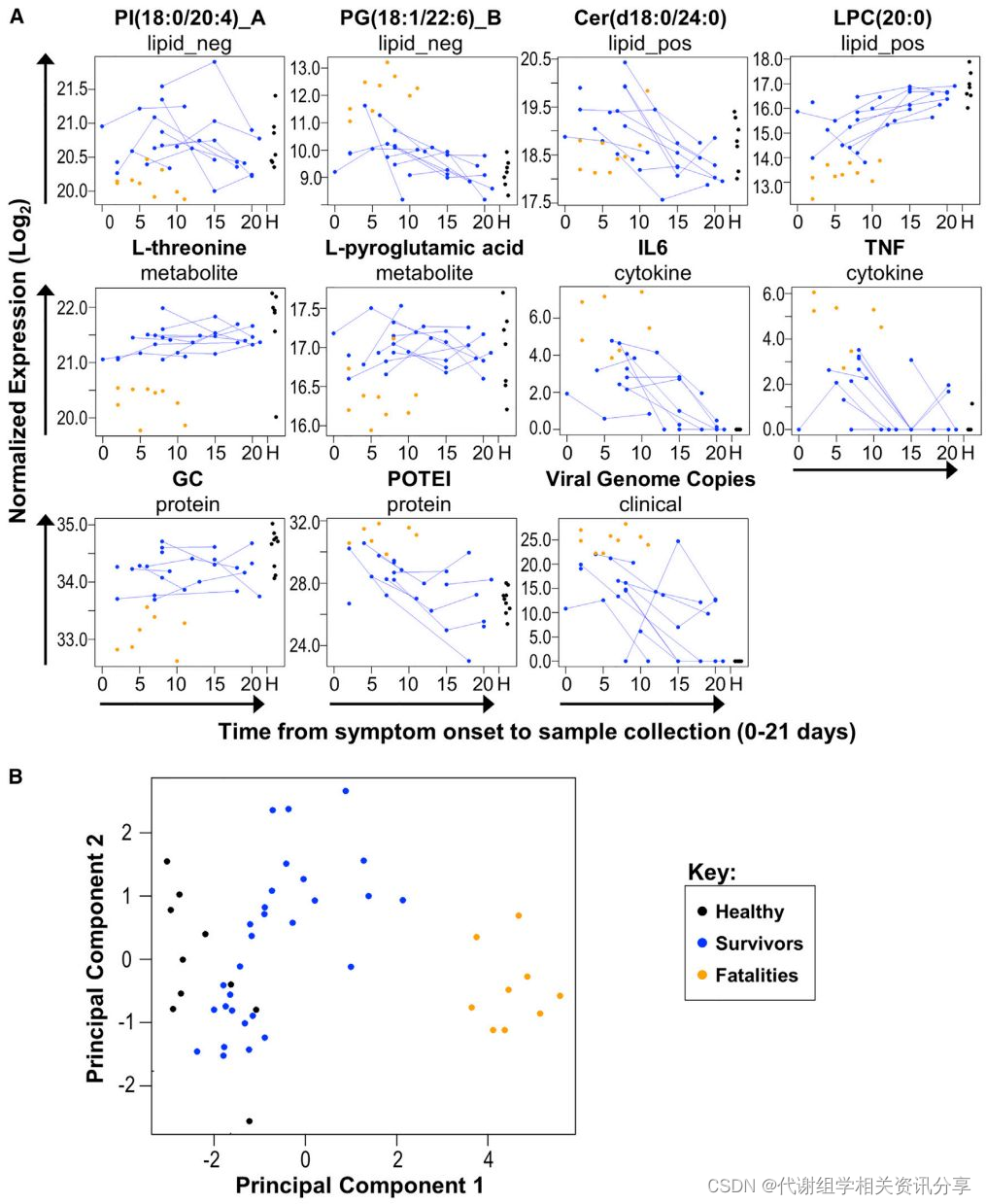
本文整理了 2023 年 1 月5 篇著名的 AI 论文,涵盖了计算机视觉、自然语言处理等方面的新研究。
InstructPix2Pix: Learning to Follow Image Editing Instructions
https://arxiv.org/abs/2211.09800v2
伯克利分校的研究人员开发了一种使用人工指令编辑图像的新方法。通过结合两个预训练模型(一个语言模型和一个文本到图像模型)的知识,他们能够生成一个大型图像编辑数据集。使用这些数据来训练他们的模型,称为 InstructPix2Pix。该模型能够快速执行编辑,这种新方法允许按照人工指令(GitHub 链接)进行更高效和准确的图像编辑。
https://github.com/timothybrooks/instruct-pix2pix

StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
https://arxiv.org/abs/2301.09515v1
研究人员在文本到图像生成领域取得了进一步的进展。他们已经能够提高生成图像的质量并使过程更快。这种新方法称为 StyleGAN-T,它能够通过使用单个前向传递来快速生成图像。与当前最先进的方法相比,这是一个很大的改进,因为后者需要迭代评估。这种新方法能够生成质量更好的图像,还能够处理不同的数据集并将文本与图像对齐。新方法还能够生成具有更多可控变化的图像
https://github.com/keyu-tian/SparK
Designing BERT for convolutional networks: sparse and hierarchical masked modelling
https://arxiv.org/abs/2301.03580
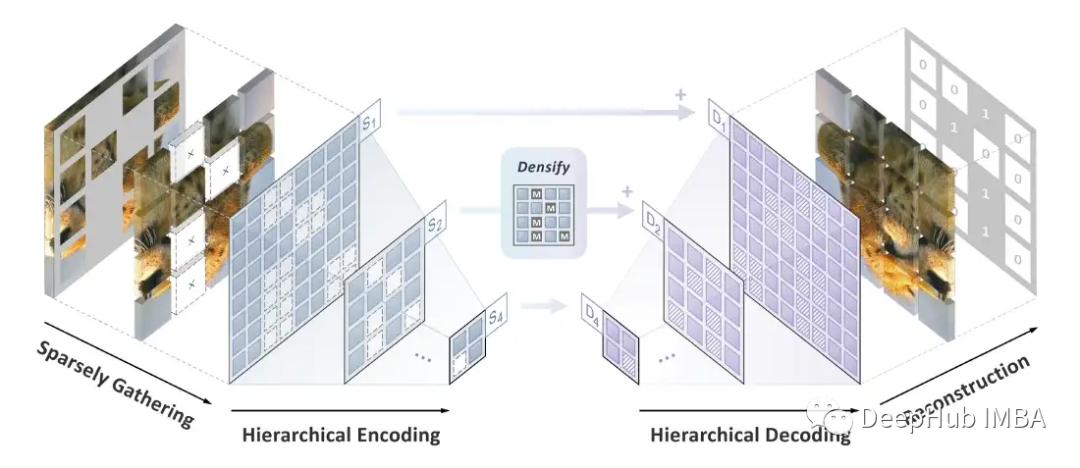
