基于sklearn-crfsuite进行命名实体识别
- 0. 条件随机场
- 1. 训练数据
- 2. 特征提取
- 3. 训练一个CRF模型
- 4. 评估
- 5. 超参数优化
- 6. 检查参数空间
- 7. 检查在测试数据上的最优估计器
- 8.检查分类器学到了什么东西
- 9.检查模型权重
- 10. 定制化
- 11.在控制台中进行格式化
- 参考资料
本文中,针对
CoNLL2002数据训练了一个用于
命名实体识别的基本
CRF模型,并检查其权重以查看该模型学到了什么。需要
NLTK>3.x和
sklearn-crfsuite Python包。本文使用
Python 3。
0. 条件随机场
**条件随机场:**条件随机场这个模型属于概率图模型中的无向图模型,这里我们不做展开,只直观解释下该模型背后考量的思想。一个经典的链式 CRF 如下图所示:
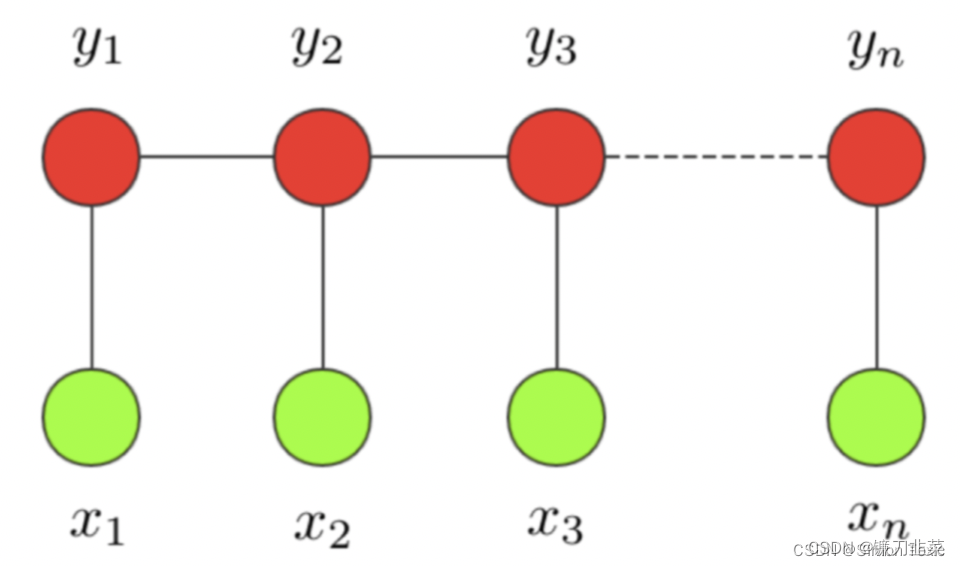
CRF 本质是一个无向图,其中绿色点表示输入,红色点表示输出。点与点之间的边可以分成两类:
- 一类是 x 与 y 之间的连线,表示其相关性;
- 另一类是相邻时刻的 y之间的相关性。
也就是说,在预测某时刻 y时,同时要考虑相邻的标签解决。当 CRF 模型收敛时,就会学到类似 P-B 和 T-I 作为相邻标签的概率非常低。
对于 CRF,我们给出准确的数学语言描述:设 X 与 Y 是随机变量,P(Y|X) 是给定 X 时 Y 的条件概率分布,若随机变量 Y 构成的是一个马尔科夫随机场,则称条件概率分布 P(Y|X) 是条件随机场。
1. 训练数据
首先导入依赖库
import nltk
import eli5
import sklearn
import sklearn_crfsuite
import scipy.stats
from itertools import chain
from sklearn.metrics import make_scorer
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RandomizedSearchCV
from sklearn_crfsuite import scorers
from sklearn_crfsuite import metrics
CoNLL2002数据集包含西班牙语句子列表,并带有注释的命名实体。 它使用IOB2编码。 CoNLL 2002 数据还提供词性标记。
import nltk
nltk.download('conll2002')
'''
[nltk_data] Downloading package conll2002 to /root/nltk_data...
[nltk_data] Package conll2002 is already up-to-date!
