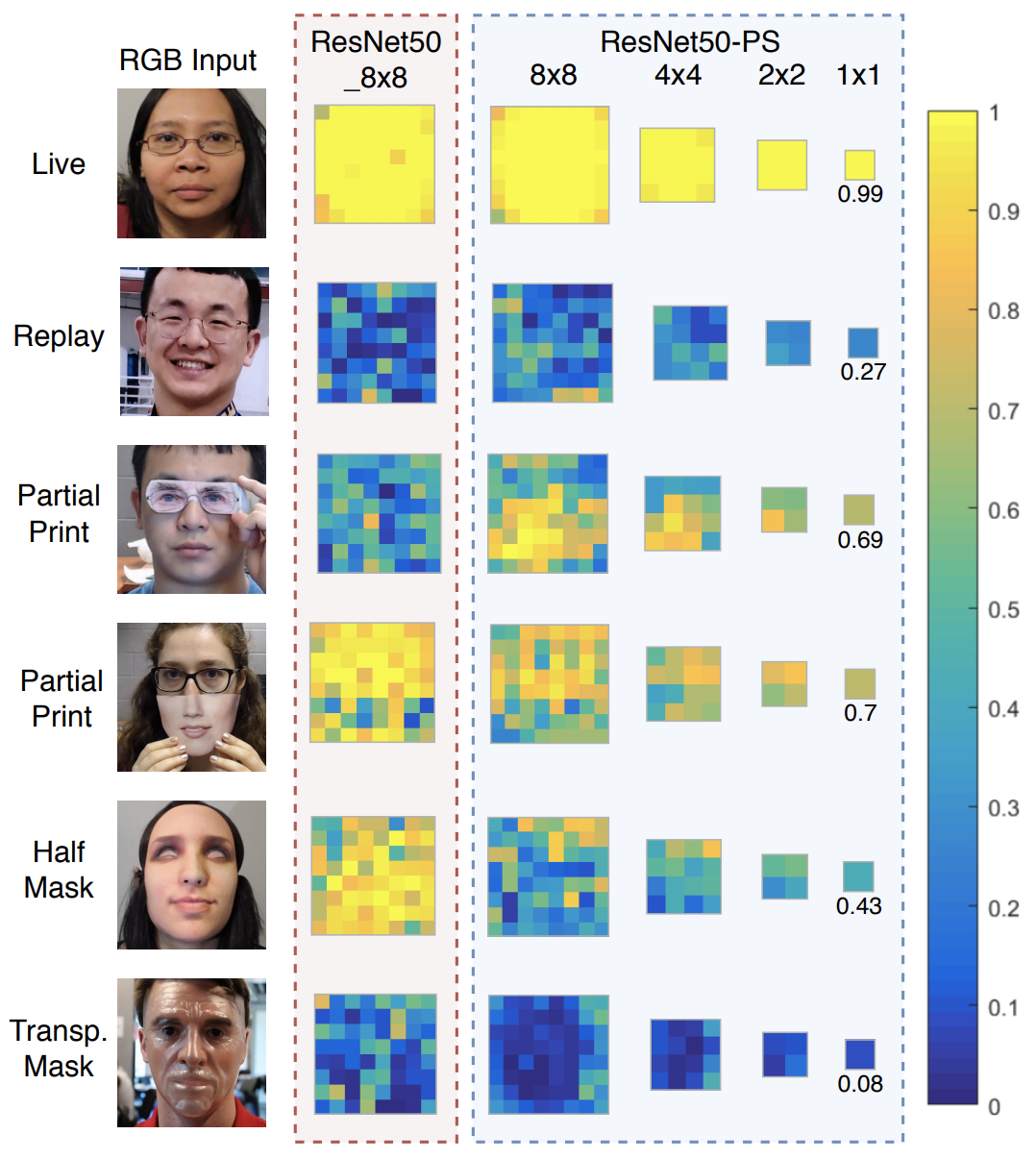
RNN
用于解决输入数据为,序列到序列(时间序列)数据,不能在传统的前馈神经网络(FNN)很好应用的问题。时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度,即输入内容的上下文关联性强。
整体结构
x、o为向量,分别表示输入层、输出层的值;U、V为权重矩阵,U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵,W 是上一次的值 S(t-1) 作为这一次的输入的权重矩阵,S(t)是当前的隐藏层矩阵。
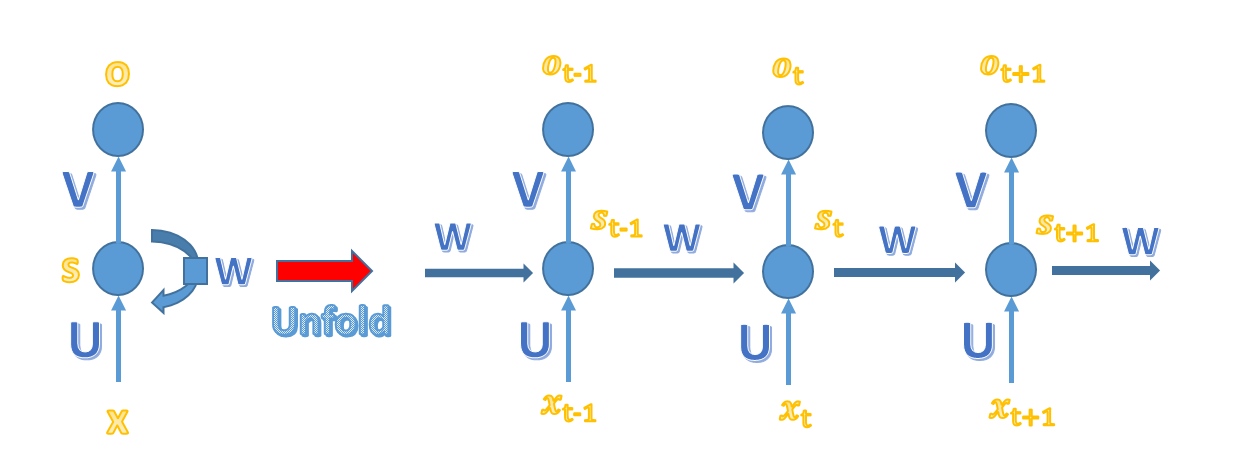
RNN层结构与计算公式
RNN层计算公式
