文章目录
- 基于梯度下降神经网络训练整体流程
- 梯度下降优化算法
- 一、简介
- 二、梯度下降方法
- 2.1 批量梯度下降法BGD
- 2.2 随机梯度下降法SGD
- 三、传统梯度下降法面临的挑战
- 四、优化器
- 4.1 Momentum
- 4.2 Adagrad
- 4.3 Adam
- 4.4 对比与选择
- 过拟合、拟合和欠拟合
- 一、防止过拟合方法
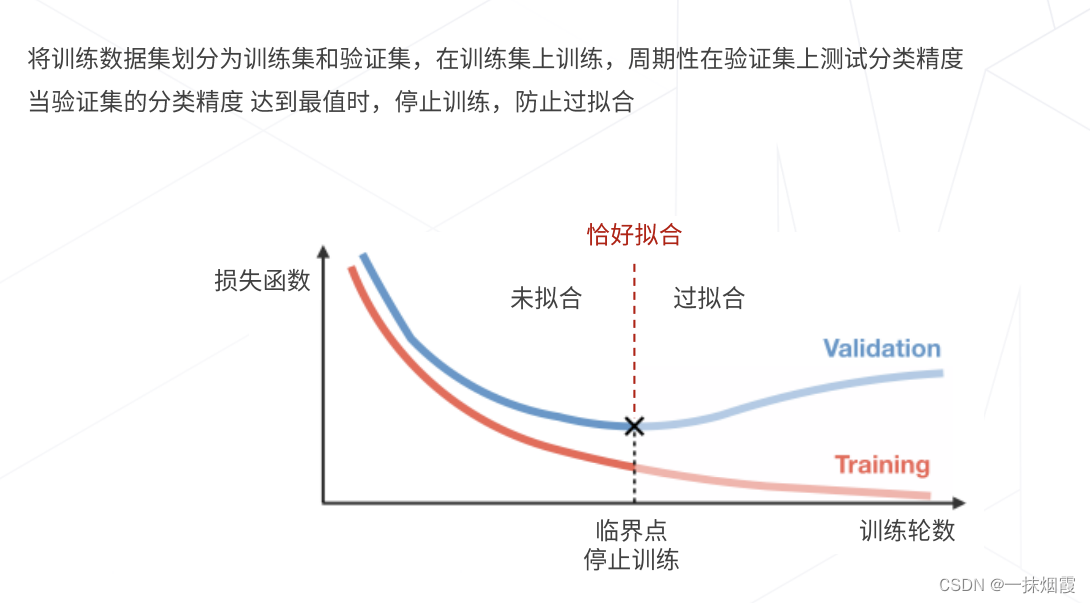
- 1.1 早停
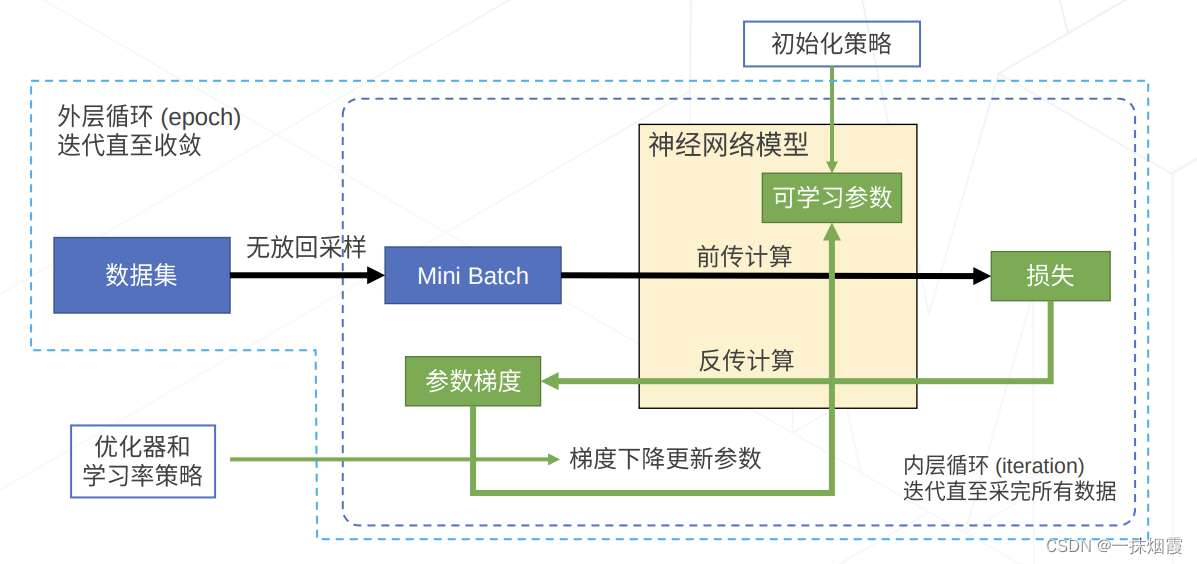
基于梯度下降神经网络训练整体流程
梯度下降优化算法
一、简介
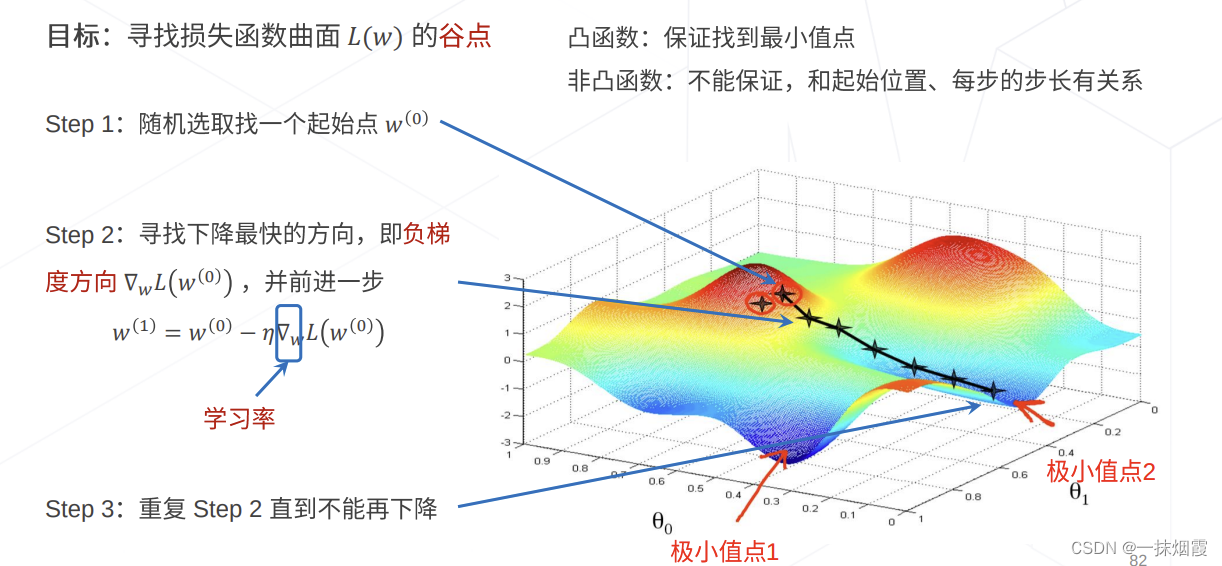
二、梯度下降方法
2.1 批量梯度下降法BGD
