数学建模简介
文章目录
- 数学建模简介
- 1. 数学建模比赛的理解
- 2. 一般数据分析的流程
- 3. 机器学习与统计数据分析
- 4. 各种编程软件仅仅是工具,对问题的观察视角和解决问题的策略才是关键
- 2.1 数学建模的特点
- 2.2 以 python(jupyter notebook工作界面)为例的工具准备
1. 数学建模比赛的理解
数学建模从字面意思上是指根据具体的任务需求和问题, 利用数学基础建立合适的数学模型, 以匹配到实际问题中. 但是这种理解对于本科生的数学建模比赛是不准确的, 我们需要正确理解数学建模比赛的4个特点:
- 建立模型涉及到模型的修改, 是一个技术性较高的工作, 本科生一般达不到此水平, 三天的时间也不可能完成.
注解: 本科生甚至研究生数学建模比赛中的数学建模更应该理解为数学套模
- 数学建模比赛的重点不在模型的套用, 而是对问题的提炼和特征的抽取(这一过程通常称为探索性数据分析)
- 数学建模比赛是开放性的, 这种开放性体现在对问题的提炼上; 数学建模没有标准答案, 在短时间内完赛是最基本的, 在此基础上才能谈出新出奇.
- 美国赛数学建模的英文翻译切不可完全照搬有道、谷歌等直译软件.
2. 一般数据分析的流程
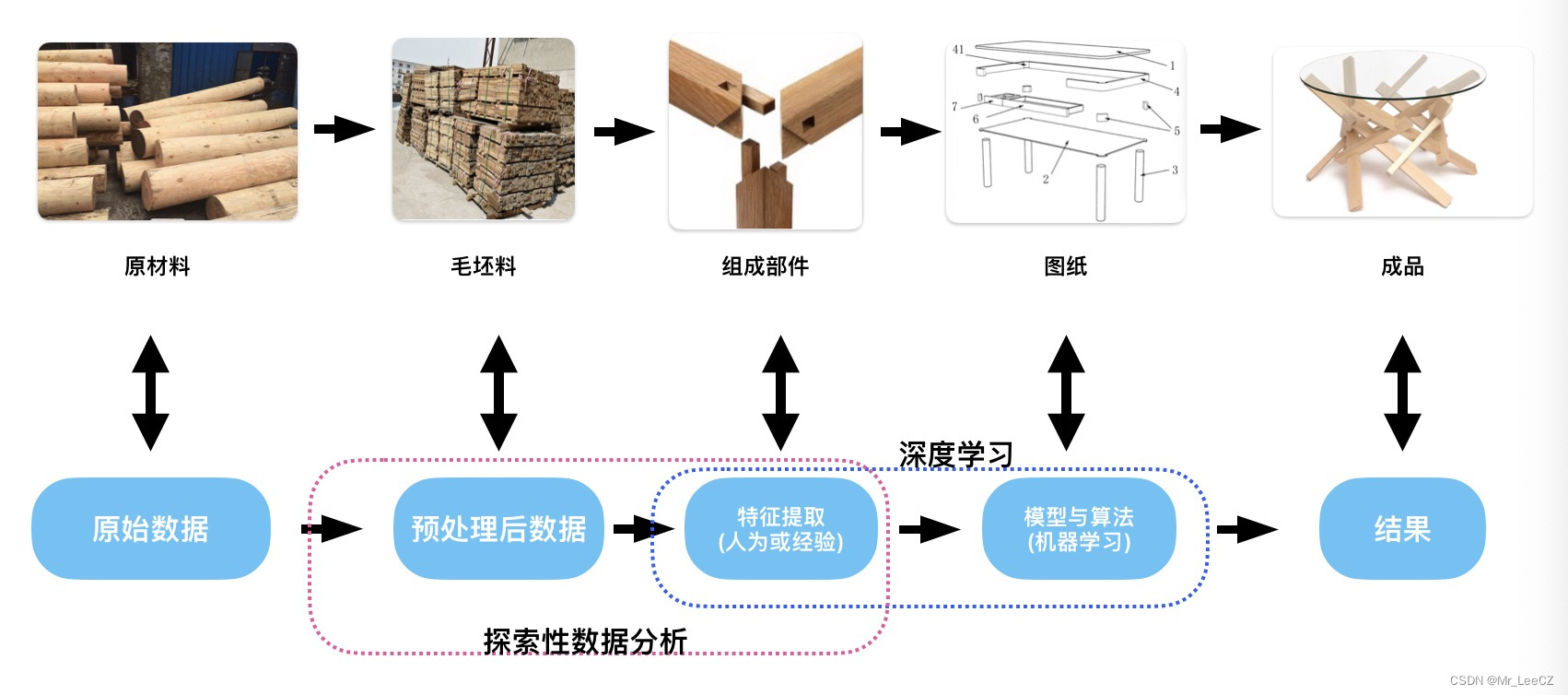
特征提取包括两种: 一种是基于相关性的传统特征提取, 又称为探索性数据分析; 另一种是用于模型效果改善的人类经验(又称为先验信息)的建模, 通常使用的是正则化模型(如龄回归、lasso回归).
