4. HBase事务
HBase 支持特定场景下的 ACID,即当对同一行进行 Put 操作时保证完全的 ACID。可以简单理解为针对一行的操作,是有事务性保障的。HBase也没有混合读写事务。也就是说,我们无法将读操作、写操作放入到一个事务中。
5. HBase数据结构
在讲解HBase的LSM合并树之前,我们需要来了解一些常用的数据结构知识。
5.1 跳表

上图是一个有序链表,我们要检索一个数据就挨个遍历。如果想要再提升查询效率,可以变种为以下结构:
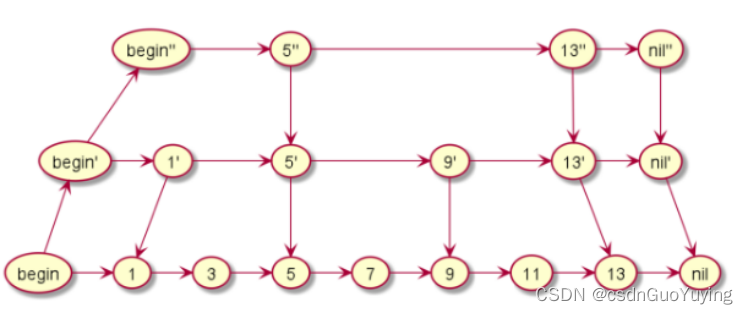
现在,我们要查询11,可以跳着来查询,从而加快查询速度。
5.2 常见树结构(扩展了解)
二叉搜索树(Binary Search Tree)
1、什么是二叉搜索树?
二叉搜索树也叫二叉查找树。它是一种比较特殊的二叉树。
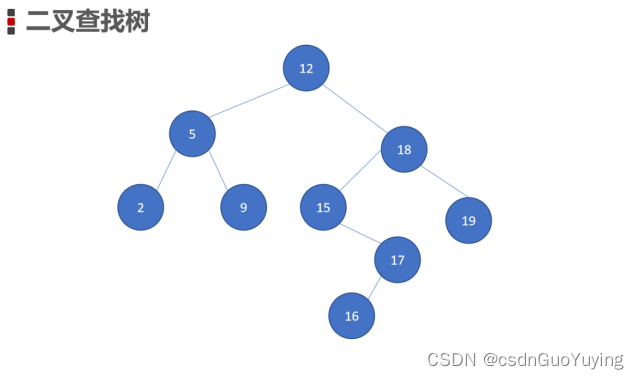
2、树的高度、深度、层数
深度:节点的深度是根节点到这个节点所经历的边的个数,深度是从上往下数的
高度:节点的高度是该节点到叶子节点的最长路径(边数),高度是从下往上数的
层数:根节点为第一层,往下依次递增
上图:
节点12的深度为0,高度为4,在第1层
节点15的深度为2,高度为2,在第3层
3、二叉搜索树的特点
树中的每个节点,它的左子树中所有关键字值小于该节点关键字值,右子树中所有关键字值大于该节点关键字值
4、二叉搜索树的查询方式
1.首先和根节点进行比较,如果等于根节点,则返回
2.如果小于根节点,则在根节点的左子树进行查找
3.如果大于根节点,则在根节点的右子树进行查找
5、二叉搜索树的缺点
因为二叉搜索树是一种二叉树,每个节点只能有两个子节点,但有较多节点时,整棵树的高度会比较大,树的高度越大,搜索的性能开销也就越大
平衡二叉树(Balance Binary Tree)
1、简介