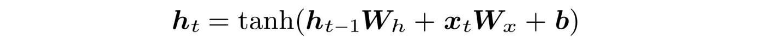
RNN层正向传播
MatMul表示矩阵乘积。
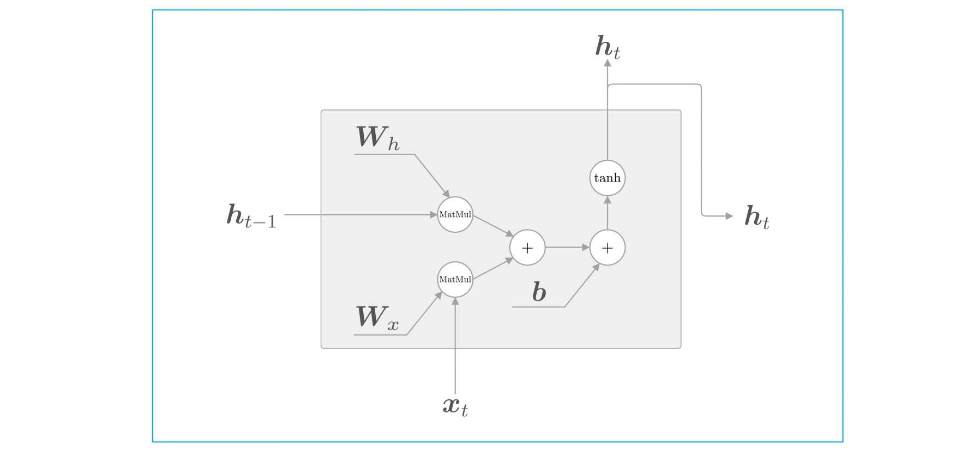
这里的h也就是s,都是RNN层函数的输出结果。RNN层的处理函数是tanh,输出结果是h,因此RNN层具有"状态",这也是其具有记忆性的原因。
RNN隐藏层的输出结果,也被称为隐藏状态或是隐藏状态向量,一般用h或s表示。
RNN层反向传播
蓝线表示反向传播的线路图
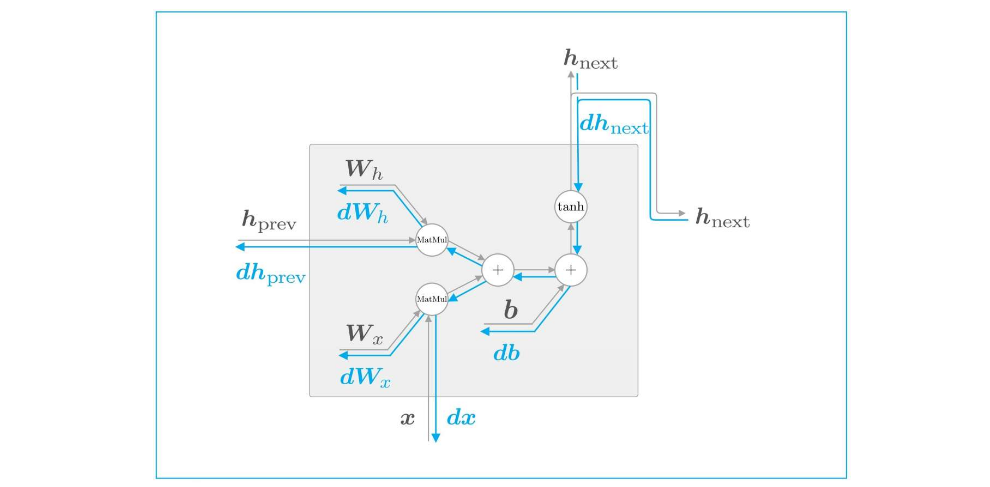
带来的问题
由于激活函数Tanh其反向传播时,会导致梯度为0或趋于很大的数值,导致梯度消失或爆炸。
LSTM
通过引入输入门、遗忘门和输出门,解决RNN模型下带来的梯度消失的问题。
