名字:阿玥的小东东
学习:python、c++
主页:阿玥的小东东
目录
一、读取文本文件的数据
二、读取电子表格文件
三、读取统计软件生成的数据文件
不论是数据分析,数据可视化,还是数据挖掘,一切的一切全都是以数据作为最基础的元素。利用Python进行数据分析,同样最重要的一步就是如何将数据导入到Python中,然后才可以实现后面的数据分析、数据可视化、数据挖掘等。
在本讲的Python学习中,我们将针对Python如何获取外部数据做一个详细的介绍,从中我们将会学习以下4个方面的数据获取:
1、读取文本文件的数据,如txt文件和csv文件
2、读取电子表格文件,如Excel文件
3、读取统计软件生成的数据文件,如SAS数据集、SPSS数据集等
4、读取数据库数据,如MySQL数据、SQL Server数据
一、读取文本文件的数据
1、读取txt数据
In [1]: import pandas as pd
In [2]: mydata_txt = pd.read_csv('D:\\test_code.txt',sep = '\t',encoding = 'utf-8')
对于中文的文本文件常容易因为编码的问题而读取失败,正如上图所示。遇到这样的编码问题该如何处置呢?解决办法有两种情况:
1)当原始文件txt或csv的数据不是uft8格式时,需要另存为utf8格式编码;
2)如果原始的数据文件就是uft8格式,为了正常读入,需要将read_csv函数的参数encoding设置为utf-8
将原始数据另存为utf8格式的数据,重新读入txt数据
In [3]: mydata_txt = pd.read_csv('C:\\test.txt',sep = '\t',encoding = 'utf-8')
In [4]: mydata_txt
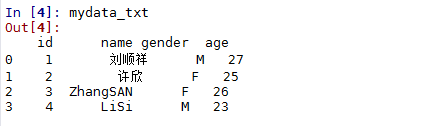
很顺利,txt文本文件数据就这样进入了Python的口袋里了。
2、读取csv数据
csv文本文件是非常常用的一种数据存储格式,而且其存储量要比Excel电子表格大很多,下面我们就来看看如何利用Python读取csv格式的数据文件:
In [5]: mydata_csv = pd.read_csv('C:\\test.csv',sep = ',',encoding = 'utf-8')
In [6]: mydata_csv

