前面介绍过队列,队列是一种先进先出(FIFO)的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队 列时,可能需要优先级高的元素先出队列,该中场景下,使用队列显然不合适,比如:在手机上玩游戏的时候,如果有来电,那么系统应该优先处理打进来的电话;初中那会班主任排座位时可能会让成绩好的同学先挑座位。 在这种情况下,数据结构应该提供两个最基本的操作,一个是返回最高优先级对象,一个是添加新的对象。这种数据结构就是优先级队列(Priority Queue)。
JDK1.8中的 PriorityQueue 底层使用了堆这种数据结构,而堆实际就是在完全二叉树的基础上进行了一些调整。 下面将详细介绍堆。
1. 堆
1.1 堆的概念
如果有一个关键码的集合K = {k0,k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一 个一维数组中,并满足:Ki <= K2i+1 且 Ki<= K2i+2 (Ki >= K2i+1 且 Ki >= K2i+2) i = 0,1,2…,则称为小堆(或大 堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
堆的性质: 1. 堆中某个节点的值总是不大于或不小于其父节点的值。 2. 堆总是一棵完全二叉树。

从堆的概念可知,堆是一棵完全二叉树,因此可以层序的规则采用顺序的方式来高效存储,而对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节 点,就会导致空间利用率比较低。 将元素存储到数组中后,假设 i 为节点在数组中的下标,则有: 如果 i 为0,则 i 表示的节点为根节点,否则 i 节点的双亲节点为 (i - 1)/2 如果 2 * i + 1 小于节点个数,则节点i的左孩子下标为 2 * i + 1 ,否则没有左孩子 如果 2 * i + 2 小于节点个数,则节点i的右孩子下标为 2 * i + 2 ,否则没有右孩子
1.2 堆的创建
堆是存储在一个一维数组中的,那么怎么用通过一个数组,让其变成一个堆呢?先简单介绍一下向下调整形成大根堆的思路:由于输入的数组是随机的,其对应的二叉树,也并不总是父亲节点的值大于孩子节点,所以我们要做的就是调整位置,让父亲节点的值与左右孩子节点的最大值做比较,小了,就与孩子节点交换位置,而大了,不做改变,从而让这个二叉树变成大根堆。
1.2.1 堆向下调整
public class TextHeap {
public int[] elem;
public int usedSized;
public TextHeap() {
this.elem = new int[10];
}
public void initElem(int[] arr){
for (int i = 0; i < arr.length; i++) {
elem[i] = arr[i];
usedSized++;
}
}
/*
//创建大根堆
*/
public void createHeap(){
//找到这个完全二叉树中,最后一个父亲节点的下标:
//最后一个节点的父亲节点,也是该二叉树的最后一个父亲节点,以此开始
for (int parent = (usedSized - 1 - 1 )/ 2; parent >= 0 ; parent--) {
//使用 usedSize 作为向下调整的最大边界
shiftDown(parent,usedSized);
}
}
private void shiftDown(int parent,int len){
//最起码有左孩子
int child = 2 * parent + 1;
// 可能需要多次向下调整:
while(child < len){
//如果有右孩子时,得让 child 这个下标对应左右孩子最大值的下标
if(child + 1 < len && elem[child] < elem[child + 1]){
child++;
}
if(elem[child] > elem[parent]){
int temp = elem[child];
elem[child] = elem[parent];
elem[parent] = temp;
parent = child;
child = 2 * parent + 1;
}else{
break;
}
}
}
}1.3 堆向下调整创建堆的时间复杂度
按照最坏的情况来看,即创建一棵高度为 h 的满二叉树的话,这样的堆的时间复杂度该如何计算呢?
高度为 h ,那么最后一层就是第 h 层,该层的节点总数为 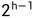 ,这一层都是叶子节点,并不需要向下调整。而倒数第二层,即 h - 1 层,该层的节点总数为
,这一层都是叶子节点,并不需要向下调整。而倒数第二层,即 h - 1 层,该层的节点总数为 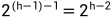 ,而这里的每一个节点都需要向下调整 1 次。以此类推到第一层。
,而这里的每一个节点都需要向下调整 1 次。以此类推到第一层。

 ①
①
 ②
②
由② - ① 得:
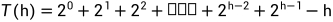
化简得:
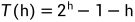
又因为总节点数 n 满足:

