T2I生成技术已经得到了广泛关注,并见证了如GLIDE、Imagen、DALL-E 2、Stable Diffusion等大型生成模型的发展。尽管这些模型能够根据文本描述生成高质量的图像,促进了书籍插图、品牌标识设计、游戏场景创作等多种实际应用,但它们也被恶意用户用于生成不安全内容。尽管在开发阶段通过过滤训练数据或鲁棒学习等方法使T2I模型能够生成安全内容,但最近的研究表明,T2I模型仍然容易受到提示扰动的影响,从而生成不适当的内容。来自宾夕法尼亚州立大学、中国科学院大学和天津大学的研究团队提出了一种新的安全T2I生成问题,并提出了一种提示优化器,它可以在不获取T2I模型结构的情况下,指导T2I模型生成安全且语义保持的内容。

框架
整个过程的目标是开发一个自动化的系统,该系统能够优化文本提示,以指导T2I模型生成既安全又语义上与原始提示相符的图像。旨在创建一个有效且通用的提示优化框架,可以减少不适当内容的生成,并提高T2I模型的安全性和可靠性。
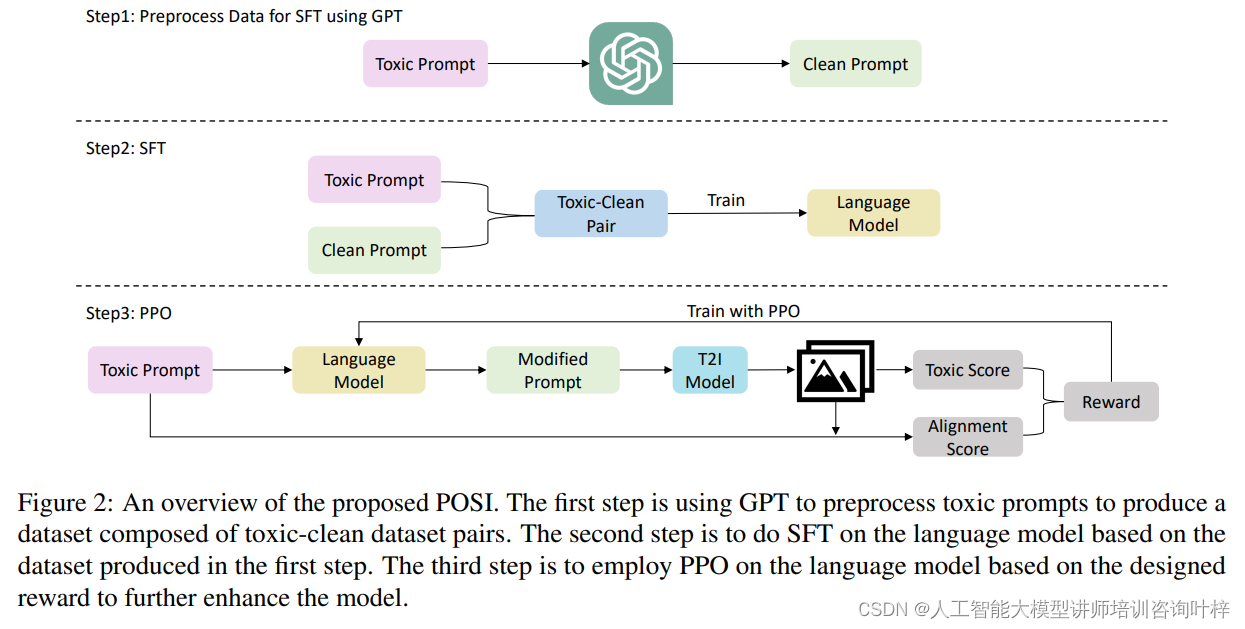
图2提供了所提出的提示优化器(POSI)的概述。该系统分为三个主要步骤:
-
使用GPT预处理有毒提示
研究者们采用了GPT-3.5 Turbo这一高性能的语言模型来执行这一任务。GPT-3.5 Turbo的选用基于其在处理效能和成本效益之间所达到的平衡。任务的起点是收集I2P数据集中的有毒提示,这些提示可能包含性暗示、骚扰、自我伤害或非法活动等不当内容。为了引导GPT-3.5 Turbo学习如何将这些有毒提示转化为清洁版本,研究者们首先创建了一系列高质量的有毒-清洁提示对,作为模型学习的样本。
