作者主页: 作者主页
本篇博客专栏:C++
创作时间 :2024年6月30日

前言:
本文主要介绍STL容器之一 ---- string,在学习C++的过程中,我们要将C++视为一个语言联邦(摘录于Effective C++ 条款一)。如何理解这句话呢,我们学习C++,可将其分为四个板块;分别为C、Object-Oriented C++(面向对象的C++)、Template C++(模板)、STL。本文就介绍STL中的string;
一、string是什么?
string是STL文档的容器之一,是一个自定义类型,是一个类,由类模板basic_string实例化出来的一个类;
我们看一下cplusplus上是咋介绍的?
我们简单看一下即可,下面我来为大家做介绍。

二、string的使用:
由于string出现的时间实际是早于STL的,是后来划分进STL库的,所以string开始的设计比较冗余,有许多没有必要的接口(一共106个接口函数);这也是被广大C++程序员吐槽的一个槽点,我们无需将每一个接口都记住,我们需要将核心接口记住并熟练使用,遇见一些默认的接口查看文档即可;
2.1构造函数
在C++98中,string的构造函数一种有如下7种;
int main() { // 1、无参默认构造 // string(); string s1; // 2、拷贝构造 // string (const string& str); string s2(s1); // 4、通过字符串常量初始化 // string (const char* s); string s4("hello world"); // 3、通过字符串子串初始化 // string (const string& str, size_t pos, size_t len = npos); string s3(s4, 5, 5); // 5、通过字符串前n个字符初始化 // string (const char* s, size_t n); string s5("hello wrold", 6); // 6、用n个字符c初始化字符串 // string (size_t n, char c); string s6(10, 'x'); // 7、迭代器区间初始化(暂不介绍) return 0; }其中提一下第三种,pos为子串的位置,len子串的长度,若len大于从子串pos位置开始后面字符总数,则表示初始化到子串结尾即可,比如我们要用 “hello world” 初始化字符串,若pos为6,len为20,则用world初始化字符串s1;len还有一个缺省值npos,其数值为无符号整型的-1,也就是无符号的最大值(无符号无负数);

2.2赋值重载:
赋值重载使string能够用=对string对象重新赋值,string的赋值重载一共有有如下三种;
int main() { string tmp("hello world"); string s1; string s2; string s3; // 1、string类进行赋值重载 s1 = tmp; // 2、使用字符串常量赋值重载 s2 = "hello world"; // 3、使用字符赋值重载 s3 = 'A'; return 0; }

2.3容量相关接口
首先介绍如下六个简单一些的接口;
int main() { string s1("hello world"); // string中储存的字符个数(不包括\0) cout << s1.length() << endl; // 与length功能相同 cout << s1.size() << endl; // 可以最多储存多少个字符(理论值,实际上并没有那么多) cout << s1.max_size() << endl; // string的当前容量 cout << s1.capacity() << endl; // 当前string对象是否为空 cout << s1.empty() << endl; // 清空s1中所有字符 s1.clear(); return 0; }其中的length与size两种并无相异,由于string出现的较早,当时没有STL其他容器,先出现了length,后来为了统一接口,于其他容器接口保持一致,因此出现了size;
int main() { // reserve 提前开空间(可能会大于指定的大小,因此开空间规则不同) string s1; s1.reserve(100); cout << s1.size() << endl; cout << s1.capacity() << endl; // resize 提前开空间并初始化 缺省值为0 string s2; s2.resize(100); cout << s2.size() << endl; cout << s2.capacity() << endl; s2 += "hhhhhh"; return 0; }
我们发现reserve仅仅只是修改capacity,而resize不仅会修改capacity,还会修改size,然后用第二个参数取去初始化新增的区间;当指定大小小于原来空间时,reserve什么都不会做,而resize则会则断大于指定大小后面的区域(在后面补零);
总结:reserve仅改变capacity,resize既改变capacity又改变size;当指定大小小于字符串的size时,resize还可以截断(在后面补 \0 )


2.4迭代器
迭代器是STL库中的一个特殊的存在,我们可以通过迭代器对string类中的字符进行增删查改; 在string类中,我们可将其视为指针;string类中的迭代器接口有如下几种;
