Elasticsearch 是一个强大的搜索和分析引擎,它通过将数据分散到多个节点的分片中来进行分布式处理。
本文将探讨分片大小和策略的概念,以优化 Elasticsearch 的性能并防止过度分片或分片过大等问题。
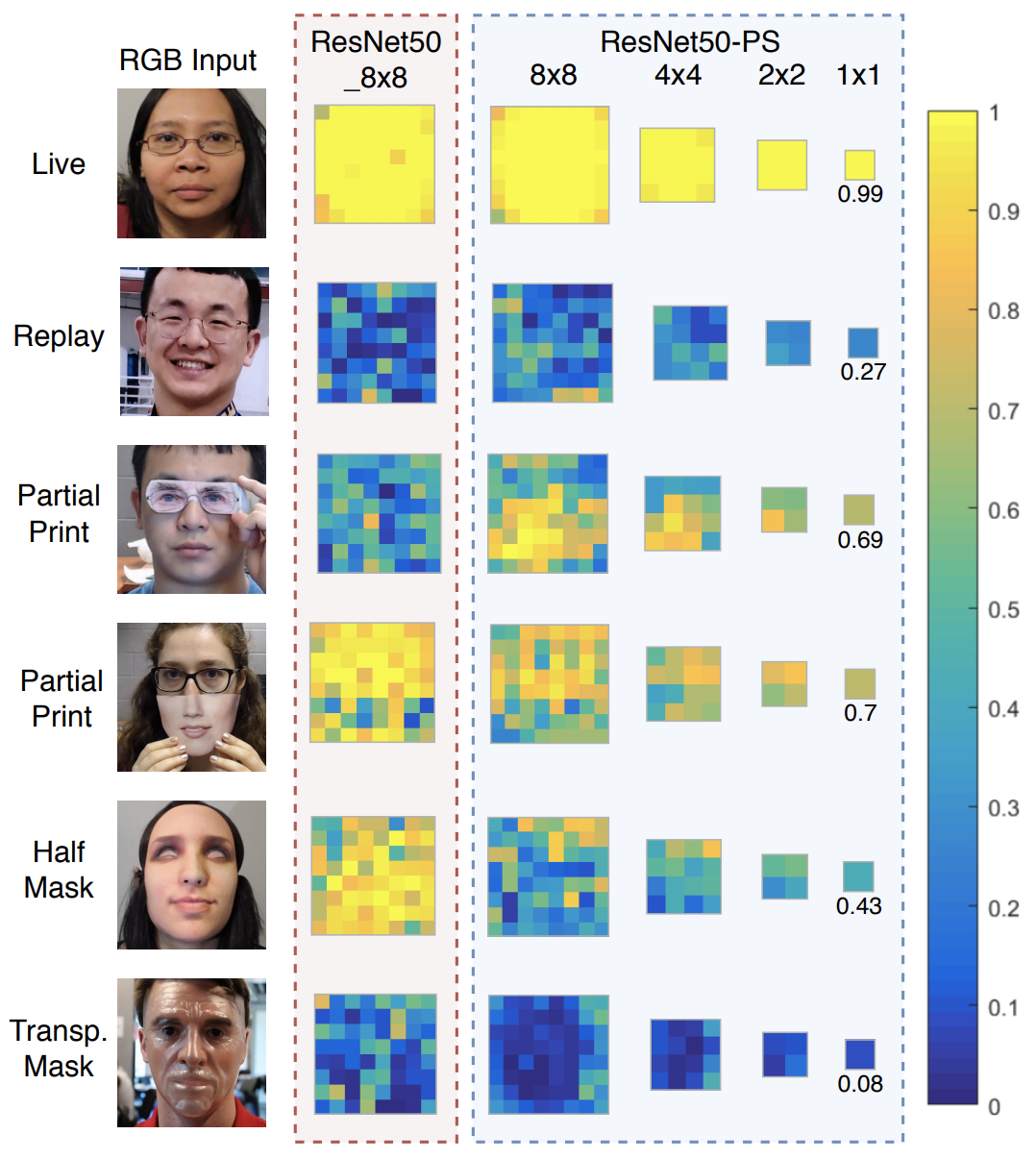
先看个分片设置不合理的真实企业案例:
10TB 左右集群数据,只有两个节点集群。单个最大索引 600GB,7.17.4 版本,200分片(全部)。
集群重启无法启动,未咨询之前是:最长时间8小时启动集群,过年期间,直接无法启动(已启动了20个小时+)。
——https://t.zsxq.com/SzcaQ
1、什么是分片?
