✍🏻 本文作者:持信、弈臻、悟放、积流、孟诸
1. 摘要
为商品图片上特定位置配上装饰性文案来突出重点在广告业务中有着十分广泛的应用前景。然而,现有的图片文案描述生成系统均生成与图片位置关系无关的文案,无法很好地应用到广告业务中。在本文中我们提出了一种新的文案生成任务——图上文案生成,并基于商品图片数据提出了一个大规模图上文案数据集CapOnImage2M。为了更好的利用上下文以及商品本身的信息来生成更适合特定位置的文案,我们提出了一种基于上下文的多模态图上文案模型,并设计了几种针对位置关系的预训练任务来帮助模型更好的理解位置信息。目前,使用该工作针对业务数据训练的模型,已经应用在淘宝首页焦点位、首页猜你喜欢信息流等广告业务中,并取得了显著的业务收益。该项工作论文已发表在EMNLP 2022,欢迎阅读交流。
论 文:CapOnImage: Context-driven Dense Captioning on Image
下 载(点击↓阅读原文):https://arxiv.org/abs/2204.12974
2.背景
广告主通常会给商品图片配上特定的装饰性文案以突出重点,提升商品的吸引力和信息量,这些文案通常包括产品名、产品介绍、卖点、点击引导、利益点等类型。然而为图片设计合适的图上文案通常需要雇佣专业写手和设计师来完成,成本较高且相对低效。传统的图文创意是基于预设模板的方式,依赖设计师的模板去填充对应的文案,模板的多样性往往不足以匹配图片的多样性,导致模板的适配性不足,同时受限于模板的固定范式,要求我们具有明确指定各种文案类型和特定字数的文案生成能力,不够灵活且适配成本较高。
为此,我们希望提出一种自动化的图文创作方式,在本文中我们提出了图上文案生成,一种新的文案生成任务,利用多模态的文案生成技术,综合考虑图片本身信息(如商品主体、商品主体位置和背景色)、商品文本信息、文本框位置layout以及多个框之间的相对位置关系等信息自适应地生成合适的文案。其中文本框位置可以通过其他手段获取,比如OCR工具或者layout模型生成等。

3.数据集
我们提出了CapOnImage2M数据集来作为图上文案任务的benchmark。它包含50类共计210万业务图片,每张图片包含每个商品标题、属性和图片上不同位置的文案以及对应的坐标。

4.方法设计
4.1 概述
现有的图像文案生成通常是对整张图片生成一个整体的叙述性文案,缺乏对图片在空间上与对应文案的交互关系。在这个任务中,我们将在图片上的多个位置生成多个与之对应的文案。为此,我们提出了一种基于上下文的多模态图上文案的模型,充分利用各模态商品信息去生成合理且多样的图上文案。以上所有输入信息分别进行信息嵌入后输入一个混合模态的多层transformer中,模型通过自回归的方式生成预测的文案[1,2]。为了更好的帮助模型理解上下文位置关系,我们提出了几种不同层级的位置相关的预训练任务,并利用progressive training的策略帮助模型训练。
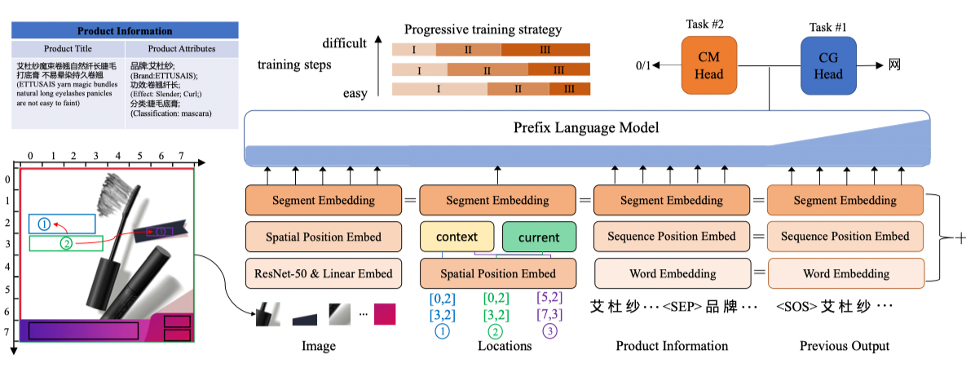
4.2 模型输入
模型将图片、当前位置框、前后位置框、商品类目、商品标题、商品属性对等作为输入,去生成对应当前位置框的文案。所有位置框的原始坐标为像素坐标,为了方便编码,我们将其进行离散化,具体来说,整张图从横纵两个方向切分为固定数量(示意图中以7X7为例)的格子patch,将位置框的坐标所在的patch的横纵坐标作为框的embedding id。图像部分的输入经过。在模型训练的过程中,由于图片上含有文字(即待生成的),为了避免模型坍塌成识别图上文字的OCR任务,我们对原图上的文字部分进行了mask。
4.3 预训练方案
我们通过预训练微调的方式来训练模型,首先通过Caption Generation(CG)和Caption Matching(CM)两个任务对模型进行预训练,在微调阶段仅利用CG任务来生成文案。CG任务我们使用Prefix LM[1,2]的方式进行解码;CM任务与视觉语言预训练工作中常用的Image-Text Matching[3,4,5]任务类似,都是构造正负样本让模型来预测图片和caption之间是否匹配,在图上文案这个任务当中,为了帮助模型进一步的理解位置关系,我们设计了3种不同难度的负样本:
Level-I: Image caption matching. 第一种负样本是我们随机替换正确的caption为其它图片的caption,我们希望模型能通过图片和商品信息来很好的识别这一类负样本。
Level-II: Location caption matching. 第二种负样本是将正确的caption随机替换为同一张图片上其它位置的caption,我们希望模型能通过文字的位置信息更好的理解文字的关系。
Level-III: Neighbor-location caption matching. 第三种负样本是将正确的caption随机替换为同一张图片上相邻(包含前后)位置的caption,这一种负样本可以看做第二种的一种特殊形式。
因为三种负样本是从易到难,我们进一步提出利用progressive training的策略在训练过程中动态的调整样本难易,来进一步帮助模型理解位置关系。
5. 实验
5.1 定量分析
因为图上文案任务是一个新提出的任务,我们将传统的图像文本描述任务的相关模型适配到我们的任务上。从表一中可以看出我们的模型在准确性以及多样性的指标上均取得了最好的结果。