机器学习与深度学习的区别
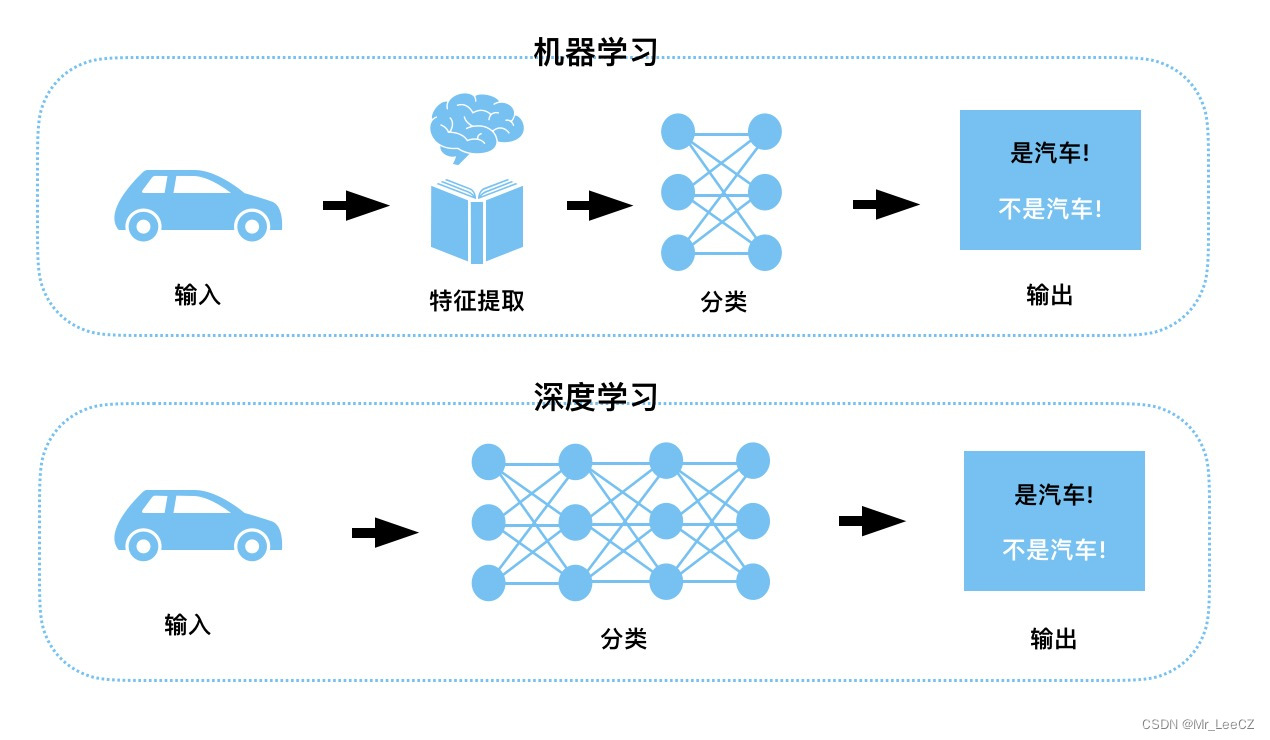
3. 机器学习与统计数据分析

机器学习的两种定义:
(1)机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
(2)机器学习是对能通过经验自动改进的计算机算法的研究。
采用一种机器学习方法,利用一个称为训练集的 N N N 个手写字体集合 { x 1 , x 1 , ⋯ , x N } \{\mathbf{x}_1,\mathbf{x}_1,\cdots,\mathbf{x}_N\} {x1,x1,⋯,xN} 来调整自适应模型的参数,可以获得更好的结果。训练集中的数字类别是预先知道的,通常是通过单独检查和手工标记它们。目标向量 t \mathbf{t} t 来表示数字的类别,目标向量 t \mathbf{t} t 表示对应数字的身份。稍后将讨论用向量表示类别的适当技术。
注解:对于每个数字图像 x \mathbf{x} x 有一个这样的目标向量 t \mathbf{t} t,如 t = ( 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 ) \mathbf{t}=(0,0,1,0,0,0,0,0,0) t=(0,0,1,0,0,0,0,0,0)表示第二类.