在 Elasticsearch 中,每个索引都被划分为多个分片,每个分片可以在多个节点上复制,以确保数据的可用性和冗余。

上图是我本地单节点8.X 集群的 Head 插件截图,绿色代表已分配分片,灰色代表未分配副本分片(单节点所以无法分配副本分片)。
然而,尽管分片允许通过分散数据来扩展,不当的分片可能导致性能瓶颈或稳定性问题。
2、为什么分片策略很重要?
有效的分片关键在于找到正确的平衡。
过多的分片会导致“过度分片”,在这种情况下,管理众多分片的开销超过了其带来的好处,导致查询处理效率降低,可能还会引发集群不稳定。
3、创建分片策略
为了防止这些问题,至关重要的是要根据我们的特定需求开发一个分片策略,这包括:
了解集群的数据和查询:分析咱们所在集群的数据性质和将执行的查询。
基准测试:在类似生产环境中测试不同的分片配置,看看更改如何影响性能。
举例,如下基准测试仅供参考。
| 分片配置 | 查询响应时间 (ms) | CPU 使用率 (%) | 内存使用率 (%) | 搜索吞吐量 (查询/秒) | 稳定性评价 |
|---|---|---|---|---|---|
| 5 分片 | 120 | 70 | 65 | 200 | 高 |
| 10 分片 | 95 | 60 | 70 | 230 | 中 |
| 20 分片 | 85 | 75 | 80 | 250 | 低 |
| 50 分片 | 78 | 85 | 90 | 260 | 非常低 |
在实际应用中,应根据具体需求和资源条件,选择最适合的分片配置。
监控:使用 Kibana 等工具监控不同分片大小和配置对集群性能和稳定性的影响。
不幸的是,没有一种万能的分片策略。一种在某个环境中有效的策略可能不适用于其他环境。一个好的分片策略必须考虑到我们的硬件基础设施、业务场景和性能预期。
所以,大厂的意见、建议、经验贴不见得适用我们下厂。这很关键!
4、分片大小的关键考虑因素
4.1 搜索线程
每个分片在单独的线程中处理搜索查询。如果存在太多分片,可能会超负荷节点的搜索线程池,从而减慢查询处理速度。
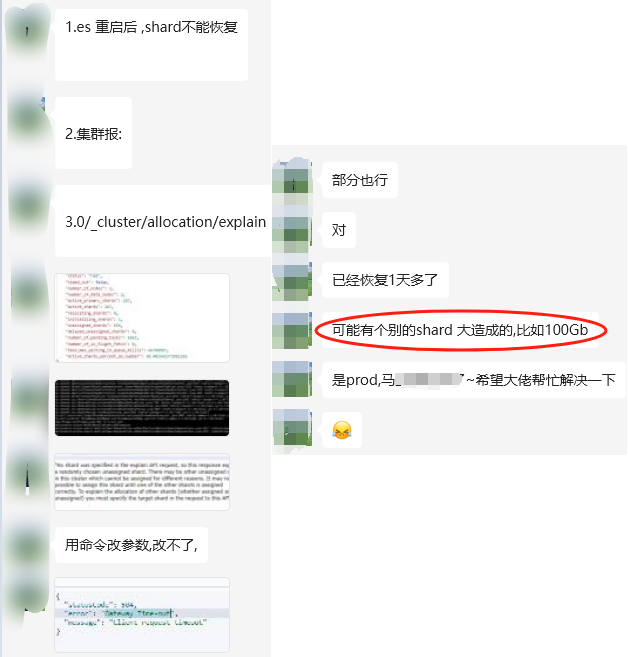
GET /_cat/thread_pool?v&h=id,name,active,rejected,completed
上述命令会显示集群中所有节点的所有线程池的信息,帮助我们识别哪些线程池可能过载。
4.2 分片开销
每个分片无论大小都会增加 CPU 和内存使用的开销。少量大分片通常比许多小分片使用资源更高效。
注意:在 Elasticsearch 中,可以使用一些命令行操作来查看分片的资源使用情况,尤其是关于 CPU 和内存的开销。
虽然没有直接的命令行工具可以显示每个分片的 CPU 使用情况(因为 CPU 使用通常被监控在节点级别而非分片级别),但咱们可以获取关于每个分片内存和存储使用的信息。
| API 名称 | 描述 | 示例请求 |
|---|---|---|
_cat/shards | 显示集群中所有分片的信息,包括健康状况、存储使用等。 | GET /_cat/shards?v |
_cat/allocation | 显示集群中每个节点的磁盘分配情况,包括已用和可用空间。 | GET /_cat/allocation?v |
_nodes/stats | 提供节点级的统计信息,包括内存使用情况、CPU使用情况等。 | GET /_nodes/stats/jvm?pretty |
_cat/segments | 提供索引的段信息,帮助了解分片的内部结构,包括段在内存中的大小等。 | GET /_cat/segments/my_index?v |
4.3 数据段
随着分片内数据的增长,数据会被划分为多个段。
Elasticsearch 在 JVM 堆内存中保留段元数据,以便可以快速检索用于搜索。随着分片的增长,其段被合并成更少的更大的段。这减少了段的数量,意味着在堆内存中保留的元数据更少。
这些段会定期合并,以优化查询性能和资源使用。
源码剖析:Elasticsearch 段合并调度及优化手段
从源码角度剖析 Elasticserach 段合并调优策略
5、分片大小的最佳实践
5.1 理想的分片大小
官方建议:分片大小在 10GB 到 50GB 之间通常是有效的,这有助于平衡资源使用和恢复时间。
Elasticsearch究竟要设置多少分片数?
