协程设计原理
背景
以epoll处理fd为例:
func () {
while (1) {
epoll_wait();
for(;;) {
recv();
send();
}
}
}
在IO操作较为密集的情况下(网络IO和磁盘IO操作多,CPU计算少),由于检测到IO事件后,需要进行同步的IO操作,使得IO处理性能降低;因此,可以将这些recv()、send()操作交给异步线程(如消息队列+线程池):
thread_cb(void *arg) {
recv();
send();
}
func () {
while (1) {
epoll_wait();
for (;;) {
push_other_thread();
}
}
}
然而,这样会不可避免地出现一个问题:同一个fd可能被多个线程处理,导致数据乱序,连接关闭了但数据未完全发送等问题。
协程
协程:同步的编程方式,异步的性能,适合做IO密集型任务
如浏览器需解析50个域名,请求DNS服务器时,同步的做法是将域名发送给DNS服务器后,等待结果返回再去发送其他域名的解析请求;另一种高效的同步方法是发送完请求后,将fd加入epoll,先去发送其他域名的解析请求,等到epoll检测到IO事件后再处理返回结果。
// 版本一:
while(idx++<50){
send(fd);
epoll_ctl(epfd,add,fd);
int nready=epoll_wait(epfd); // 这里把超时事件设置为0
while(i++<nready){
recv();
}
}
进一步将IO检测和IO操作分开:
// 版本二:
// IO操作
while(idx++<50){
<label1> // 恢复:`resume`
send(fd);
epoll_ctl(epfd,add,fd);
jump label2 // 跳转到lable2,相当于python中yield`原语`,goto只能在一个栈内跳转(函数内部跳转)
while(i++<nready){
recv();
}
jump label2
}
// IO检测
<label2>
int nready = epoll_wait(epfd);
jump label1 // 跳转到label1
其中,epoll_wait()就相当于协程调度器,IO操作就是协程,一个协程让出,另一个协程恢复
实现上面的代码要解决的问题:切换(jump)怎么实现
- C提供的标准接口:setjmp、longjmp
- Linux提供的接口:ucontext
- 自己汇编实现,本文利用汇编实现
首先,我们需要理解线程切换的概念:线程切换也只涉及基本的CPU上下文切换,也就是切换寄存器信息,而寄存器主要有:
- 栈指针寄存器 %rsp:函数的栈顶指针就存储在这里
- 指令指针寄存器 %rip:标识CPU运行的下一条指令
- 栈帧指针寄存器 %rbp:栈帧指针,标识当前栈帧的起始位置
- 状态寄存器 %rbx、%r12~%r15等:如标识CPU当前在用户态还是内核态下工作,以及进位、溢出状态
上下文可以说是一个程序的运行时切面,拿到了某一时刻的上下文,那就可以在这一时刻进行暂停与恢复;
而切换上下文分为两步:保存源寄存器值,将目的寄存器值加载到寄存器:
int _switch(nty_cpu_ctx *new_ctx, nty_cpu_ctx *cur_ctx);
// x86架构64位
__asm__ (
" .text \n"
" .p2align 4,,15 \n"
".globl _switch \n"
".globl __switch \n"
"_switch: \n"
"__switch: \n"
" # 保存第一个协程的寄存器的值 \n"
" movq %rsp, 0(%rsi) # save stack_pointer \n"
" movq %rbp, 8(%rsi) # save frame_pointer \n"
" movq (%rsp), %rax # save insn_pointer \n"
" movq %rax, 16(%rsi) \n"
" movq %rbx, 24(%rsi) # save rbx,r12-r15 \n"
" movq %r12, 32(%rsi) \n"
" movq %r13, 40(%rsi) \n"
" movq %r14, 48(%rsi) \n"
" movq %r15, 56(%rsi) \n"
" # 将第二个协程的寄存器的值加载到寄存器 \n"
" movq 56(%rdi), %r15 \n"
" movq 48(%rdi), %r14 \n"
" movq 40(%rdi), %r13 # restore rbx,r12-r15 \n"
" movq 32(%rdi), %r12 \n"
" movq 24(%rdi), %rbx \n"
" movq 8(%rdi), %rbp # restore frame_pointer \n"
" movq 0(%rdi), %rsp # restore stack_pointer \n"
" movq 16(%rdi), %rax # restore insn_pointer \n"
" movq %rax, (%rsp) \n"
" ret \n"
);
线程切换和协程切换的区别:线程是需要操作系统调度的,也就是说首先要从用户态切换到内核态调用,然后有要从内核态切换到用户态执行,而协程只发生在用户态(感觉协程就像是个自己写的框架,一个线程在某一时刻只能运行一个协程,goroutine里单个线程中的协程也是并发的,如果要真正并行,需要多个线程或进程,也就是绑定不同核的协程才能真正地并行)