平衡二叉树也称为AVL树,它是一颗空树,或者它的任意节点左右两个子树的高度差绝对值不超过1。
平衡二叉树很好地解决了二叉查找树退化成链表的问题
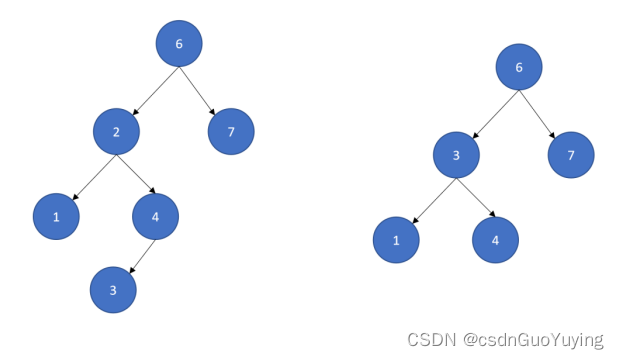
上图:
1.两棵树都是二叉查找树
2.左边的不是平衡二叉树
节点6的子节点:节点2的高度为:2,节点7的高度为:0,| 2 – 0 | = 2 > 1)
3.右边的是平衡二叉树
节点6的子节点:节点3的高度为:1,节点7的高度为:0,| 1 – 0 | = 1 = 1 )
2、平衡二叉树的特点
AVL树是高度平衡的(严格平衡),频繁的插入和删除,会引起频繁的rebalance,导致效率下降,它比较使用与插入/删除较少,查找较多的场景
红黑树
1、简介
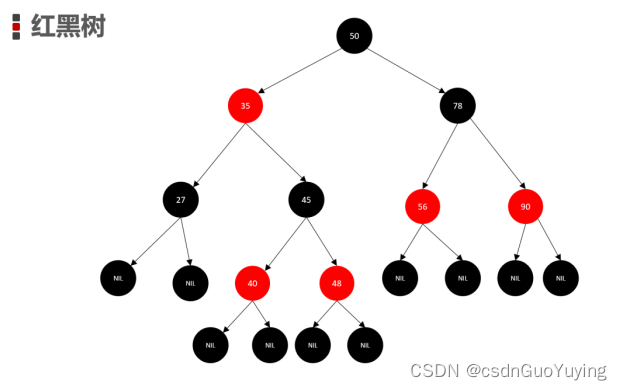
红黑树是一种含有红黑节点并能自平衡的二叉搜索树,它满足以下性质:
- 每个节点要么是黑色,要么是红色
- 根节点是黑色
- 每个叶子节点(NIL)是黑色
- 每个红色结点的两个子结点一定都是黑色
- 任意一结点到每个叶子结点的路径都包含数量相同的黑结点
2、红黑树的特点
和AVL树不一样,红黑树是一种弱平衡的二叉树,它的插入/删除效率更高,所以对于插入、删除较多的情况下,就用红黑树,而且查找效率也不低。例如:Java中的TreeMap就是基于红黑树实现的。
B树
1、什么是B树
B树是一种平衡多路搜索树;与二叉搜索树不同的是,B树的节点可以有多个子节点,不限于最多两个节点;它的子节点可以是几个或者是几千个
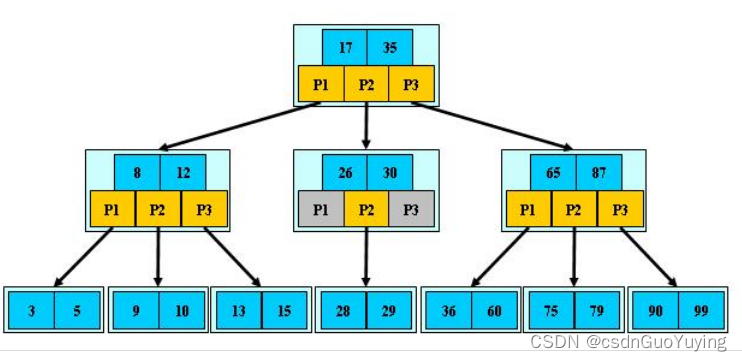
2、B树的特点
- 所有节点关键字是按递增次序排列,并遵循左小右大原则
- B-树有个最大的特点是有多个查找路径,而不像二叉搜索树,只有两路查找路径。
- 所有的叶子节点在同一层
