前言
llama 3出来后,为了通过paper-review的数据集微调3,有以下各种方式
- 不用任何框架 工具 技术,直接微调原生的llama 3,毕竟也有8k长度了
效果不期望有多高,纯作为baseline - 通过PI,把llama 3的8K长度扩展到12k,但需要什么样的机器资源,待查
apple为主,不染为辅 - 阿里云百练大模型服务平台、百度智能云千帆大模型平台对llama 3的支持
文弱zu - 通过llama factory微调3,但等他们适配3(除非我们改factory),类似
llama factory + pi
llama factory + longlora/longqlora - 我们自行改造longqlora(longlora也行,但所需机器资源更大),以适配3
类似之前的经典组合:longqlora(PI + s2-Attn + qlora) + flash attention + zero3 - 基于xtuner微调llama 3
三太子则在与70b微调工作不冲突的前提下,试下这个xtuner
第一部分 拿我司的paper-review数据集通过PI微调LLama 3
1.1 使用PI微调llama3-8b
// 待更
1.2 通过百度智能云的千帆大模型平台微调Llama 3
// 待更
第二部分 基于llama factory和paper-review数据集微调LLama3
LLaMA Factory 现已支持 Llama 3 模型,提供了在 Colab 免费 T4 算力上微调 Llama 3 模型的详细实战教程:https://colab.research.google.com/drive/1d5KQtbemerlSDSxZIfAaWXhKr30QypiK?usp=sharing
同时社区已经公开了两款利用本框架微调的中文版 LLaMA3 模型,分别为:
- Llama3-8B-Chinese-Chat,首个使用 ORPO 算法微调的中文 Llama3 模型,文章介绍:https://zhuanlan.zhihu.com/p/693905042
- Llama3-Chinese,首个使用 DoRA 和 LoRA+ 算法微调的中文 Llama3 模型,仓库地址:https://github.com/seanzhang-zhichen/llama3-chinese
// 待更
第三部分 不用PI和S2-attn,调通Llama-3-8B-Instruct-262k
3.1 基于15K的「情况1:晚4数据」微调Llama 3 8B Instruct 262k
3.1.1 基于1.5K的「情况1:晚4数据」微调Llama 3 8B Instruct 262k
24年5.25日,我司审稿项目组的青睐同学,通过我司的paper-review数据集(先只取了此文情况1中晚期paper-4方面review数据中的1.5K的规模,另,本3.1.1节和3.1.2节都统一用的情况1中的晚期paper-4方面review数据),把llama3调通了
至于llama3的版本具体用的Llama-3-8B-Instruct-262k,这个模型不是量化的版本,其他很多版本虽然扩展长度了,但基本都传的量化后的,这个模型的精度是半精的(当然,还有比较重要的一点是这个模型的下载量比较高)
以下是关于本次微调的部分细节,如青睐所说
- 一开始用A40 + 1.5K数据微调时,用了可以节省所需显存资源的s2atten(S2-attention + flash attention),且由于用了 26k 长度扩展的那个模型,便不用插值PI了
但48g的A40在保存模型的时候显存会超过48g(训练过程中不会出现),而zero3模型保存时会报oom,后来经验证发现原因是:per_eval_device_batch size设置太大导致了oom
总之,用A40 训练时其具有的48g显存是可以训练超过 12k上下文数据的,不一定非得用s2atten(毕竟上面也说了,过程中微调llama3出现oom是因为per_eval_device_batch size设置太大照成的,与训练没啥关系,一个很重要的原因是llama3的词汇表比较大,从32K拓展到了128K,压缩率比较高,导致论文的长度比llama2短,所以A40也放的下) - 后来改成了用A100训练(数据规模还是1.5K),由于用了A100,故关闭了s2atten,直接拿12K的长度开训,且用上了flash atten v2,得到下图这个结果

3.1.2 用5K-15K的「情况1:晚4数据」微调Llama-3
再后来用8卡A40对5K或15K数据微调时,便也都没有用S2-attention(关闭了),使用12K长度 + flash attention v2 微调
代码和上面跑1.5K的数据一样,也还是用的「七月大模型线上营那套longqlora代码」,但把单卡设置成多卡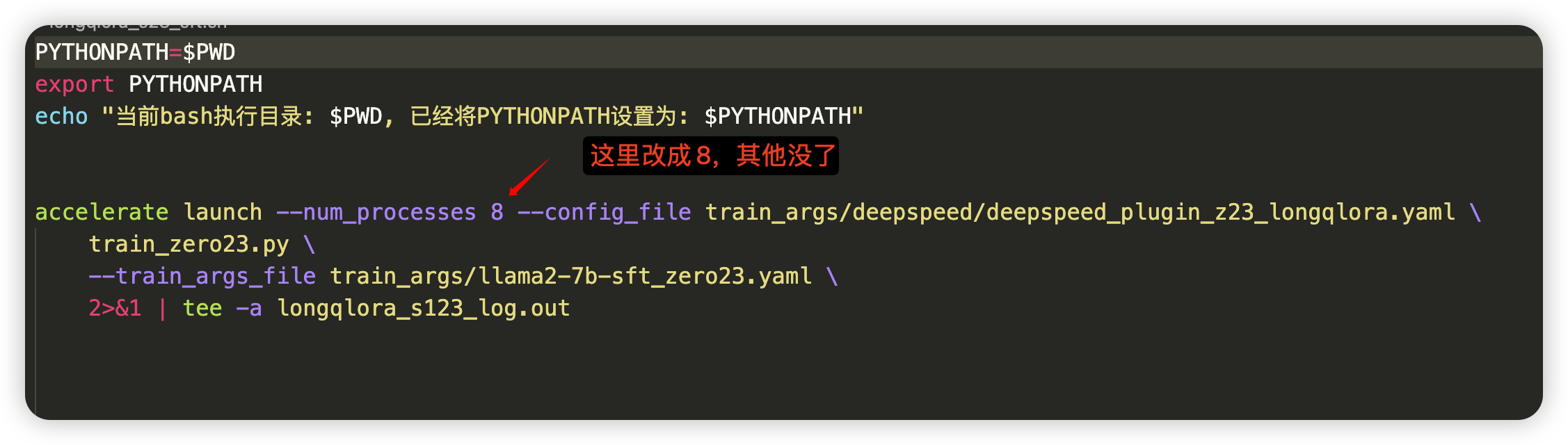
且直接租2台「8卡的A40」,一台5K的数据,一台15K的数据,直接一块跑

以下是15K数据(晚期paper-4方面review)微调后针对YaRN那篇论文得到的推理结果

接下来,青睐先推理下测试集中的晚期paper,输出4方面review
最后,文弱测评一下,让GPT4-1106、情况1的llama2(也是晚期paper-4方面review),都统一跟人工4方面review做下匹配
// 待更
3.2 基于15K的「情况3:早4数据」微调Llama 3 8B Instruct 262k
3.2.1 llama3版本的情况3 PK 上两节llama3版本的情况1
上两节用了晚期paper-4方面的review微调llama3-262k,类似于此文开头总结的情况1:用晚期paper-4方面review微调llama2
本节咱们将基于15K的早期paper-4方面review,类似于此文开头总结的情况3:用早期paper-4方面review微调llama2
本节微调完之后,自然便可以与以下模型PK(针对哪个情况,则用那个情况的paper,所以评估llama3-262k版本的情况3时,则都统一早期paper)
llama3版本的情况3 当PK 上两节的llama3版本的情况1,情况如下(当然,按理得胜,毕竟情况3的数据更强,相当于都是llama3,但数据质量不一样,当然,无论是llama2 还是llama3,按道理情况3就得好过情况1,毕竟情况3 早4,情况1 晚4,情况3-早4的数据质量是更高的)
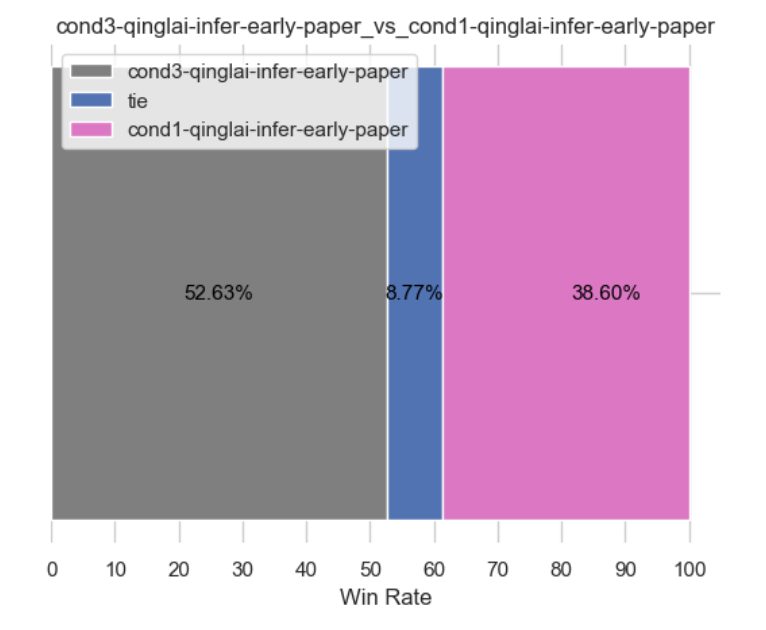
当llama3版本的情况3 PK llama2版本的情况3,按理得胜,毕竟llama3更强
当llama3版本的情况3 PK llama2版本的情况1(以阿荀微调的longqlora 7B做为情况1的基准),按理更得胜,毕竟llama3更强且情况3的数据更强,但目前得到的结果有些奇怪(如下图所示),没达预期,正在找原因中,待后续更新..


// 更多细节暂见我司的:大模型商用项目之审稿微调实战营
3.2.2 llama3情况1 PK llama2情况1——评估微调llama3-8b-instruct-262k基座性能
之后,我们发现使用 15k 情况1样本仅flash attention v2直接微调 llama3-8b-instruct-262k效果不佳,具体可以下面评估结果

- 左图:情况1样本仅flash attention v2直接微调 llama3-8b-instruct-262k
- 右图:情况1样本微调 llama2-7b-chat + PI 扩展长度
可以看到两者性能相当,这个阶段,并没有得到微调llama3性能超过微调llama2的结论,推断可能是llama3-8b-262k原始微调数据集与审稿12k数据集长度分布不太匹配,请看下文第四部分将使用llama-3-8B-Instruct-8k + PI 重新微调,最后获得大幅度性能提升
第四部分 使用PI和flash atten v2 微调llama-3-8B-Instruct-8k
下面训练的数据集皆为15k样本(样本长度普遍9k左右,最长不超过12k),评估方法为基于groud truth 命中数pk,模型取验证集loss最低的模型
此阶段将评估微调llama3-8b-8k与微调llama3-8b-262k&llama2性能差距
4.1 情况3早4数据下的:llama3-8b-instruct-8k + PI 与llama3-8b-instruct-262k 性能pk
经过评估发现,llama3-8b-8k + PI 性能较大幅度领先llama3-8b-262k的性能,如下所示

- 左图:情况3样本仅flash attention v2微调 llama3-8b-8k + PI 扩展长度
- 右图:情况3样本仅flash attention v2直接微调 llama3-8b-instruct-262k
4.2 llama3-8b-instruct-8k + PI 与 llama2-7b-chat 性能pk
4.2.1 llama3下的情况3 强于llama2下的情况3
且经过测试,llama3 在论文审稿场景下的性能确实领先 llama2

- 左图:情况3样本仅flash attention v2微调 llama3-8b-8k + PI 扩展长度
- 右图:情况3样本微调 llama2-7b-chat + PI 扩展长度
4.2.2 llama3下的情况3 更强于llama2下的情况1
此外,下面的这个实验,也无疑再次证明llama3 性能领先 llama2

- 左图:情况3样本仅flash attention v2微调 llama3-8b-8k + PI 扩展长度
- 右图:情况1样本微调 llama2-7b-chat + PI 扩展长度
第五部分 论文审稿GPT第5版:通过15K的早期paper-7方面review数据集(情况4)微调llama3
// 待更





![[数据库]mysql用户管理权限管理](https://img-blog.csdnimg.cn/direct/8f20e352fa2d4de6b09b6e9cd1ece0c9.png)