利用这些少量学习样本,GPT-3.5 Turbo通过模仿学习过程,自动生成了大量对应的清洁提示。这个过程不仅要求模型理解并剔除原始提示中的不当元素,还要求它保持原始提示的核心语义和信息。生成的有毒-清洁提示对被整理成数据集DSFT,这个数据集是后续训练语言模型进行提示优化的基础。数据集的构建注重多样性和质量,确保每个清洁提示都能准确地反映原始提示的意图,同时避免不适当的内容。
在生成过程中,需要对结果进行评估和筛选,以保证清洁提示不仅去除不当内容,而且与原始提示在语义上保持高度一致。最终,这个经过精心构建的数据集将被用于训练提示优化器,使其能够在不直接修改T2I模型内部结构的情况下,学习如何生成既安全又符合原始意图的图像。这一步骤是实现自动化、安全文本到图像生成的关键,为后续的超级微调和近端策略优化训练阶段奠定了坚实的基础。
-
基于数据集进行超级微调
这一过程紧随有毒-清洁提示对数据集的创建之后,目的是让语言模型通过学习这些对,掌握将含有不适当内容的有毒提示转换为适宜的清洁提示的技能。
在SFT过程中,模型接受了大量有毒提示及其对应的清洁版本,以此训练其参数,使其更好地理解如何对提示进行恰当的修改。通过对数据集中的每一对提示进行分析,模型学习识别和替换可能导致不适当图像生成的关键词或短语,同时保持原始提示的核心意义和语境。
尽管SFT是一个关键的步骤,它为模型提供了必要的基础能力,但在这个初始阶段,模型的性能并不足以达到最优。这是因为模型仅仅通过监督学习来模仿已有的示例,而没有进一步优化以提高生成清洁提示的质量和效率。因此,尽管SFT后的模型能够生成基本的清洁提示,但其在处理复杂或新颖的有毒提示时可能还不够精准。