True
'''
nltk.corpus.conll2002.fileids()
'''
['esp.testa', 'esp.testb', 'esp.train', 'ned.testa', 'ned.testb', 'ned.train']
'''
train_sents = list(nltk.corpus.conll2002.iob_sents('esp.train'))
test_sents = list(nltk.corpus.conll2002.iob_sents('esp.testb'))
train_sents[0]
'''
[('Melbourne', 'NP', 'B-LOC'),
('(', 'Fpa', 'O'),
('Australia', 'NP', 'B-LOC'),
(')', 'Fpt', 'O'),
(',', 'Fc', 'O'),
('25', 'Z', 'O'),
('may', 'NC', 'O'),
('(', 'Fpa', 'O'),
('EFE', 'NC', 'B-ORG'),
(')', 'Fpt', 'O'),
('.', 'Fp', 'O')]
'''
2. 特征提取
接下来,定义一些特征。 POS标签可以看作是预先提取的特征。 这里提取更多特征(word parts、简化的POS标签、lower/title/upper标记、临近单词的特征)并将它们转换为 sklear-crfsuite 格式——每个句子都应转换为字典列表。 这是一个非常简单的基线任务; 当然也可以做得更好。
sklearn-crfsuite(和python-crfsuite)支持多种特征格式; 这里我们使用feature dicts。
def word2features(sent, i):
word = sent[i][0]
postag = sent[i][1]
features = {
'bias': 1.0,
'word.lower()': word.lower(),
'word[-3:]': word[-3:],
'word.isupper()': word.isupper(),
'word.istitle()': word.istitle(),
'word.isdigit()': word.isdigit(),
'postag': postag,
'postag[:2]': postag[:2],
}
if i > 0:
word1 = sent[i-1][0]
postag1 = sent[i-1][1]
features.update({
'-1:word.lower()': word1.lower(),
'-1:word.istitle()': word1.istitle(),
'-1:word.isupper()': word1.isupper(),
'-1:postag': postag1,
'-1:postag[:2]': postag1[:2],
})
else:
features['BOS'] = True
if i < len(sent)-1:
word1 = sent[i+1][0]
postag1 = sent[i+1][1]
features.update({
'+1:word.lower()': word1.lower(),
'+1:word.istitle()': word1.istitle(),
'+1:word.isupper()': word1.isupper(),
'+1:postag': postag1,
'+1:postag[:2]': postag1[:2],
})
else:
features['EOS'] = True
return features
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
