机器学习笔记之生成对抗网络——逻辑介绍
- 引言
- 生成对抗网络——示例
- 生成对抗网络——数学语言描述
- 生成对抗网络——判别过程描述
引言
本节将介绍生成对抗网络的基本逻辑与数学语言描述。
生成对抗网络——示例
生成对抗网络(Generative Adversarial Networks,GAN),它采用对抗学习的方式对样本特征进行学习。这里以临摹绘画为例,对对抗学习思想进行描述。
假设我是一名绘画爱好者,我的目标是成为一个画家。要成为画家,意味着我的绘画水平需要提升至一定的高度,也就是说,我画出的画需要得到他人的肯定、认可。
我们首先需要学习大师们的名画,通过对名画进行临摹,从而提升我的绘画水平。在锻炼自身的绘画水平的同时,我们自然不能闭门造车——自己觉得临摹的像。我们需要将自己的画给鉴赏家们鉴赏。这种鉴赏无非有两种对立方向的结果:
- 一种方向是 临摹的太差,鉴赏家一眼就能看出哪一幅是你画的,哪一幅是大师画的;
- 另一种方向是 临摹技术非常过硬。两张画放在鉴赏家面前,他没有办法分辨出哪一幅是你画的,哪一幅是大师画的,完全可以以假乱真。
但从鉴赏家的角度观察,如果我找了一个门外汉——他本人可能没有太高的鉴赏能力,我的画可能并不是很像,他也有可能无法分辨出来。因此我也需要找到鉴赏能力足够高的鉴赏家进行鉴别。
那鉴赏家如何去提升鉴赏能力呢?自然是多观察,学习大师们的名画来提升自身的鉴赏水平。
从上面的描述可以观察到,大师的画是客观的优秀作品,是静态不变的;而我的绘画水平,我临摹的画随着我的绘画水平的提高而变化。同时,鉴赏家的鉴别能力也随着他学习、鉴赏大师的画而提升。此时的 对抗状态 出现了:
- 我需要提升自身的绘画水平,我画出的画能够与大师的画以假乱真,从而骗过鉴赏家的眼睛;
- 鉴赏家需要提升自身的鉴赏能力,当我的画与大师的画放在一起时,需要精准地分辨出哪个是大师的画、哪个是我的画,从而尽可能地防止以假乱真的出现。
但是我们的目标是我成为高水平的画家,而鉴赏家的水平提升只是一种借助手段。只有我的画以假乱真,高水平的鉴赏专家无法分辨的前提下,我才能够成为高水平的画家。
生成对抗网络——数学语言描述
已知一个样本集合 X = { x ( i ) } i = 1 N \mathcal X = \left\{x^{(i)}\right\}_{i=1}^N X={x(i)}i=1N,该样本是真实样本,是从客观的真实分布中产生的样本。将该分布记作 P d a t a \mathcal P_{data} Pdata;根据上面的示例描述,可以将这个 P d a t a \mathcal P_{data} Pdata看作大师的画,是静态不变的。
-
生成模型(绘画爱好者) 本身需要生成样本,而生成出样本的分布记作 P g e n e \mathcal P_{gene} Pgene;可以看作是绘画爱好者临摹的作品。定义该模型的参数为 θ g e n e \theta_{gene} θgene,最终对应的概率模型可表示为 P g e n e ( x ; θ g e n e ) \mathcal P_{gene}(x;\theta_{gene}) Pgene(x;θgene):
也就是说,模型生成的样本服从概率模型分布~
x ∼ P g e n e ( x ; θ g e n e ) x \sim \mathcal P_{gene}(x;\theta_{gene}) x∼Pgene(x;θgene)需要注意的是,我们并不对 P g e n e ( x ; θ g e n e ) \mathcal P_{gene}(x;\theta_{gene}) Pgene(x;θgene)进行建模,而是通过神经网络的通用逼近定理(Universal Approximation Theorem)对 P g e n e ( x ; θ g e n e ) \mathcal P_{gene}(x;\theta_{gene}) Pgene(x;θgene)进行近似。
但纯粹的神经网络不具备随机性,也就是说,只有给定一组确定的输入信息,才能够构建计算图。以此,需要给该神经网络设计一个 输入分布 Z \mathcal Z Z。这种分布通常情况下是一些简单分布,如高斯分布:
这里的μ i n i t , Σ i n i t \mu_{init},\Sigma_{init} μinit,Σinit不是参数,这只是一个给定的简单分布。
Z ∼ N ( μ i n i t , Σ i n i t ) \mathcal Z \sim \mathcal N(\mu_{init},\Sigma_{init}) Z∼N(μinit,Σinit)
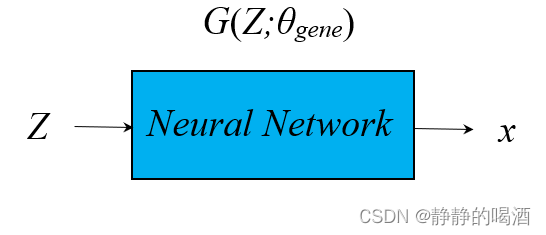
至此,定义神经网络结构为 G ( Z ; θ g e n e ) \mathcal G(\mathcal Z;\theta_{gene}) G(Z;θgene),生成过程可表示为如下形式:
x = G ( Z ; θ g e n e ) x = \mathcal G(\mathcal Z;\theta_{gene}) x=G(Z;θgene)
对应的计算图结构简单表示如下:
-
判别模型(鉴赏家) 同样通过神经网络进行描述,它的结果是一个概率分布。而该分布表示的意义是:判别样本 x x x是大师的画的概率。如果用当前环境的数学语言描述,则是“样本 x x x服从 P d a t a \mathcal P_{data} Pdata分布的概率”。记作 D ( x ; θ d ) \mathcal D(x;\theta_d) D(x;θd)。