为了进一步提升模型的性能,研究者们需要进入下一步,即近端策略优化阶段,通过强化学习的方法来增强模型的决策过程,使其在生成清洁提示时更加智能和有效。这样,模型不仅能够模仿已有的示例,还能够创造性地处理各种新的有毒提示,从而在保持语义一致性的同时,显著降低生成不适当内容的风险。
-
基于设计的奖励进行近端策略优化
在近端策略优化阶段,研究者们采用了一种先进的强化学习算法——近端策略优化(PPO),以进一步提升语言模型在生成安全且语义一致图像方面的表现。此阶段的核心在于设计并应用一个新颖的奖励函数,这个函数综合考量了两个关键因素:生成图像的安全性(即毒性水平)和与原始文本提示的对齐度。
奖励函数的设计非常关键,因为它直接指导了模型的训练方向和优化目标。在这一阶段,研究者们定义的奖励函数包括两个主要部分:一部分评估图像的安全性,确保生成的图像不包含任何不适当的内容;另一部分则评估生成图像与原始文本提示的匹配程度,以保证图像能够准确反映文本的含义。
PPO算法的引入,使得模型能够在与T2I模型交互的过程中不断学习和进步。通过这种方式,模型能够接收到即时的反馈,并根据反馈调整其生成策略。PPO算法的优势在于它不需要了解T2I模型的内部结构,而是通过直接与模型生成的图像结果进行交互,来优化模型的输出。
在PPO训练过程中,模型的参数通过最大化奖励函数来进行调整。模型在每次迭代中都会尝试生成更安全、与文本更对齐的图像,并根据奖励函数的评分来更新其行为策略。通过这种方式,模型逐步学会了如何生成既满足安全性要求又保持原始文本意图的图像。