return [label for token, postag, label in sent]
def sent2tokens(sent):
return [token for token, postag, label in sent]
X_train = [sent2features(s) for s in train_sents]
y_train = [sent2labels(s) for s in train_sents]
X_test = [sent2features(s) for s in test_sents]
y_test = [sent2labels(s) for s in test_sents]
从单个标记中提取的特性如下:
X_train[0][1]
{'bias': 1.0,
'word.lower()': '(',
'word[-3:]': '(',
'word.isupper()': False,
'word.istitle()': False,
'word.isdigit()': False,
'postag': 'Fpa',
'postag[:2]': 'Fp',
'-1:word.lower()': 'melbourne',
'-1:word.istitle()': True,
'-1:word.isupper()': False,
'-1:postag': 'NP',
'-1:postag[:2]': 'NP',
'+1:word.lower()': 'australia',
'+1:word.istitle()': True,
'+1:word.isupper()': False,
'+1:postag': 'NP',
'+1:postag[:2]': 'NP'}
3. 训练一个CRF模型
一旦拥有正确格式的特征,就可以使用sklearn_crfsuite.CRF训练一个linear-chain CRF(条件随机场)模型:
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=20,
all_possible_transitions=False,
)
crf.fit(X_train, y_train);
4. 评估
数据集中有更多的 O 实体,但我们对其他实体更感兴趣。 为了解决这个问题,将为除O之外的所有标签计算的平均F1分数。sklearn-crfsuite.metrics 包为序列分类任务提供了一些有用的指标,包括这个。
labels = list(crf.classes_)
labels.remove('O')
labels
'''
['B-LOC', 'B-ORG', 'B-PER', 'I-PER', 'B-MISC', 'I-ORG', 'I-LOC', 'I-MISC']
'''
y_pred = crf.predict(X_test)
metrics.flat_f1_score(y_test, y_pred, average='weighted', labels=labels)
'''
0.76980231377134023
'''
更详细地检查每个类的结果:
# group B and I results
sorted_labels = sorted(labels, key=lambda name: (name[1:], name[0]))
sorted_labels
print(metrics.flat_classification_report(y_test, y_pred, labels=sorted_labels, digits=3))
报错:

5. 超参数优化
为了提高质量,尝试使用随机搜索和 3 折交叉验证来选择正则化参数。