这里的样本x x x既可以是服从P d a t a \mathcal P_{data} Pdata的样本,也可以是从生成模型P g e n e ( x ; θ g e n e ) \mathcal P_{gene}(x;\theta_{gene}) Pgene(x;θgene)中产生的样本,而D ( x ; θ d ) \mathcal D(x;\theta_d) D(x;θd)仅执行一个判别操作,并返回一个概率结果。
这意味着该概率越趋近于1 1 1,样本x x x越有可能服从于P d a t a \mathcal P_{data} Pdata;反之,样本x x x越有可能是生成模型P g e n e ( x ; θ g e n e ) \mathcal P_{gene}(x;\theta_{gene}) Pgene(x;θgene)中产生的样本。
整个生成对抗网络的计算图结构表示如下:

生成对抗网络——判别过程描述
通过观察上图,可以看到该模型架构的前向传播过程。本质上就是两个前馈神经网络。但该结构是如何进行判别并以此通过反向传播将模型参数反馈给神经网络的?对该结构的 目标函数(策略、损失函数) 进行分析:
-
从判别模型的角度观察,它的 判别能力高 主要体现在两个方面:
- 如果从 P d a t a \mathcal P_{data} Pdata中选取一个样本 x x x让判别模型 D ( x ; θ d ) \mathcal D(x;\theta_d) D(x;θd)进行判断,那么 D ( x ; θ d ) \mathcal D(x;\theta_d) D(x;θd)的返回结果更趋近于 1 1 1 方向;
- 反之,如果从生成模型 P g e n e ( x ; θ g e n e ) \mathcal P_{gene}(x;\theta_{gene}) Pgene(x;θgene)中选取一个样本 x x x让判别模型 D ( x ; θ d ) \mathcal D(x;\theta_d) D(x;θd)进行判断,那么 D ( x ; θ d ) \mathcal D(x;\theta_d) D(x;θd)的返回结果更趋近于 0 0 0 方向 。
对应数学语言可表示为:
由于D ( x ; θ d ) \mathcal D(x;\theta_d) D(x;θd)表示概率结果,因此D ( x ; θ d ) ⇓ \mathcal D(x;\theta_d) \Downarrow D(x;θd)⇓使用1 − D ( x ; θ d ) 1 - \mathcal D(x;\theta_d) 1−D(x;θd)进行表示;生成模型中的x x x可以使用x = G ( Z ; θ g e n e ) x = \mathcal G(\mathcal Z;\theta_{gene}) x=G(Z;θgene)进行替换。使用log D ( ⋅ ) \log \mathcal D(\cdot) logD(⋅)替换D ( ⋅ ) \mathcal D(\cdot) D(⋅);和极大似然估计中的‘对数似然思想’相似,并且log \log log函数是单调递增函数,并不影响D ( ⋅ ) \mathcal D(\cdot) D(⋅)的取值方向。
{ if x ∼ P d a t a ⇒ log D ( x ; θ d ) ⇑ if x ∼ P g e n e ( x ; θ g e n e ) ⇒ log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ] } ⇑ s . t . Z ∼ P ( Z ) e . g . Z ∼ N ( μ i n i t , Σ i n i t ) \begin{aligned} & \begin{cases} \text{if } x \sim \mathcal P_{data} \quad \Rightarrow \log \mathcal D(x;\theta_d) \Uparrow \\ \text{if } x \sim \mathcal P_{gene}(x;\theta_{gene}) \quad \Rightarrow \log \left\{1 - \mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\} \Uparrow \end{cases} \\ & s.t. \mathcal Z \sim \mathcal P(\mathcal Z) \quad e.g. \mathcal Z \sim \mathcal N(\mu_{init},\Sigma_{init}) \end{aligned} {if x∼Pdata⇒logD(x;θd)⇑if x∼Pgene(x;θgene)⇒log{1−D[G(Z;θgene);θd]}⇑s.t.Z∼P(Z)e.g.Z∼N(μinit,Σinit)
如果一个鉴赏家的鉴赏水平高,着意味着 log D ( x ; θ d ) \log \mathcal D(x;\theta_d) logD(x;θd)和 log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ] } \log \left\{1 - \mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\} log{1−D[G(Z;θgene);θd]} 都要高:
这里使用期望的形式对全局进行描述,因为期望与积分之间仅相差常数倍的关系,它的本质依然是‘极大似然估计’。以P d a t a \mathcal P_{data} Pdata的样本集合为例:
E x ∼ P d a t a [ log D ( x ; θ d ) ] = 1 N ∑ x ( i ) ∈ X log D ( x ( i ) ; θ d ) \mathbb E_{x \sim \mathcal P_{data}}[\log \mathcal D(x;\theta_d)] = \frac{1}{N} \sum_{x^{(i)} \in \mathcal X} \log \mathcal D(x^{(i)};\theta_d) Ex∼Pdata[logD(x;θd)]=N1x(i)∈X∑logD(x(i);θd)这里的D \mathcal D D具体是指神经网络结构D \mathcal D D内部的模型参数。通过选择合适的参数,使得期望结果最大。期望结果主要分为两个部分:一个是从P d a t a \mathcal P_{data} Pdata中采样得到的期望E x ∼ P d a t a [ log D ( x ; θ d ) ] \mathbb E_{x \sim \mathcal P_{data}} \left[\log \mathcal D(x;\theta_d)\right] Ex∼Pdata[logD(x;θd)];另一个是从初始分布P ( Z ) \mathcal P(\mathcal Z) P(Z)中采样得到的期望E Z ∼ P ( Z ) [ 1 − log { D [ G ( Z ; θ g e n e ) ; θ d ] } ] \mathbb E_{\mathcal Z \sim \mathcal P(\mathcal Z)} \left[1 - \log \left\{\mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\}\right] EZ∼P(Z)[1−log{D[G(Z;θgene);θd]}].
max D { E x ∼ P d a t a [ log D ( x ; θ d ) ] + E Z ∼ P ( Z ) [ log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ] } ] } \mathop{\max}\limits_{\mathcal D} \left\{\mathbb E_{x \sim \mathcal P_{data}} \left[\log \mathcal D(x;\theta_d)\right] + \mathbb E_{\mathcal Z \sim \mathcal P(\mathcal Z)} \left[ \log \left\{1 -\mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\}\right]\right\} Dmax{Ex∼Pdata[logD(x;θd)]+EZ∼P(Z)[log{1−D[G(Z;θgene);θd]}]}
-
从生成模型的角度观察,在判别模型能力强的前提下,想要体现样本的生成水平高只需一个要求:生成出的样本在判别模型面前,让其判别失误。
关于生成样本的正确判别标准是log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ] } ⇑ \log \left\{1 - \mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\} \Uparrow log{1−D[G(Z;θgene);θd]}⇑,那么判别失误的标准自然是log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ] } ⇓ \log \left\{1 - \mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\} \Downarrow log{1−D[G(Z;θgene);θd]}⇓对应数学语言可表示为:
同上面的逻辑描述,通过对神经网络结构G \mathcal G G内部的模型参数进行选择,使得期望结果最小。
min G { E Z ∼ P ( Z ) [ log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ] } ] } \mathop{\min}\limits_{\mathcal G} \left\{\mathbb E_{\mathcal Z \sim \mathcal P(\mathcal Z)} \left[\log \left\{1 - \mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\}\right]\right\} Gmin{EZ∼P(Z)[log{1−D[G(Z;θgene);θd]}]}
结合判别模型、生成模型两个角度,总的目标函数可表示为如下形式:
min
G
max
D
{
E
x
∼
P
d
a
t
a
[
log
D
(
x
;
θ
d
)
]
+
E
Z
∼
P
(
Z
)
[
