Elasticsearch 简介
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。Elasticsearch 建立在全文搜索引擎 Apache Lucene™ 基础上,通过 Lucene 的倒排索引技术实现比关系型数据库更快的过滤,从而很方便的使大量数据具有搜索、分析和探索的能力。
毫无疑问,Elasticsearch的底层核心是倒排索引。 Elasticsearch通过扩展服务器集群的方式,将数据以文档的形式,FST压缩的方式,分布式实时存储;同时为文件每一个字段添加倒排索引,通过倒排索引以及skip list 和 bitset 三种数据结构实现实时分布式分析和快速搜索的功能。
Elasticsearch 数据存储
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条学生数据:
{
"stuName":"Rose",
"age":18,
"gender":"Male",
"resume":"I am gooding at studying",
"tuition":26800.00,
"hobbies":["sleep","games"],
"address":{
"province":"JiangSu",
"city":"NanJing",
"district":"YuHua"
}
}如果用传统的关系型数据库比如说mysql来存储上述这条数据时,我们能够想到的是去建立一张student表,表中有stuName,age,tuition,hobbies,address字段等,而在Elasticsearch里这就是一个记录student类型的文档,所有的字段类型都存在于这个文档的索引里。这里有一份简易的将Elasticsearch和关系型数据术语对照表:

Elasticsearch和传统的数据库一样,索引、类型、文档、字段都是一对多的关系。Elasticsearch数据交互可以通过HTTP的Restful请求方式直接请求,也可以通过java API请求。值得注意的是,Elasticsearch主要用来查询,因为其每一个字段都有倒排索引这种需要大量的储存空间,我刚开始接触Elasticsearch的事实增删改,如果不实用shell脚本的话,要一条一条的执行,增删改的效率很低,不如传统的数据库。事实上,现在市场的主流就是Elasticsearch与传统数据库公用,Elasticsearch用来查询,传统的用来增删改,Elasticsearch连接数据库和客户端搜索引擎的桥梁。
倒排索引
Elasticsearch倒排索引的精髓:
倒排索引压缩储存空间,减少磁盘读取次数;严格储存结构,节省搜索时间。
简单的来说,Elasticsearch将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用极其苛刻的态度使用内存。
Elasticsearch能够通过倒排索引来达到实时、高效的搜索是怎么实现的呢?下面我从时间和空间的概念来谈谈倒排索引的原理。
倒排索引的空间结构是什么样的?
首先根据上述例子拿出stuName,age,gender字段的来说:
student类型的文档上层school对应着一个索引的index为1:
PUT http://192.168.1.1:9200/school
student类型的文档对应着一个index:
| ID | stuName| age| gender |
| -- |--------|----| -------|
| 1 | Rose | 24 | Male |
| 2 | John | 24 | Female |
| 3 | Bill | 29 | Female |stuName:
| stuName| Posting List|
|--------|-------------|
| Rose | 1 |
| John | 2 |
| Bill | 3 | age:
| Term | Posting List |
| ---- |------------- |
| 24 | [1,2] |
| 29 | 3 |gender:
| Term | Posting List |
| ------ |--------------|
| Female | 1 |
| Male | [2,3] |如上所述,student所在的school索引index,student每个文档dictionary,student的每个字段Posting List都建立了索引。用一张图表示如下:

Posting List
Posting List是Elasticsearch中为每个字段field自动提供的索引集合,比方说24,29 这些叫做 term,而 [1,2] 就是 posting list。Posting list 就是一个 int 的数组,存储了所有符合某个 term 的文档 id。
Term Dictionary
Elasticsearch中为了能够快速的找到某个term,也就是我们经常用某个字段来快速查询,为了实现这一功能,Term Dictionary就产生了。Term Dictionary的实现底层就是B+Tree,使用二分法进行查询term, logN 次磁盘查找效率,就像字典查询一样,首字母是什么,就先检索什么,然后再看第二个字母是什么,检索第二个字母,…,一直到检索到这个term为止。
Term Index
由于磁盘随机读的存在,就必须将一部分数据存在缓存内存中,但是Term Dictionary磁盘存储空间的巨大,又不能将Term Dictionary完整的放到内存里。因此就有了Term Index,它就像字典里一个更大的章节一样,每个大的章节再对应着多个小的章节Term Dictionary,这样就能实现速的找到某个term。
Term Index、Term Dictionary和Posting List个关系
如下图 所示:“A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 这些单词是如何储存在Elasticsearch里的呢?Term Index就像一棵倒挂的树一样,它就是这棵树的根节点,也就是这本字典;Term Dicitionary是根节点的子节点,存放着“t”、“A”、“i”,也就是所储存单词的前缀;然后Posting List就是相同前缀的单词(term)集合,里面装着我们要检索的单词(term)。因此通过 term index能够快速精确的检索到我们所需要的term

