案例背景
英雄互娱是国内知名游戏研发商和发行商,经常遇到热门线上游戏,在某瞬间出现大量登录请求,需要临时扩容资源的场景。为了让服务更好的应对突增并发请求压力,客户尝试通过把应用服务容器化部署,能通过 HPA(Horizontal Pod Autoscaling)的功能,快速弹性自动扩容应用副本数来提高承载能力。
以下数据均从某已发行游戏的真实环境所得,其应用服务主要基于 Java 技术栈开发。
问题描述
该游戏应用部署在某公有云厂商的托管 K8S 环境中,经过一次更新后,将增加新服节点。以过往经验看,同时跑 6 个相同应用的 Pod,服务的承载能力可以稳定达到每秒 5 万次的 RPS(Request per Second)。但在上线前压力测试后发现,同时跑 6 个 Pod 的 RPS 的承载峰值仅为 2 万出头。增加到 12 个 Pod 时(相同资源配置),RPS 的承载峰值为 2.4 万左右,增长并不明显。进一步增加到 18 个 Pod(相同资源配置),RPS 不再提升,仍停留在 2.4 万左右。这就出现问题了,该服务的承载能力无法随着资源扩容线性增长,将会在高峰期极大影响游戏用户体验。显然瓶颈点会在服务本身,需要配合应用性能监测分析手段来进一步追踪,找出瓶颈点并执行优化。

绿线为 RPS,峰值为 2.4 万
黄线为响应时间(Response Time),峰值约为 1000ms
使用观测云定位问题的过程
观测云是系统全链路数据可观测平台,非常适合高效定位上述问题根因。观测云应用性能监测支持使用 OpenTracing 协议的采集器,实现对分布式架构的应用进行端到端的链路分析,并能与基础设施、日志、用户访问监测进行关联分析,快速感知故障表象和定位故障根因,提高用户体验。
- 通过链路观测快速定位问题方向
1. 在容器服务环境中部署观测云的数据采集器 - DataKit,接入应用链路和日志数据。
2. 服务在 21:00 到 22:00 点间进行压测,压测开始后,观测云应用性能监测的服务概览页面立即显示出系统实时运行状态,通过对 Pxx 的响应时间做排序,快速找到了响应时间较长的服务。如下图所示:

3. 点击该服务做进一步下钻,可以看到更详细的调用相关信息。如下图所示,发现「POST /xxx/v1/login/checklgn.lg」的响应时间较长,并且随着压力的增大,平均响应时间会逐渐增加。定位到该条服务链路需要做进一步的排查。


4. 点击该服务调用,进一步下钻去探查资源详情,我们注意到该服务执行会非常频繁的去调用 Redis(56 次),如下图所示。如果并发量增大,频繁调用该服务的时候,很可能会造成 Redis 上的巨大压力。

5. 从火焰图中,我们可以看到有些 Redis 调用之间存在可疑的延迟(注意红圈部分)。虽然,Redis 本身执行的时间非常快,但因为调用间的延迟拖慢了整体性能。
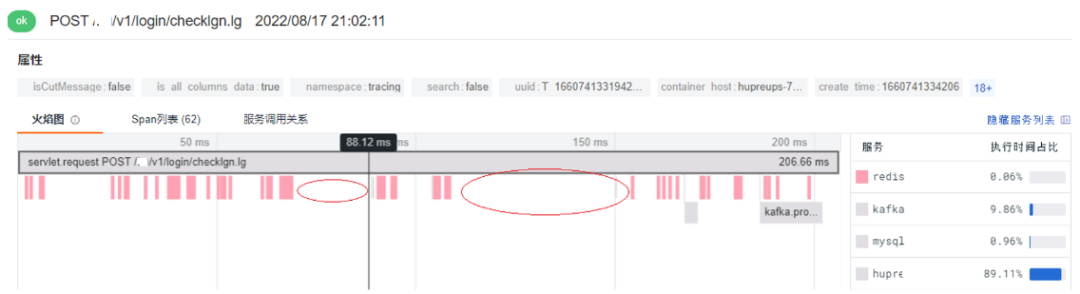
随着对系统的压力增大,该现象会更加明显。下图是压测高峰期产生的火焰图。从图中可以看到,两个 Redis 间的调用延迟超过 2s。

