介绍
论文地址:https://arxiv.org/pdf/2011.12032.pdf
近年来,人脸识别技术越来越普及。在智能手机解锁和进出机场时,理所当然地会用到它。人脸识别也有望被用于管理今年奥运会的相关人员。但与此同时,人们对人脸欺骗的关注度也越来越高,而人脸反欺骗(FAS)这一防止人脸欺骗的技术领域也备受关注。
恶搞技术每年都在发展。随着新类型的欺骗变得越来越现实,需要有一种稳健的算法,能够在没有经过现有模型训练的场景下检测欺骗。传统的基于二进制分类的模型(如"0"代表真实,"1"代表欺骗)比较容易建立,性能也比较高,但有一个弱点,就是难以学习到内在的、有辨识度的欺骗模式。
因此,最近在FAS任务中提出了Pixel-Wise Supervision,其目的是学习更细粒度的像素/斑点级特征,对识别更有用。
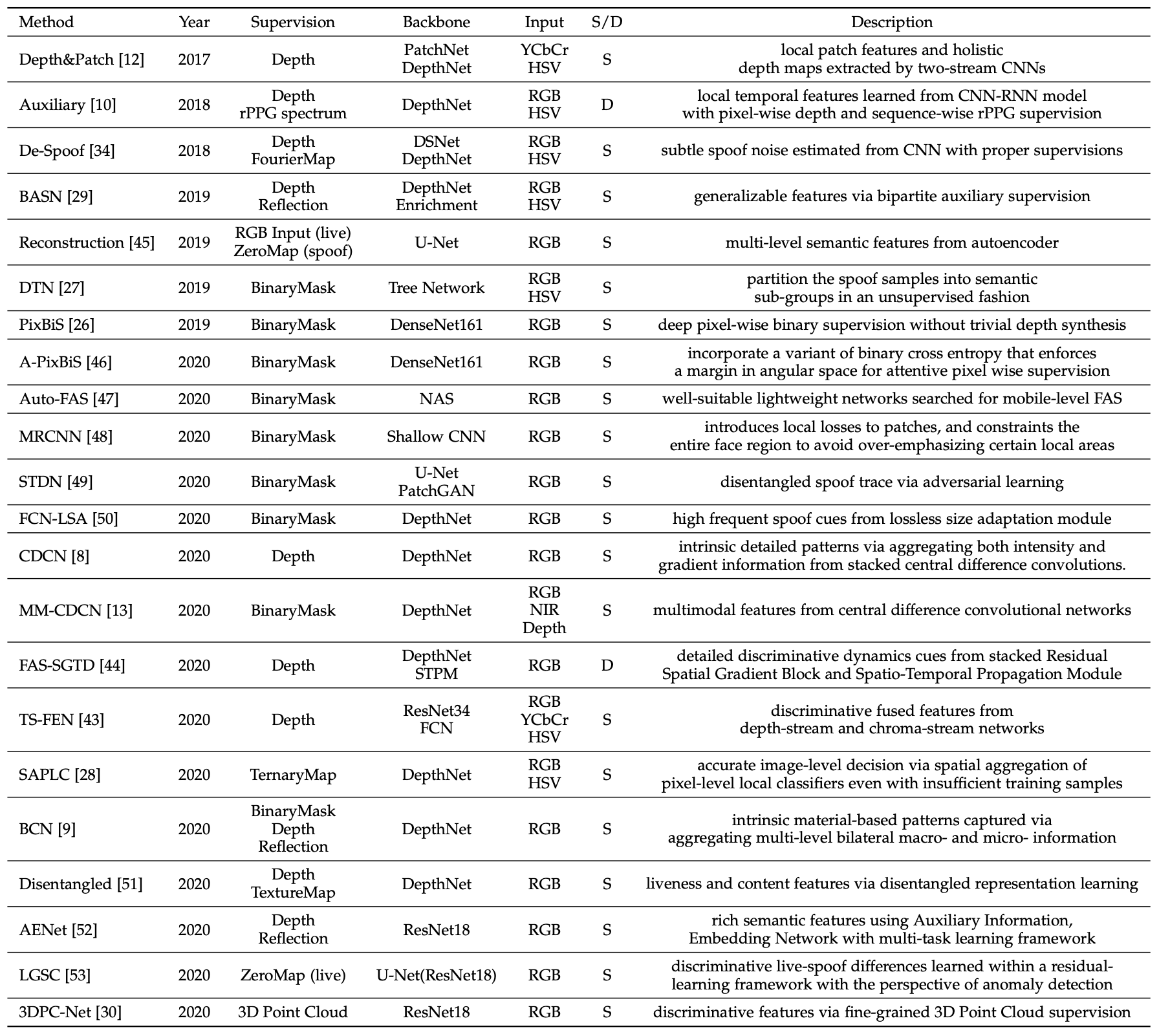
在本文中,在综合回顾了以往的方法后,如上表所示,他们提出了一个新的框架,称为Pyramid Supervision,它可以从多尺度的空间环境中学习局部细节和全局语义信息。在本文中,他们将介绍该框架及其性能。