begin函数返回的是字符串中第一个字符的位置的迭代器,而end函数返回的字符串中最后一个字符的下一个位置的迭代器; 因此遍历一个string类,有一下三种方法;
int main() { string s1("hello world"); // 三种遍历方式 // 1、通过[]来访问每一个字符 for (int i = 0; i < s1.size(); i++) { cout << s1[i] << " "; } cout << endl; // 2、通过迭代来来访问每一个字符 string::iterator it = s1.begin(); while (it != s1.end()) { cout << *it << " "; it++; } cout << endl; // 3、通过范围for(其实范围for就是编译器替换成了迭代器遍历的方法) for (auto ch : s1) { cout << ch << " "; } cout << endl; return 0; }rbegin与rend系列为反向迭代器;rbegin返回的是最后一个字符的位置的迭代器,rend返回的是第一个字符的前一个位置的迭代器;
我们可以通过反向迭代器,对其逆向遍历;反向迭代器的类型为 string::reverse_iterator;
int main() { string s1("hello world"); string::reverse_iterator rit = s1.rbegin(); while (rit != s1.rend()) { cout << *rit << " "; rit++; } }


2.5下标访问:
关于元素的访问,也有如下四个接口,最常用的还是方括号;
int main() { // []重载使string可以像字符数组一样访问 string s1("hello world"); cout << s1[0] << endl; cout << s1[1] << endl; // at 于[] 功能相同,只不过[]的越界是由assert来限制,而at则是抛异常 cout << s1.at(0) << endl; cout << s1.at(1) << endl; // front访问string中第一个字符 cout << s1.front() << endl; // back访问string中最后一个字符 cout << s1.back() << endl; return 0; }方括号的使用如同数组的方括号使用相同;at与方括号用法相同,只是遇见非法访问时是抛异常解决;

2.6修改
string的修改接口设计得十分冗余;其中我们可以用+=替代append与push_back;实际中,也是+=用得比较多,但是我们还是了解一下相关用法;
+=我们可以加等一个string类,可以加等一个字符,也可以加等一个字符指针;因此有以下用法;
int main() { string tmp("xxxx"); string s1("hello world"); // += 字符 s1 += ' '; // += string类 s1 += tmp; // += 字符指针 s1 += " hello world"; cout << s1 << endl; }
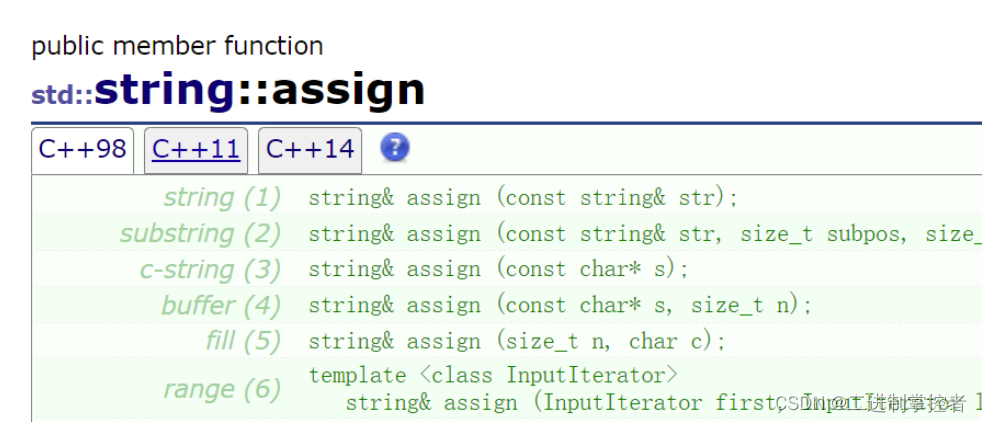
int main() { string tmp("xxxx"); string s1; // 尾加字符 // void push_back (char c); s1.push_back('c'); // 尾加string类 // string& append (const string& str); s1.append(tmp); // 尾加string从subpos位置开始的sublen个字符 //string& append (const string& str, size_t subpos, size_t sublen); s1.append(tmp, 2, 3); // 用字符指针指向的字符串/字符尾加 // string& append (const char* s); s1.append("hello world"); // 用字符指针指向的字符串的前n个字符尾加 // string& append (const char* s, size_t n); s1.append("hello world", 6); // 尾加n个c字符 // string& append (size_t n, char c); s1.append(5, 'x'); // 迭代器区间追加 // template <class InputIterator> // string& append(InputIterator first, InputIterator last); s1.append(tmp.begin(), tmp.end()); cout << s1 << endl; return 0; }assign为string的赋值函数;是一个扩增版的operator =,用的并不多,主要用法如下;
