1:数据读取和加载
接着上面的常规操作
加载环境变量---》获取所有路径---》加载文档---》切分文档
代码如下:
import os
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
# 获取folder_path下所有文件路径,储存在file_paths里
file_paths = []
folder_path = './llm-universe/data_base/knowledge_db'
for root, dirs, files in os.walk(folder_path):
# print('*'*50)
# print('root:', root)
# print('dirs:', dirs)
# print('files:', files)
# print('*'*50)
for file in files:
file_path = os.path.join(root, file)
file_paths.append(file_path)
print('*'*50)
print('file_paths:', file_paths)
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader
# 遍历文件路径并把实例化的loader存放在loaders里
loaders = []
for file_path in file_paths:
# 按照后缀对文件进行读取
file_type = file_path.split('.')[-1]
if file_type == 'pdf':
loaders.append(PyMuPDFLoader(file_path))
elif file_type == 'md':
loaders.append(UnstructuredMarkdownLoader(file_path))
# 加载文件并存储到text
texts = []
for loader in loaders: texts.extend(loader.load())
'''
载入后的变量类型为langchain_core.documents.base.Document, 文档变量类型同样包含两个属性
page_content 包含该文档的内容。
meta_data 为文档相关的描述性数据。
'''
text = texts[1]
# print(f"每一个元素的类型:{type(text)}.",
# f"该文档的描述性数据:{text.metadata}",
# f"查看该文档的内容:\n{text.page_content[0:]}",
# sep="\n------\n")
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 切分文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=50)
print('text_splitter_type:', type(text_splitter))
split_docs = text_splitter.split_documents(texts)
print('split_docs_type:', type(split_docs))
print('split_docs长度:', len(split_docs))
print('split_docs[0]:', split_docs[0])2:加载词向量模型和向量数据库
# 定义持久化路径
persist_directory = './vector_db_test/'
# 删除旧的数据库文件(如果文件夹中有文件的话),windows电脑请手动删除 !rm -rf '../../data_base/vector_db/chroma'
#加载chroma
from langchain.vectorstores.chroma import Chroma
vectordb = Chroma.from_documents(
documents=split_docs[:5], # 为了速度,只选择前 20 个切分的 doc 进行生成;使用千帆时因QPS限制,建议选择前 5 个doc
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
#存储向量数据库
vectordb.persist()
print(f"向量库中存储的数量:{vectordb._collection.count()}")在加载chroma的时候如果本身有向量数据库可能会产生错误:
Traceback (most recent call last):
File "/workspaces/test_codespace/createVectordb.py", line 94, in <module>
vectordb = Chroma.from_documents(
File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 778, in from_documents
return cls.from_texts(
File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 736, in from_texts
chroma_collection.add_texts(
File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/langchain_community/vectorstores/chroma.py", line 297, in add_texts
self._collection.upsert(
File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 299, in upsert
self._client._upsert(
File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 352, in _upsert
self._validate_embedding_record(coll, r)
File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 633, in _validate_embedding_record
self._validate_dimension(collection, len(record["embedding"]), update=True)
File "/opt/conda/envs/zyx_llm/lib/python3.10/site-packages/chromadb/api/segment.py", line 648, in _validate_dimension
raise InvalidDimensionException(
chromadb.errors.InvalidDimensionException: Embedding dimension 384 does not match collection dimensionality 1024这个就是因为你没有把之前的删除干净,解决方法就是要么删除原来的,要么重新开一个路径
3:向量检索
(1):相似度检索
Chroma的相似度搜索使用的是余弦距离,即:下面博客里面有相似度计算的向量数据库相关知识(搬运学习,建议还是看原文,这个只是我自己的学习记录)-CSDN博客
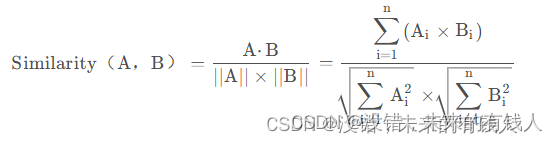
当你需要数据库返回严谨的按余弦相似度排序的结果时可以使用similarity_search函数。
(2):最大边际相关性 (MMR, Maximum marginal relevance) 检索
如果只考虑检索出内容的相关性会导致内容过于单一,可能丢失重要信息。
最大边际相关性 (MMR, Maximum marginal relevance) 可以帮助我们在保持相关性的同时,增加内容的丰富度。
核心思想是在已经选择了一个相关性高的文档之后,再选择一个与已选文档相关性较低但是信息丰富的文档。这样可以在保持相关性的同时,增加内容的多样性,避免过于单一的结果。

参考:最大边界相关算法MMR(Maximal Marginal Relevance) 实践-CSDN博客
两个检索的代码:
#向量检索
######相似度检索
question="什么是大语言模型"
# 按余弦相似度排序的结果
sim_docs = vectordb.similarity_search(question,k=3)
print(f"检索到的内容数:{len(sim_docs)}")
for i, sim_doc in enumerate(sim_docs):
print(f"检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")
#######MMR检索
mmr_docs = vectordb.max_marginal_relevance_search(question,k=3)
for i, sim_doc in enumerate(mmr_docs):
print(f"MMR 检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")