在5个FAS基准数据集上进行了大量的实验,发现Pyramid Supervision不仅提高了现有的Pixel-Wise Supervision的性能,而且还能在补丁层面识别欺骗的痕迹,提高了模型的可解释性。可解释性;
新框架"金字塔监督
金字塔 在现有的方法中很容易引入监督,以提高其绩效。在本文中,我们展示了一个在两种典型方法中引入金字塔监督的例子。二进制掩模监督和深度图监督。
首先,金字塔二元掩码监督的图,将金字塔监督应用于二元掩码监督,如下图所示。
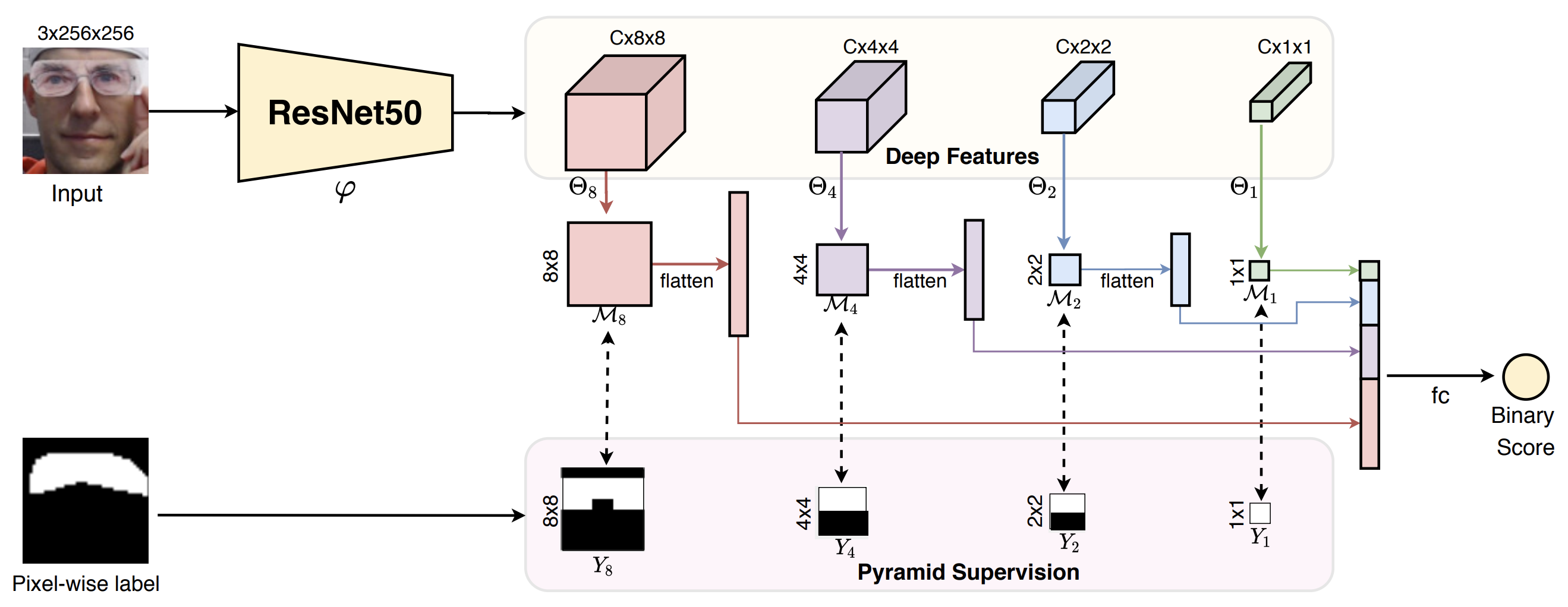
从RGB输入图像(3×256×256)中提取多尺度特征(_F__8,_F__4,F__2,F1),提取各特征后采用平均池化法。此外,每个特征(_F__8,_F__4,F__2,F1),用1x1 Conv进行特征到掩模的映射,得到多尺度二元掩模(Θ8、Θ4、Θ2、Θ1)。多尺度二元掩模预测可以表述为: 1.可制定如下:
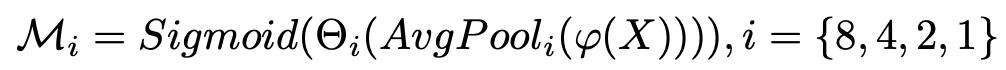
每一个生成的多尺度二元掩码都要进行变换和并联,最后应用二元分类。对于每个像素的地面真值_(Y_),可以直接使用已经注释的二进制掩码标签,也可以使用生成的粗二进制掩码。转换为与输入图像相同的多尺度掩模标签(Y8、Y4、Y2、Y1)。
预测的多尺度二进制掩码和地面真相大小相同,通过累积每个尺度每个位置的二进制交叉熵(BCE)来计算损失函数(Lpyramid)。
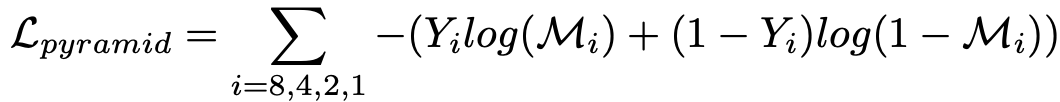
在训练过程中,网络的整体损失函数(Loverall)可以表述如下_Lbinary_将是最后一次二进制分类的BCE。在测试过程中,只使用最终的二进制分数。
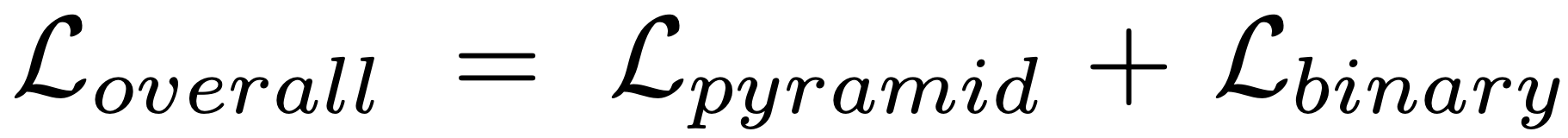
接下来,金字塔深度图监督应用于深度图监督,如下图所示。
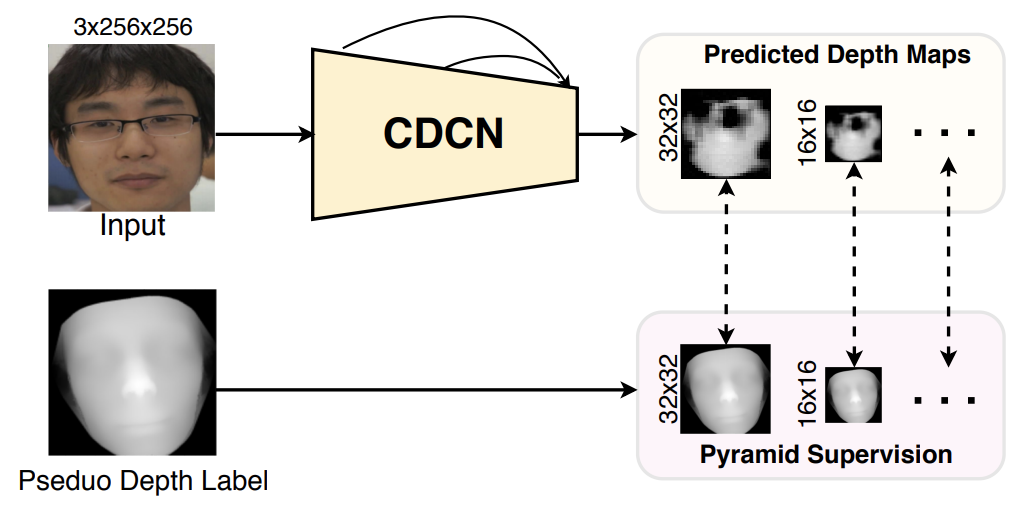