协程状态
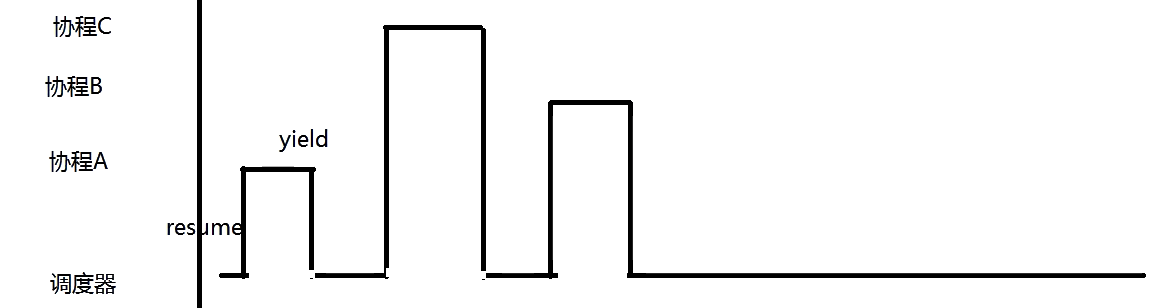
在一个时间片内,在调度器里运行一段时间,在协程A运行一段时间,在调度器里运行一段时间,在协程B里运行一段时间,参考go,一个线程设置一个调度器
总体流程是:协程遇到IO操作yeild,回到调度器,调度器去resume协程:
void nty_schedule_run(void) {
nty_schedule *sched = nty_coroutine_get_sched();
if (sched == NULL) return ;
while (!nty_schedule_isdone(sched)) {
// 1. expired --> sleep rbtree
nty_coroutine *expired = NULL;
while ((expired = nty_schedule_expired(sched)) != NULL) {
nty_coroutine_resume(expired); // 休眠的协程优先恢复
}
// 2. ready queue
nty_coroutine *last_co_ready = TAILQ_LAST(&sched->ready, _nty_coroutine_queue);
while (!TAILQ_EMPTY(&sched->ready)) {
nty_coroutine *co = TAILQ_FIRST(&sched->ready);
TAILQ_REMOVE(&co->sched->ready, co, ready_next);
if (co->status & BIT(NTY_COROUTINE_STATUS_FDEOF)) {
nty_coroutine_free(co);
break;
}
nty_coroutine_resume(co);
if (co == last_co_ready) break;
}
// 3. wait rbtree
nty_schedule_epoll(sched);
while (sched->num_new_events) {
int idx = --sched->num_new_events;
struct epoll_event *ev = sched->eventlist+idx;
int fd = ev->data.fd;
int is_eof = ev->events & EPOLLHUP;
if (is_eof) errno = ECONNRESET;
nty_coroutine *co = nty_schedule_search_wait(fd);
if (co != NULL) {
if (is_eof) {
co->status |= BIT(NTY_COROUTINE_STATUS_FDEOF);
}
nty_coroutine_resume(co);
}
is_eof = 0;
}
}
nty_schedule_free(sched);
return ;
}
协程入口函数中的让出部分代码:
static int nty_poll_inner(struct pollfd *fds, nfds_t nfds, int timeout) {
if (timeout == 0)
{
return poll(fds, nfds, timeout);
}
if (timeout < 0)
{
timeout = INT_MAX;
}
nty_schedule *sched = nty_coroutine_get_sched();
nty_coroutine *co = sched->curr_thread;
int i = 0;
for (i = 0;i < nfds;i ++) {
struct epoll_event ev;
ev.events = nty_pollevent_2epoll(fds[i].events);
ev.data.fd = fds[i].fd;
epoll_ctl(sched->poller_fd, EPOLL_CTL_ADD, fds[i].fd, &ev);
co->events = fds[i].events;
nty_schedule_sched_wait(co, fds[i].fd, fds[i].events, timeout);
}
nty_coroutine_yield(co); // 遇到IO操作,加入epoll后让出(切换新的寄存器信息与协程)
for (i = 0;i < nfds;i ++) {
struct epoll_event ev;
ev.events = nty_pollevent_2epoll(fds[i].events);
ev.data.fd = fds[i].fd;
epoll_ctl(sched->poller_fd, EPOLL_CTL_DEL, fds[i].fd, &ev);
nty_schedule_desched_wait(fds[i].fd);
}
return nfds;
}
在网络IO中,一个协程对应一个fd是可行的,但是在磁盘IO中并不实用;其次,协程+epoll的实时性和只用epoll的实时性是差不多的;并且比reactor+epoll实时性要差
代码讲解
结构体定义
定义协程结构体和调度器结构体:
struct cpu_register_set { // CPU寄存器
void *r1;
void *ebx;
.......