# define fixed parameters and parameters to search
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
max_iterations=100,
all_possible_transitions=True
)
params_space = {
'c1': scipy.stats.expon(scale=0.5),
'c2': scipy.stats.expon(scale=0.05),
}
# use the same metric for evaluation
f1_scorer = make_scorer(metrics.flat_f1_score,
average='weighted', labels=labels)
# search
rs = RandomizedSearchCV(crf, params_space,
cv=3,
verbose=1,
n_jobs=-1,
n_iter=50,
scoring=f1_scorer)
rs.fit(X_train, y_train)
报错:AttributeError: ‘CRF’ object has no attribute ‘keep_tempfiles’

pip install -U 'scikit-learn<0.24'
打印最优结果:
# crf = rs.best_estimator_
print('best params:', rs.best_params_)
print('best CV score:', rs.best_score_)
print('model size: {:0.2f}M'.format(rs.best_estimator_.size_ / 1000000))
6. 检查参数空间
显示哪些 c1 和 c2 值已检查 RandomizedSearchCV 的图表。 红色意味着更好的结果,蓝色意味着更差。
_x = [s.parameters['c1'] for s in rs.grid_scores_]
_y = [s.parameters['c2'] for s in rs.grid_scores_]
_c = [s.mean_validation_score for s in rs.grid_scores_]
fig = plt.figure()
fig.set_size_inches(12, 12)
ax = plt.gca()
ax.set_yscale('log')
ax.set_xscale('log')
ax.set_xlabel('C1')
ax.set_ylabel('C2')
ax.set_title("Randomized Hyperparameter Search CV Results (min={:0.3}, max={:0.3})".format(
min(_c), max(_c)
))
ax.scatter(_x, _y, c=_c, s=60, alpha=0.9, edgecolors=[0,0,0])
print("Dark blue => {:0.4}, dark red => {:0.4}".format(min(_c), max(_c)))
7. 检查在测试数据上的最优估计器
crf = rs.best_estimator_
y_pred = crf.predict(X_test)
print(metrics.flat_classification_report(
y_test, y_pred, labels=sorted_labels, digits=3
))
8.检查分类器学到了什么东西
from collections import Counter
def print_transitions(trans_features):