如图所示,CDCN从输入图像(3×256×256)中提取多级特征,并预测灰度深度图(32×32)。与金字塔二元掩模监督类似,预测的深度图D32(32×32)和生成的Pseduo深度都被下采样并调整为相同的比例(32×32、16×16等)。
金字塔深度损失(LdepthPyramid)可制定如下。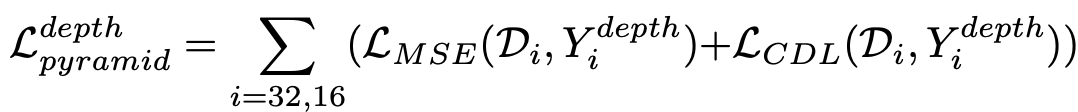
这里,Di代表预测深度图的比例尺_i_。另外,LMSE和LCDL分别代表均方误差(MSE)和对比度深度损失(CDL)。对比深度损失(CDL)是CVPR2020中提出的损失函数,其公式如下。
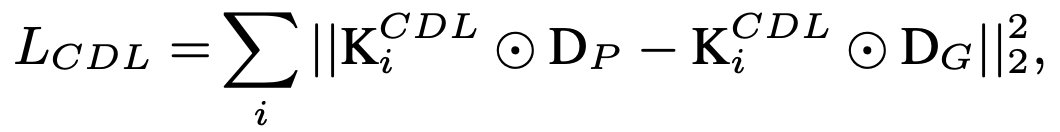
这是一种新引入的损失,因为常用的使用欧氏距离的Contrasive Loss没有考虑相邻像素信息,细节信息丢失,影响泛化性能。
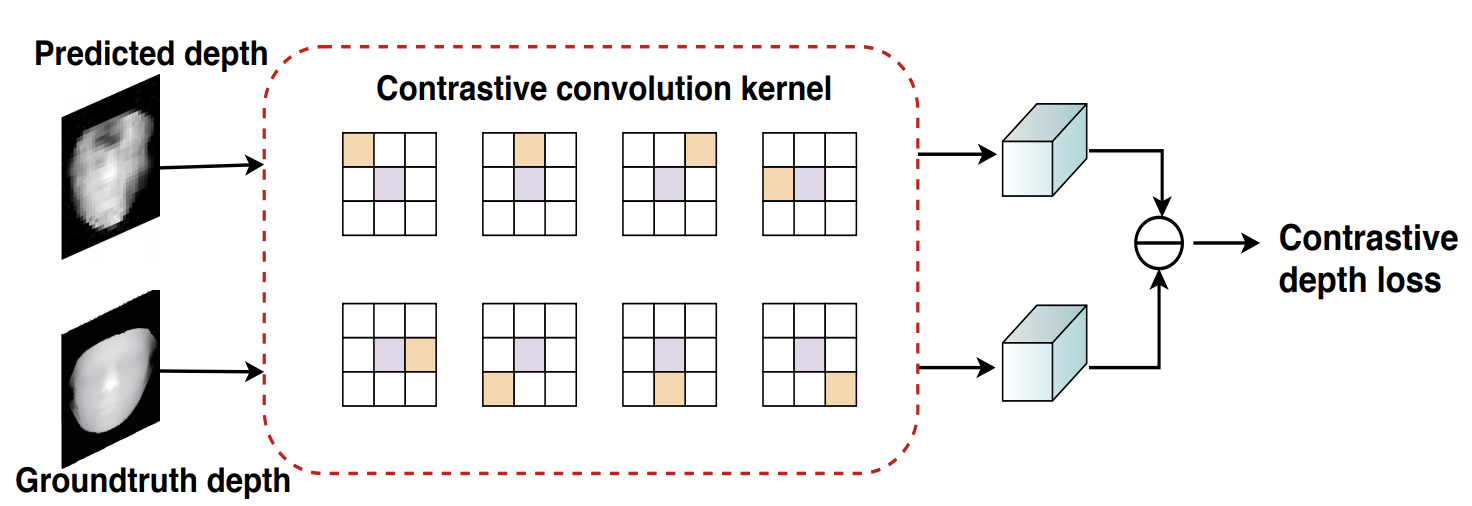
