文章目录
- Abstract
- Introduction
- Related works
- Method
- Experiment
- dataset
- baselines
- results
- main results
- analysis
- Limitation

Abstract
已有研究表明,大型语言模型(LLM)在文本的少样本推理中表现excellent,本文证明LLM在表结构的f复杂少样本推理中表现也很competent。
Introduction
已有结构化文本推理方法基于特定的输入输出格式和领域,在实际应用中需要大量语料进行微调才能取得理想效果。
本文希望找到一套通用的、不需要微调的、对表结构没有严格限制的少样本推理模型。
Related works
reasoning over tables: 存在上述缺点
In-context learning with LLMs: GPT-3可以很好地执行少样本学习
Chain of Thoughts Reasoning(CoT):相比传统prompt learning多了一些推理过程模板。
本文没有详细介绍CoT,可以参考原文:
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.

Method
任务:QA 和 fact vertification
Models:
| LLM | details |
|---|---|
| GPT3(direct) | GPT-3直接预测 |
| GPT3(+CoT) | 结合chain of thoughts |
| GPT3(+CoT-SC) | 结合chain of thoughts和多路径投票策略 |
| Codex | Codex模型 |
提示文本生成:linearize the table+concatenate it with a few examples
Experiment
dataset
question answering: WikiTableQuestions, FetaQA
fact vertification: TabFact, FEVEROUS
baselines
Pre-trained Encoder-Decoder Model : against T5(2020) and BART(2020)
Pre-trained Table Understanding Model: TAPAS (2020), TABERT (2020), and TAPEX(2021)
Neural Symbolic Model: LogicFactChecker (2020), Neural-Symbolic Machine (2018)
results
main results
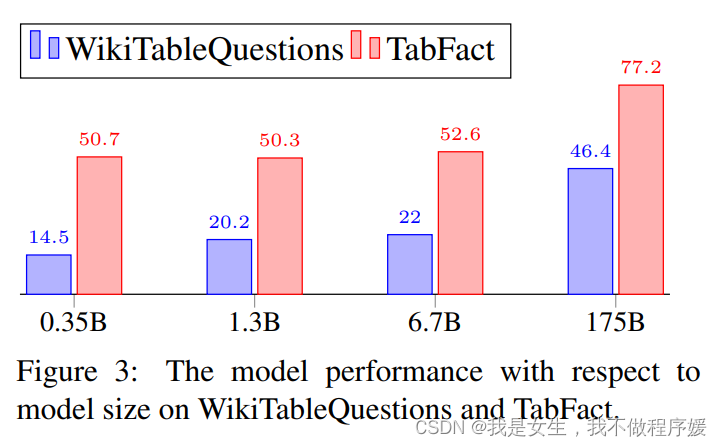
LLMs are not optimized, but highly competent, especially when combined with CoT.

analysis
Impact of Number of Shots : not sensitive, 1-shot 到2-shot有性能提升,但再增加则鲜有提升。
Quality Evaluation of Reasoning Chains :人工抽取推理链,证明预测结果是基于正确推理路径而非猜测。
Impact of Table Size:highly sensitive, 预测性能随着表增大单调下降,超过1000 tokens时退化为随机猜测。
Limitation
- 性能非最优
- costly,只有在大size下表现才较好。