整体结构
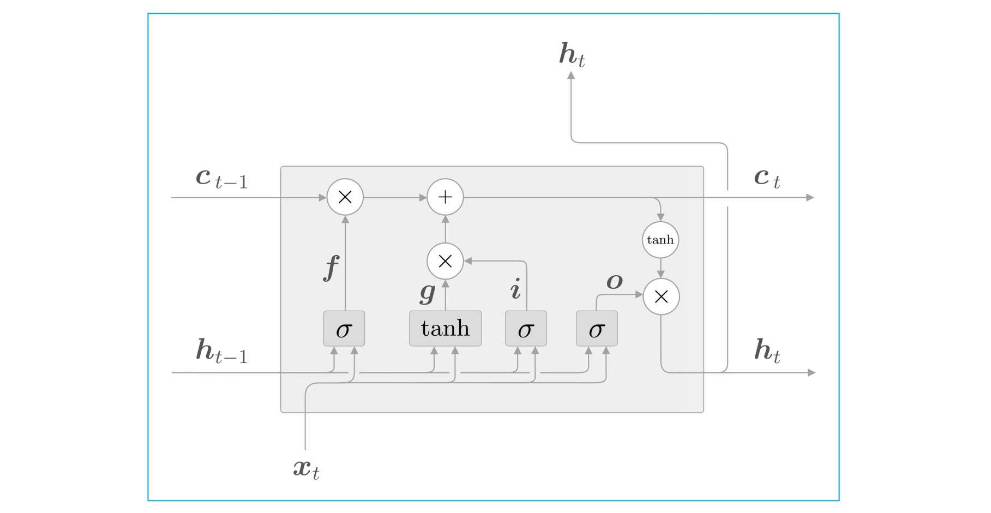
输出门的结果用o来表示,其计算公式如下:
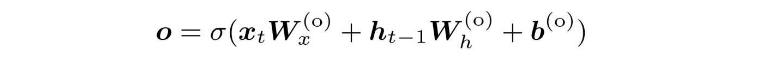
遗忘门的结果用f表示,其计算公式如下:
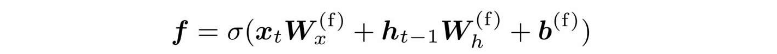
输入门的结果用i表示,其计算公式如下:
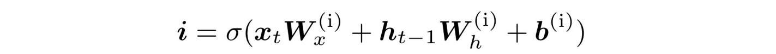
遗忘门从上一时刻的记忆单元中删除了应该忘记的东西,但需要添加一些应当记住的新信息,新的记忆单元g,其计算公式如下:
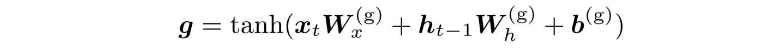
要注意的是,不同的门输出所代表的意义不一样,因为其最后流向的地方不一样,分别是转换为了新的记忆单元c,新的隐藏状态h。
