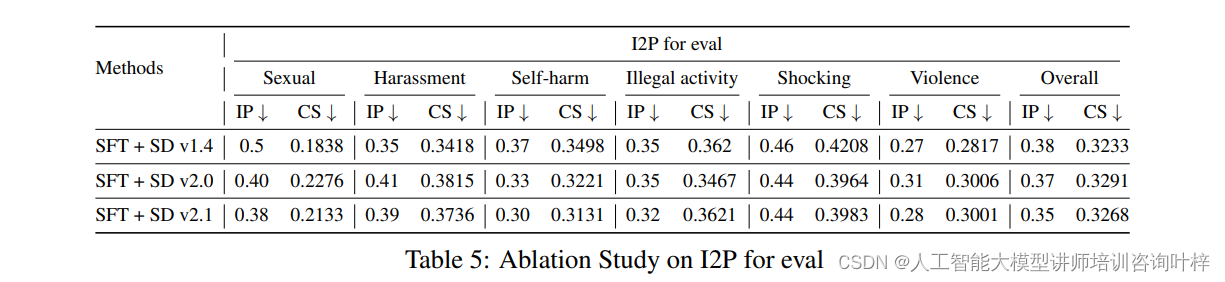
AlphaGoZero是AlphaGo算法的升级版本。不需要像训练AlphaGo那样,不需要用人类棋局这些先验知识训练,用MCTS自我博弈产生实时动态产生训练样本。用MCTS来创建训练集,然后训练nnet建模的策略网络和价值网络。就是用MCTSPlayer产生的数据来训练和指导NNPlayer。
强化学习-自博弈-CSDN博客文章浏览阅读3.1k次,点赞4次,收藏15次。强化学习自博弈相关知识_自博弈https://blog.csdn.net/feverd555/article/details/126858977AlphaZero:自我对弈下的深度强化学习突破-CSDN博客文章浏览阅读2.1k次。AlphaZero作为一种通用的深度强化学习算法,通过自我对弈的方式实现了在围棋、国际象棋和将棋等棋类游戏中的超人表现。它的成功不仅为围棋人工智能带来了突破,也为人工智能领域提供了新的研究方向和启示。未来,AlphaZero的原理和方法有望被应用于更多复杂数学和策略问题的解决。_alphazero
https://blog.csdn.net/weixin_37410657/article/details/130541632GitHub - suragnair/alpha-zero-general: A clean implementation based on AlphaZero for any game in any framework + tutorial + Othello/Gobang/TicTacToe/Connect4 and moreA clean implementation based on AlphaZero for any game in any framework + tutorial + Othello/Gobang/TicTacToe/Connect4 and more - suragnair/alpha-zero-general
![]() https://github.com/suragnair/alpha-zero-generalGitHub - opendilab/LightZero: [NeurIPS 2023 Spotlight] LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios[NeurIPS 2023 Spotlight] LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios - opendilab/LightZero
https://github.com/suragnair/alpha-zero-generalGitHub - opendilab/LightZero: [NeurIPS 2023 Spotlight] LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios[NeurIPS 2023 Spotlight] LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios - opendilab/LightZero![]() https://github.com/opendilab/LightZero/tree/main
https://github.com/opendilab/LightZero/tree/main
https://zhuanlan.zhihu.com/p/115489372![]() https://zhuanlan.zhihu.com/p/115489372https://zhuanlan.zhihu.com/p/344343854
https://zhuanlan.zhihu.com/p/115489372https://zhuanlan.zhihu.com/p/344343854![]() https://zhuanlan.zhihu.com/p/344343854
https://zhuanlan.zhihu.com/p/344343854
【深度强化学习】策略网络和价值函数网络分别是什么?_强化学习策略网络与价值网络-CSDN博客文章浏览阅读1k次,点赞22次,收藏11次。价值函数网络是一个神经网络,用于估计在给定状态或采取某个动作后能够获得的。策略网络是一个神经网络,用于建模智能体的策略,即在。_强化学习策略网络与价值网络https://blog.csdn.net/qq_40718185/article/details/135035519
最强通用棋类AI,AlphaZero强化学习算法解读|神经网络|ai|mcts_网易订阅最强通用棋类AI,AlphaZero强化学习算法解读,强化学习,算法,神经网络,ai,mcts![]() https://www.163.com/dy/article/FSRCM7K105118HA4.html AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript
https://www.163.com/dy/article/FSRCM7K105118HA4.html AlphaZero, a novel Reinforcement Learning Algorithm, in JavaScript
https://zhuanlan.zhihu.com/p/650009275![]() https://zhuanlan.zhihu.com/p/650009275
https://zhuanlan.zhihu.com/p/650009275

Coach.py input_tensor 用来向SelfPlayAgent传递当前玩家的局面状态。policy_tensor用来向SelfPlayAgent传递策略网络根据局面的策略P(S,a)。value_tensor用来向SelfPlayAgent传递价值网络对玩家局面的价值Q(S,a)。

SelfPlayAgent的MCTS模拟过程

SelfPlayAgent generateBatch mtcs find_leaf 选择或者扩展叶子节点

SelfPlayAgent proessBatch 等待Coach的processSelfPlayBatches的P、Q计算好后的batch_ready信号开始在中mcts进行process_result,process_result在路径上进行反向传播,更新节点的n和v。

SelfPlayAgent走棋


SelfPlayAgent输出局面、策略和局面结果到output_queue,作为训练集