};
// 队列宏定义
#define queue_node(name, type) struct name { \
struct type *next; \
struct type *prev; \
}
#define rbtree_node(name, type) struct name {
char color;
struct type *right;
struct type *left;
struct type *parent;
}
// 协程结构体
struct coroutine {
struct cpu_register_set *set; //cpu寄存器组
void *func; // 协程入口函数 ,参考pthread_create(),调用后不立即执行,只做两件事,创建task_struct* task结构体,将该结构体加入enqueue_ready就绪队列,然后由线程调度器调度
void *arg; // 入口函数参数
void *retval; // 协程返回值
void *stack_addr; // 协程栈,协程一开始执行就将指针指向该栈栈顶,最好一个协程一个栈(独立栈),也可以采用共享栈 =》堆上的空间,栈结构
size_t stack_size; // 栈大小
//struct coroutine *next; // 最简单的做法,协程队列,不考虑协程状态,先到的IO先处理
// 将协程按状态调度:新建、等待、就绪、睡眠、退出
queue_node(ready_queue, coroutine) *ready; // 就绪队列,用链表就ok
rbtree_node(coroutine) *sleep; // optional,跟时间的大小有关系,用红黑树且用时间做key,将超时节点置入就绪队列;不用最小堆,没有顺序,比如有两个节点超时了,小根堆只能一个一个取,太慢了
rbtree_node(coroutine) *wait; // 也跟时间有关系
};
struct scheduler { // 调度器
struct scheduler_ops *ops; // 调度策略
struct coroutine *cur; // 当前运行的协程,即调度的协程
int epfd; // epfd放到调度器中
queue_node *ready_set;
rbtree() *wait_set;
rbtree() *sleep_set;
};
// 设置多个调度策略:如多状态运行、生产消费者模式
struct scheduler_ops {
struct scheduler_ops *next;
enset();
deset();
};
API
API有两类,一类是对协程api的改造(参考线程api),一类是对网络api的改造(同步改异步+hook)
// 第一类
coroutine_create(entry_cb, arg); // 创建协程
coroutine_join(coid, &ret) { // 协程返回值,参考pthread_join()
co = search(coid) // 通过协程id获取协程
while (co->ret == NULL) {
wait(); // 条件等待cond_wait();
}
return co->ret;
}
exec(co) { // 获取返回值
co->reval = co->func(co->arg);
signal();
}
......
// 第二类:
// 同步IO api改异步,如accept(),send(),connection()等
accept_f(){
int ret = poll(fd); // 超时时间设置为0
if ( ret>0){
accept();
}else{
epoll_ctl(epfd,);
yield(); // 先让出,等待被调用
}
}
// 但是如果在项目中,很多地方都是调用的accept(),send(),难道要一个一个去更改函数名吗? =》 hook
// hook:进程在启动时,会分配一块虚拟内存,其中的代码段中的accpet等动态链接库函数指针重定向到accpet_f等自定义函数,在调用accpet时,就是调用的我自己的accpet而不是系统的
accept_t accept_f = NULL;
int init_hook(void) {
socket_f = (socket_t)dlsym(RTLD_NEXT, "socket");
//read_f = (read_t)dlsym(RTLD_NEXT, "read");
recv_f = (recv_t)dlsym(RTLD_NEXT, "recv");
recvfrom_f = (recvfrom_t)dlsym(RTLD_NEXT, "recvfrom");
//write_f = (write_t)dlsym(RTLD_NEXT, "write");
send_f = (send_t)dlsym(RTLD_NEXT, "send");
sendto_f = (sendto_t)dlsym(RTLD_NEXT, "sendto");
accept_f = (accept_t)dlsym(RTLD_NEXT, "accept");
close_f = (close_t)dlsym(RTLD_NEXT, "close");
connect_f = (connect_t)dlsym(RTLD_NEXT, "connect");
}
int accept(int fd, struct sockaddr *addr, socklen_t *len) {
if (!accept_f) init_hook();
......
return sockfd;
}
......
多核模式:协程要实现多核模式,需要借助多线程(CPU亲缘性)或多进程
github参考链接

![[Ansible系列]ansible tag介绍](https://img-blog.csdnimg.cn/44edd5ffd33d41159cbd2783a4980685.png)