批量梯度下降法(Batch Gradient Descent,简称BGD)是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,其数学形式如下:

-
优缺点:
在凸优化(Convex Optimization)的情况下,一定会找到最优解
在非凸优化的情况下,一定能找到局部最优解
由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢,单次参数调整计算量大
不适合在线(Online)的情况
2.2 随机梯度下降法SGD
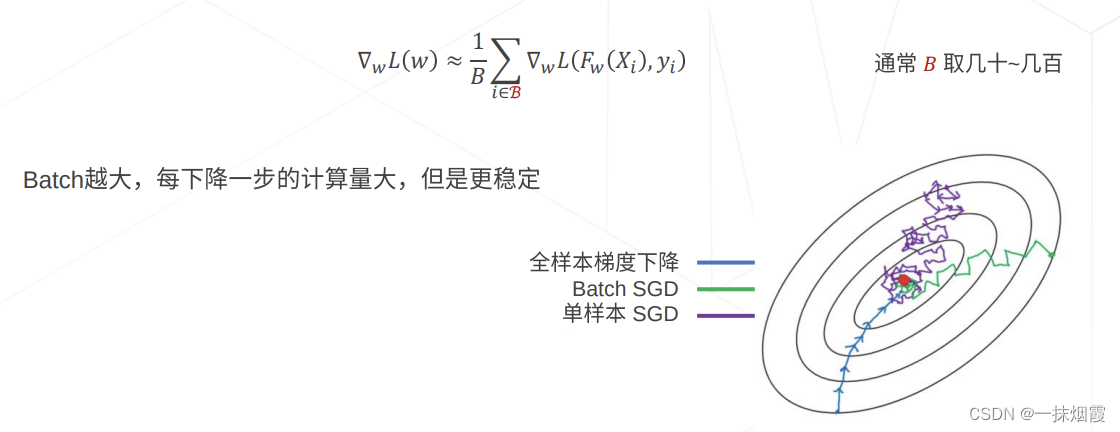
随机梯度下降法(Stochastic Gradient Descent,简称SGD)正是为了解决批量梯度下降法这一弊端而提出的。
-
优缺点:
训练速度快,适合Online的情况
通常比批处理梯度下降法快(在批处理的情况下,有可能许多的数据点产生的梯度是相似的,这些计算是冗余的,并不会有实际的帮助) .
