核心问题
什么是回表?
答:
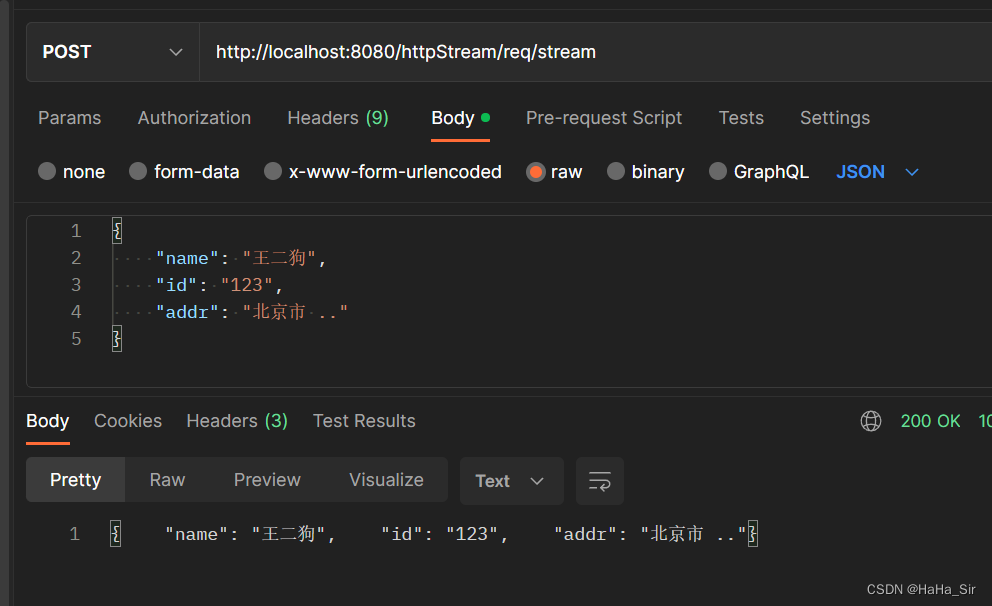
回表是一个过程,是获取到主键后再通过主键去查询数据的一个过程就叫回表。
那这个主键从哪来?
从叶子结点存储的内容来,如果存储的是非聚簇索引则通过叶子节点存储的值获取,该值就是主键。反之如果是聚簇索引则该索引就是主键,叶子几点存储的值就是具体数据内容。
一定会回表吗?
不一定,要根据查询过程中是否用到主键来判断,如果没有用到主键,只用到了其他索引,则会触发回表。
树
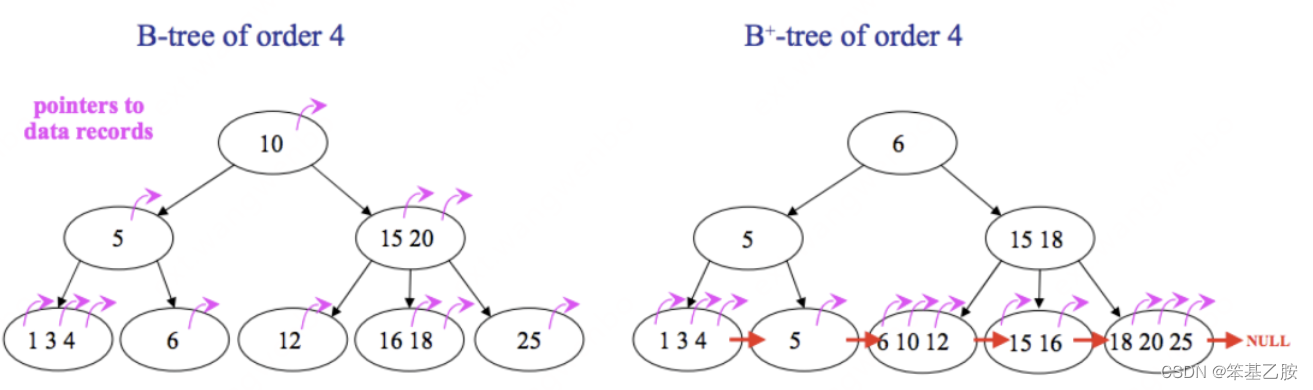
前面是 B-Tree,后面是 B+Tree,两者的区别在于:
B-Tree 中,所有节点都会带有指向具体记录的指针;B+Tree 中只有叶子结点会带有指向具体记录的指针。
B-Tree 中不同的叶子之间没有连在一起;B+Tree 中所有的叶子结点通过指针连接在一起。
B-Tree 中可能在非叶子结点就拿到了指向具体记录的指针,搜索效率不稳定;B+Tree 中,一定要到叶子结点中才可以获取到具体记录的指针,搜索效率稳定。
基于上面两点分析,我们可以得出如下结论:
B+Tree 中,由于非叶子结点不带有指向具体记录的指针,所以非叶子结点中可以存储更多的索引项,这样就可以有效降低树的高度,进而提高搜索的效率。
B+Tree 中,叶子结点通过指针连接在一起,这样如果有范围扫描的需求,那么实现起来将非常容易,而对于 B-Tree,范围扫描则需要不停的在叶子结点和非叶子结点之间移动。
索引类型
MySQL 中的索引有很多中不同的分类方式,可以按照数据结构分,可以按照逻辑角度分,也可以按照物理存储分,其中,按照物理存储方式,可以分为聚簇索引和非聚簇索引。
我们日常所说的主键索引,其实就是聚簇索引(Clustered Index);主键索引之外,其他的都称之为非主键索引,非主键索引也被称为二级索引(Secondary Index),或者叫作辅助索引。
对于主键索引和非主键索引,使用的数据结构都是 B+Tree,唯一的区别在于叶子结点中存储的内容不同:
主键索引的叶子结点存储的是一行完整的数据。
非主键索引的叶子结点存储的则是主键值。
这就是两者最大的区别。
所以,当我们需要查询的时候:
如果是通过主键索引来查询数据,例如 select * from user where id=100,那么此时只需要搜索主键索引的 B+Tree 就可以找到数据。
如果是通过非主键索引来查询数据,例如 select * from user where username=‘javaboy’,那么此时需要先搜索 username 这一列索引的 B+Tree,搜索完成后得到主键的值,然后再去搜索主键索引的 B+Tree,就可以获取到一行完整的数据。
对于第二种查询方式而言,一共搜索了两棵 B+Tree,第一次搜索 B+Tree 拿到主键值后再去搜索主键索引的 B+Tree,这个过程就是所谓的回表。
从上面的分析中我们也能看出,通过非主键索引查询要扫描两棵 B+Tree,而通过主键索引查询只需要扫描一棵 B+Tree,所以如果条件允许,还是建议在查询中优先选择通过主键索引进行搜索。
参考文献
https://blog.csdn.net/liujiaping/article/details/122599604
https://www.cnblogs.com/Bennyzion/p/14451807.html