int main() { string tmp("hello world"); string s1; // 使用string类对其赋值 // string& assign (const string& str); s1.assign(tmp); cout << s1 << endl; // 使用string类中从subpos位置开始的sublen个串来赋值 // string& assign (const string& str, size_t subpos, size_t sublen); s1.assign(tmp, 2, 5); cout << s1 << endl; // 使用字符指针所指向的字符串对其赋值 // string& assign (const char* s); s1.assign("hello naiths"); cout << s1 << endl; // 使用字符指针所指向的字符串的前n个对其赋值 // string& assign (const char* s, size_t n); s1.assign("hello naiths", 7); cout << s1 << endl; // 使用n个c字符对其赋值 // string& assign (size_t n, char c); s1.assign(10, 'x'); cout << s1 << endl; // 使用迭代器对其赋值 // template <class InputIterator> // string& assign(InputIterator first, InputIterator last); s1.assign(tmp.begin(), tmp.end()); cout << s1 << endl; return 0; }
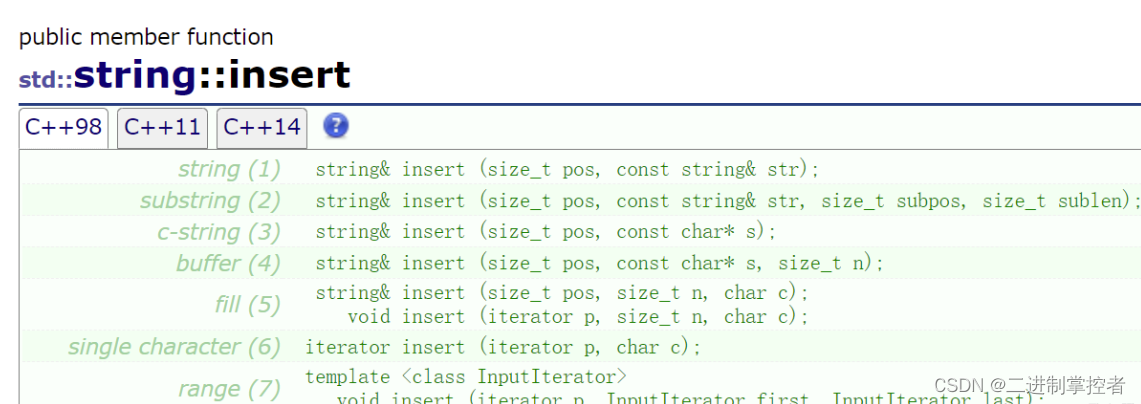
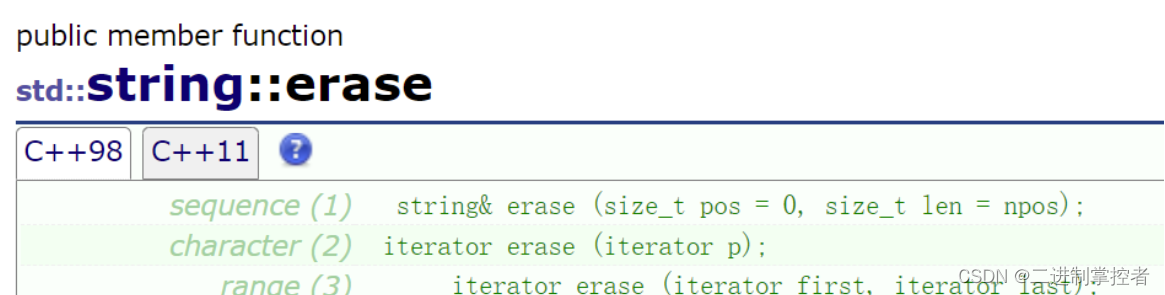
int main() { string tmp("hello world"); string s1; // 在pos位置插入string类字符串 // string& insert (size_t pos, const string& str); s1.insert(0, tmp); cout << s1 << endl; // 在pos位置插入str的子串(subpos位置开始的sublen个字符) // string& insert (size_t pos, const string& str, size_t subpos, size_t sublen); s1.insert(7, tmp, 0, 6); cout << s1 << endl; // 在pos位置插入字符指针指向的字符串 // string& insert (size_t pos, constchar* s); s1.insert(2, "xxx"); cout << s1 << endl; // 在pos位置插入字符指针指向的字符串的前n个字符 // string& insert (size_t pos, const char* s, size_t n); s1.insert(7, "hello naiths", 8); cout << s1 << endl; // 在pos位置插入n个c字符 // string& insert (size_t pos, size_t n, char c); s1.insert(0, 5, 'y'); cout << s1 << endl; // 指定迭代器的位置插入n个字符c // void insert (iterator p, size_t n, char c); string::iterator it = s1.begin() + 10; s1.insert(it, 10, 'z'); cout << s1 << endl; // 指定迭代器的位置插入字符c // iterator insert (iterator p, char c); s1.insert(s1.begin(), 'A'); cout << s1 << endl; // 指定p位置插入迭代器区间的字符 // template <class InputIterator> // void insert(iterator p, InputIterator first, InputIterator last); s1.insert(s1.begin(), tmp.begin() + 3, tmp.begin() + 8); cout << s1 << endl; // 删除pos位置开始的len个字符 // string& erase (size_t pos = 0, size_t len = npos); s1.erase(2, 5); cout << s1 << endl; // 删除迭代器位置的那个字符 // iterator erase (iterator p); s1.erase(s1.begin()); cout << s1 << endl; // 删除迭代器区间的字符 // iterator erase (iterator first, iterator last); s1.erase(s1.begin() + 2, s1.begin() + 5); cout << s1 << endl; return 0; }


三、string底层实现
其实对于上面的这些库里面的函数,我们不需要全去记住,记住一些常用的即可,其他的等到我们要用到的时候去cplusplus网站里面找即可,对于下面我们要自己实现的函数,一定要记住,这些函数用的都是比较多的。
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<assert.h>
using namespace std;
namespace bit
{
class string
{
public:
//string();//不传参的情况
string(const string& s);
string(const char* str = "");//这里可以之际全缺省