通常目标函数震荡严重.在神经网络优化情况下(没有全局最优解),这种震荡反而有可能让它避免被套牢在一个局部最小值,而找到更好的局部最优解
通过调节学习率,能够找到和批处理相似的局部或者全局最优解
三、传统梯度下降法面临的挑战
传统迷你批处理不能保证能够收敛,当学习率太小,收敛会很慢,学习率太高容易震荡,甚至无法收敛。
可以按照某个公式随着训练逐渐减小学习率,但是不同的数据集需要不同的学习率变化曲线,不容易估计所有的参数使用同样的学习率并不合适容易被套牢在马鞍点
四、优化器
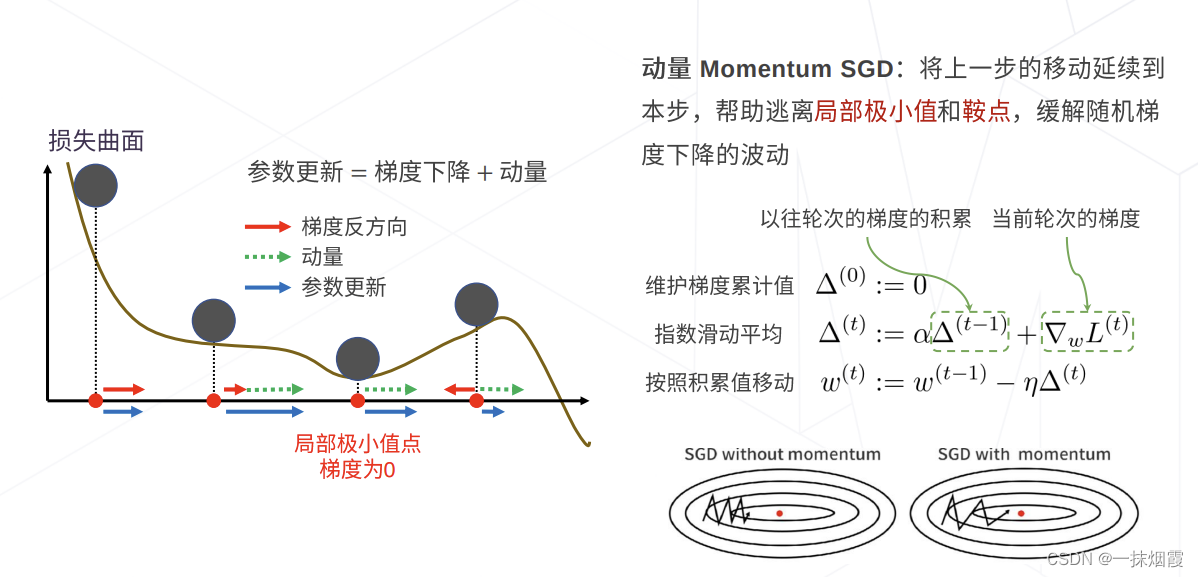
4.1 Momentum
原理:
不同dimension的变化率不一样
动量增强梯度在某一维度上的投影,使其指向同一方向上,在维度的指向上抵消不断变化的方向
4.2 Adagrad
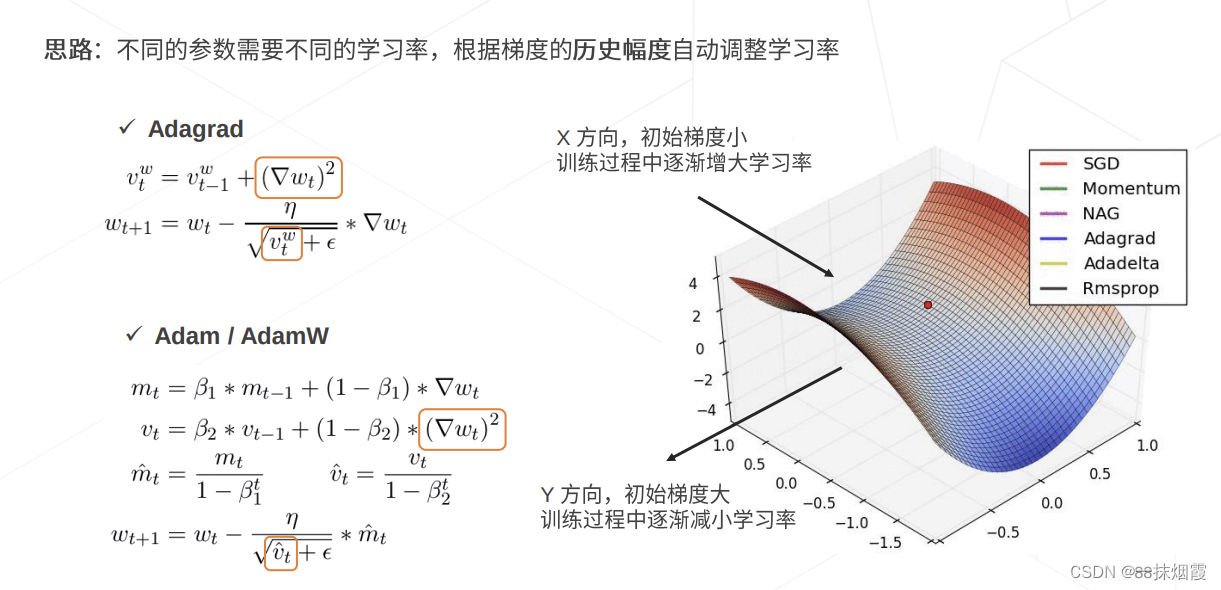
对频繁出现的参数,采用小的步长
对不频繁出现的参数,采用大的步长