运行机器学习算法的结果可以表示为函数 y ( x ) \mathbf{y}(\mathbf{x}) y(x),可理解为理想函数。该函数以新的数字图像 x ^ \hat{\mathbf{x}} x^ 作为输入,并生成输出向量 y \mathbf{y} y,其编码方式与目标向量相同。函数 y ( x ) \mathbf{y}(\mathbf{x}) y(x) 的精确形式是在训练阶段(也称为学习阶段)根据训练数据确定的。一旦模型被训练,它就可以确定新的数字图像的身份,这些新的图像被称为测试集。正确分类不同于训练集的新示例的能力称为泛化。在实际应用中,输入向量的可变性使得训练数据只占所有可能输入向量的一小部分,因此泛化是模式识别的中心目标。
在大多数实际应用中,通常对原始输入变量进行预处理,将其转换成一些新的变量空间,这样,模式识别问题就更容易解决。例如,在数字识别问题中,数字的图像通常被转换和缩放,以便每个数字都包含在一个固定大小的框中。这大大减少了每个数字类内的可变性,因为所有数字的位置和比例现在都是相同的,这使得后续的模式识别算法更容易区分不同的类。这种预处理阶段有时也称为特征提取。
注解:新的测试数据必须使用与培训数据相同的步骤进行预处理。
训练数据包含输入向量及其对应目标向量的示例的应用称为有监督学习问题。例如数字识别例子,其目的是将每个输入向量分配给有限个离散类别中的一个,这种情况称为分类问题。如果所需的输出包含一个或多个连续变量,则该任务称为回归。回归问题的一个例子是预测化学生产过程中的产量,其中输入包括反应物浓度、温度和压力。
在其他模式识别问题中,训练数据由一组输入向量 x \mathbf{x} x 组成,没有任何对应的目标值。这种无监督学习问题的目标可能是在数据中发现一组类似的例子,称为聚类,或者确定数据在输入空间中的分布,称为密度估计,或将数据从高维空间投影到二维或三维,以实现可视化。
4. 各种编程软件仅仅是工具,对问题的观察视角和解决问题的策略才是关键
2.1 数学建模的特点
-
(1) 数学建模是寻找一个已有的数学模型以解决实际问题,数学建模的关键在于运用模型的过程,特别是应用过程中对细节的处理
-
(2) 数学建模更加注重对已有模型的深刻理解和模型的深度应用
-
(3) 数据分析软件是数学建模的必备工具,除此之外,R 和 python 是数据分析的两把利器
2.2 以 python(jupyter notebook工作界面)为例的工具准备
-
(1) Anaconda3的下载地址:
-
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
注意:根据自己电脑的版本进行下载,分32位和64位
-
(2) Anaconda3的安装教程:
-
https://blog.csdn.net/u012318074/article/details/77075209
-
启动 jupyter notebook:以此点击 “开始-Anacanda3-Jupyter Notebook”即可启动
-
jupyter notebook的工作路径在 C:\Users\Administrator
-
数据一般放置在当前目录下,以便于调用;用绝对路径亦可
-
(3) 常用的python库:
(1)机器学习库 sklearn:http://scikit-learn.org/stable/
(2)统计与计量模型库 statsmodels:http://www.statsmodels.org/stable/py-modindex.html