~string();
const char* c_str() const;
size_t size() const;
char& operator[](size_t pos);
const char& operator[](size_t pos) const;
string& operator=(const string& s);
//实现一个迭代器
typedef char* iterator;
iterator begin();
iterator end();
typedef const char* const_iterator;
const_iterator begin() const;
const_iterator end() const;
void reserve(size_t n);
void push_back(char ch);
void append(const char* str);
string& operator+=(char ch);
string& operator+=(const char* str);
void insert(size_t pos, char ch);
void insert(size_t pos, const char* str);
void erase(size_t pos, size_t len=npos);
size_t find(char ch, size_t pso = 0);
size_t find(const char* str, size_t pos = 0);
void swap(string& s);
string substr(size_t pos,size_t len);
void clear();
private:
char* _str;
size_t _size;
size_t _capacity;
const static size_t npos;
};
istream& operator>>(istream& is, string& str);
ostream& operator<<(ostream& os, const string& str);
}
上面这些就是我们要实现的一些函数的底层是什么样的,当然,我只是基于自己的理解去写这些,比起C++库里面的肯定要low一点,所以我们理解基础的一些思路即可。
下面我们来看一下这些代码,大家看一下,想要更好的理解可以自己去实现一遍。
#include"string.h"
namespace bit
{
//深拷贝
string::string(const string& s)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
const size_t string::npos = -1;
//不传参的析构
//string::string()
/*{
_str = new char[1] {'\0'};
_size = 0;
_capacity = 0;
}*/
//构造函数
string::string(const char* str)
//strlen是运行时计算长度,效率比较低,三个strlen重复计算了
//但是如果像下面这样写,还是会出现一些问题,因为初始化列表的初始化是按声明的顺序初始化,这里就会出现问题
/*:_str(new char[strlen(str) + 1])
,_size(strlen(str))
,_capacity(strlen(str))*/
: _size(strlen(str))
{
_capacity = _size;
_str = new char[_size + 1];
strcpy(_str, str);
}
//赋值
string& string::operator=(const string& s)
{
//避免自己给自己赋值
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
//这样写是为了避免前面的空间大小小于后面的那个
delete[] _str;
_str = tmp;
}
return *this;
}
//析构
string::~string()
{
delete[] _str;
_size = 0;
_capacity = 0;
}
//打印
const char* string::c_str() const//像这种用于打印的函数,可以在后面加上一个const,
//加上const意味着不能修改指向的内容和本事的值,这样即使放生权限的缩小依然不会报错
{
return _str;
}
size_t string::size() const
{
return _size;
}
char& string::operator[](size_t pos)//可读可写
{
assert(pos < _size);
return _str[pos];
}
const char& string::operator[](size_t pos) const
{
assert(pos < _size);
return _str[pos];
}
//迭代器
string::iterator string::begin()
{
return _str;
}
string::iterator string::end()
{
return _str + _size;
}
//无法修改的迭代
string::const_iterator string::begin() const
{
return _str;
}
string::const_iterator string::end() const