对稀疏数据集非常有用(文本数据). Google在训练从Youtube视频自动识别猫用到了. Pennington et al训练词嵌入的GloVe也用到了
- 优势:
无需手动调整learning rate步长
设置初始步长为0.01即可
- 劣势:
随着训练,分母总是增大,步长会越来越小,算法无法收敛
- 实现:
只是累积过去的一段时间的梯度平方值
完全无需设置步长
为了便于实现,采用类使用动量的策略:
4.3 Adam
记录过去一段时间的梯度平方和(类似Adadelta和RMSprop),以及梯度的和(类似Momentum动量)把优化看作铁球滚下山坡, Adam定义了一个带动量和摩擦的铁球
在这里插入图片描述
4.4 对比与选择
1.如果数据集是稀疏的,选择自适应学习率的方法会更快收敛,而且免去了需要调试学习率的烦恼
2.RMSprop, Adadelta, Adam的效果非常相似,大多数情况下Adam略好
过拟合、拟合和欠拟合
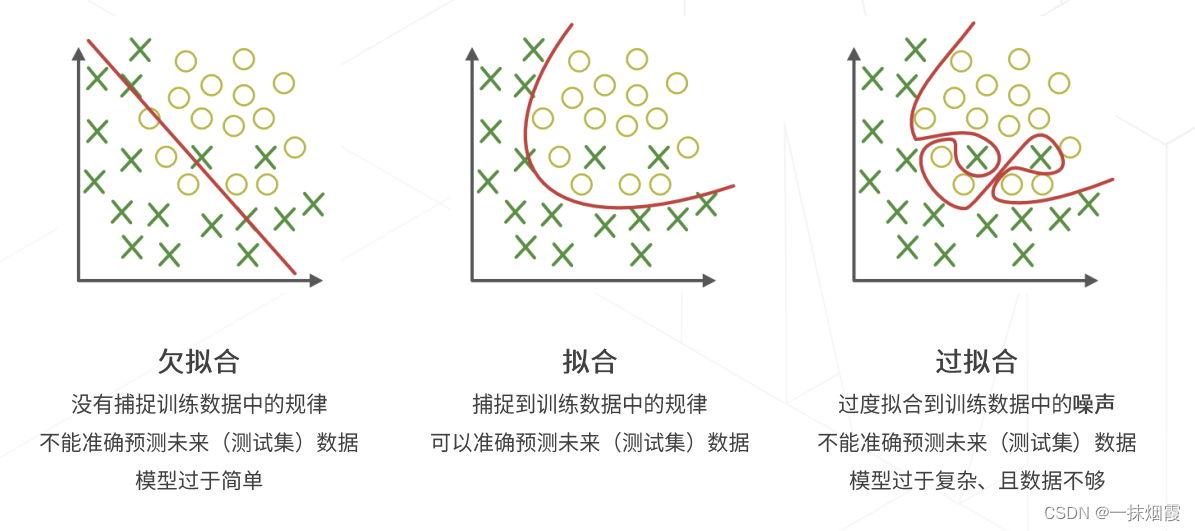
一、防止过拟合方法
1.1 早停