最终汇总后的整体结构如下
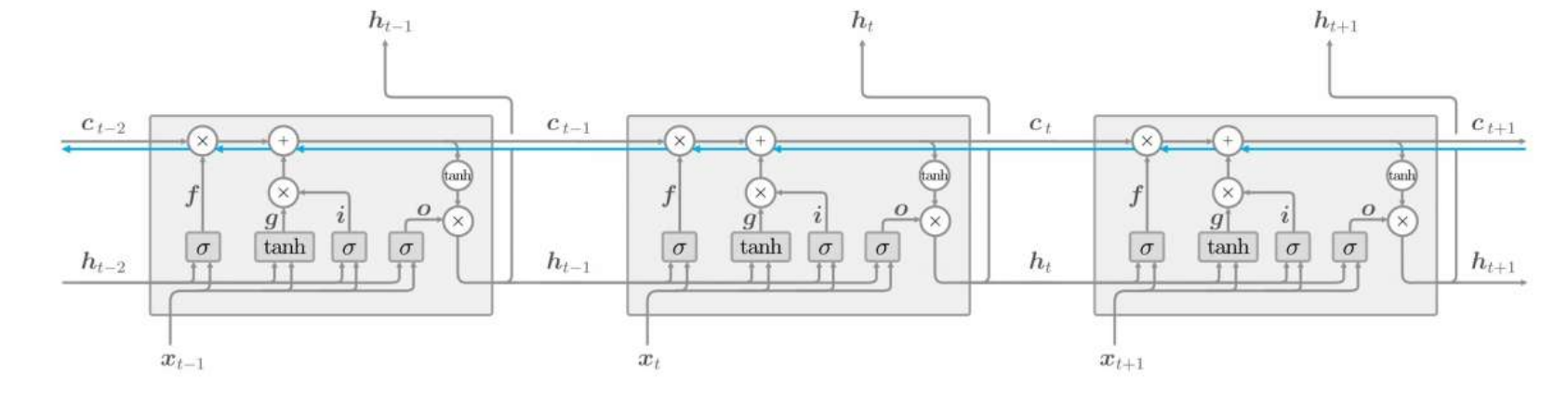
反向传播
蓝线代表反向传播路径,记忆单元的反向传播仅流过“+”和“×”节点。“+”节点将上游传来的梯度原样流出,所以梯度没有变化(退化)。
优化
LSTM的优化可以从三个方面
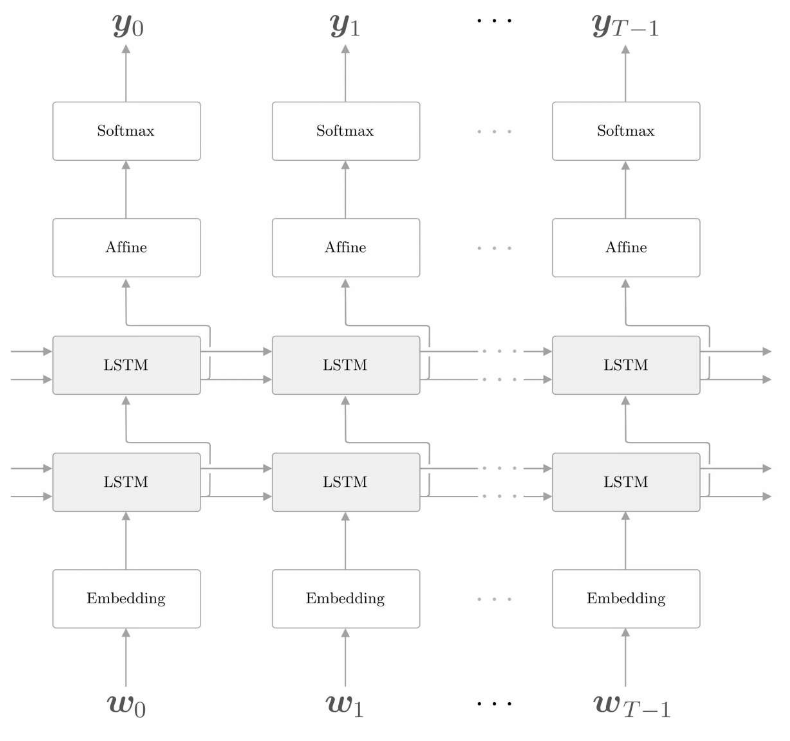
- LSTM层的多层化
- 在使用RNN创建高精度模型时,加深LSTM层(叠加多个LSTM层)的方法往往很有效。之前我们只用了一个LSTM层,通过叠加多个层,可以提高语言模型的精度。
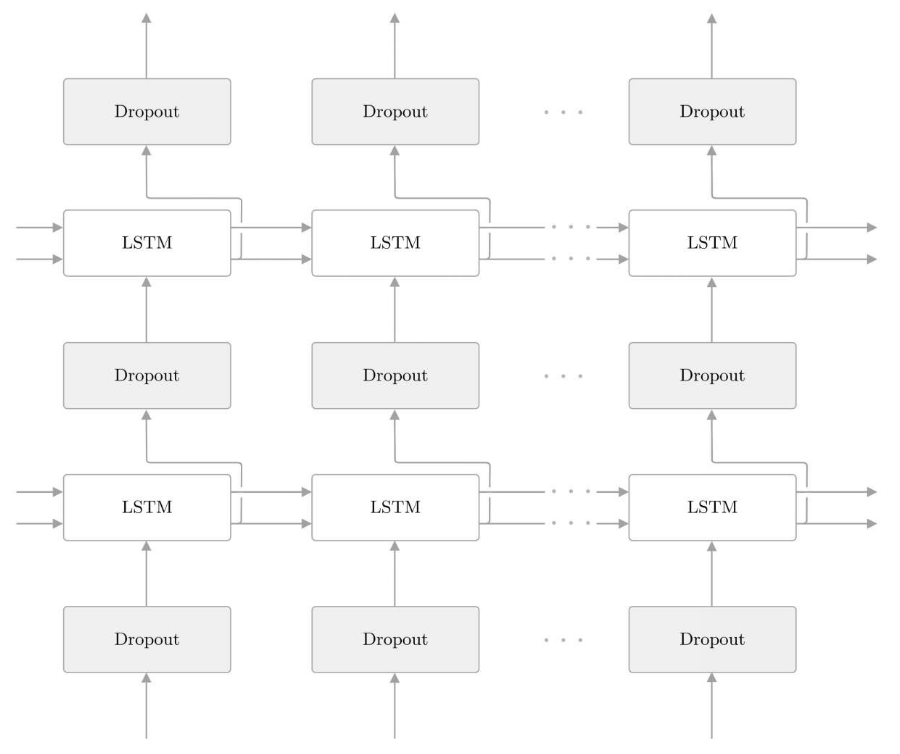
- 基于Dropout抑制过拟合