for (label_from, label_to), weight in trans_features:
print("%-6s -> %-7s %0.6f" % (label_from, label_to, weight))
print("Top likely transitions:")
print_transitions(Counter(crf.transition_features_).most_common(20))
print("\nTop unlikely transitions:")
print_transitions(Counter(crf.transition_features_).most_common()[-20:])
可以看到,例如,组织名称 (B-ORG) 的开头很可能后面跟着组织名称内部的标记 (I-ORG),但是从带有其他标签的令牌到 I-ORG 的转换会受到惩罚。
检查状态特征:
def print_state_features(state_features):
for (attr, label), weight in state_features:
print("%0.6f %-8s %s" % (weight, label, attr))
print("Top positive:")
print_state_features(Counter(crf.state_features_).most_common(30))
print("\nTop negative:")
print_state_features(Counter(crf.state_features_).most_common()[-30:])
一些观察结果:
- 9.385823 B-ORG word.lower():psoe-progresistas——模型记住了一些实体的名字——可能是过度拟合,或者我们的特征不充分,或者记忆确实有帮助;
- 4.636151 I-LOC -1:word.lower():calle:“calle”是西班牙语中的一条街道; 模型了解到,如果前一个单词是“calle”,那么该标记可能是位置的一部分;
- -5.632036 O word.isupper(), -8.215073 O word.istitle() :UPPERCASED 或 TitleCased 单词可能是某种实体;
- -2.097561 O postag:NP ——专有名词(NP 是西班牙语标记集中的专有名词)通常是实体。
9.检查模型权重
CRFsuite CRF 模型使用两种特征:state features和transition features。 使用eli5.explain_weights 检查它们的权重:
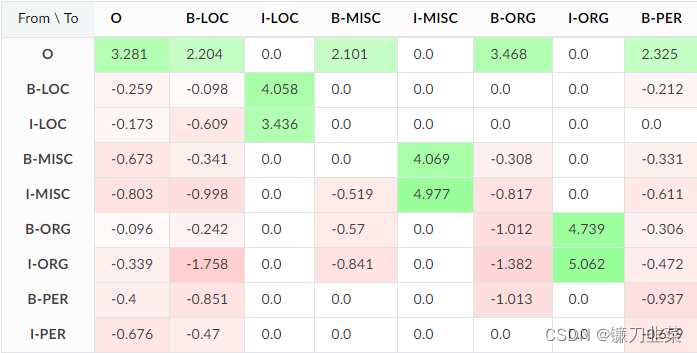
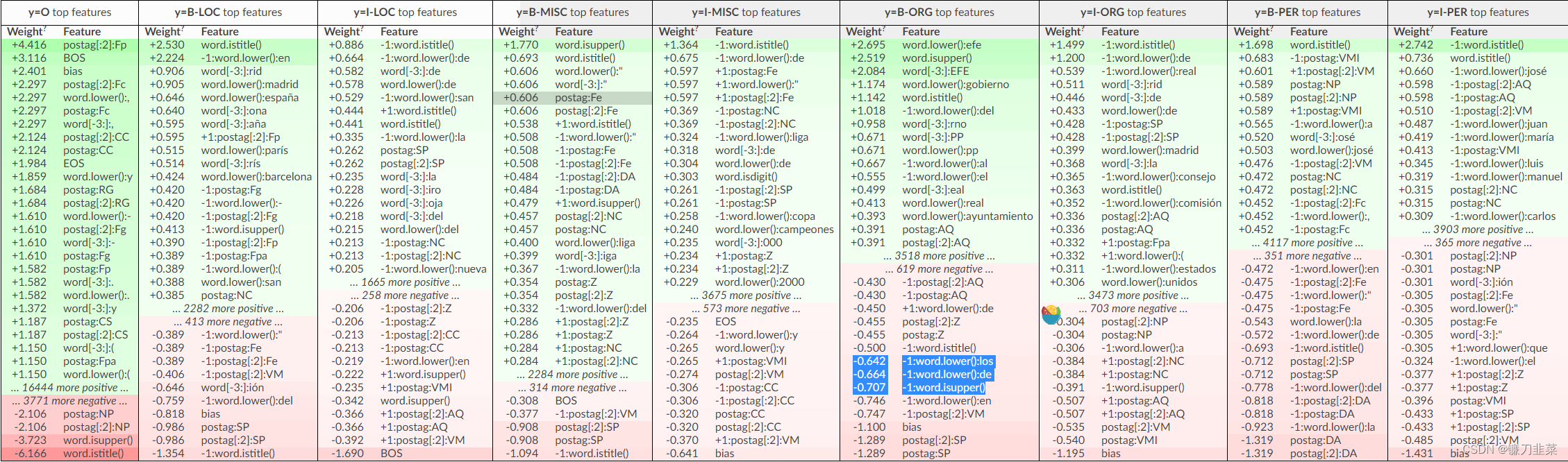
Transition features是有道理的:至少模型知道 I-ENITITY 必须遵循 B-ENTITY。 它还了解到某些转换不太可能发生,例如 在这个数据集中,在组织名称之后有一个位置并不常见(I-ORG -> B-LOC 具有很大的负权重)。
特征不使用地名词典,因此模型必须记住训练数据中的一些地理名称,例如 España 是一个位置。
如果对 CRF 进行更多的正则化,可以预期只有通用的特征会保留下来,而记忆化的标记将会消失。 使用 L1 正则化(c1 参数),大多数特征的系数应该被驱动为零。 检查一下正则化对 CRF 权重有什么影响:
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
c1=200,
c2=0.1,
max_iterations=20,