字节跳动开发了一种称为稀疏掩码建模(SparK)的新技术,可以帮助提高卷积神经网络(convnets)在图像处理任务中的性能。该技术能够克服两个主要挑战:卷积运算不适用于不规则、随机屏蔽的输入图像,以及 BERT 中使用的预训练方法不太适合卷积网络的层次结构。研究人员能够通过将未屏蔽像素视为稀疏 3D 点云、使用特殊类型的卷积来处理它们并开发分层解码器以根据处理后的特征重建图像来解决这些问题。该技术能够提高经典模型和现代模型在对象检测和实例分割等任务中的性能。
https://github.com/keyu-tian/SparK
Learning-Rate-Free Learning by D-Adaptation
https://arxiv.org/abs/2301.07733
Facebook 开发了一种可以让计算机更快、更高效地学习的新方法。他们为创造了一种新方法来调整学习速度,而无需知道解决方案的距离。这种新方法称为单循环方法,不需要进行回溯或线搜索。这是解决此类问题的第一种方法,它能够在许多不同类型的问题中匹配手动调整的学习率。这种方法实用且高效并且不需要任何额外工作
https://github.com/facebookresearch/dadaptation
One Model for All Domains: Collaborative Domain-Prefix Tuning for Cross-Domain NER
https://arxiv.org/abs/2301.10410v1
论文引入了一种称为跨域命名实体识别 (NER) 的新技术。它旨在解决实际场景中低资源的NER问题。该技术使用预训练语言模型 (PLM) 和文本到文本生成将知识从多个来源转移到目标领域,无需为每个领域创建新的 NER 模型。他们的方法具有灵活的迁移能力,并且在单源和多源跨域 NER 任务上表现更好。该技术的结果在 Cross-NER 基准测试上进行了测试,并显示出令人鼓舞的结果。
https://github.com/zjunlp/deepke
https://avoid.overfit.cn/post/31011b4e8657472982db66bb4875aba0
作者 The Geek