第一章 启发式 Arm 架构解读
第二章 CPU微架构
第三章 系统微架构
第四章 总线微架构
第五章 监控微架构
第六章 安全微架构
第七章 虚拟化微架构
第八章 Armv9-A 架构
第九章 Armv8-M 架构
第十章 Armv8-R 架构
第十一章 Cortex-A715 解读
第十二章 Cortex-X3 解读
第十三章 Neoverse 解读
第十四章 Cortex-M85 解读
第十五章 Cortex-R82 解读
目录
前言
一、架构概述
1.1 冯诺依曼架构
1.2 哈佛架构
1.3 Arm 架构
二、架构图谱
2.1 三驾马车
2.2 六代传承
2.3 最新成员
2.3.1 大师兄 Cortex-A710
2.3.2 二师弟 Cortex-R82
2.3.3 小师妹 Cortex-M85
2.4 架构宗亲
2.4.1 图形处理器单元 GPU
2.4.2 神经网络处理器单元 NPU
三、架构魔法
3.1 派系
3.1.1 Cortex-A 魔法
3.1.2 Cortex-R 魔法
3.1.3 Cortex-M 魔法
3.2 时代
3.3 微魔法
四、架构演练
4.1 大集结
4.2 排兵布阵
4.3 运筹帷幄,决胜千里之外
4.3.1 上传下达-控制台输出
4.3.2 烽火通信-LED 跑马灯
4.3.3 密令签发-加密
4.3.4 粮草先行-启动代码
4.3.5 整装待发-链接脚本
五、总结
参考
前言
- 提醒:全文10千字,预计阅读时长15分钟;
- 读者:对 Arm 架构感兴趣的小伙伴;
- 摘要:本文主要探讨了 Arm 架构的底层逻辑,介绍了Arm 架构的顶层设计;以处理器核心架构为基础,以系统架构为核心,以A系列和M系列架构为典型,对关键系统组件进行的通俗易懂的描述;本文提到的 Arm 架构不包含 GPU、NPU 架构;
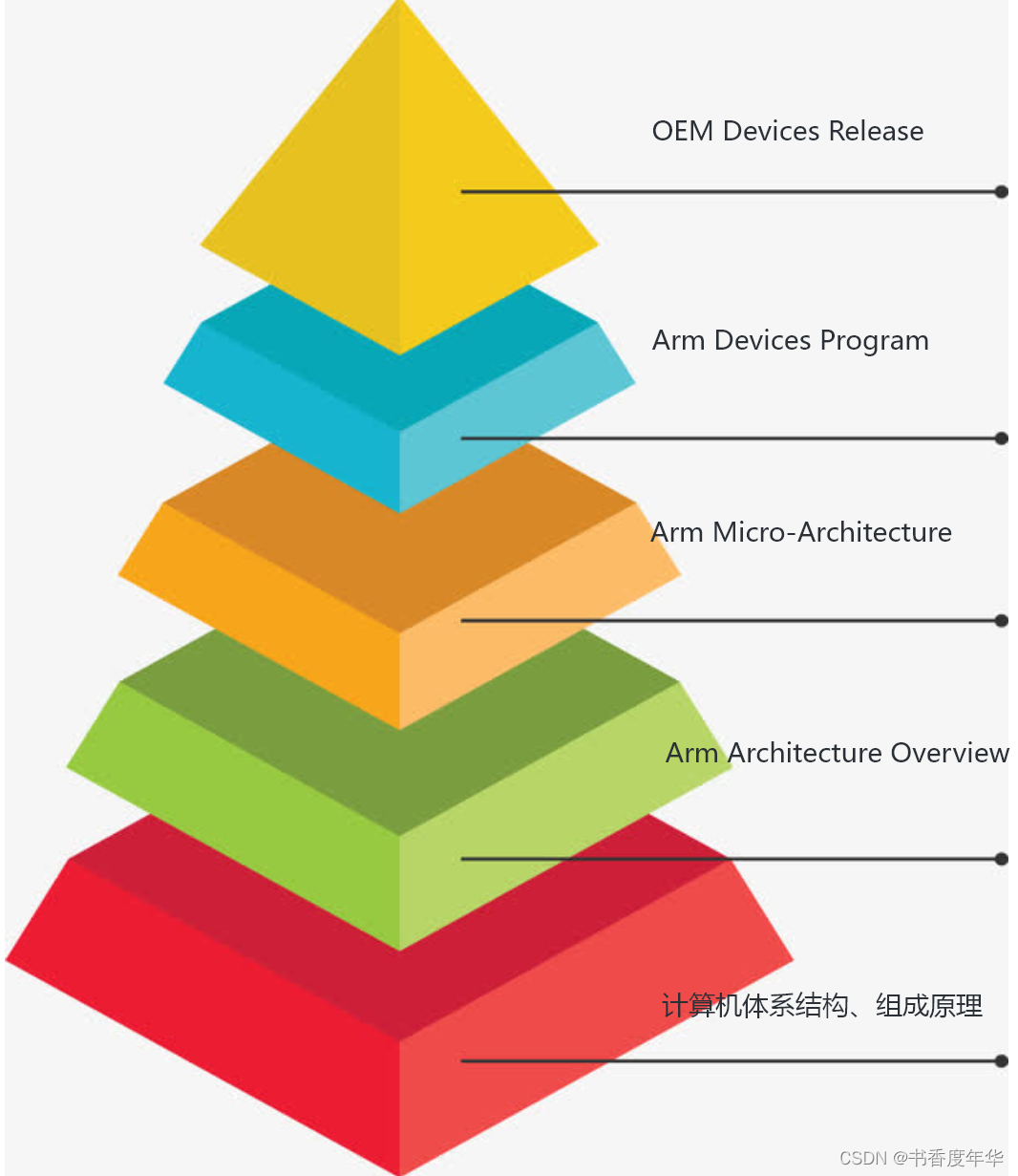
图1 Arm 知识结构
- 关键词 :Arm架构、微架构、Cortex-A、Cortex-R、Cortex-M、Armv7、Armv8、Armv9、ISA、指令集、AMBA总线、Debug、Trustzone、虚拟化、EL-2、S-EL2、EL-1、S-EL1、操作系统、RISC-V;
- 相关推荐:如果你对结构、架构、系统等概念感兴趣,建议阅读架构与系统 ;
- 相关推荐:如果你对 Arm 公司感兴趣,建议阅读一文读懂Arm公司;
一、架构概述
1.1 冯诺依曼架构
- 冯·诺依曼结构也称普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。程序指令存储地址和数据存储地址指向同一个存储器的不同物理位置,因此程序指令和数据的宽度相同,如英特尔公司的8086中央处理器的程序指令和数据都是16位宽。
- 数学家冯·诺依曼提出了计算机制造的三个基本原则,即采用二进制逻辑、程序存储执行以及计算机由五个部分组成(运算器、控制器、存储器、输入设备、输出设备),这套理论被称为冯·诺依曼体系结构。
1.2 哈佛架构
- 哈佛结构是一种并行体系结构,它的主要特点是将程序和数据存储在不同的存储空间中,即程序存储器和数据存储器是两个独立的存储器,每个存储器独立编址、独立访问。 简介 与两个存储器相对应的是系统的4条总线:程序和数据的数据总线与地址总线。