all_possible_transitions=False,
)
crf.fit(X_train, y_train)
eli5.show_weights(crf, top=30)
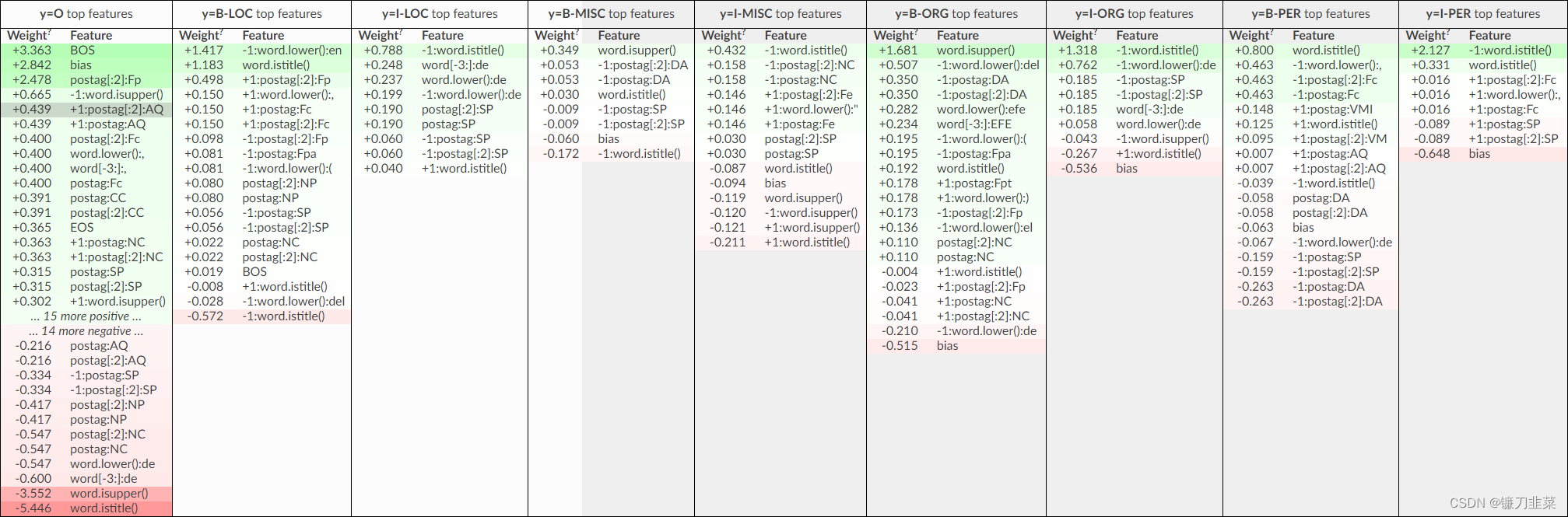
正如所看到的,记忆标记大部分都消失了,模型现在依赖于字形和 POS 标签。 只剩下几个非零特征。 在示例中,更改可能会使质量变差,但这是一个单独的问题。
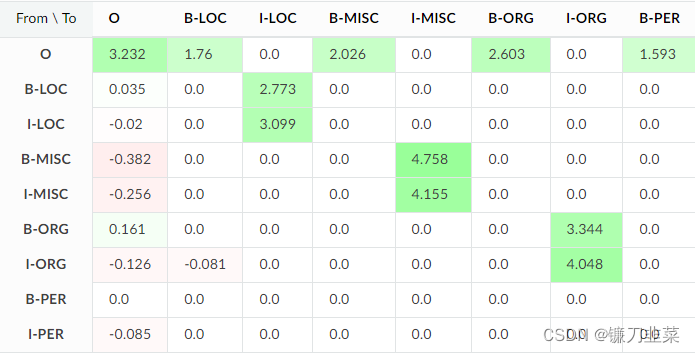
现在,关注transition weights。 可以预期 O -> I-ENTIRY 转换具有较大的负权重,因为它们是不可能的。 但是这些转换在高度正则化模型和初始模型中都具有零权重,而不是负权重。 这里发生了一些事情。
它们为零的原因是 crfsuite 没有在训练数据中看到这些转换,并假设没有必要为它们学习权重,以节省一些计算时间。 这是默认行为,但可以使用 sklearn_crfsuite.CRF all_possible_transitions 选项将其关闭。 检查一下它如何影响结果:
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=20,
all_possible_transitions=True,
)
crf.fit(X_train, y_train);
eli5.show_weights(crf, top=5, show=['transition_features'])
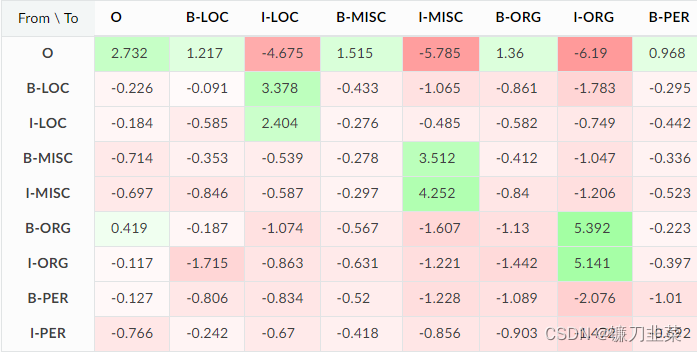
对于all_possible_transitions=True,CRF 为不可能的转换学习了大的负权重,比如 O -> I-ORG。
10. 定制化
上面的表格很大,有点难以检查; eli5提供了几个选项来只查看一部分功能。 只能检查一部分标签:
eli5.show_weights(crf, top=10, targets=['O', 'B-ORG', 'I-ORG'])
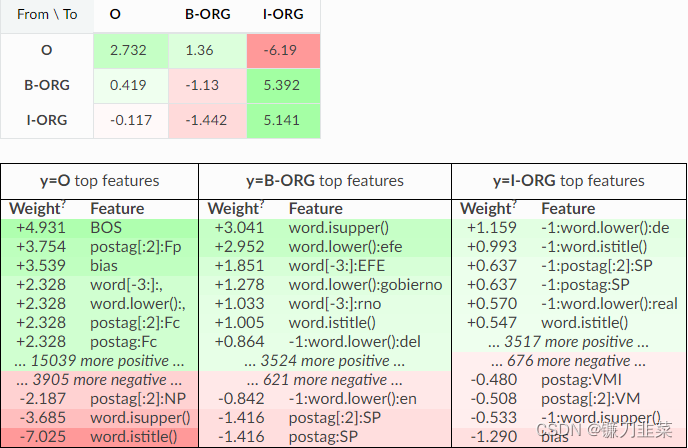
另一种选择是仅检查部分功能——它有助于检查功能是否按预期工作。 例如,使用feature_re参数和隐藏转换表来检查模型如何使用词形特征:
eli5.show_weights(crf, top=5, feature_re='^word\.is', horizontal_layout=False, show=['targets'])
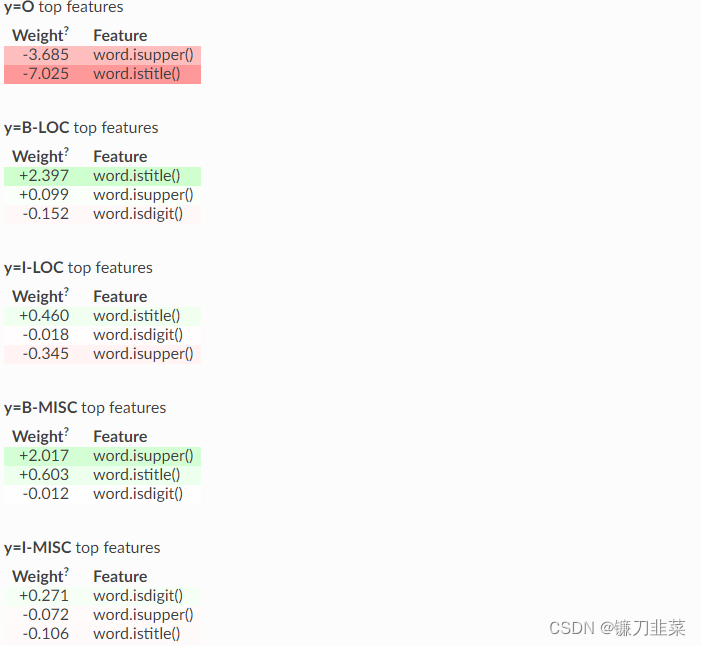
看起来不错——大写和标题大写的单词很可能是某种实体。
11.在控制台中进行格式化
也可以将结果格式化为文本(在控制台中可能有用):
expl = eli5.explain_weights(crf, top=5, targets=['O', 'B-LOC', 'I-LOC'])
print(eli5.format_as_text(expl))
注意:本文中代码可能由于相关依赖库版本无法完全实现!!!
参考资料
[1] Named Entity Recognition using sklearn-crfsuite
[2] CoNLL2002.ipynb
[3] 一文理解条件随机场CRF
[4] 利用CRF模型进行文本分类完整教程(Python语言)
[5] CRF进行中文命名实体识别(使用sklearn_crfsuite进行实现)



![[oeasy]python0068_控制序列_清屏_控制输出位置_2J](https://img-blog.csdnimg.cn/img_convert/0a825a6550832bac039b55959c5d2d18.png)