5.2 节点上的分片数
参考依据之一:根据节点的内存容量保持分片数。例如,具有 30GB 堆内存的节点最多应承载 600 个分片。
参考依据之二:数据节点个数,设置索引分片数据建议数据节点的1(或者1.5)-3倍。
5.3 最佳实践和工具的使用
节点的堆内存:通过以下命令检查每个节点的当前堆内存大小。
GET _cat/nodes?v=true&h=heap.current
检查节点上的分片数:使用以下命令来查看每个节点上的分片数量。
GET _cat/shards?v=true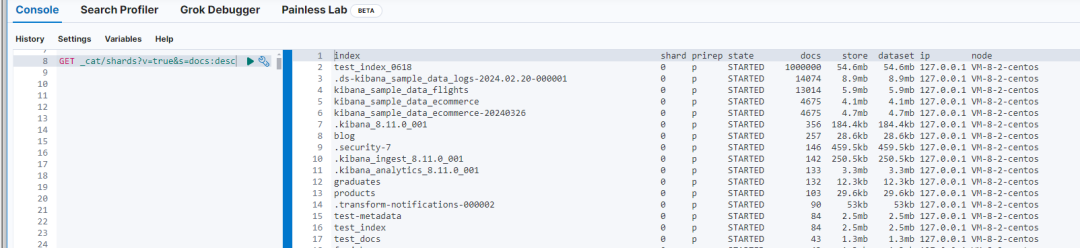
显式映射:与其让 Elasticsearch 自动创建映射,不如明确地定义它们,以避免不必要的资源使用。
更多参见《一本书讲透 Elasticsearch》P409-P411Elasticsearch 数据建模章节。
6、使用数据流和 ILM
对于时间序列数据,使用数据流(data stream)和索引生命周期管理 (ILM) 可以简化时间基础索引的管理。
ILM 帮助根据特定标准自动管理滚动和删除,确保有效的数据存储和分片管理。
7、实践中调整分片
滚动标准
设置基于分片大小或文档数量的滚动条件,防止任何单个分片变得过大。

PUT my-index-000001/_settings
{
"index" : {
"routing.allocation.total_shards_per_node" : 5
}
}避免热点:均匀地在节点之间分配分片,以防止任何单个节点成为性能瓶颈。显式映射:与其让 Elasticsearch 自动创建映射,不如明确地定义它们,以避免不必要的资源使用。
8、减少分片数量
如果我们的集群已经存在过度分片问题,可以考虑:
(1)合并索引:将小型、相似的索引合并成更大的索引。
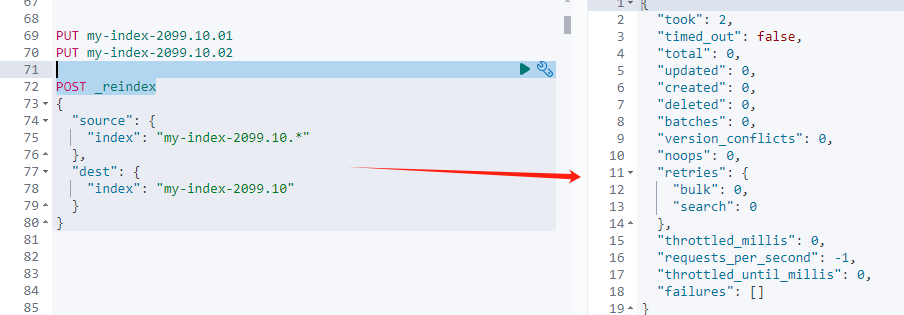
POST _reindex
{
"source": {
"index": "my-index-2099.10.*"
},
"dest": {
"index": "my-index-2099.10"
}
}删除不使用的索引:删除不再需要的索引以释放资源。
DELETE my-index-000001没到这个地方,咱们都多强调一句——删除索引,而不是文档!