1.3 Arm 架构
- Arm 架构指的是 Arm 处理器的体系结构,包含中央处理单元(CPU)微架构、系统微架构、总线微架构、监控微架构、安全微架构、虚拟化微架构。
- CPU微架构是指令集架构ISA的实现,包括 A32/T32、A64、NEON、VFP 等;
- 系统架构集包括中断控制器 GIC /系统内存管理器 SMMU /电源管理 PSCA/APCI 等;
- 总线微架构指的是 AMBA 微架构,包括 AHB、APB、AXI、CHI 等;
- 监控微架构包括调试 debug, 跟踪 trace ;
- 安全微架构包括 Trustzone、Realm、Crypto Cell、Crypto Island 等;
- 虚拟化微架构包括 VMSA、LPAE、EL-2、S-EL2 等。
| CPU 微架构 | 实现指令集架构的中央运算单元架构,A、R、M系列架构描述的就是 CPU 架构 |
| 系统微架构 | 为了处理器各个组件能够正常运行而存在的系统组件架构 |
| 总线微架构 | 将各个架构子系统连接起来的桥梁架构 |
| 监控微架构 | 对系统各个架构组件进行调试、跟踪 |
| 安全微架构 | 用来实现系统安全的架构集合 |
| 虚拟化微架构 | 用来对硬件资源进行虚拟化的架构集合 |
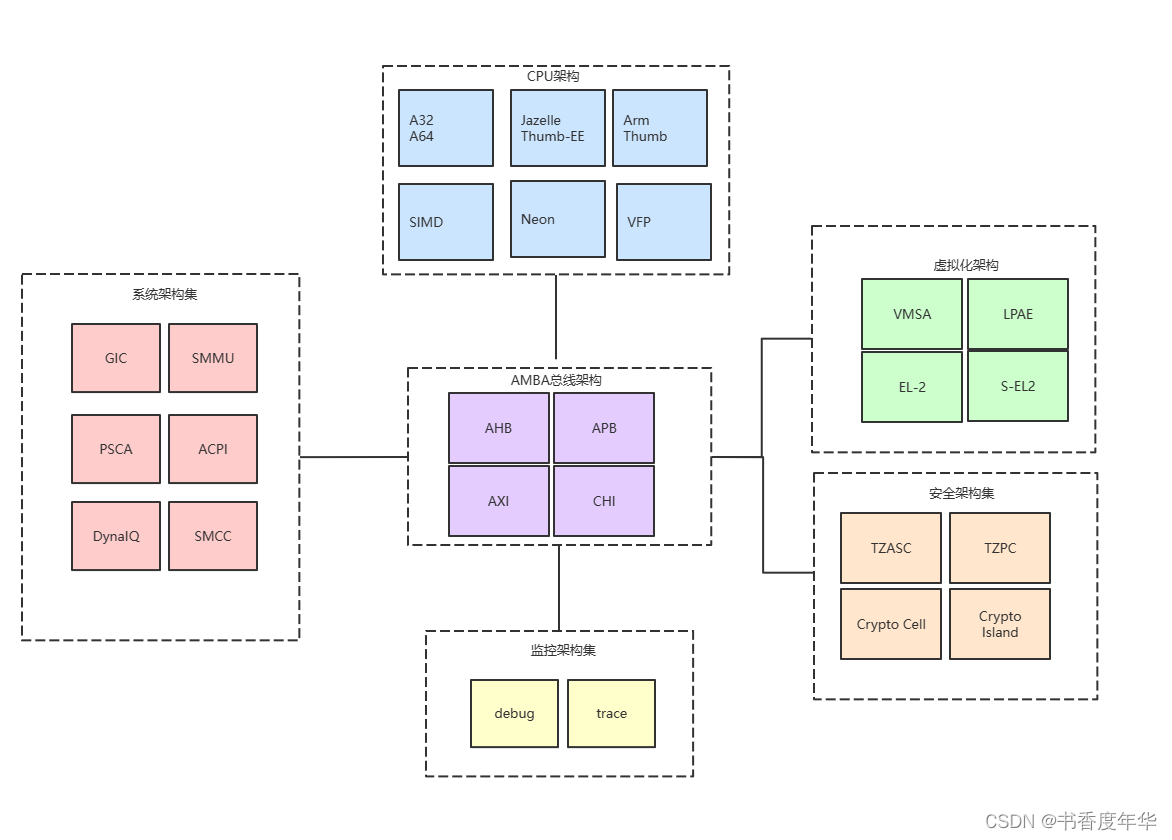
图2 Arm 处理器顶层架构
二、架构图谱
2.1 三驾马车
- Arm 架构根据应用场景不同分为 Cortex-A、Cortex-M、Cortex-R 三个架构家族;
- Arm A-Profile 架构主要包括用于移动、 PC 端的 Cortex-A 系列处理器、用于云计算和机器学习的高性能 Neoverse 处理器以及和客户合作开发的高效能 Cortex-X 系列处理器,后面两个系列可能形成独立系列;
- Arm M-Profile 架构主要包括 Armv6 的 M0,Armv7 的 Cortex-M3、 Cortex-M4 ,Armv8 的 Cortex-M23、 Cortex-M33 、 Cortex-M35 、Cortex-M55 、Cortex-M85,用于通用 MCU 、IoT 物联网领域;
- Arm R-Profile 架构主要包括 Armv7 的Cortex- R4、 Cortex-R5、 Cortex-R7、 Cortex-R8,Armv8 的 Cortex-R52 、Cortex-R82,用于实时控制领域。
每个架构家族演进既有独立性又有关联性。目前 A 系列已经演化到 Armv9 版本、M 系列演化到 Armv8 版本、R系列演化到 Armv8 版本,下面是每个家族代表性处理器的架构。
2.2 六代传承
- Arm 架构从 Armv4 到 Armv9 已经经历了六个版本;
- 目前市面活跃的是 Armv7、Armv8、Armv9 三个版本;
- 各个版本引进/废弃了不同的功能特性,比如 Armv6 的 Trustzone、 Armv7 的虚拟化,Armv8 的向量扩展 SVE、Armv9 的矩阵扩展 SME 等。
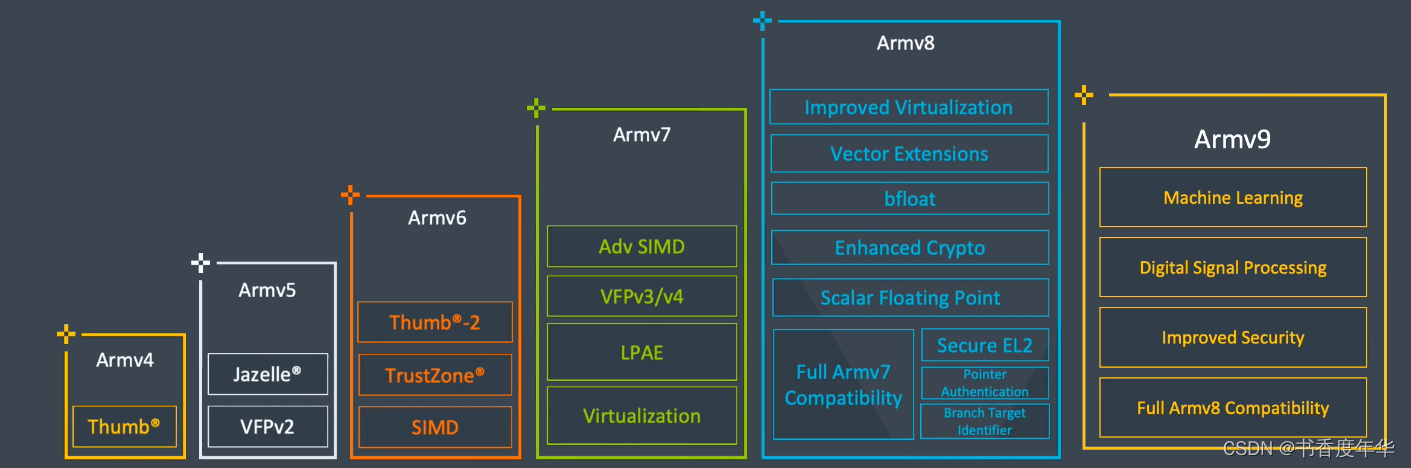
图3 架构版本
2.3 最新成员
2.3.1 大师兄 Cortex-A710