(出典:深度空间梯度和时间深度学习的人脸防欺骗技术)
在训练过程中,只使用LdepthPyramid,在测试过程中,计算所有尺度预测的深度图的平均值作为最终得分。
实验
如上所述,在基于Pixel-Wise Supervision的FAS中,主流的Backbone可以分为两类。
1)基于二进制掩码监督的网络(如ResNet和DenseNet)。
2)基于伪深度监督的网络(如DepthNet)。
在此,分别以具有代表性的ResNet50和CDCN作为基线,并与金字塔监督的模型进行比较。
数据集内类型测试 (OULU-NPU)
数据库内测试是对特定数据集的性能评估。使用一个代表性的数据集OULU-NPU来评估性能。为了公平的比较,使用原始协议和指标,指标是攻击展示分类错误率(APCER)、展示分类错误率(BPCER)和ACER的平均值计算出来的。使用ACER,其计算方法是APCER是指被误判为真实的欺骗行为的百分比,PCER是指被误判为欺骗行为的百分比。PCER是指被欺骗和误判的真品比例。下表显示了使用OULU-NPU进行Intra-Dataset测试的结果,其中Prot.代表OULU-NPU提供的四种协议。
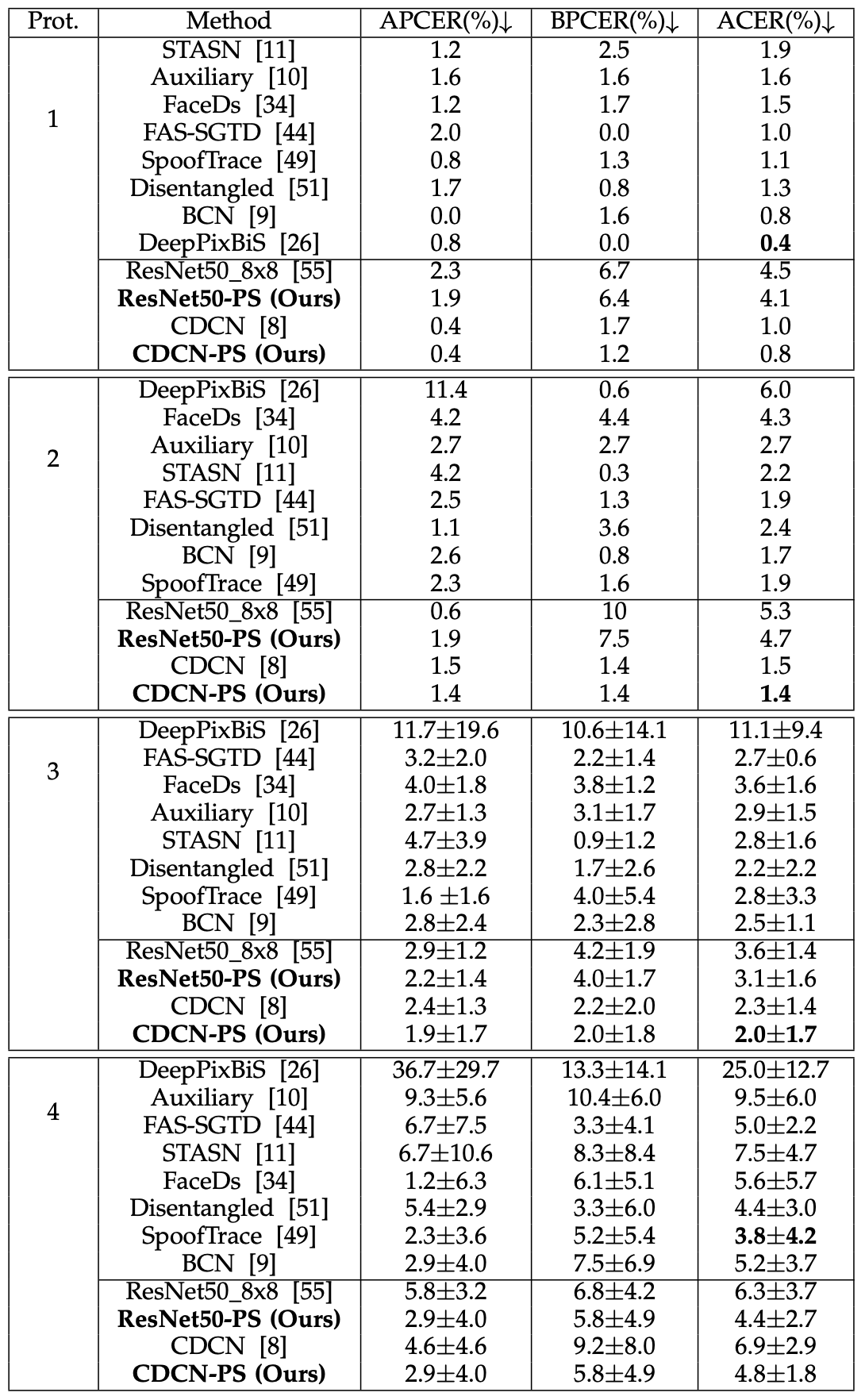
从ACER来看,重点是提出的金字塔监督(PS),可以看到它在四个协议中持续降低和提高性能。换句话说,它在光照、攻击介质和输入摄像机等外部环境方面的泛化性能有所提高。
从模型来看,CDCN-PS在四个协议中实现了比SOTA的模型更好或性能相当。ResNet50-PS显示出非常好的效果,在协议4中表现得比CDCN-PS更好,虽然前三个协议的性能没有那么高,但在协议4中最难达到高性能。这表明,即使在训练数据有限的情况下,金字塔监督也是非常有效的。
数据集内交叉类型测试(SiW-M)
通过SiW-M的跨类型测试验证未知攻击的泛化性能。如下表所示,与传统的Pixel-Wise Supervision相比,ResNet50-PS和CDCN-PS实现了整体更好的EER,分别提高了17%和12%。

跨数据集内类型测试