如下图所示,关系型数据库如Mysql 只有 term dictionary 这一层,是以 b-tree 排序的方式存储在磁盘上的。检索一个 term 需要若干次的 random access 的磁盘操作。而 Elasticsearch 在 term dictionary 的基础上添加了 term index 来加速检索,term index 以树的形式缓存在内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的 random access 次数。

倒排索引的时间概念是怎么节省的?
B-Tree+整体分区快速查找
上面说到Elasticsearch中的 term dictionary不同于关系型数据库的term dicitionary的结构B-Tree那样,将所存储的数据按照某种规则进行排序储存于磁盘里,然后通过二分法去查找某个term,这样能够达到log N的查询效率;而Elasticsearch中先把 term dictionary分为相同大小的块,然后递归去把每个块分成相同大小的块,进行快速查找。
举个例子,对于1-16这组数据进行快速查找其中的某个值:
B-Tree二分法:
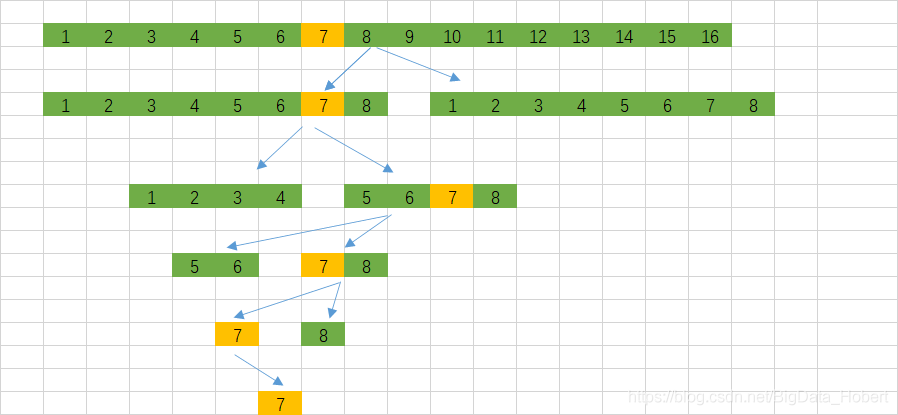
如图所示B-Tree二分法查找7这个数,需要4次方能查出来。同样的查找1和16也需要4次才能查找出来。
B-Tree+整体分区法:
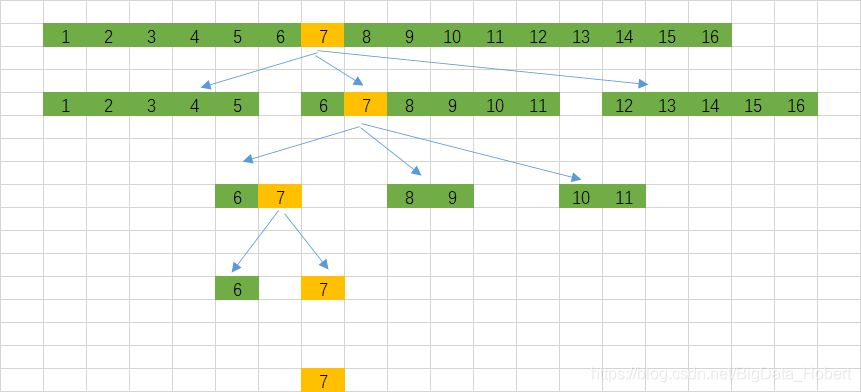
如图所示B-Tree+整体分区法查找7的时候,只需3次就能找到,相当于“三分法”一样比二分法更加的有效率,但是如果数据每次“三分”时都处于中间,那就无形的增加了判断次数(这种做法,拿要检索的值7和中间块的两头6和11比较),但是这只是极少的数据而已,在海量的数据面前,这数据更是微不足道,所以根据二八定律,它基本上能满足搜索更快的需求。这种是将块或者区域作为一个整体的思想来实现快速搜索,有一点像希尔排序一样,虽然检索效率不稳定,但是能够解决大部分的数据效率问题,就等于实现了整个数据的效率问题。
更为重要的是,Elasticsearch中不仅term dictionary实现了倒排索引,而且term index也采用了这种倒排索引,这就相当于又套了一层B-Tree+整体分区法,效率提高了一个档次。




![[HCTF 2018]WarmUp1](https://img-blog.csdnimg.cn/b4aee452861e4a79bfee4404cd7c79b6.png)