{
return _str + _size;
}
void string::reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[]_str;
_str = tmp;
_capacity = n;
}
}
void string::push_back(char ch)
{
if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
_str[++_size] = '\0';
}
void string::append(const char* str)
{
size_t len = strlen(str);
if (_size + len > _capacity)
{
reserve(_size + len);
}
strcpy(_str + _size, str);
_size += len;
}
string& string::operator+=(char ch)
{
push_back(ch);
return *this;
}
string& string::operator+=(const char* str)
{
append(str);
return *this;
}
void string::insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len >= _capacity)
{
reserve(_size + len);
}
int end = _size;
while (end >= pos)
{
_str[end+len] = _str[end];
--end;
}
memcpy(_str + pos, str, len);
_size += len;
}
void string::insert(size_t pos,char ch)
{
if (_size == _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
size_t end = _size;
while (end >= pos)
{
_str[end + 1] = _str[end];
--end;
}
_str[pos] = ch;
}
void string::erase(size_t pos, size_t len)
{
assert(pos <= _size);
//当len大于前面的个数
if (len>=_size-pos)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
}
size_t string::find(char ch, size_t pos)
{
while (pos!=_size)
{
if (ch == _str[pos])
{
return pos;
}
++pos;
}
return npos;
}
size_t string::find(const char* str, size_t pos)
{
char* p = strstr(_str + pos, str);
return p - _str;
}
void string::swap(string& s)
{
std::swap(_str, s._str);
std::swap(_capacity, s._capacity);
std::swap(_size, s._size);
}
string string::substr(size_t pos, size_t len)
{
//len大于后面的剩余字符,有多少取多少
if (len > _size - pos)
{
string sub(_str - pos);
return sub;
}
else
{
string sub;
sub.reserve(len);
for (size_t i = 0; i < len; i++)
{
sub += _str[pos + i];
}
return sub;
}
}
void string::clear()
{
_str[0] = '\0';
_size = 0;
}
istream& operator>>(istream& is, string& str)
{
char ch;
is >> ch;
while (ch != ' ' && ch != '\n')
{
str += ch;
is >> ch;
}
return is;
}
ostream& operator<<(ostream& os, const string& str)
{
for (size_t i = 0; i < str.size(); i++)
{
os << str[i];
}
return os;
}
}
最后:
十分感谢你可以耐着性子把它读完和我可以坚持写到这里,送几句话,对你,也对我:
1.一个冷知识:
屏蔽力是一个人最顶级的能力,任何消耗你的人和事,多看一眼都是你的不对。
2.你不用变得很外向,内向挺好的,但需要你发言的时候,一定要勇敢。
正所谓:君子可内敛不可懦弱,面不公可起而论之。
3.成年人的世界,只筛选,不教育。
4.自律不是6点起床,7点准时学习,而是不管别人怎么说怎么看,你也会坚持去做,绝不打乱自己的节奏,是一种自我的恒心。
5.你开始炫耀自己,往往都是灾难的开始,就像老子在《道德经》里写到:光而不耀,静水流深。
最后如果觉得我写的还不错,请不要忘记点赞✌,收藏✌,加关注✌哦(。・ω・。)
愿我们一起加油,奔向更美好的未来,愿我们从懵懵懂懂的一枚菜鸟逐渐成为大佬。加油,为自己点赞!