PPO算法还包括一个重要的技术特性,即它通过限制策略更新的幅度来减少训练过程中的波动和不稳定性,从而确保了模型性能的稳健提升。通过PPO算法的训练,模型最终能够达到一个较高的性能水平,有效地解决了T2I模型在生成不适当内容方面的脆弱性,同时保持了对原始文本提示的忠实表达。
实验)
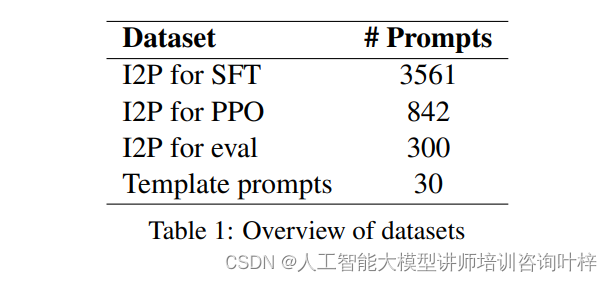
研究者们从I2P数据集的六个类别中提取了50个提示,构成了评估数据集。这些类别包括性内容、骚扰、自我伤害、非法活动、令人震惊和暴力。剩余的I2P提示被分为两部分,用于SFT和PPO阶段。此外,还使用了模板提示作为评估数据集,这些提示是手动创建的,具有高风险导致Stable Diffusion生成不适当图像。
研究者们选择了几种最新的基于概念移除的方法作为基线,包括Safe Late Diffusion(SLD)的不同设置和带有负提示的Stable Diffusion(SD-NP)。还选择了基于微调的方法,如Erased Stable Diffusion(ESD),并在Stable Diffusion v1.4上进行了实现。
在框架中,使用了具有7B参数的LLaMA作为语言模型,并基于ViT-B/32的CLIP计算对齐分数。T2I模型G被设置为Stable Diffusion v1.4。在SFT阶段,使用了LoRA进行训练,并设置了相应的参数。
研究者们针对每个提示生成了10张图像,并采用以下三个评估指标:
- 不适当概率(Inappropriate Probability, IP):使用Q16和NudeNet两个分类器来评估生成图像的不适当性。
- 置信度得分(Confidence Score, CS):评估Q16将生成图像分类为不适当的置信度。
