1.开场白
上一期讲了 TF-IDF 的底层原理,简单讲了一下它可以将文本转为向量形式,并搭配相应分类器做文本分类,且即便如今的企业实践中也十分常见。详情请见我的上一篇文章 从One-Hot到TF-IDF(点我跳转)
光说不练假把式,在这篇文章中,你更加深刻了解TF-IDF是如何做文本分类的。具体有:
- 使用sklearn库进行TFIDF向量化
- 使用不同的分类器(SVM, 随机森林, XGBoost)做文本分类
- 搭配不同分类器的效果如何?
在开始之前推荐一个Github的开源项目。里面有很多开源数据集,很适合新手去探索 --> NLP民工乐园(本篇文章的数据集也是取自这里)
2.原理
1.TFIDF
TFIDF的原理虽然之前已经介绍了,但是这里还是简单讲一下好了。
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的加权技术,用于评估一个词在文档中的重要程度。它由两部分组成:
1. 词频(Term Frequency, TF)
衡量一个词在当前文档中出现的频率:
T F ( t , d ) = f t , d ∑ t ′ ∈ d f t ′ , d TF(t, d) = \frac{f_{t,d}}{\sum_{t' \in d} f_{t',d}} TF(t,d)=∑t′∈dft′,dft,d
其中:
- f t , d f_{t,d} ft,d:词 t t t 在文档 d d d 中的出现次数
- ∑ t ′ ∈ d f t ′ , d \sum_{t' \in d} f_{t',d} ∑t′∈dft′,d:文档 d d d 中所有词的出现次数总和
2. 逆文档频率(Inverse Document Frequency, IDF)
衡量一个词的普遍重要性(在多少文档中出现):
I D F ( t , D ) = log ( N ∣ { d ∈ D : t ∈ d } ∣ ) IDF(t, D) = \log \left( \frac{N}{|\{d \in D : t \in d\}|} \right) IDF(t,D)=log(∣{d∈D:t∈d}∣N)
其中:
- N N N:语料库中文档的总数
- ∣ { d ∈ D : t ∈ d } ∣ |\{d \in D : t \in d\}| ∣{d∈D:t∈d}∣:包含词 t t t 的文档数量
3. TF-IDF 最终公式
将TF和IDF相乘得到最终权重:
T F - I D F ( t , d , D ) = T F ( t , d ) × I D F ( t , D ) TF\text{-}IDF(t, d, D) = TF(t, d) \times IDF(t, D) TF-IDF(t,d,D)=TF(t,d)×IDF(t,D)
4. 变体说明
实际应用中可能存在不同变体,例如:
- TF变体:对数缩放 T F = log ( 1 + f t , d ) TF = \log(1 + f_{t,d}) TF=log(1+ft,d)
- IDF变体:避免除零 I D F = log ( N 1 + n t ) + 1 IDF = \log(\frac{N}{1 + n_t}) + 1 IDF=log(1+ntN)+1
- 归一化:对文档向量进行L2归一化
2.SVM
全名支持向量机,简称SVM,在2000年前后的CPU时代,它也曾是顶流。
具体原理见我的另一篇文章,这是一篇背书于《统计学习方法》的、用严谨的数学进行SVM推导的文章 --> 支持向量机
之所以他曾是顶流,主要因为它具备如下优势:
- SVM不存在现代深度学习反向传播的过拟合
- 小样本数据集上表现良好
- CPU环境下就能训练、推理,边缘设备(普通电脑)上也能跑起来
- 数学背景好,理论严谨
但是现在又被“淘汰”了,原因有:
- 大数据时代,SVM拓展性不足,数据量庞大的情况下训练很慢,相反深度学习可以利用GPU的并行,加速推理
- 泛化能力有限,SVM需要手动特征,而深度学习可以端到端自动学习特征
- 非线性场景能力有限,即便有核技巧处理非线性场景,但是函数选择和调参比较麻烦。
- 深度学习可以叠的很深,可以学习到数据中更加抽象、深层的信息,但SVM与之相比是浅层模型,学习到的信息有限。
关于支持向量机的作者 Vapnik,他还和现任人工智能的三驾马车 LeCun 有一段有趣的轶事,他们两个同为贝尔实验室的同事,因为学术之争处处不合。后来他们两位之间的争论某种意义上来说也代表了传统机器学习和深度学习之间的对碰。具体请见我的另一篇文章 自然语言处理发展史(点我跳转)
3.XGBoost
XGBoost 是梯度提升树GBDT的改良版,他们都是树模型的一种。
什么?你问我什么是树模型?好吧,这里我来解答一下,其实树模型是决策树类模型的简称,业内常常管决策树类的模型叫输模型。
至于决策树模型,可以见我另一篇文章 决策树(点我跳转)
跳转文章讲了决策树模型的基本原理,从纯数学的角度出发,带你理解决策树模型。
有了决策树的基础,理解GBDT和XGBoost就不是问题了。
那么让我们先了解GBDT,再看一看他是如何从GBDT过渡到XGBoost的吧
1.GBDT(梯度提升树)
GBDT(Gradient Boosting Decision Tree)的核心思想是通过加法模型(Additive Model)将多个弱分类器(通常是决策树)的预测结果逐步累加,从而逼近真实值。
具体来说, 每一轮迭代都会训练一个新的弱分类器,使其拟合当前模型的负梯度(即残差的近似),而非直接拟合残差本身。
这里的“残差”可以理解为当前模型的预测值与真实值之间的误差方向,而GBDT通过梯度下降的策略逐步减少这一误差。
如图,Y = Y1 + Y2 + Y3

举一个非常简单的例子,比如我今年30岁了,但计算机或者模型GBDT并不知道我今年多少岁,那GBDT咋办呢?
它会在第一个弱分类器(或第一棵树中)随便用一个年龄比如20岁来拟合,然后发现误差有10岁;
接下来在第二棵树中,用6岁去拟合剩下的损失,发现差距还有4岁;
接着在第三棵树中用3岁拟合剩下的差距,发现差距只有1岁了;
最后在第四课树中用1岁拟合剩下的残差,完美。
最终,四棵树的结论加起来,就是真实年龄30岁。
实际工程中,gbdt是计算负梯度,用负梯度近似残差.
那么为什么用负梯度近似残差呢?
回归任务下,GBDT 在每一轮的迭代时对每个样本都会有一个预测值,此时的损失函数为均方差损失函数,
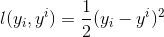
那此时的负梯度是这样计算的
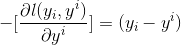
所以,当损失函数选用均方损失函数时,每一次拟合的值就是(真实值 - 当前模型预测的值),即残差。
此时的变量是
y
i
y^i
yi,即“当前预测模型的值”,也就是对它求负梯度。
2.XGBoost(极度梯度提升)
核心思想如图
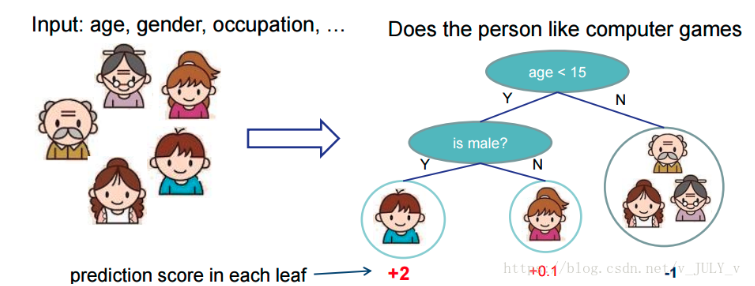

(作者陈天奇大佬的原图)
可以看到,男孩的计算得分是两个树的相加 2+0.9=2.9
这不和GBDT一样么!
确实,如果不考虑工程实现、解决问题上的一些差异,xgboost与gbdt比较大的不同就是目标函数的定义。
xgboost的目标函数如下图所示:
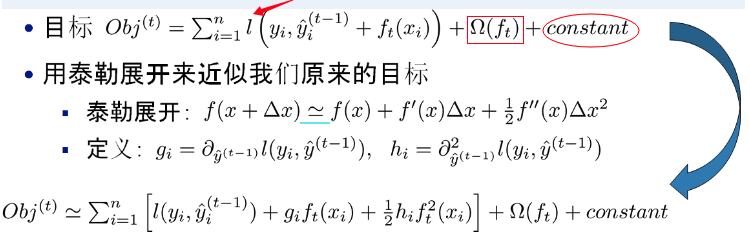

XGBoost的核心算法思想不难,基本就是:
- 不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数f(x),去拟合上次预测的残差。
- 当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数
- 最后只需要将每棵树对应的分数加起来就是该样本的预测值。
为什么XGBoost要用泰勒展开,优势在哪里?
XGBoost使用了一阶和二阶偏导, 二阶导数有利于梯度下降的更快更准. 使用泰勒展开取得函数做自变量的二阶导数形式, 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算, 本质上也就把损失函数的选取和模型算法优化/参数选择分开了. 这种去耦合增加了XGBoost的适用性, 使得它按需选取损失函数, 可以用于分类, 也可以用于回归。
3.数据集
该篇文章数据集地址 酒店评论 (也出自开头推荐的那个Github开源项目里)
该数据集是一个酒店评价数据集,有两个字段:
- review为用户评论
- label为情感的正负类标签,其中1为正面情绪,0为负面情绪
数据集预览

4.技术实践
1.sklearn中的使用TFIDF
前提:安装sklearn
pip install scikit-learn
在 scikit-learn (sklearn) 中,TfidfVectorizer 是用于 TF-IDF文本特征提取的主要类。它属于 sklearn.feature_extraction.text 模块,主要用于将文本数据转换为数值特征矩阵
下面讲一下它的关键参数吧~
stop_words{‘english’}, list, default=Nonengram_range: tuple (min_n, max_n)` default=(1, 1)
a. 要提取的不同n-gram的n值范围的下限和上限。将使用min_n<=n<=max_n的所有n值。max_dffloat or int, default=1.0:
i. 在构建词汇表时,忽略文档频率严格高于给定阈值的术语(特定于语料库的停用词)。如果在[0.0,1.0]范围内,则该参数表示文档的比例,即整数绝对计数。如果词汇表不是None,则忽略此参数。min_dffloat or int, default=1
i. 在构建词汇表时,忽略文档频率严格低于给定阈值的术语。这个值在文献中也被称为截止值。如果浮点数在[0.0,1.0]的范围内,则该参数表示文档的比例,即整数绝对计数。如果词汇表不是None,则忽略此参数。max_featuresint, default=None
i. 如果不是None,则构建一个词汇表,只考虑语料库中按词频排序的顶级max_features。否则,将使用所有功能。
如果词汇表不是None,则忽略此参数。smooth_idfbool, default=True
i. 通过在文档频率上加1来平滑idf权重,就像看到一个额外的文档包含集合中的每个术语一样。sublinear_tfbool, default=False
i. 应用亚线性tf缩放,即将 tf 替换为1 + log(tf)。
tfidf = TfidfVectorizer(
max_features=5000,
stop_words=stopwords,
ngram_range=(1,2),
min_df=3, # 过滤低频词
max_df=0.9, # 过滤高频词
# sublinear_tf=True, # 对数平滑,降低词频影响
)
X = tfidf.fit_transform(train_df['processed_text'])
- 总结
a. 注意调整ngram_range和max_features。直接对效率和特征表示能力相关联。
2.XGBoost
前提:安装XGBoost
pip install xgboost
下面讲讲xgboost的使用吧
1. 通用参数:
宏观函数控制 在 xgboost.config_context() 设置
a. verbosity: Valid values of 0 (silent), 1 (warning), 2 (info), and 3 (debug).
2. 一般参数:
a. booster [default= gbtree ]。使用哪种助推器。可以是gbtree、gblinear或dart;gbtree和dart使用基于树的模型,而gblinear使用线性函数。
b. device [default= cpu]
c. nthread [如果未设置,则默认为可用的最大线程数]
3. Booster 参数
a. eta [default=0.3, alias(别名): learning_rate]
b. gamma [default=0, alias: min_split_loss][0,∞]
- 在树的叶子节点上进行进一步分区所需的最小损失减少。gamma越大,算法就越保守。请注意,没有进行分割的树可能仍然包含一个非零分数的终端节点。
c. max_depth [default=6][0,∞]
- 树的最大深度。增加此值将使模型更加复杂,更有可能过度拟合。0表示深度没有限制。请注意,XGBoost在训练深层树时会大量消耗内存。精确树方法需要非零值。
d. min_child_weight [default=1][0,∞]
- 孩子结点所需实例权重的最小总和。如果树分区步骤导致叶节点的实例权重之和小于min_child_weight,则构建过程将放弃进一步的分区。在线性回归任务中,这只对应于每个节点中需要的最小实例数。min_child_weight越大,算法就越保守。
e. subsample [default=1]
- 训练实例的子样本比率。将其设置为0.5意味着XGBoost将在种植树木之前随机采样一半的训练数据。这将防止过拟合。子采样将在每次增强迭代中发生一次。
f. lambda [default=1, alias: reg_lambda]
- 权重的L2正则化项。增加此值将使模型更加保守。range: [0, ∞]
g. alpha [default=0, alias: reg_alpha]
- 权重上的L1正则化项。增加此值将使模型更加保守。range: [0, ∞]
h. tree_method string [default= auto] auto, exact, approx, hist
- auto: 与hist-tree方法相同。
- exact: 精确贪婪算法。枚举所有拆分的候选人。
- approx:使用分位数草图和梯度直方图的近似贪婪算法。
- hist: 更快的直方图优化近似贪婪算法。
i. scale_pos_weight [default=1]
- 控制正负权重的平衡,对不平衡的类很有用。需要考虑的典型值:sum(负实例)/sum(正实例)。
4. 特定学习任务参数
指定学习任务和相应的学习目标。目标选项如下
objective[default=reg:squarederror]
a.reg:squarederror: 平方误差:损失平方的回归
b.reg:squaredlogerror: 平方对数误差:具有平方对数损失的回归。所有输入标签都必须大于-1
c.reg:logistic: 逻辑回归,输出概率
d. reg:pseudohubererror:伪Huber误差:使用伪Huber损失的回归,这是绝对损失的两次可微替代方案。
e.reg:absoluteerror: 绝对误差:L1误差回归。当使用树模型时,在树构建后刷新叶值。如果在分布式训练中使用,叶值将作为所有工人的平均值计算,这并不能保证是最优的。
f.reg:quantileerror:分位数损失,也称为弹球损失。
g.binary:logistic: 二元逻辑回归:用于二元分类的逻辑回归,输出概率
h.binary:logitraw: 二元分类的逻辑回归,逻辑转换前的输出分数
i. binary:hinge:二元分类的铰链损失。这使得预测为0或1,而不是产生概率。
j.multi:softmax: 设置XGBoost使用softmax目标进行多类分类,还需要设置num_class(类的数量)
k.multi:softprob: 与softmax相同,但输出一个 ndatanclass 向量,该向量可以进一步整形为ndatanclass矩阵。结果包含每个数据点属于每个类的预测概率。- eval_metric [default according to objective] :验证数据的评估指标,将根据目标分配默认指标(回归的rmse,分类的logloss,排名的平均精度:映射等)
a.rmse: 均方根误差
b.mae: 平均绝对误差
c.logloss: 负对数似然
d.auc: ROC曲线下与坐标轴围成的面积。可用于分类和学习任务排名。- 用于二分类时,目标函数应为binary:logistic或类似的处理概率的函数。
- 用于多分类时,目标函数应为multi:softprob而非multi:softmax,因为后者不输出概率。AUC通过1对其余类计算,参考类由类别比例加权。
- 当输入数据集只包含负样本或正样本时,输出为NaN。具体行为取决于实现,例如scikit-learn会返回0.5。
5. XGBoost调优
1.控制过拟合
当你观察到训练精度很高,但测试精度很低时,很可能会遇到过拟合问题
在XGBoost中,通常有两种方法可以控制过拟合:
第一种方法是直接控制模型的复杂性。
a. 包括 max_depth, min_child_weight and gamma.
第二种方法是增加随机性,使训练对噪声具有鲁棒性。
a. 包括 subsample and colsample_bytree
b. 您还可以减小步长 eta。执行此操作时,请记住增加num_round
2.处理不平衡数据集
数据集非常不平衡。这会影响XGBoost模型的训练,有两种方法可以改进它。
- 如果你只关心预测的整体性能指标(AUC)
- 通过
scale_pos_weight平衡正负权重
- 通过
- 如果你关心预测正确的概率
- 将参数
max_delta_step设置为有限数(比如1)以帮助收敛
- 将参数
5.使用TFIDF做特征,用SVM或XGBoost做分类器,做酒店评价的情感分析

1.分词
ps:由于中文和英文不一样,英文会天然的使用空格进行分词,但是中文的一句话是连贯的。如:
英文:I want to go to Beijing.
中文:我想去北京。
如果把英语交给模型,模型收到的是 ["I", "want", "to", "go", "to", "Beijing", "."],总共6个词。
但是如果把中文交给模型,模型收到的是 我想去北京。,总共1个词。
故在NLP中,中文领域都是要分词的。
但是中文如果直接以“字”分词,效果可能很可能不好,因为中文是以词为单位的。如 北京 (一个词)和 北、京 (两个字)是两个完全不同的概念。
如果是传统的机器学习文本分类,如SVM和XGBoost通常是采用 Jieba 库来进行分词的。
关于这个库我以后会专门出一篇文章来讲。
总之,在这篇文章中先不考虑jieba的原理,你只需要知道他可以进行如下方式的分词即可。
text = "我要去北京。"
print(jieba.lcut(text))#
# ['我要', '去', '北京', '。']
1.这里使用的是
lcut而不是cut,是因为方便打印展示,lcut会直接返回list(迭代器),而cut会返回一个生成器<generator object Tokenizer.cut at 0x164a07a00>.
2.其实业务中大多还是采用生成器cut的形式,因为生成器是惰性迭代计算的,内存效率高。
简单解释一下生成器和迭代器的区别。
生成器 vs 迭代器(列表)(以"我要去北京。"为例):
列表:像把所有分词结果装进盒子
lcut(“我要去北京。”) → 直接给你 [‘我要’, ‘去’, ‘北京’, ‘。’]
生成器:像现用现做的流水线
cut(“我要去北京。”) → 需要时才一个个生成:
‘我要’ → ‘去’ → ‘北京’ → ‘。’
区别:
列表:一次性全做好(占内存,但能反复用)
生成器:用的时候才做(省内存,但只能用一次)
(如果同学不理解生成器和列表的区别,可以评论或留言,我会迅速转门出一篇文章来阐述他俩的区别)
2.使用SVM做分类器
import time
import pandas as pd
import jieba
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
from sklearn.metrics import classification_report
# 记录总开始时间
total_start = time.time()
# 1. 数据加载
print("1. 正在加载数据...")
start = time.time()
data = pd.read_csv('/Users/zhangqingjie/Downloads/ChnSentiCorp_htl_all.csv') # 替换为你的文件路径
print(f"数据加载完成,用时: {time.time() - start:.2f}秒")
print(f"数据样本数: {len(data)}")
# 2. 中文分词
print("\n2. 正在进行中文分词...")
start = time.time()
def chinese_tokenizer(text):
return ' '.join(jieba.cut(text))
data['review'] = data['review'].fillna('')
data['tokenized_review'] = data['review'].apply(chinese_tokenizer)
print(f"分词完成,用时: {time.time() - start:.2f}秒")
# 3. 数据划分
print("\n3. 正在划分训练集和测试集...")
start = time.time()
X_train, X_test, y_train, y_test = train_test_split(
data['tokenized_review'],
data['label'],
test_size=0.2,
random_state=42,
shuffle=True
)
print(f"数据划分完成,用时: {time.time() - start:.2f}秒")
print(f"训练集大小: {len(X_train)}, 测试集大小: {len(X_test)}")
# 4. TF-IDF特征提取
print("\n4. 正在进行TF-IDF特征提取...")
start = time.time()
tfidf = TfidfVectorizer(max_features=5000)
X_train_tfidf = tfidf.fit_transform(X_train)
X_test_tfidf = tfidf.transform(X_test)
print(f"TF-IDF特征提取完成,用时: {time.time() - start:.2f}秒")
print(f"特征维度: {X_train_tfidf.shape[1]}")
# 5. SVM模型训练
print("\n5. 正在训练SVM模型...")
start = time.time()
svm_model = SVC(kernel='linear', random_state=42)
svm_model.fit(X_train_tfidf, y_train)
print(f"SVM模型训练完成,用时: {time.time() - start:.2f}秒")
# 6. 模型评估
print("\n6. 正在评估模型...")
start = time.time()
y_pred = svm_model.predict(X_test_tfidf)
print("分类报告:")
print(classification_report(y_test, y_pred))
print(f"模型评估完成,用时: {time.time() - start:.2f}秒")
# 总用时
print(f"\n总用时: {time.time() - total_start:.2f}秒")
最终效果
分类报告:
precision recall f1-score support
0 0.84 0.76 0.80 505
1 0.89 0.93 0.91 1049
accuracy 0.88 1554
macro avg 0.87 0.85 0.86 1554
weighted avg 0.88 0.88 0.88 1554
3.使用XGBoost做分类器
import time
import pandas as pd
import jieba
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from xgboost import XGBClassifier
from sklearn.metrics import classification_report
# 记录总开始时间
total_start = time.time()
# 1. 数据加载
print("1. 正在加载数据...")
start = time.time()
data = pd.read_csv('/Users/zhangqingjie/Downloads/ChnSentiCorp_htl_all.csv') # 替换为你的文件路径
print(f"数据加载完成,用时: {time.time() - start:.2f}秒")
print(f"数据样本数: {len(data)}")
# 2. 中文分词
print("\n2. 正在进行中文分词...")
start = time.time()
def chinese_tokenizer(text):
return ' '.join(jieba.cut(text))
data['review'] = data['review'].fillna('')
data['tokenized_review'] = data['review'].apply(chinese_tokenizer)
print(f"分词完成,用时: {time.time() - start:.2f}秒")
# 3. 数据划分
print("\n3. 正在划分训练集和测试集...")
start = time.time()
X_train, X_test, y_train, y_test = train_test_split(
data['tokenized_review'],
data['label'],
test_size=0.2,
random_state=42,
shuffle=True
)
print(f"数据划分完成,用时: {time.time() - start:.2f}秒")
print(f"训练集大小: {len(X_train)}, 测试集大小: {len(X_test)}")
# 4. TF-IDF特征提取
print("\n4. 正在进行TF-IDF特征提取...")
start = time.time()
tfidf = TfidfVectorizer(max_features=5000)
X_train_tfidf = tfidf.fit_transform(X_train)
X_test_tfidf = tfidf.transform(X_test)
print(f"TF-IDF特征提取完成,用时: {time.time() - start:.2f}秒")
print(f"特征维度: {X_train_tfidf.shape[1]}")
# 5. XGBoost模型训练
print("\n5. 正在训练XGBoost模型...")
start = time.time()
xgb_model = XGBClassifier(
n_estimators=100,
max_depth=6,
learning_rate=0.1,
random_state=42,
use_label_encoder=False,
eval_metric='logloss'
)
xgb_model.fit(X_train_tfidf, y_train)
print(f"XGBoost模型训练完成,用时: {time.time() - start:.2f}秒")
# 6. 模型评估
print("\n6. 正在评估模型...")
start = time.time()
y_pred = xgb_model.predict(X_test_tfidf)
print("分类报告:")
print(classification_report(y_test, y_pred))
print(f"模型评估完成,用时: {time.time() - start:.2f}秒")
# 总用时
print(f"\n总用时: {time.time() - total_start:.2f}秒")
效果如下:
precision recall f1-score support
0 0.82 0.65 0.73 505
1 0.85 0.93 0.89 1049
accuracy 0.84 1554
macro avg 0.84 0.79 0.81 1554
weighted avg 0.84 0.84 0.84 1554
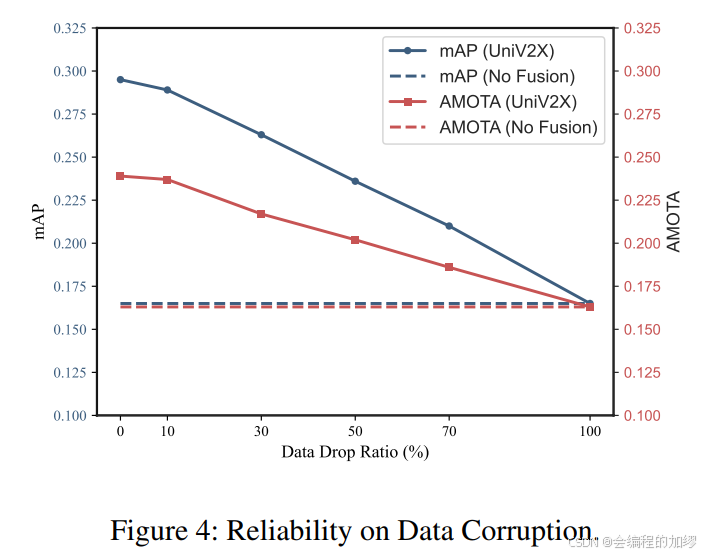
4.效果对比
| 模型 | 类别 | 精确率 | 召回率 | F1分数 | 准确率 |
|---|---|---|---|---|---|
| SVM | 0 | 0.84 | 0.76 | 0.80 | 0.88 |
| 1 | 0.89 | 0.93 | 0.91 | ||
| XGBoost | 0 | 0.82 | 0.65 | 0.73 | 0.84 |
| 1 | 0.85 | 0.93 | 0.89 |
看起来SVM更胜一筹啊。
调调参,尝试抢救一下XGBoost
xgb_model = XGBClassifier(
n_estimators=800,
max_depth=8,
subsample=0.8, # 每棵树随机采样80%数据
learning_rate=0.03,
random_state=42,
use_label_encoder=False,
objective='binary:logistic',
eval_metric='logloss'
)
现在效果如下
分类报告:
precision recall f1-score support
0 0.82 0.73 0.77 505
1 0.88 0.92 0.90 1049
accuracy 0.86 1554
macro avg 0.85 0.82 0.83 1554
weighted avg 0.86 0.86 0.86 1554
貌似还是差点意思。。。
6. 总结与收获
通过本篇文章的实践,我们系统地学习了如何使用TF-IDF结合不同分类器进行文本分类任务。以下是本次实践的核心收获:
5.1 关键技术掌握
-
TF-IDF特征提取
- 熟练使用sklearn的
TfidfVectorizer进行文本向量化 - 理解了
max_features、ngram_range等关键参数对特征空间的影响 - 掌握了中文分词处理技巧
- 熟练使用sklearn的
-
分类器应用对比
- 实现了SVM和XGBoost两种主流分类器
- 观察到SVM在本任务中表现略优(88% vs 86%准确率)
- 实践了XGBoost的参数调优过程
-
完整Pipeline构建
- 从数据加载、预处理到模型训练评估的全流程实践
- 掌握了文本分类任务的标准化开发流程
5.2 实践洞见
-
SVM的优势显现
- 在小规模文本数据上,SVM展现出更好的分类性能
- 特别是对负类(差评)的识别更准确(F1 0.80 vs 0.77)
- 验证了SVM在高维稀疏特征上的优势
-
XGBoost的调参经验
- 通过调整n_estimators、learning_rate等参数提升效果
- 发现树模型需要更精细的参数调整才能达到理想效果
- 证明了boosting算法在文本分类中的适用性
-
特征工程的关键性
- TF-IDF作为基础特征提取方法仍然非常有效
- 中文分词质量直接影响最终分类效果
- 特征维度控制(max_features)对模型效率影响显著
思考题🤔
-
在本实验中,SVM在文本分类任务上表现略优于XGBoost(88% vs 86%准确率)。结合文章提到的原理,你认为可能是什么原因导致的?如果数据集规模扩大10倍,结果可能会发生怎样的变化?为什么?
-
TF-IDF的ngram_range没有特别指定,其实内部是采用默认值的
tfidf = TfidfVectorizer(max_features=5000, ngram_range=(1,1)),(即仅使用单词)。如果将其改为(1,2)(包含单词和双词组合),你认为会对分类效果产生什么影响?尝试修改代码并观察结果,验证你的猜想。
下期预告🚀
现在的NLP模型大多是预训练语言模型BERT类和GPT的衍生,你知道最初的预训练语言模型是什么样的么?
在 Transformer 和注意力机制崛起之前,Word2Vec 率先用『词向量』颠覆了传统 NLP——它让单词不再是孤立的符号,而是蕴含语义的数学向量。
下一期将深入拆解:
🔹 为什么Word2Vec是预训练模型的雏形
🔹 CBOW和Skip-Gram究竟有什么区别?
🔹 GloVe、FastText 等变体如何改进 Word2Vec?