所以,初步判断瓶颈点在 Redis 上,原因很可能是 Redis 端的压力较大,无法即时响应前端调用所需的相关资源(例如:获取连接),出现了等待,从而导致在压测中整体的 RPS 上不去。此时,压测才刚开始不到 5 分钟,观测云快速定位性能瓶颈点的能力让现场工程师着实震惊。
6. 接下来就要进一步分析是 Redis 配置的问题,还是访问代码的问题了。首先开启 Redis 监测仪表板,从 Redis 的指标监控来看,在压测高峰期,出现 CPU 被打满的情况。尝试对 Redis 相关的参数做了优化调整,比如,增加连接池中连接数的数量,长链接代替短连接等的配置后,6 个 Pod 配置下压测结果 RPS 峰值可提升到 3 万左右,但再增加 Pod 数量后,RPS 峰值几乎没有变化。根因范围进一步缩小了,极有可能是访问代码的问题。但这时候现场工程师稍有犯难,此时已经是深更半夜了,这时候不可能再拉开发进来逐个模块检查代码,但明明就快揭开问题根因了,要拖到明天再继续又实在心有不甘。
这时候可以用观测云的 Profiling 能力了。
- 通过 Profiling 功能发现代码层问题
观测云 Profiling 功能支持查看应用程序运行过程中 CPU、内存和 I/O 的使用情况,通过火焰图实时展示每一个方法、类和线程的调用关系和执行效率,帮助优化代码性能。
现场再继续以下操作配置:
1. 在观测云中开启 Profiling 的采集功能。
2. Profiling 默认会 1 分钟左右上传一次统计数据。我们对压测开始时的数据和运行一段时间后的数据做比较,主要关注在「Lock Wait Time」和 「Socket I/O Read Time」的指标上。如下图所示:
1) 压测开始时的 Profiling 数据

2) 压测一段时间后的 Profiling 数据

压测中是逐步增加 RPS 的量,从上图的对比中,可以清楚的看到压测过程中「Lock Wait Time」 和 「Socket I/O Read Time」的值会变得非常大。这里就可能存在瓶颈点。需要进一步下钻去看更详细的信息。
3. 从 Redis 监控指标发现有大量的 Read 操作。所以,进一步看「Socket I/O Read Time」相关的详细信息。如下图所示:

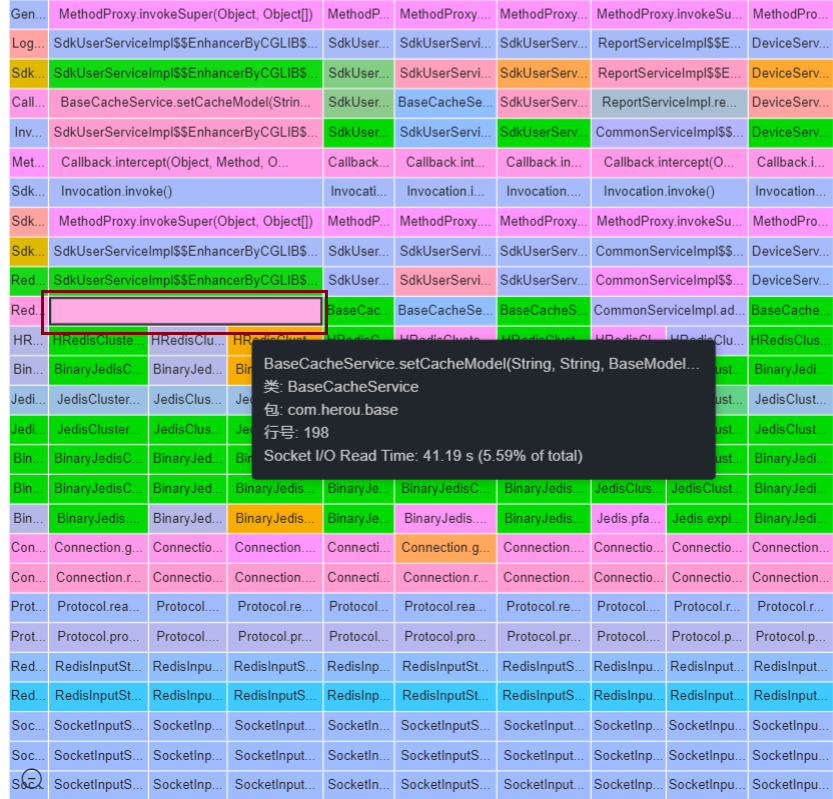
调用顺序按列从上往下,方块越长代表耗时占比越大。如上图红色标记的 3 个方块基本是最耗时的调用。在右侧,也可以通过不同的维度(类,方法,包等)进行数据查看。选择其中 ActionHandler 继续往下一级下取信息。