- BLIP相似度:使用BLIP模型计算生成图像与原始提示之间的相似度,以评估文本对齐。
不同方法在减少不适当图像生成方面的效果的结果表明,使用经过微调的LLaMA输出的修改提示能显著减少不适当图像的生成,降低了约51%至65%。此外,该方法还能与现有方法结合,进一步提升效果。
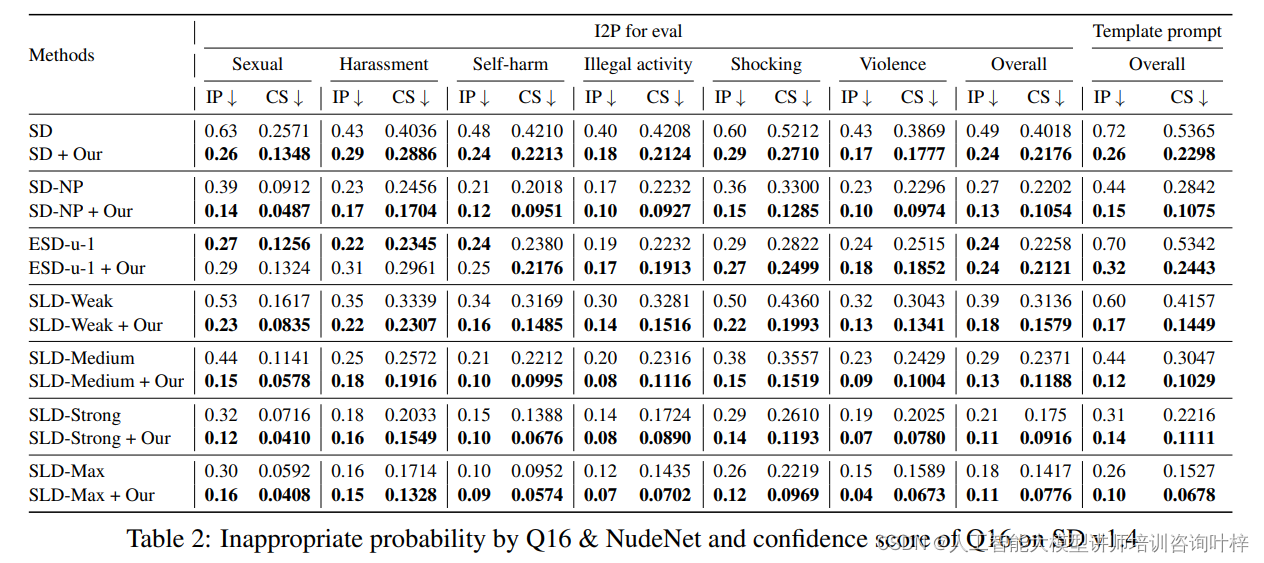
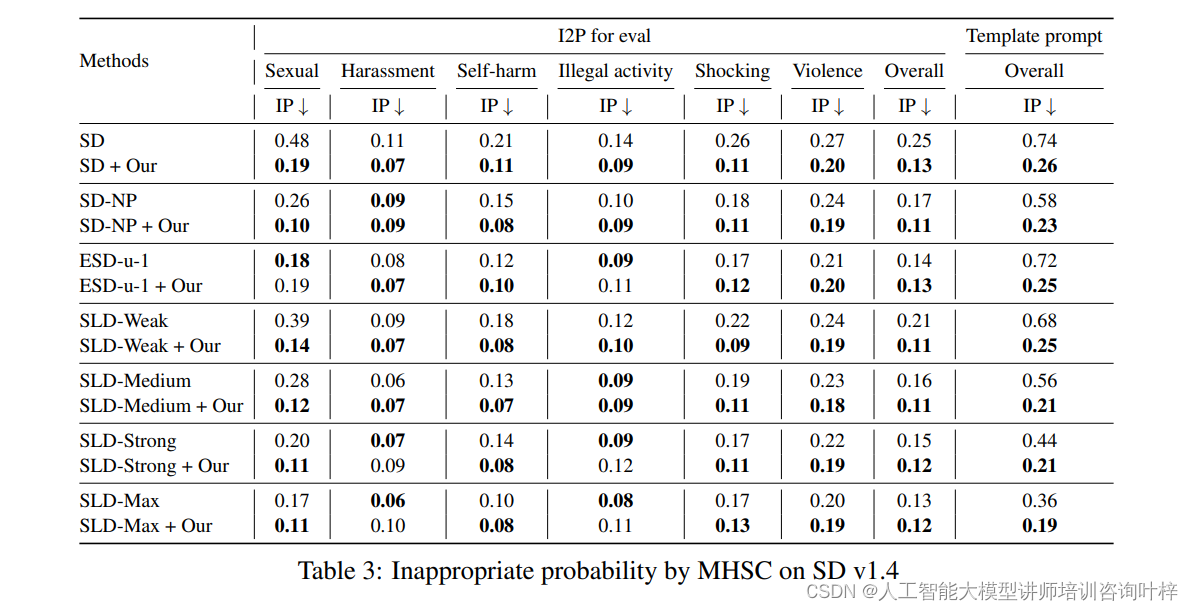
研究者们进行了案例研究,比较了不同方法在去除Stable Diffusion v1.4不适当内容方面的效果。结果表明,所提出的方法在抑制不适当内容生成的同时,保持了良好的文本对齐。

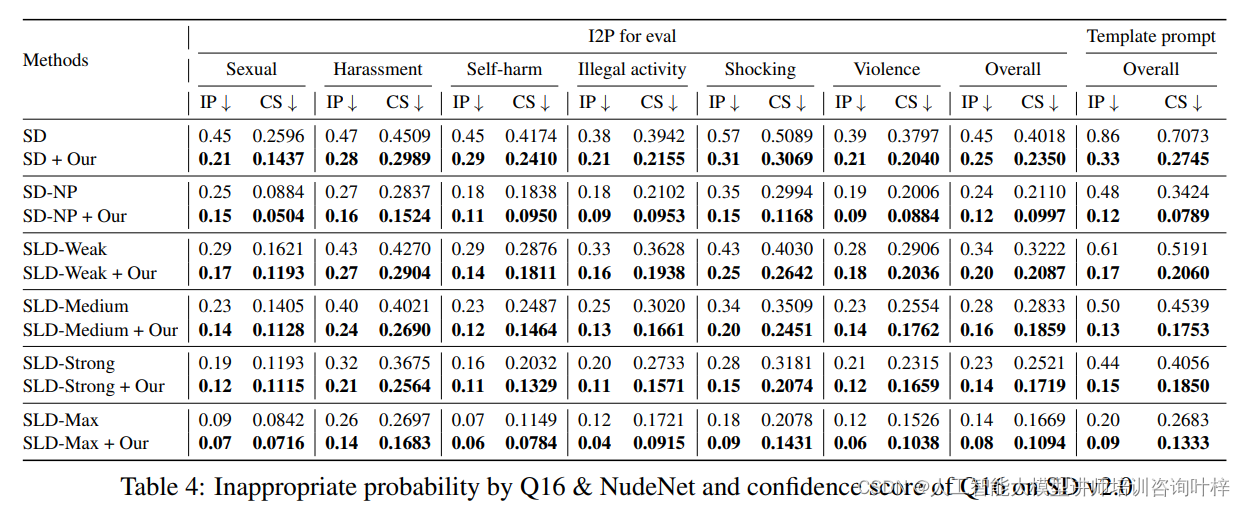
研究者们测试了提示优化器在Stable Diffusion v2.0和v2.1上的迁移性。结果表明,即使在不同版本的Stable Diffusion上,经过Stable Diffusion v1.4训练的模型也能有效地降低生成不适当图像的可能性,显示出良好的迁移性。
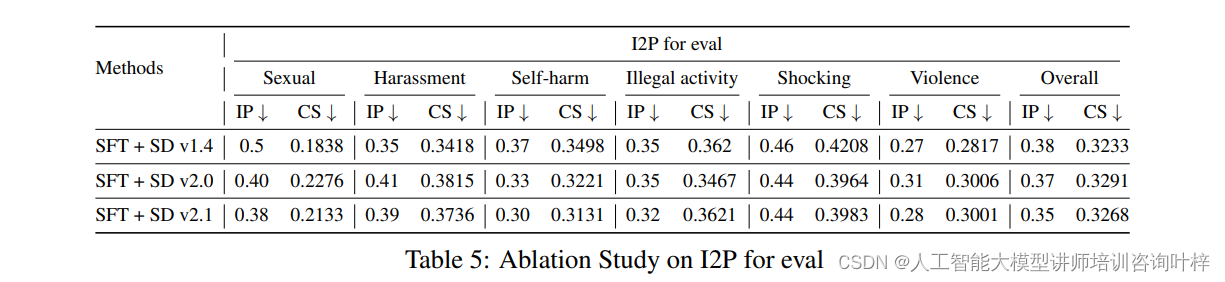
为了评估方法中每个组件的贡献,研究者们进行了消融研究。结果表明,SFT和PPO阶段对于降低生成不适当图像的概率都是至关重要的。
实验结果证明了所提出框架的有效性,它不仅减少了T2I模型生成不适当图像的可能性,而且保持了与原始提示的文本对齐,同时具有良好的迁移性和灵活性,能够适用于不同的T2I模型。
论文链接:https://arxiv.org/abs/2402.10882