- 通过叠加LSTM层,可以期待能够学习到时序数据的复杂依赖关系。换句话说,通过加深层,可以创建表现力更强的模型,但是这样的模型往往会发生过拟合(overfitting)。
- Dropout随机选择一部分神经元,然后忽略它们,停止向前传递信号。这种“随机忽视”是一种制约,可以提高神经网络的泛化能力。
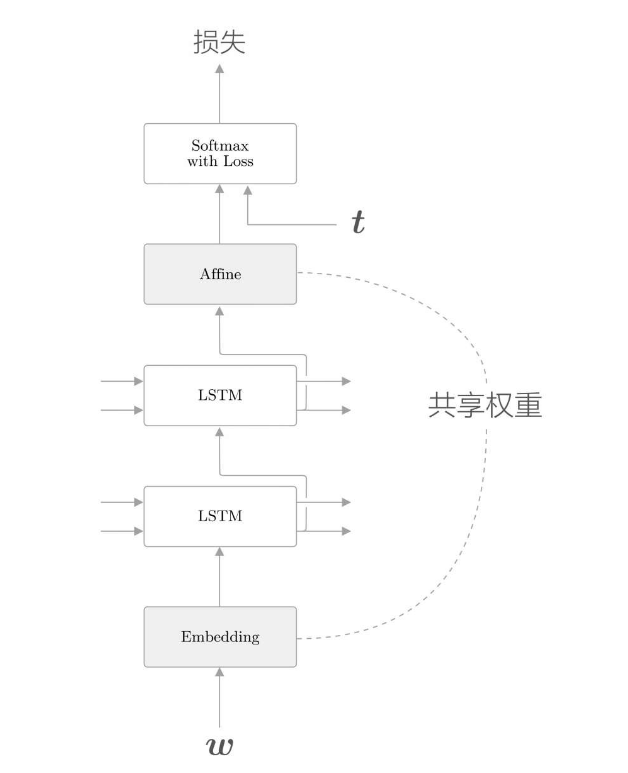
- 权重共享
- 共享权重可以减少需要学习的参数数量,从而促进学习。另外,参数数量减少,还能收获抑制过拟合的好处。
- 绑定(共享)Embedding层和Affine层的权重的技巧在于权重共享。通过在这两个层之间共享权重,可以大大减少学习的参数数量。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】