删除的文档不会立即从 Elasticsearch 的文件系统中移除。相反,Elasticsearch 会在每个相关分片上标记该文档为已删除。标记的文档将继续使用资源,直到在定期的段合并期间被移除。
(2)压缩索引:减少不再写入数据的旧索引中的分片数量。
9、处理分片相关错误
注意节点最大分片数设置。如果某个操作超过了这个限制,可能需要临时调整该设置或考虑更永久的解决方案,
如增加节点或合并分片。
必知必会两个核心参数:
- cluster.max_shards_per_node
- index.routing.allocation.total_shards_per_node9.1 cluster.max_shards_per_node
这是一个集群级别的设置,用来限制每个节点可以持有的最大分片数。默认值:1000。
其目的是防止单个节点由于持有过多分片而过载,这可能会导致性能下降和稳定性问题。
https://www.elastic.co/guide/en/elasticsearch/reference/8.14/misc-cluster-settings.html
使用场景
防止节点过载——在大规模部署中,防止任何单个节点因分片数量过多而成为性能瓶颈。
集群扩展——在节点添加到集群或从集群中移除时,该设置帮助平衡分片分布,保持集群的健康和性能。
注意事项
(1)如果 cluster.max_shards_per_node 设置得太低,可能会妨碍Elasticsearch正常的分片分配,特别是在集群扩展或收缩时。
(2)可以动态更新这个设置,以适应集群的变化,如节点增加或减少。
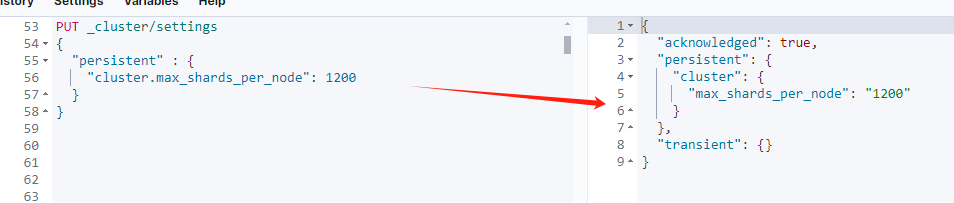
PUT _cluster/settings
{
"persistent" : {
"cluster.max_shards_per_node": 1200
}
}9.2. index.routing.allocation.total_shards_per_node
这是一个索引级别的设置,用于限制特定索引的分片可以分配到每个节点的最大数目。这个设置允许对单个索引的分片分布进行更细致的控制。
使用场景
分片均衡——确保一个高流量的索引不会在少数节点上聚集过多分片,从而避免这些节点成为热点。特定索引的性能优化:针对访问模式和查询负载对特定索引进行优化。

注意事项
-
在索引的生命周期中,我们可能需要根据使用模式和节点的变化调整这个设置。
使用这个设置可以增加配置的复杂性,需要详细监控和调整以确保最佳性能。
虽然这两个设置都涉及分片分配,但 cluster.max_shards_per_node 提供了一个全局的安全网,防止任何节点因分片过多而过载。
而 index.routing.allocation.total_shards_per_node 允许对单个索引进行更细粒度的控制。在实践中,这两个设置可以同时使用,以确保节点不会因全局或局部的分片分布不均而影响整体的Elasticsearch集群性能。
总的来说,适当配置这两个参数能够有效地管理和优化 Elasticsearch 集群的分片分布,从而提高查询性能和系统稳定性。在实际操作中,应根据集群的具体业务场景需求和表现来调整这些设置,以达到最佳的运行效果。
10、结论
在 Elasticsearch 中,有效地管理分片对于维护最佳性能至关重要。通过仔细规划我们的分片策略并定期监控分片性能和资源使用情况,可以确保 Elasticsearch 集群保持稳定、可扩展和快速。
记住,最好的分片方法是能够适应我们的数据和查询需求的不断变化的方法。
开篇问题也得以解决,截图如下。

https://www.elastic.co/guide/en/elasticsearch/reference/8.14/size-your-shards.html
Elasticsearch 使用误区之一——将 Elasticsearch 视为关系数据库!
Elasticsearch 使用误区之二——频繁更新文档
新时代写作与互动:《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!