如果你善于总结的话,你会发现,txt文件和csv文件均可以通过pandas模块中的read_csv函数进行读取。该函数有20多个参数,类似于R中的read.table函数,如果需要查看具体的参数详情,可以查看帮助文档:help(pandas.read_csv)。
二、读取电子表格文件
这里所说的电子表格就是Excel表格,可以是xls的电子表格,也可以是xlsx的电子表格。在日常工作中,很多数据都是存放在Excel电子表格中的,如果我们需要使用Python对其进行分析或处理的话,第一步就是如何读取Excel数据。下面我们来看看如果读取Excel数据集:
In [7]: mydata_excel = pd.read_excel('C:\\test.xlsx',sep = '\t',encoding = 'utf-8')
In [8]: mydata_excel
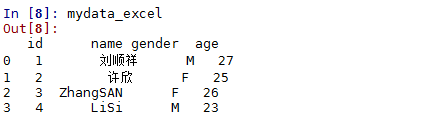
三、读取统计软件生成的数据文件
往往在集成数据源的时候,可能会让你遇到一种苦恼,那就是你的电脑里存放了很多统计软件自带的或生成的数据集,诸如R语言数据集、SAS数据集、SPSS数据集等。那么问题来了,如果你电脑里都装了这些软件的话,这些数据集你自然可以看见,并可以方便的转换为文本文件或电子表格文件,如果你的电脑里没有安装SAS或SPSS这样大型的统计分析软件的话,那么你该如何查看这些数据集呢?请放心,Python很万能,它可以读取很多种统计软件的数据集,下面我们介绍几种Python读取统计数据集的方法:
1、读取SAS数据集
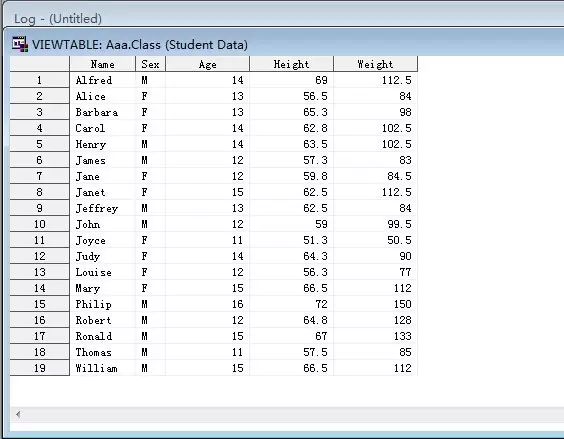
SAS数据集的读取可以使用pandas模块中的read_sas函数,我们不妨试试该函数读取SAS数据集。下图是使用SAS打开的数据集,如果你的电脑中没有安装SAS,那你也可以通过Python实现数据的读取。
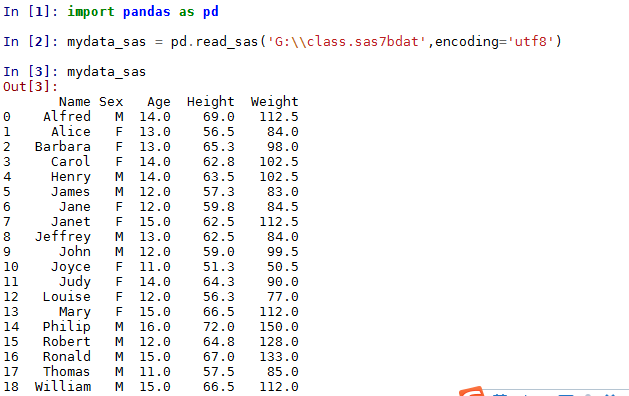
In [1]: import pandas as pd
In [2]: mydata_sas = pd.read_sas('G:\\class.sas7bdat',encoding='utf8')
2、读取SPSS数据集
读取SPSS数据就稍微复杂一点,自己测试了好多次,查了好多资料,功夫不负有心人啊,最终还是搞定了。关于读取SPSS数据文件,需要为您的Python安装savReaderWriter模块,该模块可以到如下链接进行下载并安装:https://pypi.python.org/pypi/savReaderWriter/3.4.2。
安装savReaderWriter模块
可以通过该命令进行savReaderWriter模块的安装:python setup.py install
下图是SPSS数据在SPSS中打开的样子:
In [1]: import savReaderWriter
In [2]: mydata_spss = savReaderWriter.SavReader('employee_data.sav')
In [3]: mydata_spss
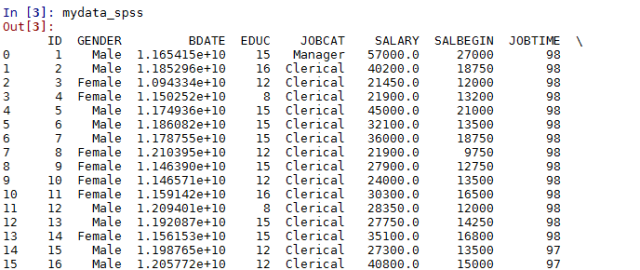
3、实在没办法该怎么办?
如果你尝试了好多种模块都无法读取某个统计软件的数据,我建议你还是回到R中,R也是开源的统计分析工具,体积也非常小,只有40M左右,而且R自带的foreign包可以读取很多种统计软件的数据集,当读取成功后,再利用write.csv函数将数据集写出为csv格式的数据,这样Python就可以轻松读取csv数据集了,万事灵活一点就可以完成你想要的任何结果~
四、读取数据库数据
企业中更多的数据还是存放在诸如MySQL、SQL Server、DB2等数据库中,为了能够使Python连接到数据库中,科学家专门设计了Python DB API的接口。我们仍然通过例子来说明Python是如何实现数据库的连接与操作的。
1、Python连接MySQL
MySQLdb模块是一个连接Python与MySQL的中间桥梁,但目前只能在Python2.x中运行,但不意味着Python3就无法连接MySQL数据库。这里向大家介绍一个非常灵活而强大的模块,那就是pymysql模块。我比较喜欢他的原因是,该模块可以伪装成MySQLdb模块,具体看下面的例子:
In [1]: import pymysql
In [2]: pymysql.install_as_MySQLdb() #伪装为MySQLdb模块
In [3]: import MySQLdb
使用Connection函数联通Python与MySQL
In [4]: conn = MySQLdb.Connection(
...: host = 'localhost',
...: user = 'root'
...: port = 3306,
...: database = 'test',
...: charset='gbk')
使用conn的游标方法(cursor),目的是为接下来的数据库操作做铺垫。
In [5]: cursor = conn.cursor()
In [6]: sql = 'select * from memberinfo'
执行SQL语句
In [7]: cursor.execute(sql)
Out[7]: 4
In [8]: data = cursor.fetchall()
In [9]: data
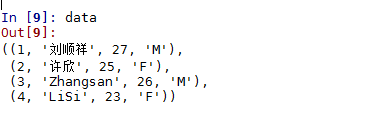
我们发现data中存储的是元组格式的数据集,我们在《Python数据分析之pandas学习(一)》中讲到,构造DataFrame数据结构只能通过数组、数据框、字典、列表等方式构建,但这里是元组格式的数据,该如何处理呢?很简单,只需使用list函数就可以快速的将元组数据转换为列表格式的数据。
In [10]: data = list(data)
In [11]: data
下面我们就是要pandas模块中的DataFrame函数将上面的data列表转换为Python的数据框格式:
In [14]: import pandas as pd
In [15]: mydata = pd.DataFrame(data, columns = ['id','name','age','gender'])
In [16]: mydata

最后千万千万注意的是,当你的数据读取完之后一定要记得关闭游标和连接,因为不关闭会导致电脑资源的浪费。
In [19]: cursor.close()
In [20]: conn.close()
2、Python连接SQL Server
使用Python连接SQL Server数据库,我们这里推荐使用pymssql模块,该模块的语法与上面讲的pymysql是一致的,这里就不一一讲解每一步的含义了,直接上代码:
In [21]: import pymssql
In [22]: connect = pymssql.connect(
...: host = '172.18.1.6\SqlR2',
...: user = 'sa',
...: database='Heinz_Ana',
...: charset='utf8')
In [23]: cursor = connect.cursor()
In [24]: sql = 'select * from HeinzDB2_10'
In [25]: cursor.execute(sql)
In [26]: data = cursor.fetchall()
In [27]: data[0]
Out[27]: (67782, '2013-05-01', '二阶段', 1.0, 279.0)
In [28]: mydata = pd.DataFrame(list(data),columns = ['ConsumerID',
...: 'Purdate',
...: 'Phase',
...: 'ChangeTinRatio',
...: 'TOTALAMT'])
In [29]: mydata.head()

本期的内容就是向大家介绍如何使用Python实现外部数据的读取,只有完成了这个基本的第一步,才会顺利的进行下面的清洗、处理、分析甚至挖掘部分。
喜欢阿玥的可以点个关注;赞;收藏哦,感谢支持











![[golang Web开发] 2.golang web开发:操作数据库,增删改查,单元测试](https://img-blog.csdnimg.cn/b9b8603b6e9f4130bd3597d7e303362b.png)