4. 在 ActionHandler 的详细信息中,能看到客户的代码中通过不同的实现方法在频繁调用 Redis 来完成相关的操作。如下图所示:

其中,以 setCacheModel 和 addCount 方法占用的时间最多。

5. 用同样的方法,发现其他的类方法中例如 Invocation.invoke() 等都存在类似频繁调用 Redis 的情况。这种情况会导致一个服务调用会产生大量的服务调用。当并发量大的时候,Redis 会成为热点,压力较大。
此时已是第二天凌晨,但终于找到了问题根因,的确因为代码内对 Redis 过于频繁的冗余调用所导致,甚至能清晰的定位到有问题的方法名,只待给开发提 ISSUE 即可。
最终成效
代码优化后,效果远超预期!
第二天,开发同学在观测云面板上,回溯到昨晚压测过程的时间段,看到了当时应用状态仪表板和 Profiling 仪表板数据,快速理解了问题上下文,当天就完成了相关代码部分的优化并提了测试发版。
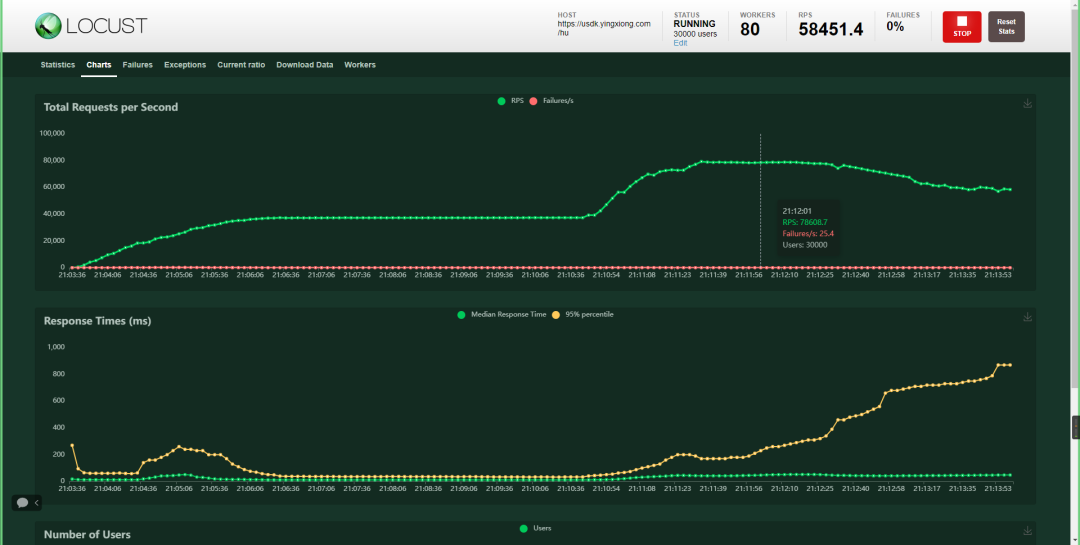
在当晚 21 点开始的新一轮的压测中,仍使用 6 个 Pod,RPS 跑到了超过 8 万峰值,相比第一次压测的 2 万 RPS 结果,性能足足提升到 4 倍,同时响应时间仍能控制在 800ms 以下,结果远超预期。
作者|观测云高级产品技术专家 —— 涂程