他们使用四个数据集,OULU-NPU(O),CASIA-MFSD(C),Idiap Replay-Attack(I)和MSU-MFSD(M)。其中,随机选取3个数据集进行训练,剩余1个数据集用于测试。下表显示了结果。
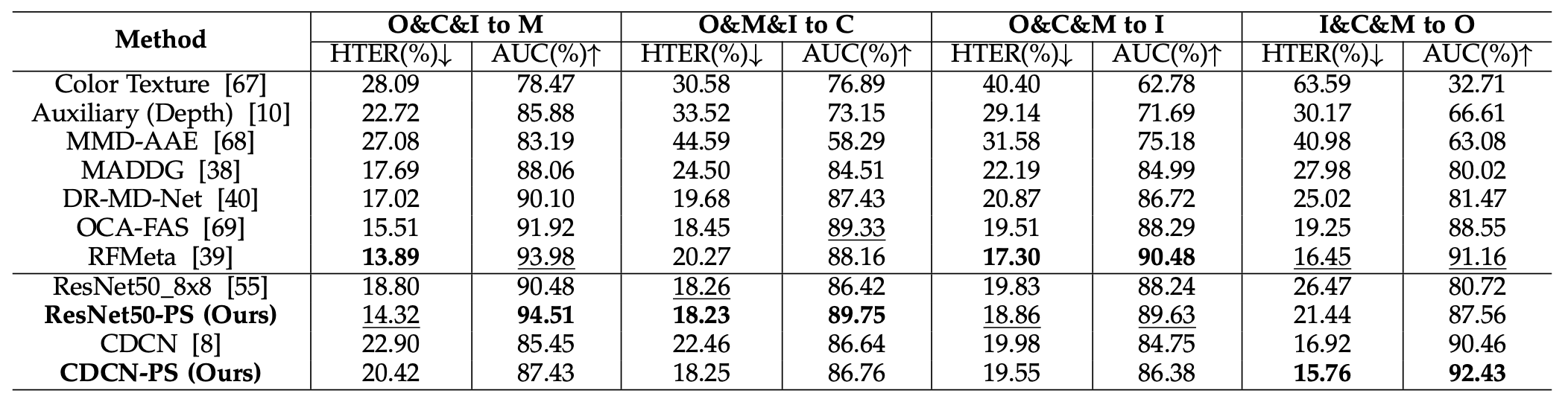
可以看出,金字塔监督的实施显著提高了ResNet50-PS的性能(HTER),尤其是"O&C & I to M"和"I&C & M to O"的性能(HTER)提高了-4.48%和-5.03%。
同样,CDCN-PS在"O & C & I to M"、“O & M & I to C”、"I & C & M to O"的表现(HTER)分别提高了-2.48%、-4.21%、-1.16%。我们表明,金字塔监督也有助于在多源域上提供丰富的多尺度指导。
可视化
下图是SiW-M在Cross-Type测试中预测的真假二元图。
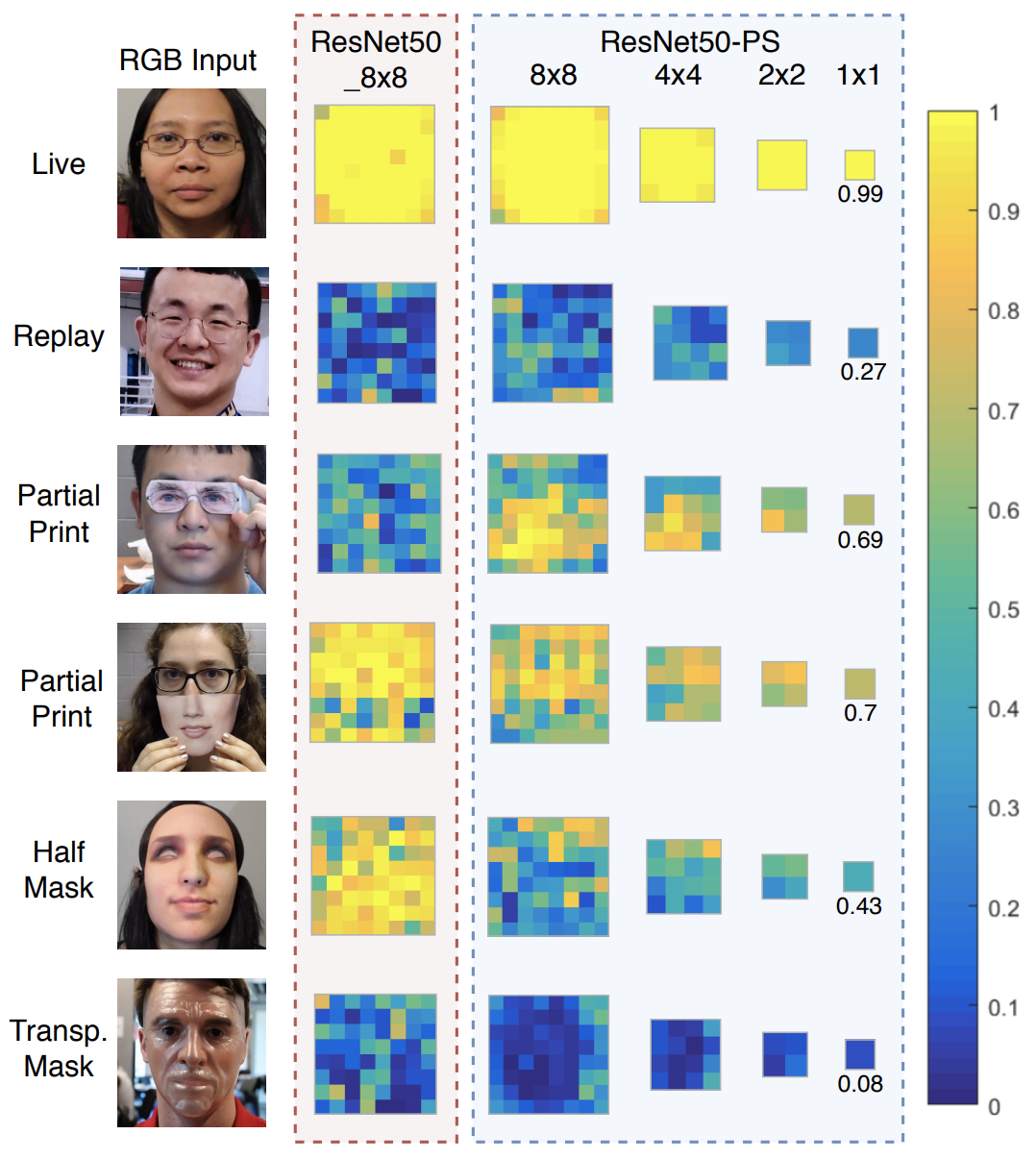
从"Live"、"Replay"和"Transp.Mask"的预测结果来看,ResNet50 8x8和ResNet50-PS的表现都不错,表现出较高的识别可信度。另一方面,对于未知攻击方法的预测,如部分打印和半掩模,显示出信心的下降。
从ResNet50 8x8的结果中,可以看到,在第3行第2列中,除了眼睛区域的Print区域外,其他面部区域的预测置信度都很低。另一方面,金字塔监督的使用显著提高了欺骗定位方面的可解释性。预测的8x8和4x4地图分别揭示了面部皮肤区域和冒充媒介的高(真)和低(假)分数位置。
随着欺骗攻击的发展,网络的可解释性将在欺骗的定位和理解上变得越来越重要。
总结
在本文中,他们提出了一种新的金字塔监督,为精细化学习提供了更丰富的多尺度空间背景。
它可以很容易地引入传统方法。实验结果也表明其在泛化和解释性能上都有很高的有效性。要实现安全可靠的人脸识别系统,高泛化性能和高可解释性是不可缺少的。
未来,我们期望通过将其纳入更先进的架构和基于像素的标签,进一步提高系统的性能。



