log
{
1
−
D
[
G
(
Z
;
θ
g
e
n
e
)
;
θ
d
]
}
]
}
\mathop{\min}\limits_{\mathcal G} \mathop{\max}\limits_{\mathcal D} \left\{\mathbb E_{x \sim \mathcal P_{data}} \left[\log \mathcal D(x;\theta_d)\right] + \mathbb E_{\mathcal Z \sim \mathcal P(\mathcal Z)} \left[ \log \left\{1 -\mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\}\right]\right\}
GminDmax{Ex∼Pdata[logD(x;θd)]+EZ∼P(Z)[log{1−D[G(Z;θgene);θd]}]}
说明:
首先关于min G max D \mathop{\min}\limits_{\mathcal G} \mathop{\max}\limits_{\mathcal D} GminDmax顺序,在上面提到过,判别模型的水平提升只是一种手段,而最终目标是从生成模型中得到‘能够骗过判别模型’的优秀样本。当判别模型的判别能力足够高后,这意味着网络结构D \mathcal D D中的参数θ d \theta_d θd逐渐稳定,最终不再变化。此时的E x ∼ P d a t a [ log D ( x ; θ d ) ] \mathbb E_{x \sim \mathcal P_{data}}[\log \mathcal D(x;\theta_d)] Ex∼Pdata[logD(x;θd)]相当于一个常数结果,而常数结果不影响网络结构G \mathcal G G模型参数的选择。假设θ d \theta_d θd逐步稳定至最优解θ d ^ \hat {\theta_d} θd^,那么上述公式可表示为如下形式:
min G max D { E x ∼ P d a t a [ log D ( x ; θ d ) ] + E Z ∼ P ( Z ) [ log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ] } ] } = min G { E x ∼ P d a t a [ log D ( x ; θ d ^ ) ] ⏟ 常数 C + E Z ∼ P ( Z ) [ log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ^ ] } ] } = min G { E Z ∼ P ( Z ) [ log { 1 − D [ G ( Z ; θ g e n e ) ; θ d ] } ] } \begin{aligned} & \quad \mathop{\min}\limits_{\mathcal G} \mathop{\max}\limits_{\mathcal D} \left\{\mathbb E_{x \sim \mathcal P_{data}} \left[\log \mathcal D(x;\theta_d)\right] + \mathbb E_{\mathcal Z \sim \mathcal P(\mathcal Z)} \left[ \log \left\{1 -\mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\}\right]\right\} \\ & = \mathop{\min}\limits_{\mathcal G} \left\{\underbrace{\mathbb E_{x \sim \mathcal P_{data}} \left[\log \mathcal D(x;\hat {\theta_d})\right]}_{常数\mathcal C} + \mathbb E_{\mathcal Z \sim \mathcal P(\mathcal Z)} \left[\log \left\{1 -\mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\hat {\theta_d}]\right\}\right]\right\} \\ & = \mathop{\min}\limits_{\mathcal G} \left\{\mathbb E_{\mathcal Z \sim \mathcal P(\mathcal Z)} \left[\log \left\{1 - \mathcal D [\mathcal G(\mathcal Z;\theta_{gene}) ;\theta_d]\right\}\right]\right\} \end{aligned} GminDmax{Ex∼Pdata[logD(x;θd)]+EZ∼P(Z)[log{1−D[G(Z;θgene);θd]}]}=Gmin⎩ ⎨ ⎧常数C Ex∼Pdata[logD(x;θd^)]+EZ∼P(Z)[log{1−D[G(Z;θgene);θd^]}]⎭ ⎬ ⎫=Gmin{EZ∼P(Z)[log{1−D[G(Z;θgene);θd]}]}
这与生成模型角度的思想完全相同。
下一节将介绍关于生成对抗网络全局最优解的求解逻辑。
相关参考:
生成对抗网络1——例子
生成对抗网络2——数学描述