所以有

所以时间复杂度为
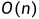
1.4 堆向上调整创建堆的时间复杂度
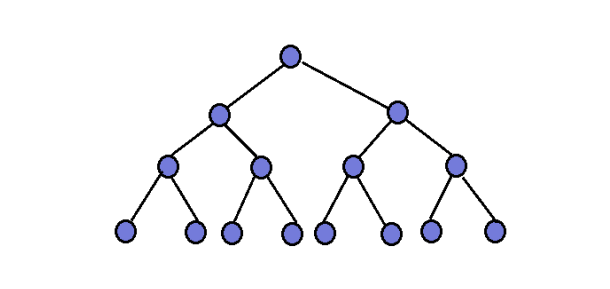

 ①
①
 ②
②
② - ① 得
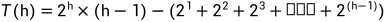
化简得:

最后:
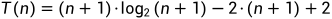
因此时间复杂度为:
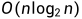
1.5 堆的插入
将要插入的元素放在堆的最后位置,向上调整,时间复杂度为二叉树的高度,只需一路向上,跟父亲节点比较交换即可。
private void shiftUp(int child){
int parent = (child - 1)/2;
while(child > 0){
if(elem[child] > elem[parent]){
int temp = elem[child];
elem[child] = elem[parent];
elem[parent] = temp;
child = parent;
parent = (child - 1)/2;
}else{
break;
}
}
}
//堆的插入
public void offer(int val){
if(isFull()){
//满了就扩容
elem = Arrays.copyOf(elem,elem.length+5);
}
elem[usedSized++] = val;
shiftUp(usedSized - 1);
}
private boolean isFull(){
return usedSized == elem.length;
}1.6 堆的删除
堆的删除,只能删除根节点元素。删除的思路:把根节点元素与堆中最后一个元素交换,usedSize--,同时向下调整。
//堆的删除
public void pop(){
if(isEmpty()){
return;
}
elem[0] = elem[usedSized - 1];
usedSized--;
//只需从0下标的这个父亲节点去向下调整就可以了
shiftDown(0,usedSized);
}
private boolean isEmpty(){
return usedSized == 0;
}1.7 堆排序
堆排序:将存储堆的数组里的元素,从小到大或从大到小排序
从小到大,建大堆
public class Text{
public static void main(String[] args) {
int[] arr = {1,4,6,235,15,75,123,61,70,13};
TextHeap heap = new TextHeap();
heap.initElem(arr);
heap.createHeap();
heap.heapSort();
System.out.println();
}
}
public class TextHeap{
........
//省略的部分可往前文查找
private void swap(int[] arr,int i ,int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
//堆排序
public void heapSort(){
int end = usedSized - 1;
while(end > 0 ){
swap(elem,0,end);
shiftDown(0,end);
end--;
}
}
}
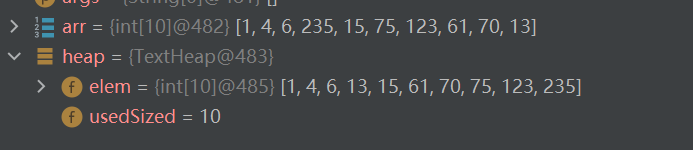
时间复杂度O(nlogn),空间复杂度O(1)。
而从大到小,则建小堆。这里就不再赘述。
2. 优先级队列(Priority Queue)
2.1 优先级队列的性质
Java集合框架中提供了 PriorityQueue 和 PriorityBlockingQueue 两种类型的优先级队列,PriorityQueue是线 程不安全的,PriorityBlockingQueue是线程安全的,本文主要介绍PriorityQueue。
关于PriorityQueue的使用要注意: 1. 使用时必须导入PriorityQueue所在的包,即:
import java.util.PriorityQueue;
2. PriorityQueue中放置的元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出 ClassCastException异常
比如以下代码,priorityQueue中存放的是Student的对象,此时这些对象并不能比较大小:
public static void main(String[] args) {
Queue<Student> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(new Student("huahua",15));
priorityQueue.offer(new Student("liu",34));
System.out.println(priorityQueue.poll());
}因此报错:

3. 不能插入null对象,否则会抛出NullPointerException

4. 没有容量限制,可以插入任意多个元素,其内部可以自动扩容 5. 插入和删除元素的时间复杂度为 ,也就是二叉树的高度 6. PriorityQueue底层使用了堆数据结构 7. PriorityQueue默认情况下是小堆---即每次获取到的元素都是最小的元素
,也就是二叉树的高度 6. PriorityQueue底层使用了堆数据结构 7. PriorityQueue默认情况下是小堆---即每次获取到的元素都是最小的元素
//检验一下 PriorityQueue 真的默认为小根堆?
public static void main(String[] args) {
Queue<Integer> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(1);
priorityQueue.offer(88);
System.out.println(priorityQueue.poll());
}2.2 top-k 问题
设计一个算法,找出数组中最小或最大的前k个数。以任意顺序返回这k个数均可。
2.2.1 排序思路——效率较低
将这个数组建成小根堆,拿这小根堆的前10个元素,但这种方法效率低下。
//top-k问题
//排序思路
public int[] topK1(int[] arr,int k){
int[] ret = new int[k];
if(arr == null || k == 0){
return ret;
}
Queue<Integer> priorityQueue = new PriorityQueue<>();
for (int i = 0; i < arr.length; i++) {
priorityQueue.offer(arr[i]);
}
for (int i = 0; i < k; i++) {
ret[i] = priorityQueue.poll();
}
return ret;
}2.2.2 善于利用堆排序解决topk问题
如果是输出数组中前k个最大的元素,其实只要创建容量为k的优先队列即可,而不是像3.2.1那样,创建一个容量为arr.length的优先队列。
此时容量为k的优先队列默认为小根堆,让数组的前k个元素放入优先级队列中,之后让数组从第k+1个元素往后遍历,每一个都与小根堆的堆顶元素做比较。由于是小根堆,堆顶元素就是k个元素中,最小的一个,与数组第k+1个元素及以后的元素作比较,挨个置换比根节点大的元素,那么等数组遍历完之后,小根堆里存储的元素都比数组中其余元素要大,不然的话,还是会被置换出来的。如此一来,小根堆存储的就是数组中前k个最大元素。
public static int[] topK2(int[] arr,int k){
int[] ret = new int[k];
if(arr == null || k == 0){
return ret;
}
Queue<Integer> priorityQueue = new PriorityQueue<>(k);
for (int i = 0; i < k; i++) {
priorityQueue.offer(arr[i]);
}
for (int i = k; i < arr.length; i++) {
if(arr[i] > priorityQueue.peek()){
priorityQueue.poll();
priorityQueue.offer(arr[i]);
}
}
for (int i = 0; i < k; i++) {
ret[i] = priorityQueue.poll();
}
return ret;
}
public static void main(String[] args) {
int[] arr = {1,6,43,2,7,88,67,17,29,257,35};
int[] ret = topK2(arr,3);
System.out.println(Arrays.toString(ret));
}输出:
[67, 88, 257]
问题换一换,找第k大的元素?
其实就是堆顶元素啦~~
那如果要求的是前k个最小元素呢?这时候就要用到大根堆,可优先级队列默认是小根堆,那该如何在优先级队列中创建大根堆呢?
2.3 优先级队列构造方法
此处只是列出了PriorityQueue中常见的几种构造方式。
构造器 | 功能介绍 |
PriorityQueue() | 创建一个空的优先级队列,默认容量是11 |
PriorityQueue(int initialCapacity) | 创建一个初始容量为initialCapacity的优先级队列,注意: initialCapacity不能小于1,否则会抛IllegalArgumentException异 常 |
PriorityQueue(int initialCapacity, Comparator<? super E> comparator) | 创建一个初始容量为initialCapacity的优先级队列,并且有比较器 |
PriorityQueue(Collection<? extends E> c) | 用一个集合来创建优先级队列 |
public static void main(String[] args) {
// 创建一个空的优先级队列,底层默认容量是11
Queue<Integer> q1 = new PriorityQueue<>();
// 创建一个空的优先级队列,底层的容量为 100
Queue<Integer> q2 = new PriorityQueue<>(100);
// 用ArrayList对象来构造一个优先级队列的对象
// q3中已经包含了三个元素
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(45);
list.add(23);
Queue<Integer> q3 = new PriorityQueue<>(list);
q3.offer(9);
System.out.println(q3.size());
}输出:
4
2.4 对象的比较方式
优先级队列在插入元素时有个要求:插入的元素不能是null或者元素之间必须要能够 进行比较,为了简单起见,我们只是插入了Integer类型,那优先级队列中能否插入自定义类型对象呢?
优先级队列底层使用堆,而向堆中插入元素时,为了满足堆的性质,必须要进行元素的比较,而在优先级队列的性质那一小节中,优先级队列插入的是引用类型,是没有办 法直接进行比较的,因此抛出异常。因此在这里引出一个问题,对象的比较方式,以下介绍三种方法:
2.4.1 equals方法
class Student{
public String name;
public int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
}
public static void main(String[] args) {
Student student1 = new Student("shanshan",15);
Student student2 = new Student("shanshan",15);
System.out.println(student1==student2);
System.out.println(student1.equals(student2));
}输出:
false
false
==比较的是地址,输出是false;而当我们一开始直接就用equals时,返回的依旧是false。这是因为Student类中并无equals方法,而所有类都是Object类的子类,所以调用的就是Object类的equals方法:

我们发现,此处的equals方法也等同于==,比较的是引用变量的地址。
但是此处,我们需要比较的是对象中的内容,那该如何处理呢?基于此,我们可以覆写基类的equals方法。(可右击自动生成)
class Student{
public String name;
public int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}输出:
false
true
覆写基类equal的方式虽然可以比较,但缺陷是:equal只能按照相等进行比较,不能按照大于、小于的方式进行比较。
因此,优先级队列并不采用equals方法。
2.4.2 Compareble接口
Comparble是JDK提供的泛型的比较接口类,源码实现具体如下:
public interface Comparable<T> {
public int compareTo(T o);
}
对用用户自定义类型,如果要想按照大于、小于的方式进行比较时:在定义类时,实现Comparble接口即可,然后在类 中重写compareTo方法,举例如下:
class Student implements Comparable<Student>{
......
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}但这样compareTo就只能比较年龄了,那要是想比较学生的成绩或是其他,该怎么办呢?
2.4.2 基于比较器比较
Comparator部分源代码:
public interface Comparator<T> {
int compare(T o1, T o2);
......
}按照比较器方式进行比较,具体步骤如下: 用户自定义比较器类,实现Comparator接口并且重写Comparator中的compare方法:
//姓名比较器
class nameComparator implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
return o1.name.compareTo(o2.name);
}
}
//年龄比较器
class AgeComparator implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
return o1.age - o2.age;
}
}上面的compareTo方法中,因为name是String类的对象,可以调用String中的compareTo方法,这里比较的是两个字符串的大小。
NameComparator nameComparator = new NameComparator();
System.out.println(nameComparator.compare(student1,student2));2.5 优先级队列的比较方式
集合框架中的PriorityQueue底层使用堆结构,因此其内部的元素必须要能够比大小,PriorityQueue采用了: Comparble和Comparator两种方式。 1. Comparble是默认的内部比较方式,如果用户插入自定义类型对象时,该类对象必须要实现Comparble接 口,并覆写compareTo方法 2. 用户也可以选择使用比较器对象,如果用户插入自定义类型对象时,必须要提供一个比较器类,让该类实现 Comparator接口并覆写compare方法。
继续用上面Student类的例子,来演示如何将自定义类型对象插入优先级队列,以及如何创建大根堆:
Comparble接口:
class Student implements Comparable<Student>{
public String name;
public int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
//为创建大根堆
@Override
public int compareTo(Student o) {
return o.age - this.age;
}
}
public static void main(String[] args) {
Student student1 = new Student("shansan",10);
Student student2 = new Student("shanan",15);
PriorityQueue<Student> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(student1);
priorityQueue.offer(student2);
System.out.println("sssssssss");
}
Comparator接口:
class InCmp implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
//调用了Integer这个类中的compareTo方法
return o2.compareTo(o1);
//return o1 - o2;
}
}
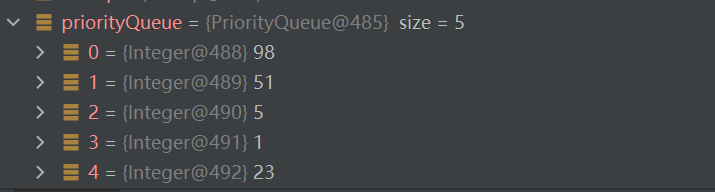
public static void main(String[] args) {
InCmp inCmp = new InCmp();
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(inCmp);
priorityQueue.offer(5);
priorityQueue.offer(1);
priorityQueue.offer(98);
priorityQueue.offer(23);
priorityQueue.offer(51);
System.out.println("2222222222222222222");
}
还可以使用匿名内部类的方法写:
//一个实现了Comparator接口的匿名内部类
PriorityQueue<Integer> priorityQueue1 = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//小根堆
return o1.compareTo(o2);
}
});