- 逐层查找,找到节点后返回
3、B-树的查找方式
- 从根节点的关键字开始比较,例如:上图为13,判断大于还是小于
- 继续往下查找,因为节点可能会有多个节点,所以需要判断属于哪个区间
- 不断往下查找,直到找到为止或者没有找到返回Null
B+树结构
1、B+树简介
B+树是B树的升级版。B+树常用在文件系统和数据库中,B+树通过对每个节点存储数据的个数进行扩展,可以让连续的数据进行快速访问,有效减少查询时间,减少IO操作。它能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度
例如:Linux的Ext3文件系统、Oracle、MySQL、SQLServer都会使用到B+树。
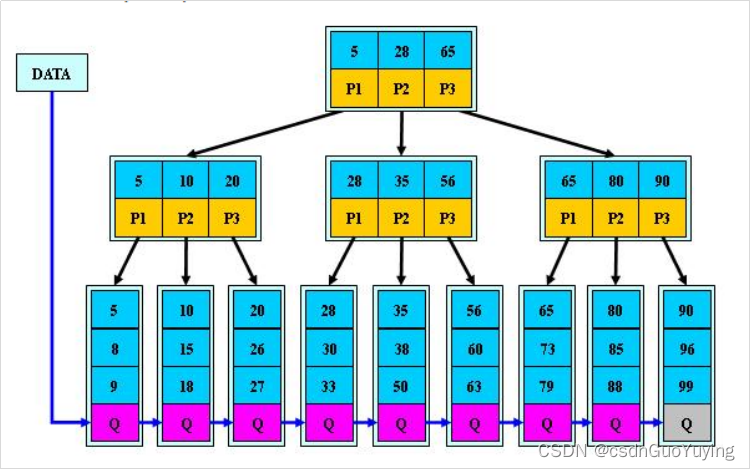
- B+ 树是一种树数据结构,是一个n叉树
- 每个节点通常有多个孩子
- 一颗B+树包含根节点、内部节点和叶子节点
- 只有叶子节点包含数据(所有数据都是在叶子节点中出现)
2、B+树的特点
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的
如果执行的是:select * from user order by id,要全表扫描数据,那么B树就比较费劲了,但B+树就容易了,只要遍历最后的链表就可以了。 - 只会在叶子节点上搜索到数据
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
- 数据库的B+树高度大概在 2-4 层,也就是说查询到某个数据最多需要2到4次IO,相当于0.02到0.04s
3、稠密索引和稀疏索引
稠密索引文件中的每个搜索码值都对应一个索引值
稀疏索引文件只为索引码的某些值建立索引项
稠密索引:
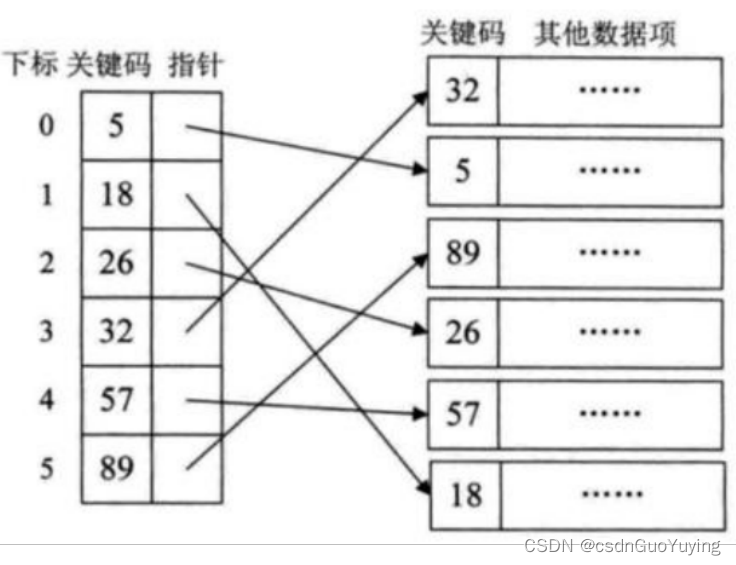
稀疏索引: