案例1:搜索引擎日志分析
数据来源:使用搜狗实验室提供的【用户查询日志】数据。使用Saprk框架,将数据封装到RDD中进行数据处理分析。
数据网址:数据地址
这个地址可能过期了,需要的伙伴可以私聊博主。
数据格式:
搜索时间 用户ID 搜索内容 URL返回排名 用户点击顺序 用户点击的URL
23:00:03 43080219994871455 c语言 1 1 http://www.xxx.cn
23:00:03 09826806962227619 IDEA 20 22 http://www.xxx.cn
业务需求:
- 1、搜索关键词统计(中文分词)
- 我们通过Python中的jieba框架实现中文分词操作
- 2、用户搜索点击统计
- 3、搜索时间端统计
jieba中文分词框架
入门使用
通过pip进行安装
因为前面我们都是使用 Anaconda环境,所以在进入Anaconda安装jieba
conda activate pyspark # 进入虚拟环境
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple # 安装jieba
# -i https://pypi.tuna.tsinghua.edu.cn/simple 指定国内镜像源
因为我使用的远程解释器环境,需要点击以下远程解释器,更新解释器环境内置的库。
代码示例:
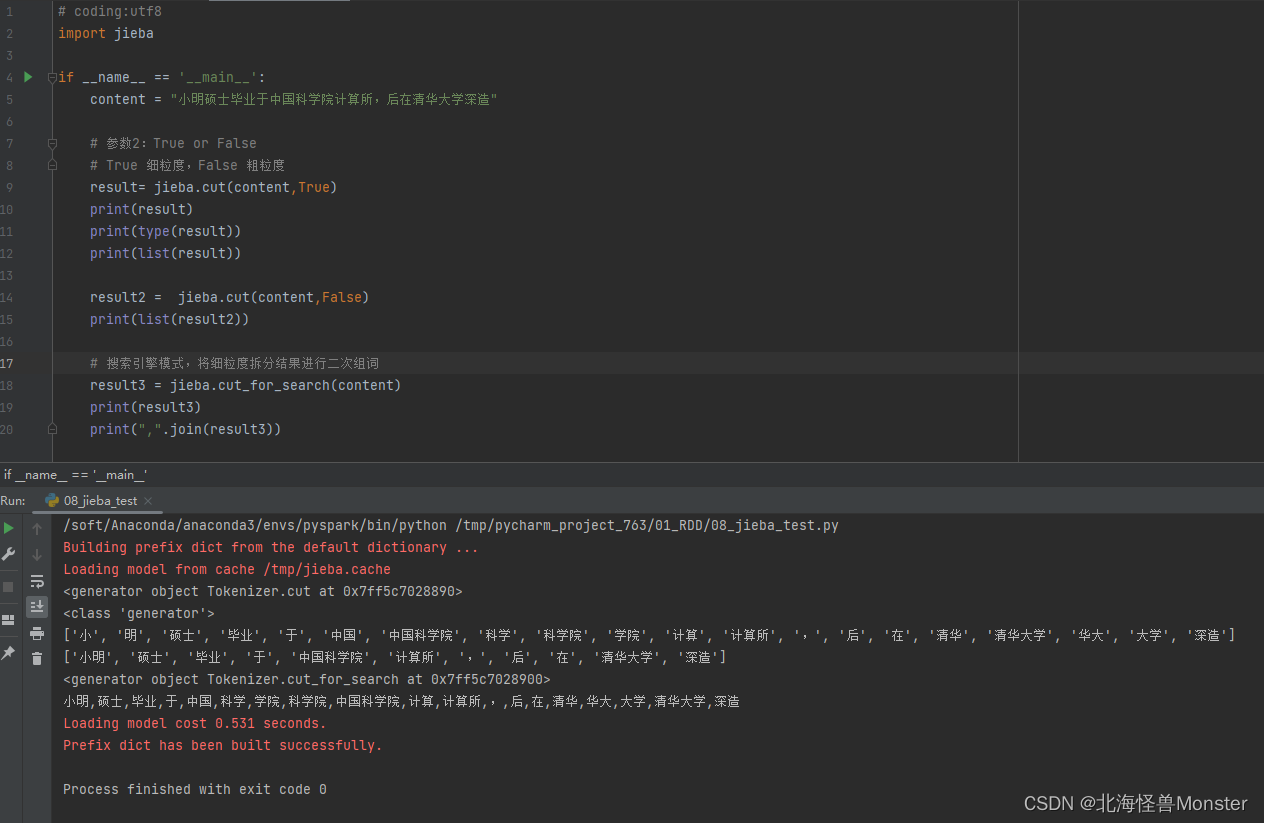
搜索引擎日志分期案例
代码:
主函数
# coding:utf8
import operator
from pyspark import SparkConf, SparkContext
from pyspark.storagelevel import StorageLevel
from defs import context_jieba, filter_words, append_words, extract_user_and_word
from operator import add
if __name__ == '__main__':
# 0. 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 1. 读取数据文件
file_rdd = sc.textFile("../../data/SogouQ.txt") # '23:00:02\t8181820631750396\titheima\t5\t2\thttp://www.itcast.cn'
# 2. 对数据进行切分
split_rdd = file_rdd.map(
lambda x: x.split("\t")) # ['08:00:22', '44801909258572364', 'hadoop', '1', '2', 'http://www.itcast.cn']
# 3. 因为要做多个需求,split_rdd 作为基础rdd 会被多次使用,所以进行持久化操作
split_rdd.persist(StorageLevel.DISK_ONLY)
# TODO:需求1:用户搜索的关键词分析(wordCount)
# 取出搜索内容
context_rdd = split_rdd.map(lambda x: x[2])
# 对搜索内容进行分词
words_rdd = context_rdd.flatMap(context_jieba)
# print(words_rdd)
# 分词结果和实际有出入,所以还需要手动处理结果
# 院校 帮 -> 院校帮
# 博学 谷 -> 博学谷
# 传智播 客 -> 传智播客
# 将单个词 帮,谷,客过滤,最后直接替换为词条
filtered_rdd = words_rdd.filter(filter_words)
final_words_rdd = filtered_rdd.map(append_words)
# 对单词进行排序,求出前五
result1 = final_words_rdd.reduceByKey(lambda a, b: a + b).sortBy(lambda x: x[1], ascending=False,
numPartitions=1).take(5)
print("需求1结果:", result1)
# TODO 需求2:用户和关键词组合分析
# 用户id,我喜欢hadoop
# 用户id+喜欢 用户id+hadoop 这样可以知道用户搜索频率
user_content_rdd = split_rdd.map(lambda x: (x[1], x[2]))
# 对用户搜索内容进行分词
user_word_with_one_rdd = user_content_rdd.flatMap(extract_user_and_word)
# 对内容进行分组聚合,排序,求前五
result2 = user_word_with_one_rdd.reduceByKey(lambda a, b: a + b). \
sortBy(lambda x: x[1], ascending=False, numPartitions=1). \
take(5)
print("需求2结果:", result2)
# TODO 需求3:热门搜索时间段分析
# 取出所有的时间
time_rdd = split_rdd.map(lambda x: x[0])
# 对时间进行处理,只保留小时精度即可
hour_with_one_rdd = time_rdd.map(lambda x: (x.split(":")[0], 1))
# lambda a, b: a + b 这个一直写很烦,python的operator包中提供了 加减乘除都有
result3 = hour_with_one_rdd.reduceByKey(operator.add).\
sortBy(lambda x:x[1],ascending=False,numPartitions=1).\
collect()
print("需求3结果:", result3)
defs.py文件
# coding:utf8
import jieba
def context_jieba(data):
"""jieba分词工具"""
seg = jieba.cut_for_search(data)
l = list()
for word in seg:
l.append(word)
return l
def filter_words(data):
"""过滤不要的词"""
return data not in ["谷", "帮", "客"]
def append_words(data):
"""修订关键词内容"""
if data == '传智播': data = '传智播客'
if data == '博学': data = '博学谷'
if data == '院校': data = '院校帮'
return (data, 1)
def extract_user_and_word(data):
"""传入数据格式:(用户id,我喜欢hadoop)"""
user_id = data[0]
content = data[1]
# 对content进行分词
words = context_jieba(content)
return_list = list()
for word in words:
# 过滤 ["谷", "帮", "客"]
if filter_words(word):
return_list.append((user_id + "_" + append_words(word)[0] , 1))
return return_list
提交代码到YARN集群运行
1、修改主文件
# conf = SparkConf().setAppName("test").setMaster("local[*]")
conf = SparkConf().setAppName("test")
# file_rdd = sc.textFile("../../data/SogouQ.txt")
file_rdd = sc.textFile("hdfs://node1:8020/input/SoguoQ.txt")
2、将两个文件上传到Linux中
3、因为代码中使用jieba库,所以所有的机器都应该安装jieba库
因为Executor运行在其他机器上时,没有jieba库会运行报错
4、执行代码
spark-submit --master yarn --py-files /root/defs.py /root/09_Demo_search.py
提交成功

普通提交成功
榨干集群性能提交
首先我们需要先查看集群的资源有多少
- 查看CPU有几核 cat /proc/cpuinfo | grep processor | wc -l
- 查看内存多大 free -g

我学习使用,只分配了1G,但是显示是0.9… ,所以是显示0,将total mem 单元格加1,就是当前机器内存
spark-submit --master yarn --py-files /root/defs.py
--executor-memory 512m # 指定每个Executor的内存
--executor-cores 1 # 指定每个Executor的可使用cpu核心数
--num-executors 3 # 指定executor总数 ,一般几台机器就指定几个
/root/09_Demo_search.py