5.2 消融实验
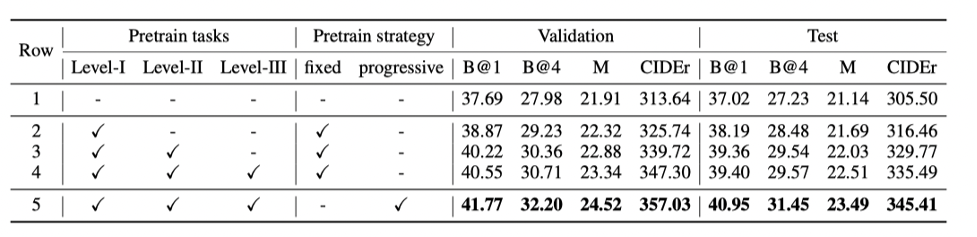
我们进一步进行实验对我们提出的三种预训练task以及progressive training策略的有效性进行验证,从表二可以看出,三种不同难度的预训练task均可以帮助模型更好的理解位置关系,进而提升模型效果;progressive training的策略进一步提升了模型的效果。
5.3 可视化分析
在图四中我们可视化了一些生成的case,并与ground-truth进行了对比,可以看出模型生成的文案很好的理解了多模态信息以及上下文位置关系,生成了与位置相匹配的文案。

6. 总结与展望
本文提出了一种新的文案生成任务——图上文案生成,在广告、社交平台图片等多个场景都有着很好的应用前景,我们基于商品图片提出了一个大规模数据集 CapOnImage2M 以方便后续工作对任务进行进一步探索。我们相信自动化是图文创作的未来,希望本文工作能对后续广告文案自动化生成有所启发。
后续我们将持续改进图上文案生成的质量,并预期可以不借助于前置文本框预测模型和后置文字渲染模型,做到端到端的文字渲染。
7. 关于我们
我们是阿里妈妈创意&内容算法团队,致力于推动广告创意和内容投放产业的AI升级,努力推动创意制作、理解、模型预估和广告投放的全栈智能化。得益于阿里巴巴庞大而真实的营销场景,团队在图像技术、视频技术、文案生成、广告投放等领域持续发力和创新,现已构建出图片与短视频创意自动生成,创意个性化投放,智能文案写作,全自动与交互式抠图等特色产品,论文发表于CVPR、ICCV、AAAI、ACMMM、WWW、EMNLP、CIKM、ICASSP 等领域知名会议。用AI赋能现代营销,驱动产业升级。真诚欢迎CV、NLP和推荐系统相关领域的同学加入!
投递简历邮箱:
alimama_chuangyi@service.alibaba.com
8. 引用
[1] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. J. Mach. Learn. Res., 2020, 21(140): 1-67.
[2] Dong L, Yang N, Wang W, et al. Unified language model pre-training for natural language understanding and generation[J]. Advances in Neural Information Processing Systems, 2019, 32.
[3] Chen Y C, Li L, Yu L, et al. Uniter: Universal image-text representation learning[C]//European conference on computer vision. Springer, Cham, 2020: 104-120.
[4] Li G, Duan N, Fang Y, et al. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(07): 11336-11344.
[5] Zhuge M, Gao D, Fan D P, et al. Kaleido-bert: Vision-language pre-training on fashion domain[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 12647-12657.
END

也许你还想看
丨营销文案的“瑞士军刀”:阿里妈妈智能文案多模态、多场景探索
丨实现"模板自由"?阿里妈妈全自动无模板图文创意生成
丨告别拼接模板 —— 阿里妈妈动态描述广告创意
丨如何快速选对创意 —— 阿里妈妈广告创意优选

喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓









![[golang Web开发] 2.golang web开发:操作数据库,增删改查,单元测试](https://img-blog.csdnimg.cn/b9b8603b6e9f4130bd3597d7e303362b.png)