Cortex-A710 是 Cortex-A78 的增强版,Armv9-A 架构的大核架构,使用起来和上一代基本相同,新的微架构能获得更好的性能和更低的功耗;增强版的向量计算扩展架构 SVE2 支持;高级 SIMD&DSP 的 NEON 架构支持;兼容 VFPv3 向量浮点的 FPU 浮点架构。

图4 Cortex-A710 架构图
2.3.2 二师弟 Cortex-R82
Cortex-R82 是 R 系列最新的处理器,采用 Armv8 架构,包含 CoreSgiht MDT、GIC、FPU、TCM、SCU、ACP、AXI-S、AXI-M、LLPP、LLRAM 等微架构。
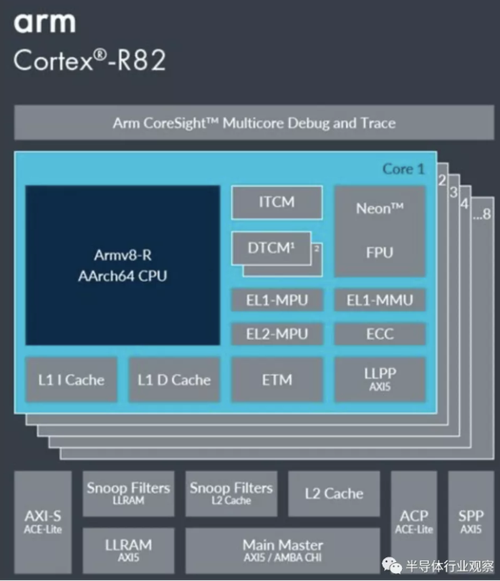
图5 Cortex-R82 架构图
2.3.3 小师妹 Cortex-M85
M85 是 Armv8.1-M 架构,包括 MPU、Helium、PMU、CP、FPU、TCM、AHB、DSP、ETM、PACBTI、APH 等微架构。
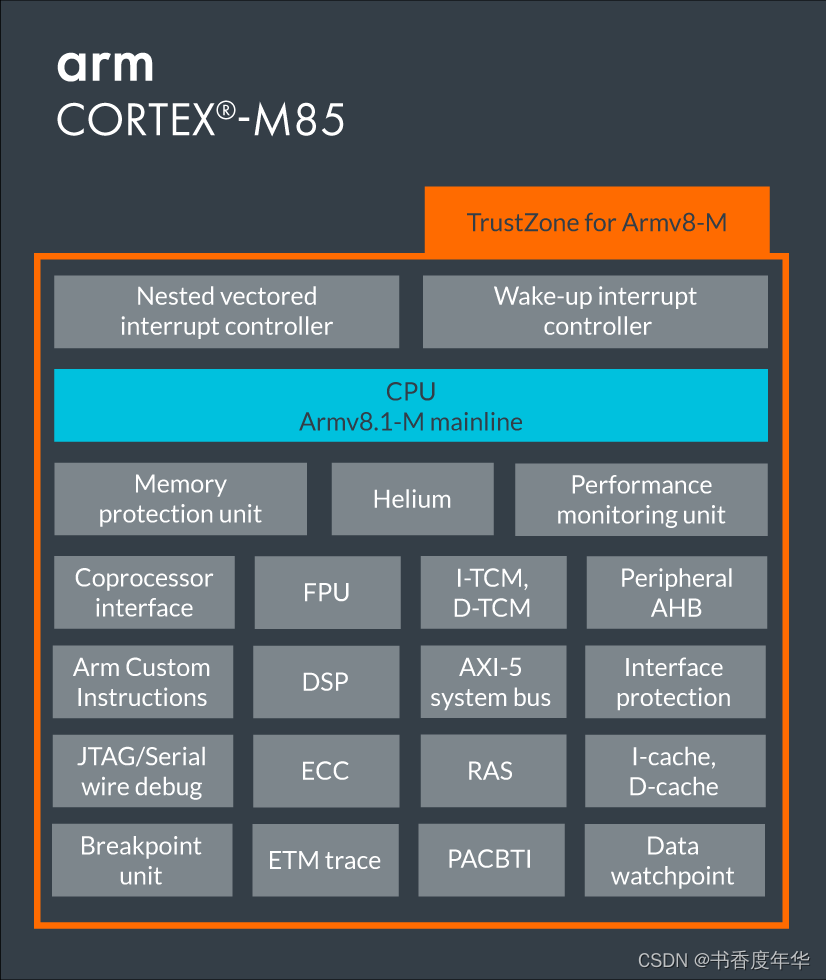
图6 Cortex-M85 架构图
2.4 架构宗亲
本文讲述的 Arm 架构指的是通用处理器架构,并不包含专业处理器。除了通用处理器,Arm 还有图形处理器和神经网络处理器。
2.4.1 图形处理器单元 GPU

图7 Mali GPU 路线图
GPU 架构分为传统的 Mali 架构和最新的 Immortalis 架构两个分支:
- Mali目前一共四代,分别是 Utgard,Midgard,Bifrost 和 Valhall
- Immortalis 是新推出的架构,以Immortalis-G715 为代表
更多GPU架构知识,参考 Arm GPUs
2.4.2 神经网络处理器单元 NPU
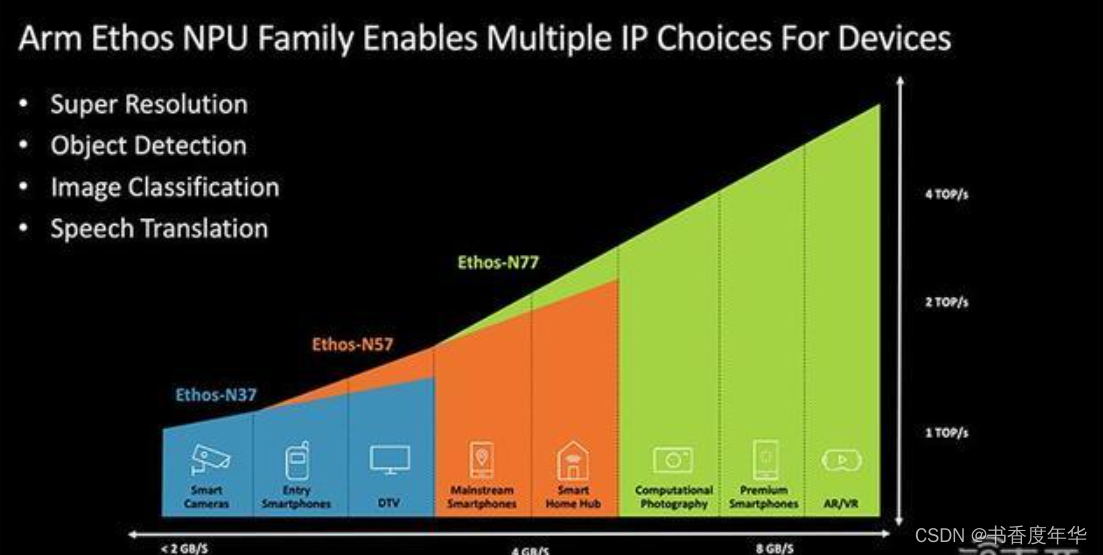
图8 Ethos NPU 家族
Ethos - NPUs 是Arm推出的基于神经网络的机器学习芯片架构,包括 U55、U65、 N78,
更多 NPU 知识,参考 Arm NPUs
三、架构魔法
架构魔法指的是架构特性,比如运算魔法、安全魔法、虚拟化魔法等,而这部分我们将从派系、时代、微魔法多个维度介绍这些神秘的魔法。
3.1 派系
3.1.1 Cortex-A 魔法
魔法8.0(Armv8.0-A)
- Advance SIMD
- aSIMD,增强的定长高级单指令多数据
- 在 Armv8-A 中,与变长的 SVE、SVE2 共同构成了SIMD
- SVE 主要用在 HPC 中,在 V9 中为标配
- 密码扩展 (Crypto Extension ,CE)
- AES加速器:AEAD、AESE
- SHA加速器:SHA1、SHA256
- CRC
- 硬件 CRC 加速
魔法8.1(Armv8.1-A)
- Atomic memory access instructions (AArch64)
- 为大型 系统 LSE 设计的存储原子访问扩展,PostgreSQL 已经支持,比如独占加载指令LDXR、独占存储指令STXR
- Limited Order regions (AArch64)
- 为大系统LSE设计的内存访问顺序,load-aquire、store-release指令
- 是乱序时代的DMB、DSB、ISB的升级版
- Increased Virtual Machine Identifier (VMID) size, and Virtualization Host Extensions (AArch64)
- 虚拟化中更大的虚拟机 ID
- 直接将 Host 运行在 EL2 的 VHE 技术
- Privileged Access Never (PAN) (AArch32 and AArch64)
- 可以通过 PAN 限制内核对用户空间内存的访问
魔法8.2(Armv8.2-A)
- Support for 52-bit addresses (AArch64)
- 52位大物理地址和大虚拟地址的支持,通常面向服务器应用
- The ability for PEs to share Translation Lookaside Buffer (TLB) entries (AArch32 and AArch64)
- 多 PE 共享 TLB,即共享页表项
- FP16 data processing instructions (AArch32 and AArch64)
- 相对于单精度和双精度,支持半精度
- Statistical profiling (AArch64)
- 内置于流水线内部的指令统计工具,比如包延迟、采样指令的重要信息(access/hit/miss,分支预测错误,是否读写互锁)、源于哪一级的存储
- Reliability Availability Serviceability (RAS) support becomes mandatory (AArch32 and AArch64)
- 提供保证可靠性、可用性、可服务性的机制,TF-A 已经支持了 RAS 框架
- 安全扩展 CE
- SHA2-512、SHA3
- SM3、SM4
魔法8.3(Armv8.3-A)
- Pointer authentication (AArch64)
- 对指令指针、数据指针进行身份认证
- 目前GCC -msign-return-address 支持返回LR的认证
- Nested virtualization (AArch64)
- 允许客户机在 EL1 中运行虚拟机管理程序
- 增加了 EL1 到 EL2 的访问机制
- Advanced Single Instruction Multiple Data (SIMD) complex number support (AArch32 and AArch64)
- aSIMD支持复数运算
- Improved JavaScript data type conversion support (AArch32 and AArch64)
- 改进的javascript数据类型转换支持
- A change to the memory consistency model (AArch64)
- 在RCsc基础上增加weaker RCpc支持
- ID mechanism support for larger system-visible caches (AArch32 and AArch64)
- cache ID寄存器扩容
魔法8.4(Armv8.4-A)
- Secure virtualization (AArch64)
- S-EL2支持,可以在安全环境下运行安全虚拟机
- Nested virtualization enhancements (AArch64)
- Small translation table support (AArch64)
- Relaxed alignment restrictions (AArch32 and AArch64)
- Memory Partitioning and Monitoring (MPAM) (AArch32 and AArch64)
- Additional crypto support (AArch32 and AArch64)
- Generic counter scaling (AArch32 and AArch64)
- Instructions to accelerate SHA
魔法8.5/9.0(Armv8.5-A/Armv9.0-A)
- Memory Tagging (AArch64)
- Branch Target Identification (AArch64)
- Random Number Generator instructions (AArch64)
- Cache Clean to Point of Deep Persistence (AArch64)
- V5A
魔法8.6/9.1(Armv8.6-A/Armv9.1-A)
- General Matrix Multiply (GEMM) instructions (AArch64)
- Fine grained traps for virtualization (AArch64)
- High precision Generic Timer
- Data Gathering Hint (AArch64)
- V6-A
魔法8.7/9.2(Armv8.7-A/Armv9.2-A)
- Enhanced support for PCIe hot plug (AArch64)
- Atomic 64-byte load and stores to accelerators (AArch64)
- Wait For Instruction (WFI) and Wait For Event (WFE) with timeout (AArch64)
- Branch-Record recording (Armv9.2 only)
魔法8.8/9.3(Armv8.8-A/Armv9.3-A)
- Non-maskable interrupts (AArch64)
- Instructions to optimize memcpy() and memset() style operations (AArch64)
- Enhancements to PAC (AArch64)
- Hinted conditional branches
3.1.2 Cortex-R 魔法
第七代魔法(Armv7-R)
第八代魔法(Armv8-R)
3.1.3 Cortex-M 魔法
第八代魔法(Armv8.0-M)
第八代魔法v1(Armv8.1-M)
- MVE (M-Profile Vector Extension),Arm Helium
-
LoB/Loop Tail Predication/BF
-
Security
- Execution permission
- V8.2-M PAC(Pointer Authentication)
- V8.2-M BTI(Branch Target Instructions)
- DIT(Data Independent Timing)
- UDE(Unprivileged Debug Extension)
3.2 时代
| 2022 | A-PROFILE 2022 |
| 2021 | A-PROFILE 2021 |
| 2020 | A-PROFILE 2020 |
| 2019 | - |
| 2018 | A-PROFILE 2018 |
| 2017 | A-PROFILE 2017 |
| 2016 | A-PROFILE 2016 |
| 2015 | A-PROFILE 2015 |
| 2014 | A-PROFILE 2014 |
3.3 微魔法
| NEON | 整数向量运算 |
| VFP | 浮点向量运算 |
| SVE | 变长向量扩展运算 |
查看ID_AA64xxxx系列寄存器识别当前 CPU 实现的架构特性。
四、架构演练
4.1 大集结
随着时间的推移和需求变化,各个产品家族都演化出了多个成员,其中 Cortex-A 系列处理器从 A5到 A715 共发布了24款,Cortex-M 系列处理器从 M0 到 M85 共发布了11款,Cortex-R 系列处理器从 R4 到 R82 共发布了11款,对于各个处理器之间的差异,可以从下面链接表格中看到。
- Arm Cortex-A 系列处理器功能对比表
- Arm Cortex-M 处理器功能对比表
- ArmCortex-R 处理器功能对比表
4.2 排兵布阵
不同的处理器可处理不同的应用。
在可穿戴方面,主要用 Cortex-A 和 Cortex-M ;存储方面 Cortex-R 和 Cortex-M ;在 ADAS 方面有 Cortex-A 和 Cortex-R ,A用于高性能计算、R用于实时和安全控制;在移动消费市场,Cortex-A、Cortex-R 和 Cortex-M 都有应用,A 来做应用处理器,R 主要是做基带,Cortex-M 可能会用于sensor hub (传感器中枢)的芯片领域。
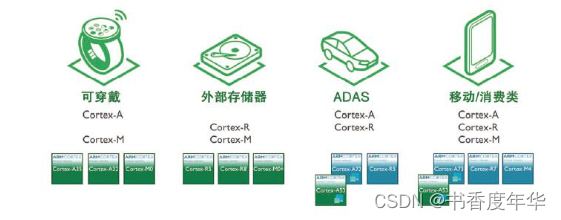
图7 应用领域
4.3 运筹帷幄,决胜千里之外
4.3.1 上传下达-控制台输出
/*Hello world*/
#include <stdio.h>
int main()
{
printf("Hello World\n");
return 0;
}4.3.2 烽火通信-LED 跑马灯
#include"led.h"
void LED_Init(void)
{
RCC->APB2ENR|=1<<2;
RCC->APB2ENR|=1<<5;
GPIOA->CRH&=0XFFFFFFF0;
GPIOA->CRH|=0X00000003;
GPIOA->ODR|=1<<8;
GPIOD->CRL&=0XFFFFF0FF;
GPIOD->CRL|=0X00000300;
GPIOD->ODR|=1<<2;
}4.3.3 密令签发-加密
void mbedtls_aes_encrypt( mbedtls_aes_context *ctx,
const unsigned char input[16],
unsigned char output[16] )
{
int i;
uint32_t *RK, X0, X1, X2, X3, Y0, Y1, Y2, Y3;
RK = ctx->rk;
GET_UINT32_LE( X0, input, 0 ); X0 ^= *RK++;
GET_UINT32_LE( X1, input, 4 ); X1 ^= *RK++;
GET_UINT32_LE( X2, input, 8 ); X2 ^= *RK++;
GET_UINT32_LE( X3, input, 12 ); X3 ^= *RK++;
for( i = ( ctx->nr >> 1 ) - 1; i > 0; i-- )
{
AES_FROUND( Y0, Y1, Y2, Y3, X0, X1, X2, X3 );
AES_FROUND( X0, X1, X2, X3, Y0, Y1, Y2, Y3 );
}
AES_FROUND( Y0, Y1, Y2, Y3, X0, X1, X2, X3 );
X0 = *RK++ ^
( (uint32_t) FSb[ ( Y0 ) & 0xFF ] ) ^
( (uint32_t) FSb[ ( Y1 >> 8 ) & 0xFF ] << 8 ) ^
( (uint32_t) FSb[ ( Y2 >> 16 ) & 0xFF ] << 16 ) ^
( (uint32_t) FSb[ ( Y3 >> 24 ) & 0xFF ] << 24 );
X1 = *RK++ ^
( (uint32_t) FSb[ ( Y1 ) & 0xFF ] ) ^
( (uint32_t) FSb[ ( Y2 >> 8 ) & 0xFF ] << 8 ) ^
( (uint32_t) FSb[ ( Y3 >> 16 ) & 0xFF ] << 16 ) ^
( (uint32_t) FSb[ ( Y0 >> 24 ) & 0xFF ] << 24 );
X2 = *RK++ ^
( (uint32_t) FSb[ ( Y2 ) & 0xFF ] ) ^
( (uint32_t) FSb[ ( Y3 >> 8 ) & 0xFF ] << 8 ) ^
( (uint32_t) FSb[ ( Y0 >> 16 ) & 0xFF ] << 16 ) ^
( (uint32_t) FSb[ ( Y1 >> 24 ) & 0xFF ] << 24 );
X3 = *RK++ ^
( (uint32_t) FSb[ ( Y3 ) & 0xFF ] ) ^
( (uint32_t) FSb[ ( Y0 >> 8 ) & 0xFF ] << 8 ) ^
( (uint32_t) FSb[ ( Y1 >> 16 ) & 0xFF ] << 16 ) ^
( (uint32_t) FSb[ ( Y2 >> 24 ) & 0xFF ] << 24 );
PUT_UINT32_LE( X0, output, 0 );
PUT_UINT32_LE( X1, output, 4 );
PUT_UINT32_LE( X2, output, 8 );
PUT_UINT32_LE( X3, output, 12 );
}4.3.4 粮草先行-启动代码
.text
.global _start
_start:
@异常向量表
b reset
nop
b swi_handler
nop
nop
nop
b irq_hander
nop
reset:
ldr sp,=buf+512*3
@irq模式
mrs r0,cpsr
bic r0,#0x1f
orr r0,#0x12
msr cpsr,r0
ldr sp,=buf+512*2
@user模式
mrs r0,cpsr
bic r0,#0x1f
orr r0,#0x10
msr cpsr,r0
ldr sp,=buf+512
mov r0,#0x11
mov r1,#0x22
SWI 1
add r2,r0,r1
nop
nop
stop:
nop
nop
nop
B stop
@软中断
swi_handler:
@入栈保护现场
stmfd sp!,{r0-r12,lr}
mov r0,#0x1f
mov r1,#0x2f
mov r2,#0x3f
mov r3,#0x4f
mov r4,#0x5f
@出栈 恢复现常,还原模式 spsr->cpsr
@lc -> pc
ldmfd sp!,{r0-r12,pc}^
@mov pc,lr
@中断
irq_hander:
@入栈保护现场
stmfd sp!,{r0-r12,lr}
@中断处理
@switch(irqnum)
ldmfd sp!,{r0-r12,pc}^
.DATA
buf:
.space 512*3
.end
4.3.5 整装待发-链接脚本
SECTIONS
{
. = 0x80000,
.text.boot :{*(.text.boot)}
.text : {*(.text)}
.rodata : {*(.rodata)}
.data : {*(.data)}
. = ALIGN(0x8);
bss_begin = .;
.bss :{*(.bss*)}
bss_end = .;
. = ALIGN(4096);
init_pg_dir = .;
+= 4096;
}五、总结
从过程角度来看,本文以架构概述、架构发展、架构特性、架构演练为主线对 Arm 架构进行了启发式的介绍。从金字塔式知识结构角度来看,本文涉及到了计算机体系结构、Arm 系统架构、微架构、处理器编程模型、应用编程;从系统思维角度来看,本文只是对于读者很可能是浮光掠影,蜻蜓点水,所以后面章节会更加系统化、体系化、深入的讲述 Arm 架构。
参考
- Arm CPU架构参考手册合集
- AMBA 总线微架构参考手册合集
- 系统微架构参考手册合集
- 指令集微架构参考手册合集
- 安全微架构参考手册合集
- 功耗控制系统架构PSCA
术语
图灵机
一个抽象的机器、思想模型;
总线
计算机各种功能部件之间传送信息的公共通信干线;
Trustzone
通过隔离实现可信域的技术;
Hypervisor
虚拟机监视器,是用来建立与执行虚拟机器的软件、固件或硬件。
分享知识是一种美德,如果你感觉这篇文章写的还不错,请点赞、收藏、分享。
下一章 CPU微架构

![[oeasy]python0068_控制序列_清屏_控制输出位置_2J](https://img-blog.csdnimg.cn/img_convert/0a825a6550832bac039b55959c5d2d18.png)